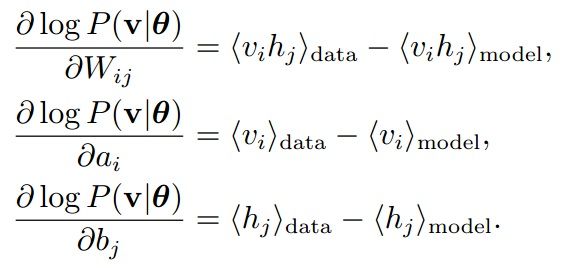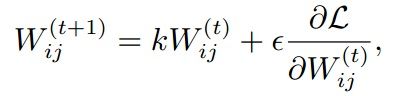- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 数字里的世界17期:2021年全球10大顶级数据中心,中国移动榜首
张三叨
你知道吗?2016年,全球的数据中心共计用电4160亿千瓦时,比整个英国的发电量还多40%!前言每天,我们都会创造超过250万TB的数据。并且随着物联网(IOT)的不断普及,这一数据将持续增长。如此庞大的数据被存储在被称为“数据中心”的专用设施中。虽然最早的数据中心建于20世纪40年代,但直到1997-2000年的互联网泡沫期间才逐渐成为主流。当前人类的技术,比如人工智能和机器学习,已经将我们推向
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- Python开发常用的三方模块如下:
换个网名有点难
python开发语言
Python是一门功能强大的编程语言,拥有丰富的第三方库,这些库为开发者提供了极大的便利。以下是100个常用的Python库,涵盖了多个领域:1、NumPy,用于科学计算的基础库。2、Pandas,提供数据结构和数据分析工具。3、Matplotlib,一个绘图库。4、Scikit-learn,机器学习库。5、SciPy,用于数学、科学和工程的库。6、TensorFlow,由Google开发的开源机
- Python实现简单的机器学习算法
master_chenchengg
pythonpython办公效率python开发IT
Python实现简单的机器学习算法开篇:初探机器学习的奇妙之旅搭建环境:一切从安装开始必备工具箱第一步:安装Anaconda和JupyterNotebook小贴士:如何配置Python环境变量算法初体验:从零开始的Python机器学习线性回归:让数据说话数据准备:从哪里找数据编码实战:Python实现线性回归模型评估:如何判断模型好坏逻辑回归:从分类开始理论入门:什么是逻辑回归代码实现:使用skl
- 遥感影像的切片处理
sand&wich
计算机视觉python图像处理
在遥感影像分析中,经常需要将大尺寸的影像切分成小片段,以便于进行详细的分析和处理。这种方法特别适用于机器学习和图像处理任务,如对象检测、图像分类等。以下是如何使用Python和OpenCV库来实现这一过程,同时确保每个影像片段保留正确的地理信息。准备环境首先,确保安装了必要的Python库,包括numpy、opencv-python和xml.etree.ElementTree。这些库将用于图像处理
- ai绘画工具midjourney怎么下载?附作品管理教程
设计师早上好
Midjourney是一款功能强大的AI绘画工具,它使用机器学习技术和深度神经网络等算法,可以生成各种艺术风格的绘画作品。在创意设计、广告宣传等方面有着广泛的应用前景。那么,ai绘画工具midjourney怎么下载?本文将为您介绍Midjourney的下载以及作品的相关管理。一、Midjourney下载Midjourney的下载非常简单,只需打开Midjourney官网(点击“GetMidjour
- [实践应用] 深度学习之模型性能评估指标
YuanDaima2048
深度学习工具使用深度学习人工智能损失函数性能评估pytorchpython机器学习
文章总览:YuanDaiMa2048博客文章总览深度学习之模型性能评估指标分类任务回归任务排序任务聚类任务生成任务其他介绍在机器学习和深度学习领域,评估模型性能是一项至关重要的任务。不同的学习任务需要不同的性能指标来衡量模型的有效性。以下是对一些常见任务及其相应的性能评估指标的详细解释和总结。分类任务分类任务是指模型需要将输入数据分配到预定义的类别或标签中。以下是分类任务中常用的性能指标:准确率(
- 机器学习-聚类算法
不良人龍木木
机器学习机器学习算法聚类
机器学习-聚类算法1.AHC2.K-means3.SC4.MCL仅个人笔记,感谢点赞关注!1.AHC2.K-means3.SC传统谱聚类:个人对谱聚类算法的理解以及改进4.MCL目前仅专注于NLP的技术学习和分享感谢大家的关注与支持!
