强化学习:Reinforce with Baseline求解MountainCar-v0小车上山问题
1.问题背景
小车上山问题的问题背景就不再赘述了,在实现过程中用到了python的gym库。导入该环境的过程代码如下:
import gym
# 环境类型
env = gym.make("MountainCar-v0")
env = env.unwrapped
print("初始状态{}".format(np.array(env.reset())))
而提前需要导入的库如下:
import sys
import numpy as np
import torch
# 导入torch的各种模块
import torch.nn as nn
from torch.nn import functional as F
from torch.distributions import Categorical
2.A2C原理
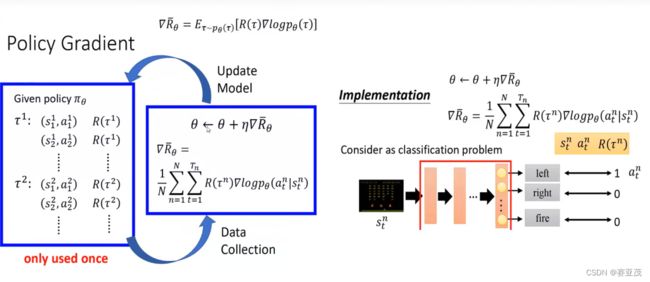
A2C的原理不过多赘述,只需要了解其策略网络 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ)的梯度为:
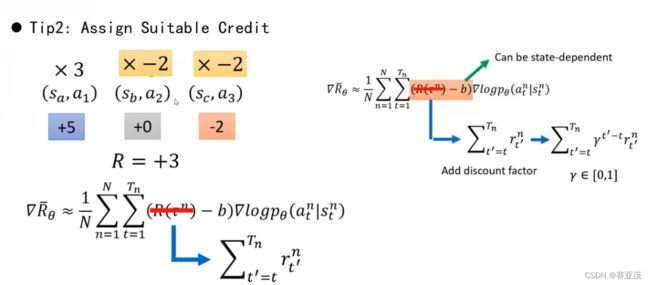
∇ θ J ( θ ) = E s t , a t ∼ π ( . ∣ s t ; θ ) [ A ( s t , a t ; ω ) ∇ θ ln π ( a t ∣ s t ; θ ) ] θ ← θ + α ∇ θ J ( θ ) \nabla_{\theta}J(\theta)=E_{s_t,a_t\sim\pi(.|s_t;\theta)} [A(s_t,a_t;\omega)\nabla_{\theta}\ln\pi(a_t|s_t;\theta)] \\ \theta \leftarrow \theta +\alpha \nabla_{\theta}J(\theta) ∇θJ(θ)=Est,at∼π(.∣st;θ)[A(st,at;ω)∇θlnπ(at∣st;θ)]θ←θ+α∇θJ(θ)其中: A ( s t , a t ) = Q ( s t , a t ) − v ( s t ; ω ) ≈ G t − v ( s t ; ω ) A(s_t,a_t)=Q(s_t,a_t)-v(s_t;\omega)\approx G_t-v(s_t;\omega) A(st,at)=Q(st,at)−v(st;ω)≈Gt−v(st;ω)为优势函数。
而对于每一个轨迹 τ : s 0 a 0 r 0 s 1 , . . . s T − 1 a T − 1 r T − 1 s T \tau:s_0a_0r_0s_1,...s_{T-1}a_{T-1}r_{T-1}s_T τ:s0a0r0s1,...sT−1aT−1rT−1sT而言:
∇ θ J ( θ ) = E τ [ ∇ θ ∑ i = 0 T − 1 ln π ( a t ∣ s t ; θ ) ( R ( τ ) − v ( s t ; ω ) ) ] \nabla_{\theta}J(\theta)=E_{\tau} [\nabla_{\theta}\sum_{i=0}^{T-1}\ln\pi(a_t|s_t;\theta)(R(\tau)-v(s_t;\omega))] \\ ∇θJ(θ)=Eτ[∇θi=0∑T−1lnπ(at∣st;θ)(R(τ)−v(st;ω))]其中: R ( τ ) = ∑ i = 0 ∞ γ i r t R(\tau)=\sum_{i=0}^{\infty} \gamma^{i}r_t R(τ)=∑i=0∞γirt。
对于 v ( s ; ω ) v(s;\omega) v(s;ω)其梯度采用MC算法计算:
∇ ω J ( ω ) = ( G t − v ( s t ; ω ) ) ∇ ω v ( s t ; ω ) ω ← ω − β ∇ ω J ( ω ) \nabla_{\omega}J(\omega)=(G_t-v(s_t;\omega)) \nabla_{\omega} v(s_t;\omega) \\ \omega \leftarrow \omega-\beta \nabla_{\omega}J(\omega) ∇ωJ(ω)=(Gt−v(st;ω))∇ωv(st;ω)ω←ω−β∇ωJ(ω)其中: G t = ∑ i = t T γ i r i G_t=\sum_{i=t}^T\gamma^ir_i Gt=∑i=tTγiri。
将初始化函数__init__;网络的前馈函数forward;根据 π ( a ∣ s ; θ ) , v ( s ; ω ) \pi(a|s;\theta),v(s;\omega) π(a∣s;θ),v(s;ω)采样动作及输出 ln π ( a t ∣ s t ; θ ) , G t \ln \pi(a_t|s_t;\theta),G_t lnπ(at∣st;θ),Gt的函数为:select_action;更新网络参数的函数为:update_policy;网络的训练函数train_network封装到policyNet类中。其代码如下:
class policyNet(nn.Module):
def __init__(self,state_num,action_num,hidden_num=50,lr=0.01):
super(policyNet,self).__init__()
self.fc1 = nn.Linear(state_num,hidden_num)
self.action_fc = nn.Linear(hidden_num,action_num)
self.state_fc = nn.Linear(hidden_num,1)
self.optimzer = torch.optim.Adam(self.parameters(),lr=lr)
# 动作与回报的缓存
self.saved_states = []
self.saved_log_pi = []
