论文阅读《Incremental Few-Shot Object Detection》
Background & Motivation
目标检测领域一阶段和二阶段的网络都不是增量学习的模式,本文的方法是基于一阶段的 CentreNet。小样本分类任务的方法各式各样,其思想应该是小样本检测任务的创新源泉。文章提出了一个增量学习的范式(Incremental Few-Shot Detection,iFSD):
- 使用 Base 数据完成对模型的预训练。
- 这个模型部署到设备上后,设备应该能随时接收数据量很少的 Novel 数据完成增量训练,并不影响其在 Base 数据上的精度。
- 这个增量训练不应需要太多的计算、存储以及内存开销,因为这个设备往往很 source-limited。
之前没有增量学习的模式的小样本检测方法,之前的做法会带来巨大且重复的计算开销,同时牵涉到了数据隐私的问题。
选择 CentreNet 很重要的一个原因是其遵循了 class-specific 的范式:
For few-shot object detection in particular, a key merit of CentreNet is that each individual class maintains its own prediction heatmap and makes independent detection by activation thresholding.
因此很容易将 Novel 数据的特征通过增量学习添加到模型中,Novel 数据中的类别应该是 order-free 并且 combination-insensitive。CentreNet 的结构图如下所示:

将传统的检测任务变为中心点和 bounding box 长宽的回归任务,模型的检测输出是 2D 的热力图,不需要产生 region proposal。
Methodology
OpeN-ended Centre nEt(ONCE)
文中提出的模型叫做 ONCE,将 CentreNet 解耦成 class-generic 和 class-specific 的模块,先用 Base 数据来训练 class-generic 模块,之后用元学习的方法训练 class-specific 模块。训练完成后,class code generator(其输出可以看作是一个卷积核)使得 ONCE 可以用反向传播的方法增量地学习在测试阶段输入的 Novel 数据,而不需要像之前一样再将 Base 数据一起送入模型重新微调。
ONCE 由三部分组成:Feature extractor(class-generic)、Object locator 和 Class code generator,Class code generator 用一批输入的 support 来产生 Object locator 的参数。其网络结构如下:

Stage I: Feature Extractor Learning
用 Base 数据完成对 feature extractor f() 和 object locator h() 的预训练,这个阶段 class code generator g() 的参数是固定值从别的地方 copy 过来的,之后的训练中 feature extractor 保持冻结。
The locator learned in this stage is a regular CentreNet locator, which will be discarded in stage II, but will be used at the test time for the base classes.
the class code generator weights are initialised by cloning the weights of the encoder part of the feature extractor.
这个阶段训练的公式为:
![]()
其中 m 是 f() 输出的特征图,ck 是 h() 中用到的可学习的卷积核,k 是 Base 数据的类别数,得到的 Yk 是热力图的预测。
定位物体的做法是首先找到那些局部“峰值”点(xi,yi),这些点是 Yk 中激活值比周围8领域要高的点。bounding box 的预测值是:

其中 бxi 和 бyi 是偏移量的预测,hi 和 wi 是大小的预测。使用 L1 回归损失。
The class code parameters c learned for detection above are fixed parameters for base-classes only.
Stage II: Class Code Generator Learning
g() 采用元学习的方法训练,先从标签集中抽样出几个类别,根据这几个类别构建 support set 和 query set,都包含了标注。后者用来产生 class code,也即卷积核:
![]()
之后用这个卷积核对 query set 的特征图进行卷积,得到热力图:
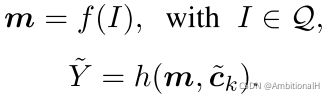
只更新 g() 的参数,使用 L1 损失,其中 Z 是 gt 的热力图:
![]()
Meta Testing: Enrolling New Classes
输入的 Novel 数据每一类包含少量的带标签数据,这个阶段的测试分为几步:
- 用 g() 获得 Novel 数据中每一类对应的卷积核。
- 用 f() 计算 Novel 数据的特征。
- 用 h() 计算 Novel 数据的热力图。
- 计算出 bounding box。
- 根据热力图输出每一类最终的检测结果。
This process applies for the base classes except that Step 1 is no longer needed since their class codes are already obtained from the training stage I.
Experiment
Non-Incremental Few-Shot Detection

非增量学习情况下精度不高。
For model training, we used 10 shots per novel class along with all the base class training data.
Incremental Few-Shot Object Detection
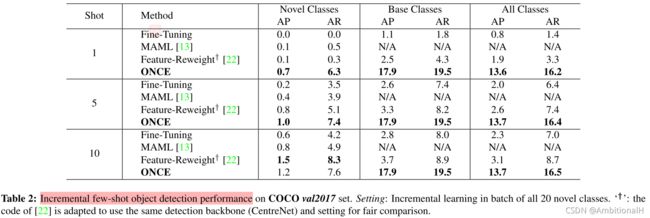
上图采用的按批次加入 Novel 数据的方法,比如一次加入一个类。可以看到 Novel 类数据的精度不高,因为这是全新并且具有挑战性的任务(增量学习)。但是本文方法的贡献在于使增量学习迈出了第一步,下图的精度是一次将20个 Novel 类的数据直接加入到训练中:

Conclusion
看的第一篇增量学习的小样本目标检测文章,用 Novel 类数据当卷积核的思想与这篇文章有点类似。由于不了解 CentreNet,所以这篇文章的有些细节还不是很清楚。