- 未来软件市场是怎么样的?做开发的生存空间如何?
cesske
软件需求
目录前言一、未来软件市场的发展趋势二、软件开发人员的生存空间前言未来软件市场是怎么样的?做开发的生存空间如何?一、未来软件市场的发展趋势技术趋势:人工智能与机器学习:随着技术的不断成熟,人工智能将在更多领域得到应用,如智能客服、自动驾驶、智能制造等,这将极大地推动软件市场的增长。云计算与大数据:云计算服务将继续普及,大数据技术的应用也将更加广泛。企业将更加依赖云计算和大数据来优化运营、提升效率,并
- python中zeros用法_Python中的numpy.zeros()用法
江平舟
python中zeros用法
numpy.zeros()函数是最重要的函数之一,广泛用于机器学习程序中。此函数用于生成包含零的数组。numpy.zeros()函数提供给定形状和类型的新数组,并用零填充。句法numpy.zeros(shape,dtype=float,order='C'参数形状:整数或整数元组此参数用于定义数组的尺寸。此参数用于我们要在其中创建数组的形状,例如(3,2)或2。dtype:数据类型(可选)此参数用于
- 【NumPy】深入解析numpy.zeros()函数
二七830
numpy
欢迎莅临我的个人主页这里是我深耕Python编程、机器学习和自然语言处理(NLP)领域,并乐于分享知识与经验的小天地!博主简介:我是二七830,一名对技术充满热情的探索者。多年的Python编程和机器学习实践,使我深入理解了这些技术的核心原理,并能够在实际项目中灵活应用。尤其是在NLP领域,我积累了丰富的经验,能够处理各种复杂的自然语言任务。技术专长:我熟练掌握Python编程语言,并深入研究了机
- 【中国国际航空-注册_登录安全分析报告】
风控牛
验证码接口安全评测系列安全行为验证极验网易易盾智能手机
前言由于网站注册入口容易被黑客攻击,存在如下安全问题:1.暴力破解密码,造成用户信息泄露2.短信盗刷的安全问题,影响业务及导致用户投诉3.带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞所以大部分网站及App都采取图形验证码或滑动验证码等交互解决方案,但在机器学习能力提高的当下,连百度这样的大厂都遭受攻击导致点名批评,图形验证及交互验证方式的安全性到底如何?请看具体分析一、中国国际航空PC
- 机器学习 流形数据降维:UMAP 降维算法
小嗷犬
Python机器学习#数据分析及可视化机器学习算法人工智能
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。个人主页:小嗷犬的个人主页个人网站:小嗷犬的技术小站个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。本文目录UMAP简介理论基础特点与优势应用场景在Python中使用UMAP安装umap-learn库使用UMAP可视化手写数字数据集UMAP简介UMAP(UniformManifoldApproximatio
- 七.正则化
愿风去了
吴恩达机器学习之正则化(Regularization)http://www.cnblogs.com/jianxinzhou/p/4083921.html从数学公式上理解L1和L2https://blog.csdn.net/b876144622/article/details/81276818虽然在线性回归中加入基函数会使模型更加灵活,但是很容易引起数据的过拟合。例如将数据投影到30维的基函数上,模
- 机器学习-------数据标准化
罔闻_spider
数据分析算法机器学习人工智能
什么是归一化,它与标准化的区别是什么?一作用在做训练时,需要先将特征值与标签标准化,可以防止梯度防炸和过拟合;将标签标准化后,网络预测出的数据是符合标准正态分布的—StandarScaler(),与真实值有很大差别。因为StandarScaler()对数据的处理是(真实值-平均值)/标准差。同时在做预测时需要将输出数据逆标准化提升模型精度:标准化/归一化使不同维度的特征在数值上更具比较性,提高分类
