ADTK 检测器(detector)方法汇总
ADTK 检测器(detector)方法汇总
一、ThresholdAD将每个时间序列值与给定阈值进行比较。
在以下示例中,我们检测温度高于 30C 或低于 15C 的时间点。

方法调用
adtk.detector.ThresholdAD(low=None, high=None)
参数介绍
low(float, optional) -- 低于该值被视为异常的阈值。默认值:None,即下侧没有阈值
high(float, optional) -- 高于该值被视为异常的阈值。默认值:None,即上侧没有阈值。
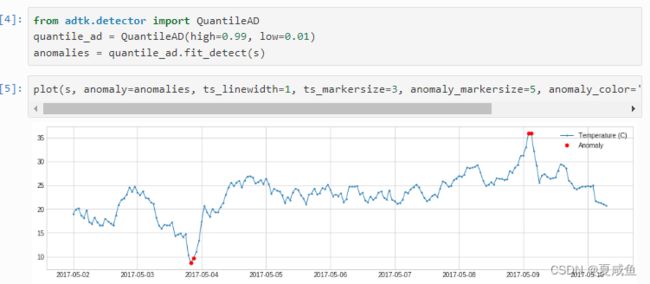
二、QuantileAD将每个时间序列值与历史分位数进行比较。
在以下示例中,我们检测温度高于 99% 百分位或低于 1% 百分位的时间点。
方法调用
adtk.detector.QuantileAD(low=None, high=None)
参数介绍
low(float, optional) -- 历史数据的分位数较低,该值被视为异常。必须介于 0 和 1 之间。
默认值:None,即下限没有阈值。
high(float, optional) -- 历史数据的分位数,超过该分位数的值被视为异常。必须介于 0 和 1 之间。
默认值:None,即上侧没有阈值。
三、InterQuartileRangeAD另一个广泛使用的基于简单历史统计的检测器是基于四分位距 (IQR)。当值超出定义的范围时 [Q1−c×IQR, Q3+c×IQR] 在哪里 IQR=Q3−Q1 是 25% 和 75% 分位数之间的差异。在只有一小部分甚至没有训练数据异常的情况下,此检测器通常优于 QuantileAD。

方法调用
adtk.detector.InterQuartileRangeAD(c=3.0)
参数介绍
c (float, or 2-tuple(float, float), optional) -- 用于确定正常范围界限的因子(Q1-c*IQR 和 Q3+c*IQR 之间)。
如果是元组 (c1, c2),则因子分别用于下限和上限。默认值:3.0。
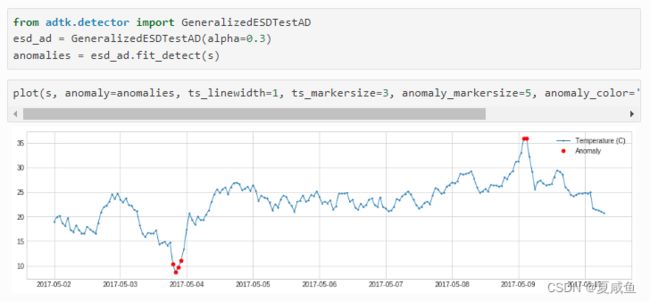
四、GeneralizedESDTestAD基于广义极端学生偏差 (ESD) 测试检测异常。该检测器对历史数据执行广义极端学生偏差 (ESD) 测试 [1, 2] ,并识别正常值与异常值进行训练。为了进行预测,检测器将测试序列中的每个值独立地添加到训练序列的正常值集合中,并对该集合进行广义 ESD 测试(训练序列的所有正常值,加上测试序列的一个值),以评估是否感兴趣的价值是一个异常值。请注意,广义 ESD 测试的一个关键假设是正态值服从近似正态分布。请仅在此假设成立时使用此检测器。
[1] Rosner, Bernard (May 1983), Percentage Points for a Generalized ESD Many-Outlier Procedure, Technometrics, 25(2), pp. 165-172。
[2] https://www.itl.nist.gov/div898/handbook/eda/section3/eda35h3.htm
方法调用
adtk.detector.GeneralizedESDTestAD(α=0.05)
参数介绍
