招聘网探究分析报告(以描述性分析为主)
招聘网探究分析报告(以描述性分析为主)
1 引 言
记得在我中学时,就听到过“大学生一毕业就失业”的言论。网上资料显示是大学扩招,书本理论知识与岗位真实需求脱节严重,善于纸上谈兵而不注重动手实践,自我定位过高骄子心态等的缘由。如果能提前了解现在的就业形势,了解整个就业市场缺少的人才、岗位任职资格等一些基本信息,然后能自学符合企业要求的技能,就完全碾压没有准备的人,俗话说的好,机会总是留给有准备的人。但是,有时候也是需要天时地利人和相结合。
确实,天有不测风云,今年爆发新冠肺炎疫情,疫情对餐饮、旅游、住宿、娱乐等行业的冲击很大,相关企业被迫压缩人力资源支出,招聘需求下降,社会失业率升高,但同时,也为医疗健康、IT、智能制造、电子物流等行业带来了机遇。暂时失业者一定要抓住机会,必须多多关注企业的招聘信息和政府的相关政策。虽然减少用人需求,但终究是有企业用人的,是否能够抓住机会,只是对我们的努力提出了更高的要求而已。基于此,对就业市场展开了分析研究。主要分析岗位分布及需求、企业、职位要求、薪资要求。
2 数据来源
数据来源于拉勾网,不限字段,通过python爬取网站数据,共爬取拉勾网招聘网的职业信息450条,字段信息包含职位、地区、薪资、学历要求、经验要求、公司名称、公司规模、公司领域、备注、职业诱惑。
3 拉勾网招聘数据
不设定关键字,利用爬虫selenium库动态爬取12月19日晚上九点左右更新的数据。技术分析流程分为以下三个步骤:网络数据获取、数据读入和数据清洗、数据可视化分析。
经过网络爬虫,整理出12个字段。字段含义为职位、招聘所在城市、最低薪资、最高薪资、平均薪资、公司名称、公司规模、公司领域、对于相关职业的关键点、职业诱惑。
3.1岗位分布及需求
3.1.1根据不同城市岗位需求进行统计分析
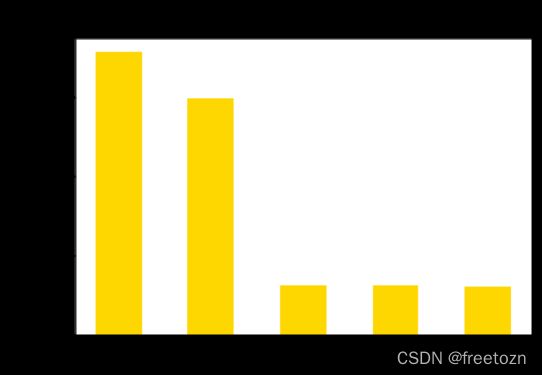
根据上图,提取岗位需求排名前五的城市,数据显示,杭州、北京的岗位需求远远大于其他城市。
3.1.2统计不同职位的需求量

根据上图,golong开发工程师、iOS技术专家、ETL工程师、手游推广、高级体验设计专家的职位需求量并列第一,说明在移动互联网、技术开发等领域,人才需求较大,市场尚未饱和。现在社会进步、科技发展,高科技人才确实重要。
3.2企业分析
3.2.1统计岗位需求排名前五的公司。

根据上图,光年实验室、红蓝CP、花信科技、跟谁学、锦乐煜五金岗位需求并列第一,查询信息得知,光年实验室软件、硬件和大数据领域都有大量创新,能快速帮助商家掌握互联网营销从而实现高速增长;红蓝CP是从事APP开发的;花信科技是针对银行C端客户而开发的创新品牌,基于人工智能、生物识别、数据分析、智能匹配等前沿技术来开发产品;跟谁学是有关教育培训的。岗位需求量大的基本上是从事科技、教育领域,与现在的行业形势相呼应。提示就业者需要多多关注这些信息。
3.2.2公司规模分析
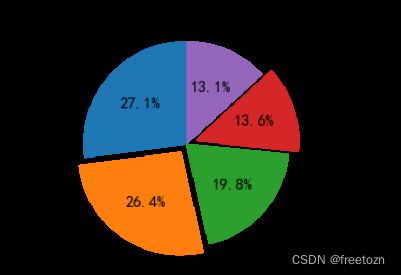
根据上图,公司规模大体分为15-50人,50-150人,150-500人,500-2000人,2000人以上,其中50-150人占据27.1%,15-50人占据26.4%,150-500人占据13.1%,500-2000人占据13.6%,2000人以上占据19.8%。招聘企业公司规模集中于15-150人。
3.2.3公司领域分析
根据describe()分析公司领域,排在前列的字眼往往是移动互联网、数据服务、信息安全等有关科技方面的。说明整个行业趋势正在往移动互联网这方面发展。
3.2.4分析排名前五公司的平均薪资。
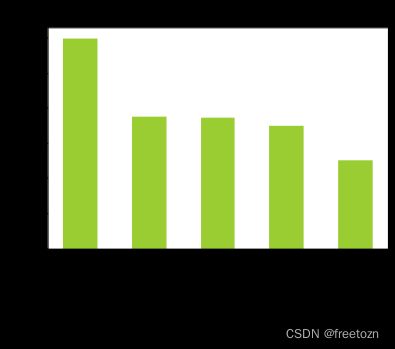
根据上图,显示出排名前五公司的平均成绩,其中跟谁学是位居第一,平均薪资高达6万元,跟谁学是国内以K-12为主的在线教育机构,秉承科技让教育更美好的使命,通过直播+辅导的双师模式,提供小学、初中、高中全科,以及语言、职业和兴趣教育等课程。说明在线教育行业市场前景较好,尤其是与科技相结合能发挥到极致。其中得物App开创性的推出了"先鉴别,再发货"的购物流程,钉钉则是由阿里巴巴出品,专为全球企业组织打造的智能移动办公平台。这两个App都是用科技便利社会。由这些公司的平均薪资也是能反映出公司在自己领域获得了不菲的利益,科技创新就是硬道理。
3.3职位要求分析
3.3.1应聘者的学历要求分布
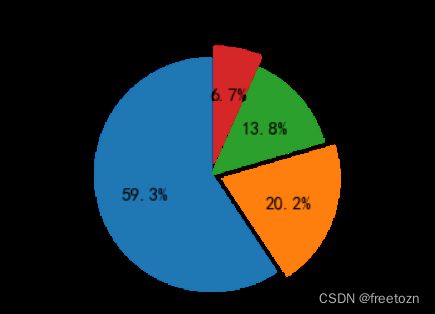
根据上图,企业要求的学历基本上为本科,说明一般大学毕业生的起跑线还是同等的。
3.3.2应聘者的经验要求
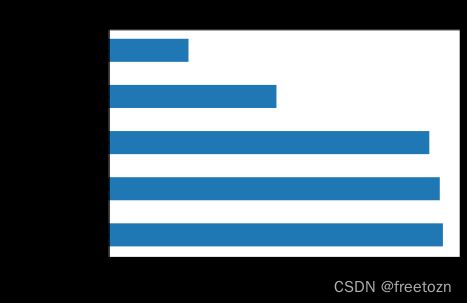
根据上图,公司对于应聘者的工作经验要求大体分为五个区间,分别是在校应届、1-3年、3-5年、5-10年、经验不限,并且呈现双向发展,经验不限与经验为5-10年的需求量差不多。
3.3.3不同职业的薪资比较


根据上图,有关开发设计人员薪资的底价至少为2万元,而排名靠后的职位(如大客户代表、普工操作工)的薪资到顶也只有8千元。说明一些有技术含量、需要运用高科技知识的职位薪资远远高于其他职业,甚至是遥不可及的。
3.3.4排名前五的职业诱惑
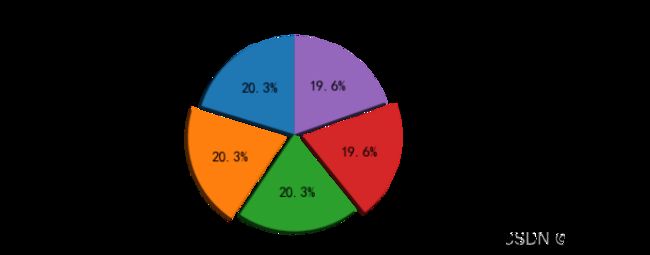