- 分享一个基于python的电子书数据采集与可视化分析 hadoop电子书数据分析与推荐系统 spark大数据毕设项目(源码、调试、LW、开题、PPT)
计算机源码社
Python项目大数据大数据pythonhadoop计算机毕业设计选题计算机毕业设计源码数据分析spark毕设
作者:计算机源码社个人简介:本人八年开发经验,擅长Java、Python、PHP、.NET、Node.js、Android、微信小程序、爬虫、大数据、机器学习等,大家有这一块的问题可以一起交流!学习资料、程序开发、技术解答、文档报告如需要源码,可以扫取文章下方二维码联系咨询Java项目微信小程序项目Android项目Python项目PHP项目ASP.NET项目Node.js项目选题推荐项目实战|p
- 两种方法判断Python的位数是32位还是64位
sanqima
Python编程电脑python开发语言
Python从1991年发布以来,凭借其简洁、清晰、易读的语法、丰富的标准库和第三方工具,在Web开发、自动化测试、人工智能、图形识别、机器学习等领域发展迅猛。 Python是一种胶水语言,通过Cython库与C/C++语言进行链接,通过Jython库与Java语言进行链接。 Python是跨平台的,可运行在多种操作系统上,包括但不限于Windows、Linux和macOS。这意味着用Py
- 使用最大边际相关性(MMR)选择示例:提高AI模型的多样性和相关性
aehrutktrjk
人工智能easyui前端python
使用最大边际相关性(MMR)选择示例:提高AI模型的多样性和相关性引言在机器学习和自然语言处理领域,选择合适的训练示例对模型性能至关重要。最大边际相关性(MaximalMarginalRelevance,MMR)是一种优秀的示例选择方法,它不仅考虑了示例与输入的相关性,还注重保持所选示例之间的多样性。本文将深入探讨如何使用MMR来选择示例,以提高AI模型的性能和泛化能力。什么是最大边际相关性(MM
- LangChain集成指南:如何利用多样化的AI提供商
aehrutktrjk
人工智能langchainpython
LangChain集成指南:如何利用多样化的AI提供商引言在人工智能和机器学习领域,LangChain已成为一个强大而灵活的框架,允许开发者轻松集成各种AI服务提供商。本文将深入探讨LangChain的集成能力,介绍如何利用不同的AI提供商来增强你的应用程序,并提供实用的代码示例。LangChain集成概览LangChain支持多种AI提供商的集成,这些集成可以分为两类:独立包集成:这些提供商有独
- 机器学习VS深度学习
nfgo
机器学习
机器学习(MachineLearning,ML)和深度学习(DeepLearning,DL)是人工智能(AI)的两个子领域,它们有许多相似之处,但在技术实现和应用范围上也有显著区别。下面从几个方面对两者进行区分:1.概念层面机器学习:是让计算机通过算法从数据中自动学习和改进的技术。它依赖于手动设计的特征和数学模型来进行学习,常用的模型有决策树、支持向量机、线性回归等。深度学习:是机器学习的一个子领
- 大数据毕业设计hadoop+spark+hive知识图谱租房数据分析可视化大屏 租房推荐系统 58同城租房爬虫 房源推荐系统 房价预测系统 计算机毕业设计 机器学习 深度学习 人工智能
2401_84572577
程序员大数据hadoop人工智能
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。我先来介绍一下这些东西怎么用,文末抱走。(1)Python所有方向的学习路线(
- 【机器学习与R语言】1-机器学习简介
苹果酱0567
面试题汇总与解析java中间件开发语言springboot后端
1.基本概念机器学习:发明算法将数据转化为智能行为数据挖掘VS机器学习:前者侧重寻找有价值的信息,后者侧重执行已知的任务。后者是前者的先期准备过程:数据——>抽象化——>一般化。或者:收集数据——推理数据——归纳数据——发现规律抽象化:训练:用一个特定模型来拟合数据集的过程用方程来拟合观测的数据:观测现象——数据呈现——模型建立。通过不同的格式来把信息概念化一般化:一般化:将抽象化的知识转换成可用
