基于深度学习的表面缺陷检测方法综述
题目: 基于深度学习的表面缺陷检测方法综述
作者: 陶显,侯伟,徐德
收稿日期: 2019-11-27
网络首发日期: 2020-04-02
1 缺陷检测问题的定义
缺陷的定义: 在机器视觉任务中, 缺陷倾向于是人类经验上的概念, 而不是一个纯粹的数学定义。
第
一种有监督的方法体现在利用标记了标签(包括类别、矩形框或逐像素等)的缺陷图像输入到网络中进行训练. 此时\缺陷"意味着标记过的区域或者图像。
第二种是无监督的缺陷检测方法, 通常只需要正常无缺陷样本进行网络训练, 也被称为one-class learning. 该方法更关注无缺陷(即正常样本)特征, 当缺陷检测过程中发现没有见过的特征(异常特征)时, 即认为检测出缺陷. 此时\缺陷"意味着异常, 因此该方法也被称作异常检测(Anomaly Detection).
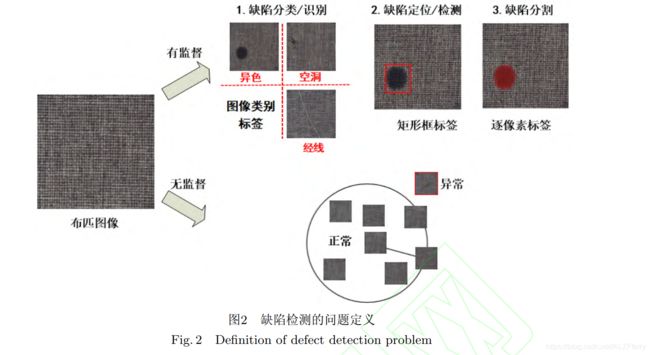
缺陷检测的定义: 对比计算机视觉中明确的分类、检测和分割任务, 缺陷检测的需求非常笼统. 实际上, 其需求可以划分为三个不同的层次: \缺陷是什么"、 \缺陷在哪里"和\缺陷是多少". 第一阶段\缺陷是什么"对应计算机视觉中的分类任务, 如图2中分类三种缺陷类别: 异色、空洞和经线, 这一阶段的任务可以被称为\缺陷分类", 仅仅给出图像的类别信息. 第二阶段\缺陷在哪里"对应计算机视
觉中的定位任务, 这一阶段的缺陷定位才是严格意义上的检测. 不仅获取图像中存在哪些类型的缺陷,而且也给出缺陷的具体位置, 如图2中将异色缺陷用矩形框标记出来. 第三阶段\缺陷是多少"对应计算机视觉中的分割任务, 如图2中缺陷分割的区域所示,将缺陷逐像素从背景中分割出来, 并能进一步得到缺陷的长度、面积、位置等等一系列信息, 这些信息能辅助产品高一级的质量评估, 例如优劣等级的判断. 虽然缺陷检测的三个阶段的功能需求和目标不同, 但实际上三个阶段互相包含且能相互转换. 例如第二阶段\缺陷定位"包含第一阶段\缺陷分类"这
一过程, 第三阶段\缺陷分割"同时也能完成第二阶段\缺陷定位". 第一阶段\缺陷分类"也能通过一些方法实现第二阶段和第三阶段的目标. 因此, 在后文还是按照传统工业习惯统称为缺陷检测, 只是在针对不同网络结构和目标功能时, 才有所区分.