根据上图,团队氛围好,上市公司、股票、七险一金,市场前景好、企业快速成长期、股票期权都占据20.3%,五险一金、周末双休、年底双薪,发展前景好、技术大牛、福利待遇好都占据19.6%,虽说是排名前五的待遇,但事实上差距不大。企业给出的职业诱惑基本上是五险一金、七险一金、双休、双薪等福利诱惑。
3.4薪资分析
3.4.1不同学历要求的平均薪资
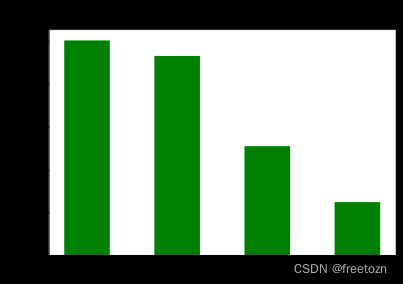
根据上图,显而易见,学历程度与平均薪资成正比,学历要求为本科及本科以上的平均薪资远远超过本科以下的。提示从业者,高水平的知识劳动更有价值。读书是硬道理,读得好有朝一日会有回报的。
3.4.2不同工作经验的平均薪资
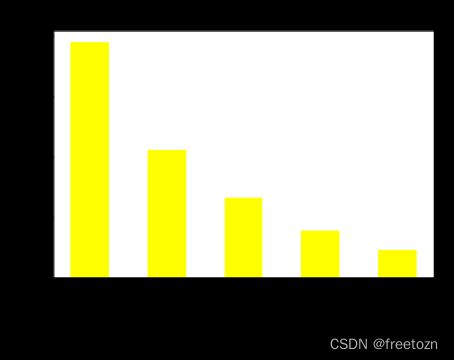
根据上图,图形呈现阶梯状,经验越高,平均薪资也是越高。虽然经验不限与经验5-10年的需求量相差不大,但是薪资差别大,即职场菜鸟与老手的区别。
4 结 论
对于不同职位需求,杭州和北京的需求量相对较多。集中在开发设计等有关互联网领域的人才较为稀缺,招聘人数较多。在校或应届大学生可能多涉猎相关知识,学习相关技能,市场尚未饱和,需要抓住机遇。
招聘需求发布较多的企业所涉及的领域基本集中在移动互联网、教育等方面,如跟谁学、花信科技、光年实验室等。教育行业必然是不容小觑的,尤其疫情的出现倒逼教育要在短时间内在时空上做出改变,在线教育的蓬勃发展,既是对当下教育困境的应对,也是对教育未来带来的创新。科技领域更是不用说,在这个大数据时代、5G时代,科技型人才不可少。而且这些类型的公司提供的薪资要高于其它类型企业。招聘公司规模基本位于15-50人以及50-150人。从职业诱惑,企业善于抓住应聘者的心理,抛出的福利基本上是一些保障类(如五险一金、七险一金、双休、双薪等)。
企业的目的就是盈利,招聘人才时自然会录取更有价值的应聘者。学历要求为本科占比59.3%,说明“一毕业就失业”的言论还有待于考究。而且对于本科生以及硕士生的薪资相差不大。从工作经验来看,经验1-3年和经验5-10年的人才需求差不多,但是工作差距基本上一倍。所以说,大学生如果打算考研固然是好的,如果没有这个打算,在大学期间根据课上学和自学等方式学习自己的专业知识或学习其它现在市场需求较大的职位所需的技能,在毕业之后也不至于迷茫。而且能实习的机会一定要抓住。
5 附 录
5.1网络数据获取
#selenium库对拉勾网进行数据爬取
from selenium import webdriver
browser=webdriver.Chrome()
url='https://www.lagou.com/zhaopin/'
browser.get(url)
import time
zhiwei=[]
diqu=[]
xinzi=[]
xueli=[]
jingyan=[]
gongsimingcheng=[]
gongsilingyu=[]
gongsiguimo=[]
beizhu=[]
zhiyeyouhuo=[]
for i in range(30):
time.sleep(10)#睡眠10秒
for t in browser.find_elements_by_class_name('item_con_list')[1].find_elements_by_tag_name('li'):
zhiwei.append(t.find_elements_by_class_name('list_item_top')[0].find_elements_by_class_name('position')[0].find_elements_by_class_name('p_top')[0].find_elements_by_tag_name('h3')[0].text)#职位存入列表
diqu.append(t.find_elements_by_class_name('list_item_top')[0].find_elements_by_class_name('position')[0].find_elements_by_class_name('p_top')[0].find_elements_by_tag_name('em')[0].text)#地区存入列表
xinzi.append(t.find_elements_by_class_name('list_item_top')[0].find_elements_by_class_name('position')[0].find_elements_by_class_name('p_bot')[0].find_elements_by_class_name('li_b_l')[0].find_elements_by_tag_name('span')[0].text)#薪资存入列表
xueli.append(t.find_elements_by_class_name('list_item_top')[0].find_elements_by_class_name('position')[0].find_elements_by_class_name('p_bot')[0].find_elements_by_class_name('li_b_l')[0].text.replace('/','').split(' ')[-1])#学历存入列表