- Python前沿技术:机器学习与人工智能
4.0啊
Python人工智能python机器学习
Python前沿技术:机器学习与人工智能一、引言随着科技的飞速发展,机器学习和人工智能(AI)已经成为了计算机科学领域的热门话题。Python作为一门易学易用且功能强大的编程语言,已经成为了这两个领域的首选语言之一。本文将深入探讨Python在机器学习和人工智能领域的应用,以及一些前沿技术和工具。二、Python机器学习基础2.1机器学习概述机器学习是人工智能(AI)的一个关键子集,它的核心在于让
- chatgpt赋能python:如何在Python中计算平均值
tulingtest
ChatGptpythonchatgptnumpy计算机
如何在Python中计算平均值计算平均值是数据分析、统计和机器学习等许多领域中的常见任务。Python作为一门功能强大且易于学习的编程语言,为计算平均值提供了多种方法。在本文中,我们将介绍如何在Python中计算平均值。什么是平均值简单来说,平均值是一组数字的总和除以数字的数量。例如,对于数字序列1,3,5,7,9,平均值是(1+3+5+7+9)/5=5。平均值在数据分析中非常有用,因为它可以提供
- Python 初学者入门必知: Anaconda是什么?有什么作用?怎么使用?
懒大王爱吃狼
Python基础python开发语言python基础python学习anacondaanaconda安装python教程
初学者在学习Python时,经常看到的一个名字是Anaconda。究竟什么是Anaconda,为什么它如此受欢迎?在这篇文章中,我们将探讨Anaconda,了解Anaconda的从安装到使用的。Anaconda是一个免费开源的Python和R编程发行版,包含上千个适用于数据科学和机器学习的包。同时,配备了Spyder和Jupyternotebook等工具,初学者可以使用它们来学习Python,使用
- 每天五分钟玩转深度学习PyTorch:模型参数优化器torch.optim
幻风_huanfeng
深度学习框架pytorch深度学习pytorch人工智能神经网络机器学习优化算法
本文重点在机器学习或者深度学习中,我们需要通过修改参数使得损失函数最小化(或最大化),优化算法就是一种调整模型参数更新的策略。在pytorch中定义了优化器optim,我们可以使用它调用封装好的优化算法,然后传递给它神经网络模型参数,就可以对模型进行优化。本文是学习第6步(优化器),参考链接pytorch的学习路线随机梯度下降算法在深度学习和机器学习中,梯度下降算法是最常用的参数更新方法,它的公式
- 一切皆是映射:AI的去中心化:区块链技术的融合
AI大模型应用之禅
计算科学神经计算深度学习神经网络大数据人工智能大型语言模型AIAGILLMJavaPython架构设计AgentRPA
一切皆是映射:AI的去中心化:区块链技术的融合作者:禅与计算机程序设计艺术/ZenandtheArtofComputerProgramming关键词:AI,区块链,去中心化,智能合约,共识机制,数据安全,隐私保护,分布式账本技术,机器学习,数据隐私1.背景介绍1.1问题的由来随着人工智能(AI)技术的快速发展,其在各个领域的应用越来越广泛,从自动驾驶、智能医疗到金融服务,AI正在改变着我们的生活。
- 第五届核磁机器学习班(训练营:2023.6.5~6.17)
茗创科技
茗创科技专注于脑科学数据处理,涵盖(EEG/ERP,fMRI,结构像,DTI,ASL,FNIRS)等,欢迎留言讨论及转发推荐,也欢迎了解茗创科技的脑电课程,数据处理服务及脑科学工作站销售业务,可添加我们的工程师(微信号MCKJ-zhouyi或17373158786)咨询。★课程简介★基于血氧水平依赖的功能磁共振成像(fMRI)技术,利用其数据构建的功能性脑网络后,发现脑并不是一个单纯对外界刺激进行
- 如何有效的学习AI大模型?