2 表面缺陷检测深度学习方法
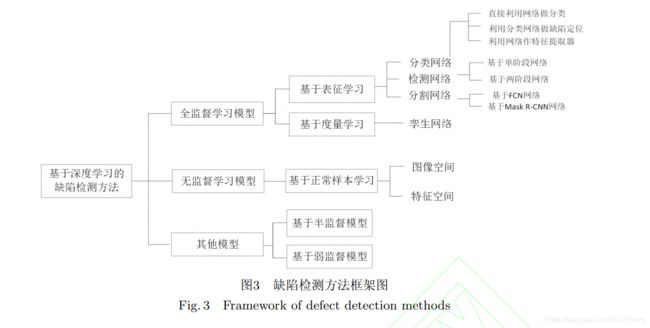
本节总结概述基于深度学习的表面缺陷检测方法. 如图3所示, 依据数据标签的不同, 将其整体分为全监督学习模型、无监督学习模型和其他方法(半监督学习模型和弱监督学习模型). 在全监督模型中, 依据输入图像方式和损失函数的差异, 分为基于表征学习和度量学习的方法. 在表征学习中, 根据网络结构的不同可以进一步细分为分类网络、检测网络和分割网络. 目前大量的研究工作都是着眼于全监督学习方向, 但无监督学习同样是一个值得研究的方向. 从图3中可以看出, 本文按照每类方法的处理特点又细分为若干种不同的子方法。
这个问题可以回答得很简单:是否有监督(supervised),就看输入数据是否有标签(label)。输入数据有标签,则为有监督学习,没标签则为无监督学习。
2.1 表征学习
现阶段大部分基于深度学习的表面缺陷检测是基于有监督的表征学习方法. 表征学习的本质是将缺陷检测问题看作计算机视觉中的分类任务, 包括粗粒度的图像标签分类或区域分类, 以及最精细的像素分类.
2.1.1 分类网络
在真实的工业生产中, 检测对象形状、尺寸、纹理、颜色、背景、布局和成像光照的巨大差异使复杂环境下的缺陷分类成为一项艰巨的任务. 由于CNN强大的特征提取能力, 采用基于CNN的分类网络目前已成为表面缺陷分类中最常用的模式.通常CNN分类网络的特征提取部分由级联的卷积层+pooling层组成, 后面连接全连接层(或averagepooling层)+softmax结构用于分类. 一般来说,现有
表面缺陷分类的网络常常采用计算机视觉中现成的网络结构, 包括AlexNet[5], VGG[6], GoogLeNet[7],ResNet[8], DenseNet[9], SENet[10], Shu†eNet[11],
MobileNet[12] 等. 或者针对实际问题搭建简易的网络结构, 通过输入一张测试图像到分类网络中, 网络输出该图像的类别和其类别的置信度. 依据分类网络方法实现任务的差异, 我们将其细分为三个小类:直接利用网络做分类、利用网络做缺陷定位和利用网络作为特征提取器.
a.直接利用网络做分类
1)原图分类即直接将收集的完整缺陷图像放入网络进行学习训练
2)定位ROI后分类.它在许多工业应用中较为常见. 通常来说, 针对获取到的整张图像中, 我们常常只关注某个固定区域中是否存在缺陷, 因此往往预先获取到感兴趣的区域(ROI), 然后将ROI输入网络进行缺陷类别的判断.
3)多类别分类.
当待分类的缺陷类型超过2类时, 常规的缺陷分类网络与原图分类方法一样, 即网络的输出节点为缺陷类型的数目+1(包括正常类别). 但多类别分类方法往往先采用一个基础网络进行缺陷与正常样本二分类, 然后在同一个网络上共享特征提取部分, 修改或者增加缺陷类别的分类分支. 通过该方式相当于给后续的多目标缺陷分类网络准备了一个预训练权重参数,这个权重参数是通过正常样本与缺陷样本之间二分类训练得到
b.利用网络做缺陷定位
一般认为, 分类网络只能完成图像标签级别的分类, 实际上结合不同的技巧和方式, 分类网络也可以实现缺陷的定位与逐像素的分类. 根据采用的手段不同, 它进一步可以分为滑动窗口、热力图(heatmap)和多任务学习网络三种形式.
1)滑动窗口
是最简单和直观的实现缺陷粗定位的方法. 一般工业表面缺陷检测处理的图像分辨率较大, 通过较小尺寸的窗口在原始图像上进行冗余滑动, 将滑动窗口中的图像输入到分类网络中进行缺陷识别.最后将所有的滑动窗口进行连接, 即可获得缺陷粗定位的结果.