alpha(float, optional) -- 重要性级别,值越大,异常检测算法越敏感。默认值:0.05。
五、PersistAD将每个时间序列值与其先前的值进行比较,根据前一周期的值检测异常。此检测器将时间序列值与其先前时间窗口的值进行比较,如果值与其先前平均值或中值的变化异常大,则将时间点识别为异常。在内部,它被实现为带有转换器DoubleRollingAggregate的管道网络。
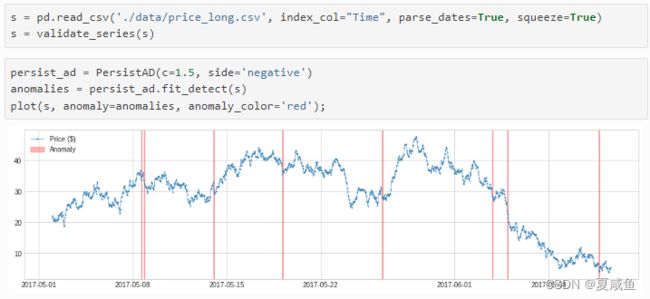
在以下示例中,我们检测到价格的异常积极变化。

默认情况下,PersistAD只检查一个先前的值,这在短期范围内擅长捕捉加性异常,但在长期范围内则不适合。
在以下示例中,它未能在更长的时间范围内捕捉到有意义的价格下跌。
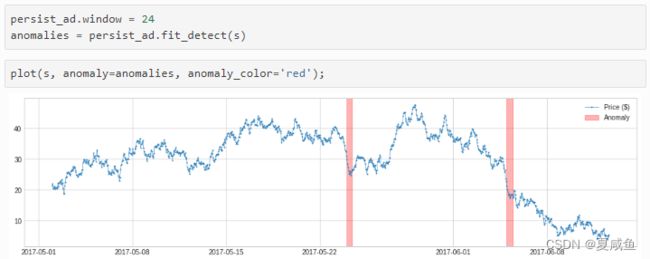
我们可以将参数 window 更改为大于 1 的数字,检测器会将一个值与其前一个时间窗口的中值或平均值进行比较。这将捕捉到中长期尺度的异常变化。
在与上述相同的示例中,它成功地检测到了长期规模的价格下跌。
方法调用
adtk.detector.PersistAD(window=1, c=3.0, side='both', min_periods=None, agg='median')
参数介绍
window(int or str, optional) -- 前一个时间窗口的大小。
如果是int,则为该时间窗口内的时间点个数。
如果是str,则必须能够转换成 pandas Timedelta 对象。
默认值:1。
c (float, optional) -- 用于根据历史四分位数范围确定正常范围界限的因子,与InterQuartileRangeAD中含义相同。
默认值:3.0。
side (str, optional) -- 如果“both”,则检测异常的正负变化;
如果为“positive”,则仅检测异常的正变化,上升趋势异常;
如果为“negative”,则仅检测异常的负变化,下降趋势异常。
默认值:“both”。
min_periods (int, optional) -- 每个窗口中的最小观察次数需要具有该窗口的值,有缺失值的时候需要指定或者填充。
默认值:None,即所有观测值都必须有值。
agg (str, optional) -- 时间窗口的聚合操作,“mean”或“median”。
默认值:“median”。
六、LevelShiftAD通过跟踪彼此相邻的两个滑动时间窗口的中值之间的差异来检测值水平的变化。它对瞬时尖峰不敏感,如果经常发生嘈杂的异常值,它可能是一个不错的选择。在内部,它被实现为带有转换器DoubleRollingAggregate的管道网络。
在以下示例中,我们检测 CPU 使用率的偏移点。
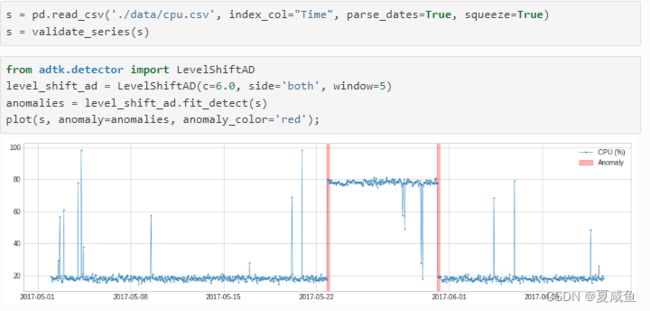
方法调用
adtk.detector.LevelShiftAD(窗口,c=6.0,side='both',min_periods=None )
参数介绍
window(int or str, or 2-tuple of int or str) -- 时间窗口的大小。
如果是int,则为该时间窗口内的时间点个数。
如果是str,则必须能够转换成pandas Timedelta 对象。
如果是 2 元组,则分别定义左右窗口。
c(float, optional) -- 用于根据历史四分位数范围确定正常范围界限的因子。