Python程序员罗宾
学习人工智能语言模型自然语言处理架构
学习AI大模型是一个系统性的过程,涉及到多个学科的知识。以下是一些建议,帮助你更有效地学习AI大模型:基础知识储备:数学基础:学习线性代数、概率论、统计学和微积分等,这些是理解机器学习算法的数学基础。编程技能:掌握至少一种编程语言,如Python,因为大多数AI模型都是用Python实现的。理论学习:机器学习基础:了解监督学习、非监督学习、强化学习等基本概念。深度学习:学习神经网络的基本结构,如卷
- java观察者模式
3213213333332132
java设计模式游戏观察者模式
观察者模式——顾名思义,就是一个对象观察另一个对象,当被观察的对象发生变化时,观察者也会跟着变化。
在日常中,我们配java环境变量时,设置一个JAVAHOME变量,这就是被观察者,使用了JAVAHOME变量的对象都是观察者,一旦JAVAHOME的路径改动,其他的也会跟着改动。
这样的例子很多,我想用小时候玩的老鹰捉小鸡游戏来简单的描绘观察者模式。
老鹰会变成观察者,母鸡和小鸡是
- TFS RESTful API 模拟上传测试
ronin47
TFS RESTful API 模拟上传测试。
细节参看这里:https://github.com/alibaba/nginx-tfs/blob/master/TFS_RESTful_API.markdown
模拟POST上传一个图片:
curl --data-binary @/opt/tfs.png http
- PHP常用设计模式单例, 工厂, 观察者, 责任链, 装饰, 策略,适配,桥接模式
dcj3sjt126com
设计模式PHP
// 多态, 在JAVA中是这样用的, 其实在PHP当中可以自然消除, 因为参数是动态的, 你传什么过来都可以, 不限制类型, 直接调用类的方法
abstract class Tiger {
public abstract function climb();
}
class XTiger extends Tiger {
public function climb()
- hibernate
171815164
Hibernate
main,save
Configuration conf =new Configuration().configure();
SessionFactory sf=conf.buildSessionFactory();
Session sess=sf.openSession();
Transaction tx=sess.beginTransaction();
News a=new
- Ant实例分析
g21121
ant
下面是一个Ant构建文件的实例,通过这个实例我们可以很清楚的理顺构建一个项目的顺序及依赖关系,从而编写出更加合理的构建文件。
下面是build.xml的代码:
<?xml version="1
- [简单]工作记录_接口返回405原因
53873039oycg
工作
最近调接口时候一直报错,错误信息是:
responseCode:405
responseMsg:Method Not Allowed
接口请求方式Post.
- 关于java.lang.ClassNotFoundException 和 java.lang.NoClassDefFoundError 的区别
程序员是怎么炼成的
真正完成类的加载工作是通过调用 defineClass来实现的;
而启动类的加载过程是通过调用 loadClass来实现的;
就是类加载器分为加载和定义
protected Class<?> findClass(String name) throws ClassNotFoundExcept
- JDBC学习笔记-JDBC详细的操作流程
aijuans
jdbc
所有的JDBC应用程序都具有下面的基本流程: 1、加载数据库驱动并建立到数据库的连接。 2、执行SQL语句。 3、处理结果。 4、从数据库断开连接释放资源。
下面我们就来仔细看一看每一个步骤:
其实按照上面所说每个阶段都可得单独拿出来写成一个独立的类方法文件。共别的应用来调用。
1、加载数据库驱动并建立到数据库的连接:
Html代码
St
- rome创建rss
antonyup_2006
tomcatcmsxmlstrutsOpera
引用
1.RSS标准
RSS标准比较混乱,主要有以下3个系列
RSS 0.9x / 2.0 : RSS技术诞生于1999年的网景公司(Netscape),其发布了一个0.9版本的规范。2001年,RSS技术标准的发展工作被Userland Software公司的戴夫 温那(Dave Winer)所接手。陆续发布了0.9x的系列版本。当W3C小组发布RSS 1.0后,Dave W