2)热力图(heatmap)
是一种反映图像中各区域重要性程度的图像, 颜色越深代表越重要.在缺陷检测领域, 热力图中颜色越深的区域代表其属于缺陷的概率越大。在热力图基础上运用Otsu大津法[34]和图割算法进一步得到准确的缺陷轮廓区域. 在计算机视觉领域, 常采用CAM(Class Activation Mapping)[35]和GradCAM[36]方法获得heatmap,
. 3)多任务学习网络.
单纯的分类网络不加其他技巧的话, 一般只能实现图像级别的分类. 因此, 为了精细定位缺陷位置, 往往设计的网络会加上额外的分割分支, 两个分支共享特征提取的backbone结果, 这样网络一般有分类和分割两个输出, 构成多任务学习网络
c.利用网络做特征提取器
在早期基于深度学习的缺陷分类方法中, 不少文献利用CNN特征提取的强大功能, 先将图像输入到预训练网络中获取图像表征特征, 再将获取的特征输入到常规的机器学习分类器(例如SVM等)中进行分类.

2.1.2 检测网络
目标定位是计算机视觉领域中最基本的任务之一, 同时它也是和传统意义上缺陷检测最接近的任务, 其目的是获得目标精准的位置和类别信息. 目前, 基于深度学习的目标检测方法层出不穷, 一般来说, 基于深度学习的缺陷检测网络从
结构上可以划分为: 以Faster R-CNN[43]为代表的两阶段(two stage)网络和以SSD[44]或YOLO[45]为代表的一阶段(one stage)网络. 两者的主要差异在于两阶段网络需要首先生成可能包含缺陷的候选框(proposal), 然后在进一步进行目标检测. 一阶段网络直接利用网络中提取的特征来预测缺陷的位置和类别
a.基于两阶段的缺陷检测网络
两 阶 段 检 测 网 络(Faster R-CNN)的 基 本 流程是首先通过backbone网络获取输入图像的特征图, 然后利用RPN计算锚框(anchor box)置信度, 获 取proposal. 然 后 对proposal区 域 的 特 征图进行ROIpooling 后输入网络, 通过对初步检测结果进行精细调整, 最终得到缺陷的定位和类 别 结 果.
b.基于单阶段的缺陷检测网络
单阶段检测网络分为SSD和YOLO两种, 两者都是利用整张图作为网络的输入, 直接在输出层回归bounding box(边界框)的位置及其所属的类别.SSD的特点在于引入了特征金字塔检测方式, 从不同尺度的特征图中来预测目标位置与类别. 它使用6个不同特征图检测不同尺度的目标, 一般底层特征图用于预测小目标, 高层特征图预测大目标.
2.1.3 分割网络
分割网络将表面缺陷检测任务转化为缺陷与正常区域的语义分割甚至实例分割问题, 它不但能精细分割出缺陷区域, 而且可以获取缺陷的位置、类别以及相应的几何属性(包括长度、宽度、面积、轮廓、中心等). 按照分割功能的区别, 其大致可以分为: FCN[60](Fully Convolutional Networks)方法和Mask R-CNN[61]方法两种
a.FCN方法
全卷积神经网络(FCN)是图像语义分割的基础, 目前几乎所有的语义分割模型都是基于FCN.FCN首先利用卷积操作对输入图像进行特征提取和编码, 然后再通过反卷积操作或上采样将特征图逐渐恢复到输入图像尺寸大小. 依据FCN网络结构的差异, 其缺陷分割方法可以进一步细分为常规FCN、Unet[62]和SegNet[63]三种方法.1)常规FCN方法. Wang[64]等人提出一种基于FCN的
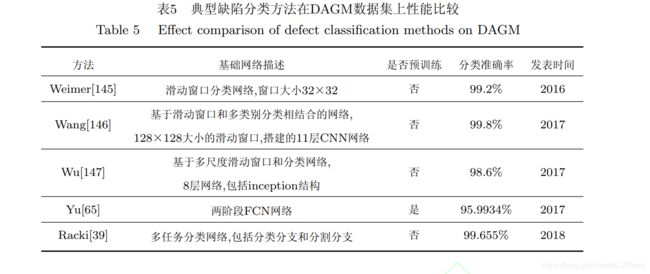
轮胎X射线图像缺陷分割方法, 相比于原始FCN方法, 文章通过融合多尺度采样层的特征图来细化分割轮胎图像中的缺陷. Yu等人[65]提出了一个基于FCN的两阶段表面缺陷分割模型, 第一阶段采用一个轻量级的FCN快速获取粗略缺陷区域, 然后第一阶段的输出作为第二阶段FCN的输入用于细化缺陷分割结果, 该方法在公共数据集DAGM2007上取得了95.9934%的平均像素准确率. Dung等人[66]采用基于VGG16编码器的FCN网络对混凝土表面裂缝进行分割, 其平均像素准确率达到90%.
2)Unet方法. Unet不仅是一种经典的FCN结构, 同时也是典型的编码器-解码器(encoder-decoder)结构. 它的特点在于引入了跳层连接,将编码阶段的特征图与解码阶段的特征图进行融合, 有利于分割细节的恢复.
3)SegNet方法. 它也是一种经典的编码器-解码器结构. 其特点在于解码器中的上采样操作利用了编码器中最大池化操作的索引
b.Mask R-CNN方法
Mask R-CNN是目前最常用的图像实例分割方法之一, 可以被看作是一种基于检测和分割网络相结合的多任务学习方法. 当多个同类型缺陷存在粘连或重叠时, 实例分割能将单个缺陷进行分离并进一步统计缺陷数目, 然而语义分割往往将多个同类型缺陷当作整体进行处理. 目前大部分文献都是直接将Mask R-CNN框架应用于缺陷分割, 例如路面缺陷分割[82]、工业制造缺陷[83]、螺栓紧固件缺陷[84]和皮革表面缺陷[85].相比分类和检测网络方法, 分割方法在缺陷信息获取上有其优势. 但它与检测网络一样, 需要大量的标注数据, 其标注信息是逐像素, 往往花费大量的标注精力和成本
2.2 度量学习
度量学习是使用深度学习直接学习输入的相似性度量. 在缺陷分类任务中, 往往采用孪生网络(Siamese network)进行度量学习. 不同于表征学习输入单张图像转化为分类任务, 孪生网络的输入通常为两张或多张成对图像, 通过网络学习出输入图片的相似度, 判断其是否属于同一类. 孪生网络损失函数的核心思想是让相似的输入距离尽可能地小,不同类别的输入距离尽可能地大
**孪生网络:**一般原始孪生网络的输入是两张成对的图像, 网络的\连体"是通过共享权值来实现的.Kim等人[86]设计了一个基于CNN结构的孪生网络对钢表面缺陷图像进行分类, 首先将两张图像输入到共享权值的CNN中完成特征提取, 然后利用基于相似度函数的对比损失计算两个特征之间的差异程度.