jingyan.append(t.find_elements_by_class_name('list_item_top')[0].find_elements_by_class_name('position')[0].find_elements_by_class_name('p_bot')[0].find_elements_by_class_name('li_b_l')[0].text.replace('/','').split(' ')[1]+''+t.find_elements_by_class_name('list_item_top')[0].find_elements_by_class_name('position')[0].find_elements_by_class_name('p_bot')[0].find_elements_by_class_name('li_b_l')[0].text.replace('/','').split(' ')[-2])#经验存入列表
gongsimingcheng.append(t.find_elements_by_class_name('list_item_top')[0].find_elements_by_class_name('company')[0].find_elements_by_class_name('company_name')[0].text)#公司名称存入列表
gongsilingyu.append(t.find_elements_by_class_name('list_item_top')[0].find_elements_by_class_name('company')[0].find_elements_by_class_name('industry')[0].text.split('/')[0])#公司领域存入列表
gongsiguimo.append(t.find_elements_by_class_name('list_item_top')[0].find_elements_by_class_name('company')[0].find_elements_by_class_name('industry')[0].text.split('/')[-1])#公司规模存入列表
beizhu.append(t.find_elements_by_class_name('list_item_bot')[0].find_elements_by_class_name('li_b_l')[0].text)#备注存入列表
zhiyeyouhuo.append(t.find_elements_by_class_name('list_item_bot')[0].find_elements_by_class_name('li_b_r')[0].text.replace('“','').replace('”',''))#职业诱惑存入列表
element=browser.find_elements_by_class_name('page_no')[5]#下一页
element.click()#点击下一页
import pandas as pd
date=pd.DataFrame({'职位':zhiwei,'地区':diqu,'薪资':xinzi,'学历 ':xueli,'经验':jingyan,'公司名称':gongsimingcheng,'公司领域':gongsilingyu,'公司规模':gongsiguimo,'备注':beizhu,'职业诱惑':zhiyeyouhuo})
writer=pd.ExcelWriter('拉勾网.xlsx')#写入excel
date.to_excel(writer,'爬虫数据')
writer.save()
5.2数据读入和数据清洗
#数据处理的代码汇总
import pandas as pd#导入pandas
data=pd.read_excel('拉勾网.xlsx')#读取数据
data.head()#获取前五信息
len(data)#获取数据量
data=data.drop_duplicates() #删除重复值
dq=data['地区'].str.split('·').str[0] #根据'.'分割取出地区
xinzizuidi=data['薪资'].str.split('k').str[0].astype(int)#根据k分割取出第一个值,即下限(最低薪资)
xinzizuigao=abs(data['薪资'].str.split('k').str[1].astype(int))#根据k分割取出第二个值,即上限(最高薪资)
avgxinzi=(xinzizuigao+xinzizuidi)/2 #计算平均薪资
guanjianzi=data['备注']#字段备注改为关键字
data1=pd.DataFrame({'职位':data['职位'],'地区':dq,'最低薪资':xinzizuidi,'最高薪资':xinzizuigao,'平均薪资':avgxinzi,'学历':data['学历'],'经验':data['经验'],'公司名称':data['公司名称'],'公司领域':data['公司领域'],'公司规模':data['公司规模'],'关键字':guanjianzi,'职业诱惑':data['职业诱惑']})#重新整理数据