- html表格和表单基础
百合不是茶
html表格表单meta锚点
第一次用html来写东西,感觉压力山大,每次看见别人发的都是比较牛逼的 再看看自己什么都还不会,
html是一种标记语言,其实很简单都是固定的格式
_----------------------------------------表格和表单
表格是html的重要组成部分,表格用在body里面的
主要用法如下;
<table>
&
- ibatis如何传入完整的sql语句
bijian1013
javasqlibatis
ibatis如何传入完整的sql语句?进一步说,String str ="select * from test_table",我想把str传入ibatis中执行,是传递整条sql语句。
解决办法:
<
- 精通Oracle10编程SQL(14)开发动态SQL
bijian1013
oracle数据库plsql
/*
*开发动态SQL
*/
--使用EXECUTE IMMEDIATE处理DDL操作
CREATE OR REPLACE PROCEDURE drop_table(table_name varchar2)
is
sql_statement varchar2(100);
begin
sql_statement:='DROP TABLE '||table_name;
- 【Linux命令】Linux工作中常用命令
bit1129
linux命令
不断的总结工作中常用的Linux命令
1.查看端口被哪个进程占用
通过这个命令可以得到占用8085端口的进程号,然后通过ps -ef|grep 进程号得到进程的详细信息
netstat -anp | grep 8085
察看进程ID对应的进程占用的端口号
netstat -anp | grep 进程ID
&
- 优秀网站和文档收集
白糖_
网站
集成 Flex, Spring, Hibernate 构建应用程序
性能测试工具-JMeter
Hmtl5-IOCN网站
Oracle精简版教程网站
鸟哥的linux私房菜
Jetty中文文档
50个jquery必备代码片段
swfobject.js检测flash版本号工具
- angular.extend
boyitech
AngularJSangular.extendAngularJS API
angular.extend 复制src对象中的属性去dst对象中. 支持多个src对象. 如果你不想改变一个对象,你可以把dst设为空对象{}: var object = angular.extend({}, object1, object2). 注意: angular.extend不支持递归复制. 使用方法: angular.extend(dst, src); 参数:
- java-谷歌面试题-设计方便提取中数的数据结构
bylijinnan
java
网上找了一下这道题的解答,但都是提供思路,没有提供具体实现。其中使用大小堆这个思路看似简单,但实现起来要考虑很多。
以下分别用排序数组和大小堆来实现。
使用大小堆:
import java.util.Arrays;
public class MedianInHeap {
/**
* 题目:设计方便提取中数的数据结构
* 设计一个数据结构,其中包含两个函数,1.插
- ajaxFileUpload 针对 ie jquery 1.7+不能使用问题修复版本
Chen.H
ajaxFileUploadie6ie7ie8ie9
jQuery.extend({
handleError: function( s, xhr, status, e ) {
// If a local callback was specified, fire it
if ( s.error ) {
s.error.call( s.context || s, xhr, status, e );
}
- [机器人制造原则]机器人的电池和存储器必须可以替换
comsci
制造
机器人的身体随时随地可能被外来力量所破坏,但是如果机器人的存储器和电池可以更换,那么这个机器人的思维和记忆力就可以保存下来,即使身体受到伤害,在把存储器取下来安装到一个新的身体上之后,原有的性格和能力都可以继续维持.....
另外,如果一
- Oracle Multitable INSERT 的用法
daizj
oracle
转载Oracle笔记-Multitable INSERT 的用法
http://blog.chinaunix.net/uid-8504518-id-3310531.html
一、Insert基础用法
语法:
Insert Into 表名 (字段1,字段2,字段3...)
