Python——词频统计
Python——词频统计
- 问题
- 解答
-
- 方法1(针对英文):
-
- 调用内置collections库
- 手撕代码法
- 方法2(针对中文):
-
- 单个文件
- 多文件批量操作
- 拓展延伸(词云图)
问题
统计每个单词出现的频率
解答
方法1(针对英文):
调用内置collections库
使用collections库的collections.Counter()方法进行词频统计
import collections
songs = 'You raise me up so I can stand on mountains You raise me up to walk on stormy seas I am strong when I am on your shoulders You raise me up To more than I can be'
word_list = songs.split() # 字符串删除空格,输出为列表形式
print(collections.Counter(word_list))
print(dict(collections.Counter(word_list))) # 转换为字典格式,统计完成
输出:
![]()
优点:
调用python内置库,很快速的一个方法进行词频统计
缺点:
大小写不分(以上实例中“To”与“to”被识别为两个单词)
手撕代码法
songs = 'You raise me up so I can stand on mountains You raise me up to walk on stormy seas I am strong when I am on your shoulders You raise me up To more than I can be'
word_list = songs.split() # 字符串删除空格,输出为列表形式
d = {}
for word in word_list:
word = word.lower() # 单词改为小写版
if word in d:
d[word] += 1
else:
d[word] = 1
print(d)
输出:
![]()
方法2(针对中文):
单个文件
中文不同于英文,词是由一个一个汉字组成的,而英文的词与词之间本身就有空格,所以中文的分词需要单独的库才能够实现,常用的是jieba。我们以一份入党申请书进行分词,分词前如下图所示:

通过open打文本文件,使用读模式r,为避免编码错误,指定编码类型为utf-8。读取出来是一个大字符串,将这个大字符串存入变量txt。然后调用jieba进行分词。lcut的意思是切分词后再转换成列表("l"即表示list的首字母)。将切分后的词存入列表words。
import jieba
txt = open("入党申请书.txt", "r", encoding="utf-8").read()
words = jieba.lcut(txt)
print(words)
部分输出如下图:

由上图可见,结果基本是按照我们的汉字使用习惯来区分词的,不能组成词的字则是按单独一个字符串存放的。然后我们就需要将词和对应出现的次数统计出来。此处的代码与上面 “针对英文——手撕代码” 部分的思路核心一致。然后我们根据此出现的次数,降序排序,并查看前15个词的情况。
wordsDict = {} #新建字典用于储存词及词频
for word in words:
if len(word) == 1: #单个的字符不作为词放入字典(其中包括标点)
continue
elif word.isdigit() == True: # 剔除数字
continue
elif word in wordsDict:
wordsDict[word] +=1 #对于重复出现的词,每出现一次,次数增加1
else:
wordsDict[word] =1
wordsDict_seq = sorted(wordsDict.items(),key=lambda x:x[1], reverse=True) #按字典的值降序排序
# wordsDict_seq #此行代码便于从全部中选取不需要的关键词
wordsDict_seq[:15] # 查看前15个

声明:有一些为敏感词汇,为防止被和谐我做了打码处理!
可以看到,有些词并不是我们想要的,比如“一个”、“我要”、“20”。因此需要把这些意义不大的词删除。先定义一个储存要排除的词的列表stopWords,将想排除的词放进去,一般是放出现次数较多,但意义不大的词,可根据实际需要调整。然后遍历这个字典,在检查这些词是否在目标字典wordsDict中,如果在,就将字典中这个词对应的数据删除。
stopWords = ["我们","自己","还有","从不","起到","我要","不仅","一名","各种","半点","这是","没有","一个","自己","才能","随着"]
for word in stopWords:
if word in wordsDict:
del wordsDict[word] #删除对应的词
wordsDict_seq = sorted(wordsDict.items(),key=lambda x:x[1], reverse=True) #按字典的值降序排序
wordsDict_seq[:15]
然后将筛选后的数据转换成DataFrame,并增加列名“词”和“次数”,然后导出为Excel文件。
df = pd.DataFrame(wordsDict_seq,columns=['词','次数'])
df.to_excel("入党申请书.xlsx",index = False) #存为Excel时去掉index索引列
df.head(10)
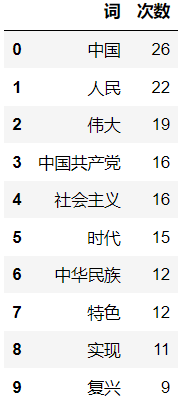
多文件批量操作
import os
# os.getcwd() #返回当前工作目录
path = '入党申请书' #文件所在文件夹,文件夹必须放在当前工作目录中
files = [path+"\\"+i for i in os.listdir(path)] #获取文件夹下的文件名,并拼接完整路径
files

以上,先获取到所有待分析文件的路径。然后逐个进行分析。稍微修改一下上面的程序,很快分析完成。结果如下。
import jieba
import pandas as pd
for file in files:
txt = open(file, "r", encoding="utf-8").read()
words = jieba.lcut(txt)
wordsDict = {} #新建字典用于储存词及词频
for word in words:
if len(word) == 1: #单个的字符不作为词放入字典
continue
elif word in wordsDict:
wordsDict[word] +=1 #对于重复出现的词,每出现一次,次数增加1
else:
wordsDict[word] =1
stopWords = ["我们","自己","20","还有","从不","起到","我要","不仅","一名","各种","半点","这是","没有","一个","自己","才能","随着"]
for word in stopWords:
if word in wordsDict:
del wordsDict[word] #删除对应的词
wordsDict_seq = sorted(wordsDict.items(),key=lambda x:x[1], reverse=True) #按字典的值降序排序
df = pd.DataFrame(wordsDict_seq,columns=['词','次数'])
df.to_excel("词频//{}.xlsx".format(file.split("\\")[1][:-4]),index = False) #存为Excel时去掉index索引列
拓展延伸(词云图)
https://blog.csdn.net/weixin_47282404/article/details/119916124