data1.head()#重新输出清洗后的前五条数据
5.3数据可视化分析
#单字段分析
data1['职位'].describe()#有关职位信息
data1['地区'].describe()#有关地区信息
data1['学历'].describe()#有关学历信息
data1['经验'].describe()#有关经验信息
data1['公司规模'].describe()#有关公司规模信息
data1['公司领域'].describe()#有关公司领域信息
data1['职业诱惑'].describe()#有关职业诱惑信息
data1['公司名称'].describe()#有关公司名称信息
data1['最低薪资'].describe()#有关最低薪资信息
data1['最高薪资'].describe()#有关最高薪资信息
data1['职位'].groupby(data1['职位']).count().sort_values(ascending=False)#以职业数量降序输出职位以及数量
data1['地区'].groupby(data1['地区']).count().sort_values(ascending=False)#以地区数量降序输出地区以及数量
data1['学历'].groupby(data1['学历']).count().sort_values(ascending=False)#以学历出现频数降序输出学历以及出现频数
data1['经验'].groupby(data1['经验']).count().sort_values(ascending=False)#以经验出现频数降序输出经验以及出现频数
data1['公司规模'].groupby(data1['公司规模']).count().sort_values(ascending=False)#以公司规模出现频数降序输出公司规模以及出现频数
data1['公司领域'].groupby(data1['公司领域']).count().sort_values(ascending=False)#以公司领域出现频数降序输出公司领域以及出现频数
data1['公司名称'].groupby(data1['公司名称']).count().sort_values(ascending=False)#以公司名称出现频数降序输出公司名称以及出现频数
data1['职业诱惑'].groupby(data1['职业诱惑']).count().sort_values(ascending=False)#以职业诱惑出现频数降序输出职业诱惑以及出现频数
data1['平均薪资'].groupby(data1['平均薪资']).count().sort_values(ascending=False)#平均薪资
data1['最高薪资'].groupby(data1['最高薪资']).count().sort_values(ascending=False)#最高薪资
data1['最低薪资'].groupby(data1['最低薪资']).count().sort_values(ascending=False)#最低薪资
data1['平均薪资'].median()#平均薪资
data1['最高薪资'].median()#最高薪资
data1['最低薪资'].median()#最低薪资
#多字段分析
data1['最低薪资'].groupby(data1['职位']).mean().sort_values(ascending=False)#不同职位的最低薪资
data1['最高薪资'].groupby(data1['职位']).mean().sort_values(ascending=True)#不同职位的最高薪资
data1['平均薪资'].groupby(data1['公司名称']).mean().sort_values(ascending=False)#不同公司的平均薪资
data1['平均薪资'].groupby(data1['经验']).mean().sort_values(ascending=False)#不同工作经验的平均薪资
#绘制职位分布
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 15
x = [1,2,3,4,5]
height =data1['地区'].groupby(data1['地区']).count().sort_values(ascending=False)[:5].values
plt.bar(x, height, width=0.5,color='gold')#绘制柱状图
plt.title('职位所在地区分布')
plt.ylabel('出现频率')
plt.xticks(x, (data1['地区'].groupby(data1['地区']).count().sort_values(ascending=False)[:5].index))
plt.show()
#绘制工作经验要求
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 15
y = [1,2,3,4,5]
width = data1['经验'].groupby(data1['经验']).count().sort_values(ascending=False)[0:].values