默认值:6.0。
side(str, optional) -- 如果“both”,则检测异常的正负变化;
如果为“positive”,则仅检测异常的正变化;
如果为“negative”,则仅检测异常的负变化。
默认值:“both”。
min_periods(int, or 2-tuple of int, optional) -- 每个窗口中的最小观察数需要具有该窗口的值。
如果是 2 元组,则分别定义左右窗口。
默认值:None,即所有观测值都必须有值。
七、VolatilityShiftAD通过跟踪彼此相邻的两个滑动时间窗口的标准偏差之间的差异来检测波动率水平的变化,如果两个时间窗口中波动率测量值的差异异常大,则将其间的时间点识别为波动率偏移点。在内部,它被实现为带有转换器DoubleRollingAggregate的管道网络。
在以下示例中,我们检测到表明地震开始的地震振幅波动性的正向偏移。
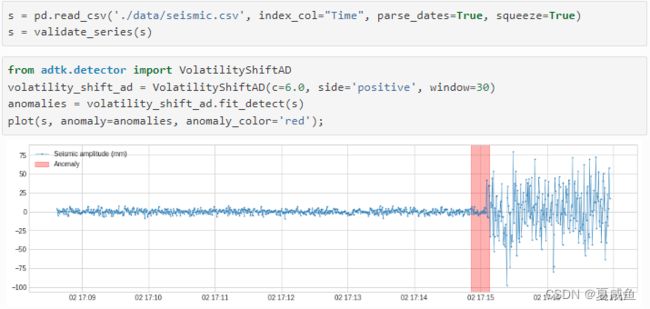
方法调用
adtk.detector.VolatilityShiftAD(window, c=6.0, side='both', min_periods=None, agg='std')
参数介绍
window(int or str, or 2-tuple of int or str) -- 时间窗口的大小。
如果是int,则为该时间窗口内的时间点个数。
如果是str,则必须能够转换成pandas Timedelta 对象。
如果是 2 元组,则分别定义左右窗口。
c(float, optional) -- 用于根据历史四分位数范围确定正常范围界限的因子。
默认值:6.0。
side(str, optional) -- 如果“both”,则检测异常的正负变化;
如果为“positive”,则仅检测异常的正变化;
如果为“negative”,则仅检测异常的负变化。
默认值:“both”。
min_periods(int, or 2-tuple of int, optional) -- 每个窗口中的最小观察数需要具有该窗口的值。
如果是 2 元组,则分别定义左右窗口。
默认值:None,即所有观测值都必须有值。
八、SeasonalAD检测异常违反季节性模式,该检测器使用季节性分解变换器来去除季节性模式(以及可选的趋势),并在季节性分解的残差异常大时将时间点识别为异常。在内部,它被实现为带有转换器 ClassicSeasonalDecomposition的管道网络。
在下面的示例中,我们检测到异常流量,主要发生在重大节假日。

方法调用
adtk.detector.SeasonalAD(freq=None, side='both', c=3.0, trend=False)
参数介绍
freq (int, optional) -- 季节性周期的长度,作为周期中时间点的数量。如果未指定,模型将尝试根据训练序列的自相关来确定它。
默认值: None.
c(float, optional) -- 用于根据历史四分位数范围确定正常范围界限的因子。
默认值:3.0。
side(str, optional) -- 如果“both”,则检测异常的正负变化;
如果为“positive”,则仅检测异常的正变化;
如果为“negative”,则仅检测异常的负变化。
默认值:“both”。
trend(bool, optional) -- 是否在分解过程中提取趋势。
默认值:False.