2.3 正常样本学习
目前最常用于表面缺陷检测的无监督学习模型是基于正常样本学习的方法. 由于只需要正常无缺陷样本进行网络训练, 该方法也常被称为one-classlearning. 正常样本学习的网络只接受正常(无缺陷)样本进行训练, 使得其具备强大的正常样本分布的重建和判别能力. 因此, 当网络输入的样本存在缺陷时, 往往会产生与正常样本不同的结果. 相比于有监督学习模型, 它能够检测到偏离预期的模式或没有见过的模式, 这些模式都可以被称为缺陷或者异常. 依据处理空间的不同, 本文将该缺陷检测方法分为基于图像空间和特征空间两种. 通常该方法采用的网络模型为自编码器(autoencoder, AE)和GAN
2.3.1 基于图像空间
基于图像空间的方法是在图像空间上对缺陷进行检测. 因此, 该方法不仅能实现图像级别的分类和识别, 也可以获取到缺陷的具体位置. 该方法常用的手段有两种, 1)利用网络实现样本重建与补全.其原理类似去噪编码器, 当输入任意样本图像到网络中, 都可以得到其重建后对应的正常(无缺陷)样本, 因此, 网络可以看作具备自动修复或者补全缺陷区域的能力. 用输入图像分别减去这些重建或修复图像可以获得残差图像, 这些残差图像也被称为重建误差. 它能作为判断待检测样本是否异常的指. 当重建误差过大时, 可以认为输入图像认为存在缺陷,差异过大的区域即为缺陷区域. 当重建误差很小, 即认为输入图像是正常样本.
2)利用网络实现异常区域分类. 这类网络通常采用GAN的判别器. 该方法原理是训练生成对抗网络GAN以生成类似于正常表面图像的伪图像, 这意味着训练好的GAN可以在潜在特征空间中很好地学习正常样本图像. 因此, GAN的判别器可以自然地用作分类器, 用于分类缺陷和正常样本.
2.3.2 基于特征空间
基于特征空间的方法是在特征空间中, 通过正常样本与缺陷样本特征分布之间的差异来进行缺陷检测,特征之间差异也叫做异常分数, 当异常分数高于某个值, 即可认为出现缺陷
2.4 弱监督与半监督学习
这个问题可以回答得很简单:是否有监督(supervised),就看输入数据是否有标签(label)。输入数据有标签,则为有监督学习,没标签则为无监督学习。
通常基于***弱监督***的方法是指采用图像级别类别标注(弱标签)来获取分割/定位级别的检测效果.
***半监督***学习通常会使用大量的未标记数据和少部分有标签的数据用于表面缺陷检测模型的训练
3 关键问题
目前深度学习方法广泛应用在各种计算机视觉
任务中, 表面缺陷检测一般被看作是其在工业领域
的具体应用. 在传统的认识中, 深度学习方法无法
直接应用在表面缺陷检测中的原因是因为在真实的
工业环境中, 所能提供的工业缺陷样本太少. 相比
于ImageNet数据集中1400多万张样本数据, 表面缺
陷检测中面临的最关键的问题是小样本问题, 在很
多真实的工业场景下甚至只有几张或几十张缺陷图
片. 实际上, 针对于工业表面缺陷检测中关键问题之
一的小样本问题, 目前有4种不同的解决方式:
1)数据扩增、合成与生成.最常用的缺陷图像扩
增方法是对原始缺陷样本采用镜像、旋转、平移、扭
曲、滤波、对比度调整等多种图像处理操作来获取
更多的样本
2)网络预训练或迁移学习.一般来说, 采用小
样本来训练深度学习网络很容易导致过拟合, 因此
基于预训练网络或迁移学习的方法是目前针对样
本中最常用的方法之一
3)合理的网络结构设计.通过设计合理的网络
结构也可以大大减少样本的需求.
4)采用无监督与半监督模型方法.这两种方式
都可以减少样本的需求. 在无监督模型中, 只利用正
常样本进行训练, 因此不需要缺陷样本. 半监督方法
可以利用没有标注的样本来解决小样本情况下的网
络训练难题.
3.2 实时性
基于深度学习的缺陷检测方法在工业应用中
包括三个主要环节: 数据标注、模型训练与模型推
断. 在实际工业应用中的实时性更关注模型推断这
一环节. 目前大多数缺陷检测方法都集中在分类或
识别的准确性上, 而很少关注模型推断的效率.
3.3 与传统基于图像处理的缺陷检测方法对比

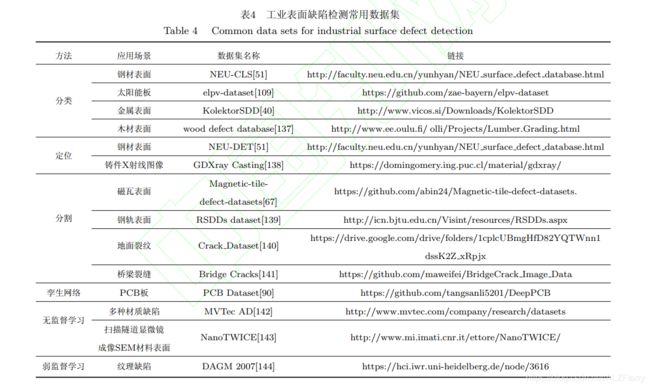
4 缺陷检测数据集
5 总结与展望
缺陷检测是一个宽泛的应用领域, 具体包括缺陷分类、缺陷定位和缺陷分割等环节, 相比于传统图像处理方法分多个步骤和环节处理缺陷检测任务,基于深度学习的方法将其统一为端到端的特征提取和分类. 虽然表面缺陷检测技术已经不断地从学术研究走向成熟的工业应用, 但是依然有一些需要解决的问题.
1)网络结构设计:
文章第二部分综述的方法大部分具有不同的网络结构, 这些网络也都是人工进行设计, 从模型包含多少层到每一层的详细结构都是一个漫长设计和调参的过程. 这种网络很难说是最优的, 只能说这些手工设计的网络在当前缺陷检测数据集上大致满足需求. 类似于传统手工设计的缺陷检测特征, 例如文献[16]中提到的三种手工特征(KAZE[17]、 SIFT[18]、 SURF[19]), 相比CNN网络自身学到的特征, 其缺陷分类效果逊色不少. 因此,随着Auto machine learning和Neural ArchitectureSearch技术的兴起, 相信会有越来越多机器搜寻和自动生成的网络逐步替代人工设计的网络, 这些网络不仅能够大幅度的减少手工设计网络参数, 同时在检测的正确率上也会领先.
2)网络训练学习:
人工在进行工业缺陷的目视检测时, 很难收集到所有缺陷类型的样本, 很多时候只有良品数据(正样本). 然而目前大部分基于深度学习的表面缺陷检测方法是基于大量的缺陷样本的有监督学习. 深度学习的网络学习是一个\黑匣子",需要大量标注好的训练样本端到端进行学习, 可解释性差. 因此, 如何利用类脑(受脑启发的)计算与仿人视觉认知模型这些先验知识来指导缺陷检测网络的训练和学习, 也是一个值得思考的方向.
3)异域数据联邦学习:
单个表面缺陷检测数据集往往都很少, 虽然小样本问题可以通过文章第三部分介绍的方法缓解相关问题, 但是实际上不同工业行业和领域中, 真实工业表面缺陷数据是非常多的, 一些缺陷种类也是共同的, 例如划痕广泛存在金属、液晶屏幕、太阳能电池板、玻璃等等一系列材质表面. 同时, 人类也会将统一类型的缺陷进行标记,并不会因为检测领域的不同而产生差异. 但是由于涉及隐私敏感, 不同检测领域之间数据并没有有效结合和利用. 如何利用不同工业领域的缺陷数据集来进行网络学习, 也是表面缺陷检测的一种重要研究方向. 因此, 基于异域数据的联邦学习将会成为一个趋势, 它能够打破不同应用场景之间的壁垒, 充分学习不同领域之间数据来提升网络性能.
6 结论
随着人工智能技术的发展, 目前基于机器视觉的表面缺陷检测的研究焦点已经从经典的图像处理和机器学习方法转移到深度学习方法, 在很多工业场景下解决了以往传统方法无法解决的难题. 本文系统的总结、对比和分析了深度学习算法在表面缺陷检测领域的研究进展, 同时对基于深度学习的表面缺陷检测的研究趋势进行了展望, 以期为相关研究人员提供详实和有效参考.