plt.barh(y, width, height=0.5)#绘制条形图
plt.title('经验要求')
plt.xlabel('出现频率')
plt.yticks(y, ('经验不限', '经验1-3年 ', '经验5-10年 ', '经验3-5年 ','经验在校应届')) #设置数轴刻度标签
plt.show()
#绘制不同学历要求的平均薪资
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 15
x = [1,2,3,4]
height = data1['平均薪资'].groupby(data1['学历']).mean().sort_values(ascending=False)[0:].values
plt.bar(x, height, width=0.5,color='g')#绘制柱状图
plt.title('不同学历要求的平均薪资')
plt.ylabel('薪资')
plt.xticks(x, (data1['平均薪资'].groupby(data1['学历']).mean().sort_values(ascending=False)[0:].index))
plt.show()
#绘制排名前五职位的平均最低薪资
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 15
y = [1,2,3,4,5]
width = data1['最低薪资'].groupby(data1['职位']).mean().sort_values(ascending=False)[:5].values
plt.barh(y, width, height=0.5,color='orange')#绘制条形图
plt.title('排名前五职位的平均最低薪资')
plt.xlabel('最低薪资')
plt.yticks(y,(data1['最低薪资'].groupby(data1['职位']).mean().sort_values(ascending=False)[:5].index))
plt.show()
#排名前五的职位的平均最高薪资
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 15
x = [1,2,3,4,5]
height = data1['最高薪资'].groupby(data1['职位']).mean().sort_values(ascending=True)[:5].values
plt.bar(x, height, width=0.5,color='brown')#绘制柱状图
plt.title('排名前五的职位的平均最高薪资')
plt.ylabel('薪资')
plt.xticks(x, (data1['最高薪资'].groupby(data1['职位']).mean().sort_values(ascending=True)[:5].index)) #更改刻度标签
plt.xticks(rotation = 90) #将横标签旋转60度
plt.show()
#绘制学历要求
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 15
labels = '本科', '大专 ', '不限', '硕士'
sizes = data1['学历'].groupby(data1['学历']).count().sort_values(ascending=False)[0:].values
explode = (0, 0.1, 0, 0.1) #大专、硕士弹出
plt.pie(sizes,explode=explode,labels=labels,autopct='%1.1f%%',shadow=False,startangle=90)#绘制饼图
plt.axis('equal')#圆形
plt.title('学历要求')
plt.show()
#排名前五公司的平均薪资
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 15
x = [1,2,3,4,5]
height = data1['平均薪资'].groupby(data1['公司名称']).mean().sort_values(ascending=False)[:5].values
plt.bar(x, height, width=0.5,color='yellowgreen')#绘制柱状图
plt.title('排名前五公司的平均薪资')
plt.ylabel('薪资')
plt.xticks(x, (data1['平均薪资'].groupby(data1['公司名称']).mean().sort_values(ascending=False)[:5].index)) #更改刻度标签
plt.xticks(rotation = 60) #将横标签旋转60度
plt.show()
#绘制公司规模
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 15
labels = '50-150人', '15-50人 ', '2000人以上', ' 500-2000人','150-500人'
sizes = data1['公司规模'].groupby(data1['公司规模']).count().sort_values(ascending=False)[0:].values
explode = (0, 0.1, 0, 0.1,0)#15-50人 500-2000人以上弹出
plt.pie(sizes,explode=explode,labels=labels,autopct='%1.1f%%',shadow=False,startangle=90)#绘制饼图
plt.axis('equal') #画圆形
plt.title('公司规模')
plt.show()
#排名前五职业诱惑
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 15
labels = data1['职业诱惑'].groupby(data1['职业诱惑']).count().sort_values(ascending=False)[:5].index[0],
data1['职业诱惑'].groupby(data1['职业诱惑']).count().sort_values(ascending=False)[:5].index[1],
data1['职业诱惑'].groupby(data1['职业诱惑']).count().sort_values(ascending=False)[:5].index[2],
data1['职业诱惑'].groupby(data1['职业诱惑']).count().sort_values(ascending=False)[:5].index[3],
data1['职业诱惑'].groupby(data1['职业诱惑']).count().sort_values(ascending=False)[:5].index[4]
sizes = data1['职业诱惑'].groupby(data1['职业诱惑']).count().sort_values(ascending=False)[:5].index[0]
explode = (0, 0.1, 0, 0.1,0)#第二、四项弹出
plt.pie(sizes,explode=explode,labels=labels,autopct='%1.1f%%',shadow=True,startangle=90)#绘制饼图
plt.axis('equal') #画圆形
plt.title('排名前五职业诱惑')
plt.show()
#绘制岗位需求排名前五公司
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 15
y = [1,2,3,4,5]
width = data1['公司名称'].groupby(data1['公司名称']).count().sort_values(ascending=False)[:5].values
plt.barh(y, width, height=0.5,color='pink')#绘制条形图
plt.title('岗位需求排名前五公司')
plt.xlabel('出现频率')
plt.yticks(y, (data1['公司名称'].groupby(data1['公司名称']).count().sort_values(ascending=False)[:5].index))
plt.show()
#绘制职位需求量
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 15
y = [1,2,3,4,5]
width = data1['职位'].groupby(data1['职位']).count().sort_values(ascending=False)[:5].values
plt.barh(y, width, height=0.5,color='red')#绘制条形图
plt.title('职位需求')
plt.xlabel('需求数')
plt.yticks(y, (data1['职位'].groupby(data1['职位']).count().sort_values(ascending=False)[:5].index))
plt.show()
#绘制不同工作经验的平均薪资
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 15
x = [1,2,3,4,5]
height = data1['平均薪资'].groupby(data1['经验']).mean().sort_values(ascending=False)[0:].values
plt.bar(x, height, width=0.5,color='yellow')#绘制柱状图
plt.title('不同工作经验的平均薪资')
plt.ylabel('薪资')
plt.xticks(x, (data1['平均薪资'].groupby(data1['经验']).mean().sort_values(ascending=False)[0:].index)) #更改刻度标签
plt.xticks(rotation = 30) #将横标签旋转60度
plt.show()