self.saved_values = []
self.saved_actions = []
self.saved_rewards = []
# 前馈
def forward(self,state):
hidden_output = self.fc1(state)
x = F.relu(hidden_output)
action_prob = self.action_fc(x)
action_prob = F.softmax(action_prob,dim=-1)
state_values = self.state_fc(x)
return action_prob,state_values
# 选择动作
def select_action(self,state):
# 输入state为numpy数据类型,要先进行数据转化
# 输出lnpi(a|s),v(s),r
state = torch.from_numpy(state).float()
probs,state_value = self.forward(state)
m = Categorical(probs)
action = m.sample()
# 存储数据
self.saved_states.append(state)
self.saved_log_pi.append(m.log_prob(action))
self.saved_values.append(state_value)
self.saved_actions.append(action)
# 返回action
return action.item()
# 实现A2C策略梯度更新
def update_policy(self,gamma=1.0):
# 先计算Gt
R = 0
G = np.zeros_like(self.saved_rewards)
for t in reversed(range(len(self.saved_rewards))):
R = self.saved_rewards[t] + gamma*R
G[t] = R
# 对G标准化
G = (G - np.mean(G))/np.std(G)
G = torch.tensor(G)
# 下面开始求policy_loss,value_loss
policy_loss = []
value_loss = []
for t in range(len(self.saved_rewards)):
log_prob = self.saved_log_pi[t]
value = self.saved_values[t]
Gt = G[t]
advantage = Gt - value
# 计算actor的loss
policy_loss.append(-advantage*log_prob)
value_loss.append(F.smooth_l1_loss(value,Gt))
# 下面开始优化
self.optimzer.zero_grad()
loss = torch.stack(policy_loss).sum() + torch.stack(value_loss).sum()
loss.backward()
self.optimzer.step()
# 更新完后重置缓存
del self.saved_actions[:]
del self.saved_log_pi[:]
del self.saved_rewards[:]
del self.saved_states[:]
del self.saved_values[:]
# 实现训练
def train_network(self,env,epsiodes=1000,gamma=1.0):
# 设置数组用以存储奖励
epsiode_rewards_array = []
rewards_mean_array = []
# env是环境
for epsiode in range(epsiodes):
# 初始化环境状态
state = np.array(env.reset())
epsiode_reward = 0
while True:
action = self.select_action(state)
next_state,reward,done,_ = env.step(action)
self.saved_rewards.append(reward)
epsiode_reward += reward
if done:
#print("第{}次迭代的奖励值为{}".format(epsiode,epsiode_reward))
break
state = next_state
self.update_policy(gamma=gamma)
epsiode_rewards_array.append(epsiode_reward)
rewards_mean_array.append(np.mean(epsiode_rewards_array))
print("第{}次迭代的奖励值为{},累计奖励{}".format(epsiode,epsiode_reward,int(rewards_mean_array[-1])))
return epsiode_rewards_array,rewards_mean_array
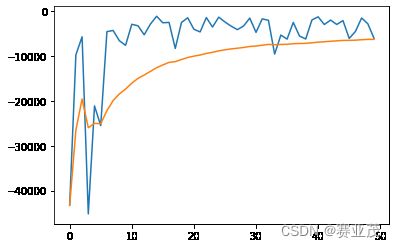
3.训练网络
主函数调用如下:
policyNetWork = policyNet(2,env.action_space.n)
rewards_array,rewards_mean_array = policyNetWork.train_network(env,epsiodes=500)
# 下面是画图函数
import matplotlib.pyplot as plt
plt.plot(rewards_array)
plt.plot(rewards_mean_array)
plt.show()
由于算力有限,仅仅给出收敛次数epsiodes=50时的结果: