目标检测DETR源码解读(一)
 官方源码地址:https://github.com/facebookresearch/detr
官方源码地址:https://github.com/facebookresearch/detr
数据集COCO2017
标注文件.json,格式: 
目标检测任务中,主要使用“image_id”图片名,“bbox”目标的边界框(left_x, left_y, w, h),"category_id"目标类别。
各字段详细说明,可参考:
【沐枫8023】https://blog.csdn.net/weixin_50727642/article/details/122892088
数据导入(以验证集说明)
1. 创建数据集
导入数据、数据预处理(norm、resize)。如果是训练集,则resize尺度为scales = [480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800]之一。min(w,h)缩放到scales尺度,另一属性做相应变化,从而满足多尺度。
dataset_val = build_dataset(image_set='val', args=args)
# 其中 transforms:
normalize = T.Compose([
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_norm = T.Compose([
T.RandomResize([800], max_size=1333),
normalize,
])
2. DataLoader
data_loader_val = DataLoader(dataset_val, args.batch_size, sampler=sampler_val, drop_last=False, collate_fn=utils.collate_fn, num_workers=args.num_workers)
3. 获取数据
注: train数据直接通过data_loader_train获取,不经过此步骤。
base_ds = get_coco_api_from_dataset(dataset_val)

boxes处理:
- orig_box(x1, y1, x2, y2),ratio_w = resize_w / orig_w,ratio_h = resize_h / orig_h。
- rescale目标框:orig_box * (ratio_w, ratio_h, ratio_w, ratio_h)
- 中心化:(x1, y1, x2, y2)转(center_x, center_y, w, h)
- (resize_w, resize_h)归一化目标框:(center_x, center_y, w, h) / (resize_w, resize_h, resize_w, resize_h)
批处理batch中图像rescale_size:w取每个image缩放后的max(w1,w2,w3, …);h取每个image缩放后的max(h1, h2, h3, …)。
处理通道boxes数据复原:以val集000000000285.jpg为例

反向执行boxes处理步骤:

Code
1、核心部分
- transformer: encoder + decoder
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
- 构建model、评估准则、后处理器
def build(args):
# the `num_classes` naming here is somewhat misleading. 指代分类最大分类id号。
# 例如,如果有 4 个 ID 分别为 1、23、24、56 的类,那么使用 num_classes=57。
# 然后,Detr 将为“no_object”类保留 id 57。
# it indeed corresponds to `max_obj_id + 1`, where max_obj_id
# is the maximum id for a class in your dataset. For example,
# COCO has a max_obj_id of 90, so we pass `num_classes` to be 91.
# As another example, for a dataset that has a single class with id 1,
# you should pass `num_classes` to be 2 (max_obj_id + 1).
# For more details on this, check the following discussion
# https://github.com/facebookresearch/detr/issues/108#issuecomment-650269223
num_classes = 20 if args.dataset_file != 'coco' else 91
if args.dataset_file == "coco_panoptic":
# for panoptic, we just add a num_classes that is large enough to hold
# max_obj_id + 1, but the exact value doesn't really matter
num_classes = 250
device = torch.device(args.device)
backbone = build_backbone(args) # 返回resnet50和position_encoding网络,其中resnet中layer2\3\4层之外不参与梯度更新
transformer = build_transformer(args) # encoder and decoder
model = DETR(
backbone,
transformer,
num_classes=num_classes,
num_queries=args.num_queries,
aux_loss=args.aux_loss,
)
if args.masks: # 针对分割
model = DETRsegm(model, freeze_detr=(args.frozen_weights is not None))
matcher = build_matcher(args) # 匈牙利:an assignment between the targets and the predictions of the network
weight_dict = {'loss_ce': 1, 'loss_bbox': args.bbox_loss_coef}
weight_dict['loss_giou'] = args.giou_loss_coef
if args.masks:
weight_dict["loss_mask"] = args.mask_loss_coef
weight_dict["loss_dice"] = args.dice_loss_coef
# TODO this is a hack
if args.aux_loss:
aux_weight_dict = {}
for i in range(args.dec_layers - 1):
aux_weight_dict.update({k + f'_{i}': v for k, v in weight_dict.items()})
weight_dict.update(aux_weight_dict)
losses = ['labels', 'boxes', 'cardinality']
if args.masks:
losses += ["masks"]
criterion = SetCriterion(num_classes, matcher=matcher, weight_dict=weight_dict,
eos_coef=args.eos_coef, losses=losses) # 评价标准:1)计算GT框和模型输出之间的匈牙利分配 2)监督每对匹配的GT/预测(监督类和框)
criterion.to(device)
postprocessors = {'bbox': PostProcess()} #converts the model's output into the format expected by the coco api
if args.masks:
postprocessors['segm'] = PostProcessSegm()
if args.dataset_file == "coco_panoptic":
is_thing_map = {i: i <= 90 for i in range(201)}
postprocessors["panoptic"] = PostProcessPanoptic(is_thing_map, threshold=0.85)
return model, criterion, postprocessors
- 类DETR
class DETR(nn.Module):
""" This is the DETR module that performs object detection """
def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):
""" Initializes the model.
Parameters:
backbone: torch module of the backbone to be used. See backbone.py
transformer: torch module of the transformer architecture. See transformer.py
num_classes: number of object classes
num_queries: number of object queries, ie detection slot. This is the maximal number of objects
DETR can detect in a single image. For COCO, we recommend 100 queries.
aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used.
"""
super().__init__()
self.num_queries = num_queries
self.transformer = transformer
hidden_dim = transformer.d_model
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
self.query_embed = nn.Embedding(num_queries, hidden_dim)
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
self.backbone = backbone
self.aux_loss = aux_loss
def forward(self, samples: NestedTensor):
""" The forward expects a NestedTensor, which consists of:
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
It returns a dict with the following elements:
- "pred_logits": the classification logits (including no-object) for all queries.
Shape= [batch_size x num_queries x (num_classes + 1)]
- "pred_boxes": The normalized boxes coordinates for all queries, represented as
(center_x, center_y, height, width). These values are normalized in [0, 1],
relative to the size of each individual image (disregarding possible padding).
See PostProcess for information on how to retrieve the unnormalized bounding box.
- "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list of
dictionnaries containing the two above keys for each decoder layer.
"""
if isinstance(samples, (list, torch.Tensor)):
samples = nested_tensor_from_tensor_list(samples)
features, pos = self.backbone(samples) # features为list类型,且元素为NestedTensor; pos为list类型,元素为tensor,torch.Size([2, 256, 28, 38])
src, mask = features[-1].decompose() # 分解
assert mask is not None
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
outputs_class = self.class_embed(hs)
outputs_coord = self.bbox_embed(hs).sigmoid()
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
return out
@torch.jit.unused # 向编译器指示应忽略函数或方法并用引发异常来替换
def _set_aux_loss(self, outputs_class, outputs_coord):
# this is a workaround to make torchscript happy, as torchscript
# doesn't support dictionary with non-homogeneous values, such
# as a dict having both a Tensor and a list.
return [{'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
- 匈牙利匹配
class HungarianMatcher(nn.Module):
"""This class computes an assignment between the targets and the predictions of the network
For efficiency reasons, the targets don't include the no_object. Because of this, in general,
there are more predictions than targets. In this case, we do a 1-to-1 matching of the best predictions,
while the others are un-matched (and thus treated as non-objects).
"""
def __init__(self, cost_class: float = 1, cost_bbox: float = 1, cost_giou: float = 1):
"""Creates the matcher
Params:
cost_class: This is the relative weight of the classification error in the matching cost
cost_bbox: This is the relative weight of the L1 error of the bounding box coordinates in the matching cost
cost_giou: This is the relative weight of the giou loss of the bounding box in the matching cost
"""
super().__init__()
self.cost_class = cost_class
self.cost_bbox = cost_bbox
self.cost_giou = cost_giou
assert cost_class != 0 or cost_bbox != 0 or cost_giou != 0, "all costs cant be 0"
@torch.no_grad() # 指明以下数据不需要计算梯度,不进行反向传播
def forward(self, outputs, targets):
""" Performs the matching
Params:
outputs: This is a dict that contains at least these entries:
"pred_logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits
"pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates
targets: This is a list of targets (len(targets) = batch_size), where each target is a dict containing:
"labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of ground-truth
objects in the target) containing the class labels
"boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates
Returns:
A list of size batch_size, containing tuples of (index_i, index_j) where:
- index_i is the indices of the selected predictions (in order)
- index_j is the indices of the corresponding selected targets (in order)
For each batch element, it holds:
len(index_i) = len(index_j) = min(num_queries, num_target_boxes)
"""
bs, num_queries = outputs["pred_logits"].shape[:2]
# We flatten to compute the cost matrices in a batch
out_prob = outputs["pred_logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes]
out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
# Also concat the target labels and boxes
tgt_ids = torch.cat([v["labels"] for v in targets])
tgt_bbox = torch.cat([v["boxes"] for v in targets])
# Compute the classification cost. Contrary to the loss, we don't use the NLL,
# but approximate it in 1 - proba[target class].
# The 1 is a constant that doesn't change the matching, it can be ommitted.
cost_class = -out_prob[:, tgt_ids]
# Compute the L1 cost between boxes
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1)
# Compute the giou cost betwen boxes
cost_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox))
# Final cost matrix
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
C = C.view(bs, num_queries, -1).cpu()
sizes = [len(v["boxes"]) for v in targets]
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))] # C.split(sizes, -1)[0].shape: torch.Size([2, 100, 20]) ; C.split(sizes, -1)[1].shape=torch.Size([2, 100, 1])
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
- 评估标准:loss
class SetCriterion(nn.Module):
""" This class computes the loss for DETR.
The process happens in two steps:
1) we compute hungarian assignment between ground truth boxes and the outputs of the model
2) we supervise each pair of matched ground-truth / prediction (supervise class and box)
"""
def __init__(self, num_classes, matcher, weight_dict, eos_coef, losses):
""" Create the criterion.
Parameters:
num_classes: number of object categories, omitting the special no-object category
matcher: module able to compute a matching between targets and proposals
weight_dict: dict containing as key the names of the losses and as values their relative weight.
eos_coef: relative classification weight applied to the no-object category
losses: list of all the losses to be applied. See get_loss for list of available losses.
"""
super().__init__()
self.num_classes = num_classes
self.matcher = matcher
self.weight_dict = weight_dict
self.eos_coef = eos_coef
self.losses = losses
empty_weight = torch.ones(self.num_classes + 1)
empty_weight[-1] = self.eos_coef
self.register_buffer('empty_weight', empty_weight)
def loss_labels(self, outputs, targets, indices, num_boxes, log=True):
"""Classification loss (NLL)
targets dicts must contain the key "labels" containing a tensor of dim [nb_target_boxes]
"""
assert 'pred_logits' in outputs
src_logits = outputs['pred_logits']
idx = self._get_src_permutation_idx(indices)
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)])
target_classes = torch.full(src_logits.shape[:2], self.num_classes,
dtype=torch.int64, device=src_logits.device)
target_classes[idx] = target_classes_o
loss_ce = F.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight)
losses = {'loss_ce': loss_ce}
if log:
# TODO this should probably be a separate loss, not hacked in this one here
losses['class_error'] = 100 - accuracy(src_logits[idx], target_classes_o)[0]
return losses
@torch.no_grad() #指明以下数据不需要计算梯度,不进行反向传播
def loss_cardinality(self, outputs, targets, indices, num_boxes):
""" Compute the cardinality error, ie the absolute error in the number of predicted non-empty boxes
This is not really a loss, it is intended for logging purposes only. It doesn't propagate gradients
"""
pred_logits = outputs['pred_logits']
device = pred_logits.device
tgt_lengths = torch.as_tensor([len(v["labels"]) for v in targets], device=device)
# Count the number of predictions that are NOT "no-object" (which is the last class)
card_pred = (pred_logits.argmax(-1) != pred_logits.shape[-1] - 1).sum(1)
card_err = F.l1_loss(card_pred.float(), tgt_lengths.float())
losses = {'cardinality_error': card_err}
return losses
def loss_boxes(self, outputs, targets, indices, num_boxes):
"""Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss
targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]
The target boxes are expected in format (center_x, center_y, w, h), normalized by the image size.
"""
assert 'pred_boxes' in outputs
idx = self._get_src_permutation_idx(indices)
src_boxes = outputs['pred_boxes'][idx]
target_boxes = torch.cat([t['boxes'][i] for t, (_, i) in zip(targets, indices)], dim=0)
loss_bbox = F.l1_loss(src_boxes, target_boxes, reduction='none')
losses = {}
losses['loss_bbox'] = loss_bbox.sum() / num_boxes
loss_giou = 1 - torch.diag(box_ops.generalized_box_iou(
box_ops.box_cxcywh_to_xyxy(src_boxes),
box_ops.box_cxcywh_to_xyxy(target_boxes)))
losses['loss_giou'] = loss_giou.sum() / num_boxes
return losses
def loss_masks(self, outputs, targets, indices, num_boxes):
"""Compute the losses related to the masks: the focal loss and the dice loss.
targets dicts must contain the key "masks" containing a tensor of dim [nb_target_boxes, h, w]
"""
assert "pred_masks" in outputs
src_idx = self._get_src_permutation_idx(indices)
tgt_idx = self._get_tgt_permutation_idx(indices)
src_masks = outputs["pred_masks"]
src_masks = src_masks[src_idx]
masks = [t["masks"] for t in targets]
# TODO use valid to mask invalid areas due to padding in loss
target_masks, valid = nested_tensor_from_tensor_list(masks).decompose()
target_masks = target_masks.to(src_masks)
target_masks = target_masks[tgt_idx]
# upsample predictions to the target size
src_masks = interpolate(src_masks[:, None], size=target_masks.shape[-2:],
mode="bilinear", align_corners=False)
src_masks = src_masks[:, 0].flatten(1)
target_masks = target_masks.flatten(1)
target_masks = target_masks.view(src_masks.shape)
losses = {
"loss_mask": sigmoid_focal_loss(src_masks, target_masks, num_boxes),
"loss_dice": dice_loss(src_masks, target_masks, num_boxes),
}
return losses
def _get_src_permutation_idx(self, indices):
# permute predictions following indices
batch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(indices)])
src_idx = torch.cat([src for (src, _) in indices])
return batch_idx, src_idx
def _get_tgt_permutation_idx(self, indices):
# permute targets following indices
batch_idx = torch.cat([torch.full_like(tgt, i) for i, (_, tgt) in enumerate(indices)])
tgt_idx = torch.cat([tgt for (_, tgt) in indices])
return batch_idx, tgt_idx
def get_loss(self, loss, outputs, targets, indices, num_boxes, **kwargs):
loss_map = {
'labels': self.loss_labels,
'cardinality': self.loss_cardinality,
'boxes': self.loss_boxes,
'masks': self.loss_masks
}
assert loss in loss_map, f'do you really want to compute {loss} loss?'
return loss_map[loss](outputs, targets, indices, num_boxes, **kwargs)
def forward(self, outputs, targets):
""" This performs the loss computation.
Parameters:
outputs: dict of tensors, see the output specification of the model for the format
targets: list of dicts, such that len(targets) == batch_size.
The expected keys in each dict depends on the losses applied, see each loss' doc
"""
outputs_without_aux = {k: v for k, v in outputs.items() if k != 'aux_outputs'}
# Retrieve the matching between the outputs of the last layer and the targets
indices = self.matcher(outputs_without_aux, targets) # giou、匈牙利匹配linear_sum_assignment
# Compute the average number of target boxes accross all nodes, for normalization purposes
num_boxes = sum(len(t["labels"]) for t in targets)
num_boxes = torch.as_tensor([num_boxes], dtype=torch.float, device=next(iter(outputs.values())).device)
if is_dist_avail_and_initialized():
torch.distributed.all_reduce(num_boxes)
num_boxes = torch.clamp(num_boxes / get_world_size(), min=1).item()
# Compute all the requested losses
losses = {}
for loss in self.losses:
losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes))
# In case of auxiliary losses, we repeat this process with the output of each intermediate layer.
if 'aux_outputs' in outputs:
for i, aux_outputs in enumerate(outputs['aux_outputs']):
indices = self.matcher(aux_outputs, targets)
for loss in self.losses:
if loss == 'masks':
# Intermediate masks losses are too costly to compute, we ignore them.
continue
kwargs = {}
if loss == 'labels':
# Logging is enabled only for the last layer
kwargs = {'log': False}
l_dict = self.get_loss(loss, aux_outputs, targets, indices, num_boxes, **kwargs)
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
return losses
2、train
def train_one_epoch(model: torch.nn.Module, criterion: torch.nn.Module,
data_loader: Iterable, optimizer: torch.optim.Optimizer,
device: torch.device, epoch: int, max_norm: float = 0):
model.train()
criterion.train()
metric_logger = utils.MetricLogger(delimiter=" ")
metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value:.6f}'))
metric_logger.add_meter('class_error', utils.SmoothedValue(window_size=1, fmt='{value:.2f}'))
header = 'Epoch: [{}]'.format(epoch)
print_freq = 10
for samples, targets in metric_logger.log_every(data_loader, print_freq, header):
samples = samples.to(device) # NestedTensor类型,成员mask、tensor
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
outputs = model(samples)
loss_dict = criterion(outputs, targets)
weight_dict = criterion.weight_dict
losses = sum(loss_dict[k] * weight_dict[k] for k in loss_dict.keys() if k in weight_dict)
# reduce losses over all GPUs for logging purposes
loss_dict_reduced = utils.reduce_dict(loss_dict)
loss_dict_reduced_unscaled = {f'{k}_unscaled': v
for k, v in loss_dict_reduced.items()}
loss_dict_reduced_scaled = {k: v * weight_dict[k]
for k, v in loss_dict_reduced.items() if k in weight_dict}
losses_reduced_scaled = sum(loss_dict_reduced_scaled.values())
loss_value = losses_reduced_scaled.item()
if not math.isfinite(loss_value):
print("Loss is {}, stopping training".format(loss_value))
print(loss_dict_reduced)
sys.exit(1)
optimizer.zero_grad()
losses.backward()
if max_norm > 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
optimizer.step()
metric_logger.update(loss=loss_value, **loss_dict_reduced_scaled, **loss_dict_reduced_unscaled)
metric_logger.update(class_error=loss_dict_reduced['class_error'])
metric_logger.update(lr=optimizer.param_groups[0]["lr"])
# gather the stats from all processes
metric_logger.synchronize_between_processes()
print("Averaged stats:", metric_logger)
return {k: meter.global_avg for k, meter in metric_logger.meters.items()}
3、evaluate
3.1、模型:

backbone:
- CNN特征features(list类型):NestedTensor—tensors(torch.Size([2, 2048, 28, 38]))、mask
- 位置编码pos(list类型):torch.Size([2, 256, 28, 38])
features, pos = self.backbone(samples)# backbone包含:CNN特征提取模型(如resnet、vgg)和位置编码模型(sine或学习)
transformer:
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0] # 解码特征torch.Size([6, 2, 100, 256])
self.input_proj为conv2d,将特征维度映射到transformer维度。src、mask分别为features[0]、features[1]。
返回transformer解码层的最后解码结果,大小torch.Size([6, 2, 100, 256])。 6表示解码特征维度,即transformer编码解码层数为6;2表示批处理数量;100为作者设定的查询token,即表示最多同时检测 100 个物体;256为特征大小。
预测:
- 类别预测:nn.Linear(hs)
- 坐标预测:MLP(hs).sigmoid()
得:

即最后模型输出结果为out。包含keys-values: - pred_logits:类别标签值;
- pred_boxes:检测框,归一化(center_x, center_y, h, w);
- aux_outputs:(可选),用于辅助损失计算,返回的每个解码层结果,不包含最后一层解码层(已包含在pred_logits, pred_boxes中)。
3.2、特征评估:
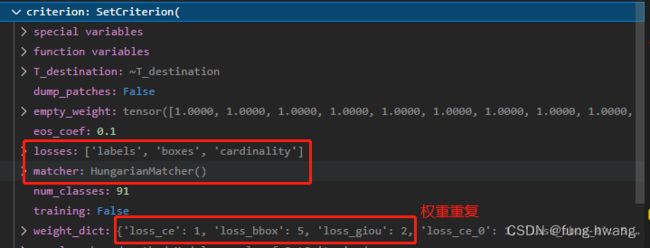
matcher:giou、匈牙利分配,预测(最后一层输出(即out前两个key))与targets.
indices = self.matcher(outputs_without_aux, targets) # giou、匈牙利匹配linear_sum_assignment between the outputs of the last layer and the targets
- 先对pred_logits使用softmax()计算类别概率值,然后根据targets的类别索引取相应类别的概率值,计算分类损失cost_class。
- 计算boxes的L1损失cost_bbox
- 计算boxes giou损失cost_giou
损失矩阵:
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
改进的匈牙利算法分配:
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))] # sizes对应批次中每个图像包含的targets数量,此处批处理大小为2,sizes=[n1,n2]
对批处理中的每个图像predicts和targets的损失矩阵计算分配,返回匹配成功的索引值。linear_sum_assignment执行次数由batch_size决定。c[i]大小为[len(predicts), len(targets)]。
losses:
postprocessors:pred_boxes转原始图像,xyxy格式。
检测结果为:
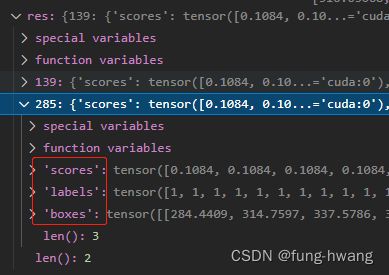
可阅读博客:
https://blog.csdn.net/baidu_36913330/article/details/120495817