九、AutoregressionAD检测时间序列中自回归行为的异常变化,许多时间序列具有自回归行为。例如,在线性自回归时间序列中,当前值是多个先前值的线性组合。违反通常的自回归行为可能表明异常。检测器应用回归器来学习时间序列的自回归特性,并在自回归残差异常大时将时间点识别为异常。该方法适用于明确周期性的情况下使用,如周期为一天,采样频率为分,则可以分别设置 n_steps 和 step_size 为 7 和 1440。在内部,它被实现为带有转换器Retrospect和RegressionResidual的管道网络。
对于与上述相同的示例,我们检测到违反交通历史中通常的回归行为。

以下示例是将回归拟合模型更改为随机森林。
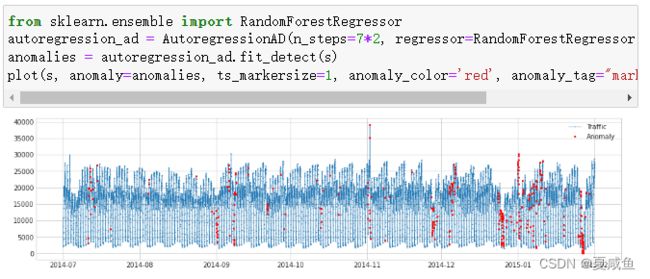
方法调用
adtk.detector.AutoregressionAD(n_steps=1, step_size=1, regressor=None, c=3.0, side='both')
参数介绍
n_steps(int, optional) -- 要包含在模型中的步骤数(以前的值)。
默认值:1。
step_size(int, optional) -- 步长。例如,如果 n_steps=2,step_size=3,X_[t-3] 和 X_[t-6] 将用于预测 X_[t]。
默认值:1。
regressor(object, optional) -- 要使用的回归器。与 scikit-learn 回归器相同,它应该至少具有拟合和预测方法。
如果没有给出,将使用线性回归器。
c(float, optional) -- 用于根据历史四分位数范围确定正常范围界限的因子。
默认值:3.0。
side(str, optional) -- 如果“both”,则检测异常的正负变化;
如果为“positive”,则仅检测异常的正变化;
如果为“negative”,则仅检测异常的负变化。
默认值:“both”。
十、MinClusterDetector将多元时间序列视为高维空间中的独立点,将它们划分为集群,并将最小集群中的值标识为异常。检测器使用聚类模型进行聚类,如果时间点属于最小聚类,则将其识别为异常。这可能有助于捕获高维空间中的异常值。
在以下示例中,我们检测到发电机速度与发电量之间关系的异常变化。违反正则关系表示设备故障。
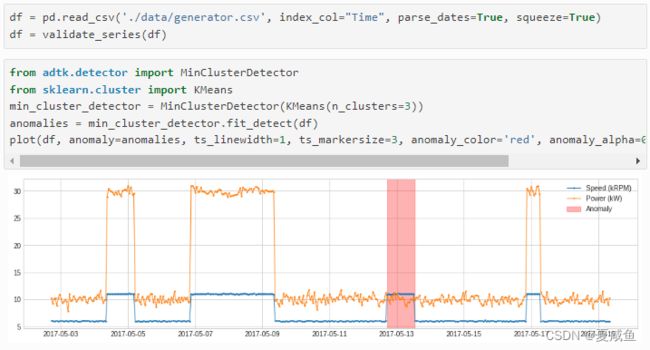
方法调用
adtk.detector.MinClusterDetector(model)
参数介绍
model(object) -- 用于对时间序列值进行聚类的聚类模型。与 scikit-learn 中的聚类模型相同,
该模型应至少具有拟合方法和预测方法。predict方法应该返回一个集群标签数组。
十一、OutlierDetector执行多变量与时间无关的异常值检测并将异常值识别为异常。多元异常值检测算法可以是 scikit-learn 或其他遵循相同 API 的包中的算法。
对于与上面相同的示例,我们使用 OutlierDetector scikit-learn 局部异常值因子模型。

方法调用
adtk.detector.OutlierDetector(model)
参数介绍
model (object) -- 要使用的异常值检测模型。与 scikit-learn 中的异常值检测模型
(例如 EllipticEnvelope、IsolationForest、LocalOutlierFactor)相同,
该模型应至少具有fit_predict 方法,或fit和predict方法。
fit_predict或predict方法应返回异常值指标组,其中异常值用 -1 标记。
十二、RegressionAD通过跟踪回归误差检测多元序列之间通常关系的异常违反,该检测器执行回归以建立目标序列与其余序列之间的关系,并在回归残差异常大时将时间点识别为异常。在内部,它被实现为带有转换器的RegressionResidual的管道网络。