Values (值1,
- 专访黑客历史学家George Dyson
datamachine
on
20世纪最具威力的两项发明——核弹和计算机出自同一时代、同一群年青人。可是,与大名鼎鼎的曼哈顿计划(第二次世界大战中美国原子弹研究计划)相 比,计算机的起源显得默默无闻。出身计算机世家的历史学家George Dyson在其新书《图灵大教堂》(Turing’s Cathedral)中讲述了阿兰·图灵、约翰·冯·诺依曼等一帮子天才小子创造计算机及预见计算机未来
- 小学6年级英语单词背诵第一课
dcj3sjt126com
englishword
always 总是
rice 水稻,米饭
before 在...之前
live 生活,居住
usual 通常的
early 早的
begin 开始
month 月份
year 年
last 最后的
east 东方的
high 高的
far 远的
window 窗户
world 世界
than 比...更
- 在线IT教育和在线IT高端教育
dcj3sjt126com
教育
codecademy
http://www.codecademy.com codeschool
https://www.codeschool.com teamtreehouse
http://teamtreehouse.com lynda
http://www.lynda.com/ Coursera
https://www.coursera.
- Struts2 xml校验框架所定义的校验文件
蕃薯耀
Struts2 xml校验Struts2 xml校验框架Struts2校验
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年7月11日 15:54:59 星期六
http://fa
- mac下安装rar和unrar命令
hanqunfeng
mac
1.下载:http://www.rarlab.com/download.htm 选择
RAR 5.21 for Mac OS X 2.解压下载后的文件 tar -zxvf rarosx-5.2.1.tar 3.cd rar sudo install -c -o $USER unrar /bin #输入当前用户登录密码 sudo install -c -o $USER rar
- 三种将list转换为map的方法
jackyrong
list
在本文中,介绍三种将list转换为map的方法:
1) 传统方法
假设有某个类如下
class Movie {
private Integer rank;
private String description;
public Movie(Integer rank, String des
- 年轻程序员需要学习的5大经验
lampcy
工作PHP程序员
在过去的7年半时间里,我带过的软件实习生超过一打,也看到过数以百计的学生和毕业生的档案。我发现很多事情他们都需要学习。或许你会说,我说的不就是某种特定的技术、算法、数学,或者其他特定形式的知识吗?没错,这的确是需要学习的,但却并不是最重要的事情。他们需要学习的最重要的东西是“自我规范”。这些规范就是:尽可能地写出最简洁的代码;如果代码后期会因为改动而变得凌乱不堪就得重构;尽量删除没用的代码,并添加
- 评“女孩遭野蛮引产致终身不育 60万赔偿款1分未得”医腐深入骨髓
nannan408
先来看南方网的一则报道:
再正常不过的结婚、生子,对于29岁的郑畅来说,却是一个永远也无法实现的梦想。从2010年到2015年,从24岁到29岁,一张张新旧不一的诊断书记录了她病情的同时,也清晰地记下了她人生的悲哀。
粗暴手术让人发寒
2010年7月,在酒店做服务员的郑畅发现自己怀孕了,可男朋友却联系不上。在没有和家人商量的情况下,她决定堕胎。
12月5日,
- 使用jQuery为input输入框绑定回车键事件 VS 为a标签绑定click事件
Everyday都不同
jspinput回车键绑定clickenter
假设如题所示的事件为同一个,必须先把该js函数抽离出来,该函数定义了监听的处理:
function search() {
//监听函数略......
}
为input框绑定回车事件,当用户在文本框中输入搜索关键字时,按回车键,即可触发search():
//回车绑定
$(".search").keydown(fun
- EXT学习记录
tntxia
ext
1. 准备
(1) 官网:http://www.sencha.com/
里面有源代码和API文档下载。
EXT的域名已经从www.extjs.com改成了www.sencha.com ,但extjs这个域名会自动转到sencha上。
(2)帮助文档:
想要查看EXT的官方文档的话,可以去这里h
- mybatis3的mapper文件报Referenced file contains errors
xingguangsixian
mybatis
最近使用mybatis.3.1.0时无意中碰到一个问题:
The errors below were detected when validating the file "mybatis-3-mapper.dtd" via the file "account-mapper.xml". In most cases these errors can be d