对于与上述相同的示例,我们应用RegressionAD线性回归模型。
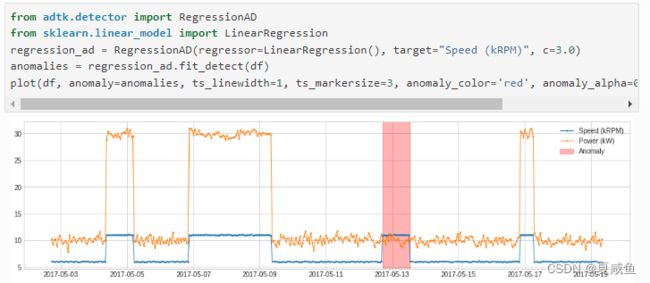
方法调用
adtk.detector.RegressionAD(regressor, target, c=3.0, side='both')
参数介绍
target(str) -- 被视为目标变量的列的名称。
regressor(object, optional) -- 要使用的回归器。与 scikit-learn 回归器相同,它应该至少具有拟合和预测方法。
如果没有给出,将使用线性回归器。
c(float, optional) -- 用于根据历史四分位数范围确定正常范围界限的因子。
默认值:3.0。
side(str, optional) -- 如果“both”,则检测异常的正负变化;
如果为“positive”,则仅检测异常的正变化;
如果为“negative”,则仅检测异常的负变化。
默认值:“both”。
十三、PcaAD对多变量时间序列(每个时间点作为高维空间中的一个向量)执行主成分分析 (PCA) 并跟踪这些向量的重构误差。该检测器对多元时间序列进行主成分分析(每个时间点都被视为高维空间中的一个点),测量每个时间点的重构误差,并且当重构误差超过异常区间时,识别此时间点为异常点。当正常点应该位于较低等级的流形上而异常点不是时,此检测器可能会有所帮助。在内部,它被实现为带有转换器 PcaReconstructionError的管道。
我们应用PcaAD与上述相同的示例。
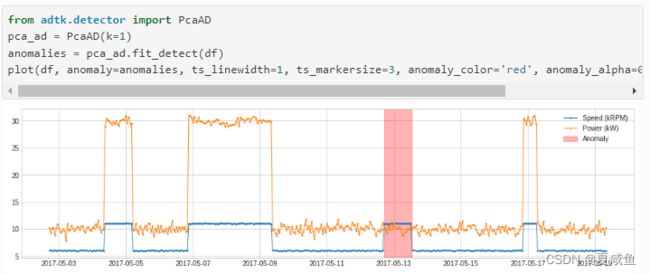
方法调用
adtk.detector.PcaAD(k=1 ,c=5.0)
参数介绍
k(int, optional) -- 要使用的主成分数。默认值:1。
c(float, optional) -- 用于根据历史四分位数范围确定正常范围界限的因子。默认值:5.0。
十四、定制探测器:CustomizedDetector1D(单变量检测器)和CustomizedDetectorHD(多变量检测器)帮助用户将功能转换为可以(Pipeline例如由对象)用作其他检测器对象的定制检测器对象。
在以下示例中,我们检测到何时产生的功率(以 kW 为单位)小于发电机速度(以 kRPM 为单位)的 1.2 倍。

方法调用
adtk.detector.CustomizedDetector1D(detect_func, detect_func_params=None, fit_func=None, fit_func_params=None)
adtk.detector.CustomizedDetectorHD(detect_func, detect_func_params=None,fit_func=None, fit_func_params=None)
参数介绍
detect_func(function) -- 从单/多变量时间序列中检测异常的函数。
第一个输入参数必须是 pandas Series/DataFrame,
可选输入参数可以通过参数detect_func_params和 fit_func的输出接受,
输出必须是与输入具有相同索引的二进制 pandas Series。
detect_func_params(dict, optional) -- detect_func的参数。
默认值:None。
fit_func(function, optional) -- 具有单/多变量时间序列的detect_func函数训练参数。
第一个输入参数必须是 pandas 系列,可选输入参数可以通过参数fit_func_params接受,
输出必须是可以被detect_func用作参数的 dict。
默认值:无。
fit_func_params(dict, optional) -- fit_func的参数。
默认值:无。