深度学习经典网络解析图像分类篇(七):ResNet
深度学习经典网络解析图像分类篇(七):ResNet
- 1.背景介绍
- 2. 网络过深导致的问题
-
- 为什么随着网络层级越深,模型效果却变差了呢?
- 3. ResNet
-
- 3.1ResNet概要
- 3.2 ResNet网络结构
-
- 3.2.1 残差结构
- 3.2.2 ResNet中卷积块设计
- 3.2.3 不同跳跃连接
- 3.3 RenNet创新点
- 4.1 总结
ResNet论文翻译详情见我的博客:
深度学习论文阅读(五):ResNet《Deep Residual Learning for Image Recognition》
1.背景介绍
如果说你对深度学习略有了解,那你一定听过大名鼎鼎的ResNet,正所谓ResNet 一出,谁与争锋?现如今2022年,依旧作为各大CV任务的backbone,比如ResNet-50、ResNet-101等。ResNet是2015年的ImageNet大规模视觉识别竞赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)中获得了图像分类和物体识别的冠军,是中国人何恺明、张祥雨、任少卿、孙剑在微软亚洲研究院(AI黄埔军校)的研究成果。

网络出自论文《Deep Residual Learning for Image Recognition》我们都知道增加网络的宽度和深度可以很好的提高网络的性能,深的网络一般都比浅的的网络效果好,比如说一个深的网络A和一个浅的网络B,那A的性能至少都能跟B一样,为什么呢?因为就算我们把B的网络参数全部迁移到A的前面几层,而A后面的层只是做一个等价的映射,就达到了B网络的一样的效果。一个比较好的例子就是VGG,该网络就是在AlexNet的基础上通过增加网络深度大幅度提高了网络性能。
对于原来的网络,如果简单地增加深度,会导致梯度弥散或梯度爆炸。对于该问题的解决方法是正则化初始化和中间的正则化层(Batch Normalization),这样的话可以训练几十层的网络。
虽然通过上述方法能够训练了,但是又会出现另一个问题,就是退化问题,网络层数增加,但是在训练集上的准确率却饱和甚至下降了。这个不能解释为过拟合,因为过拟合应该表现为在训练集上表现更好才对。退化问题说明了深度网络不能很简单地被很好地优化。作者通过实验:通过浅层网络等同映射构造深层模型,结果深层模型并没有比浅层网络有等同或更低的错误率,推断退化问题可能是因为深层的网络并不是那么好训练,也就是求解器很难去利用多层网络拟合同等函数。
2. 网络过深导致的问题

从上面两个图可以看出,在网络很深的时候(56层相比20层),模型效果却越来越差了(误差率越高),并不是网络越深越好。
通过实验可以发现:随着网络层级的不断增加,模型精度不断得到提升,而当网络层级增加到一定的数目以后,训练精度和测试精度迅速下降,这说明当网络变得很深以后,深度网络就变得更加难以训练了。

为什么随着网络层级越深,模型效果却变差了呢?
假设一个神经网络如下图所示:

根据神经网络反向传播的原理,先通过正向传播计算出output,然后与样本比较得出误差值损失Etotal
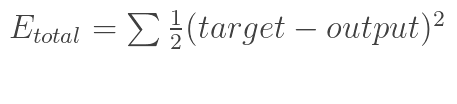
根据误差损失结果,利用“链式法则”求偏导,使结果误差反向传播从而得出权重w调整的梯度。下图是输出结果到隐含层的反向传播过程(隐含层到输入层的反向传播过程也是类似):

通过不断迭代,对参数矩阵进行不断调整后,使得输出结果的误差值更小,使输出结果与事实更加接近。
从上面的过程可以看出,神经网络在反向传播过程中要不断地传播梯度,而当网络层数加深时,梯度在传播过程中会逐渐消失(假如采用Sigmoid函数,对于幅度为1的信号,每向后传递一层,梯度就衰减为原来的0.25,层数越多,衰减越厉害),导致无法对前面网络层的权重进行有效的调整。
那么有没有一种方法既能加深网络层数,又能解决梯度消失问题、又能提升模型精度呢?
3. ResNet
3.1ResNet概要
ResNet的核心是残差结构,我们知道网络越深的时候,提取到的不同层次的信息会越多,但随着网络层数的增加,网络很大程度可能出现梯度消失和梯度爆炸情况,loss不减反增,传统对应的解决方案则是数据的初始化,批标准化(batch normlization)和正则化,但是这样虽然解决了梯度传播的问题,深度加深了,可以训练十几或者几十层的网络,却带来了另外的问题,就是网络性能的退化问题,深度加深了,错误率却上升了,并且确定这不是过拟合导致的,因为过拟合训练集的准确率应该很高。因此为解决随着深度加深,性能不退化,残差网络就出现了,深度残差网络用来解决性能退化问题,其同时也解决了梯度问题,更使得网络的性能也提升了,用了残差结构的网络深度可以到达几百层。
3.2 ResNet网络结构
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如图5所示。变化主要体现在ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。从图5中可以看到,ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示feature map数量发生了改变。图5展示的34-layer的ResNet,还可以构建更深的网络如表1所示。从表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1,一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。


3.2.1 残差结构
ResNet引入了残差网络结构(residual network),通过这种残差网络结构,可以把网络层弄的很深,并且最终的分类效果也非常好,残差网络的基本结构如下图所示,很明显,该图是带有跳跃结构的:

为什么残差链接有良好的效果?可以使更深的网络训练?
首先我们要知道我们为什么会提出残差链接,因为在深度网络的反向传播中,通过导数的多次迭代,可能最后返回的梯度更新会很小(趋近于0),这样网络的权重就没有办法进行更新,从而导致权重无法训练。
反向传播以及梯度的计算详情见我的博客:深度学习相关概念:计算图与反向传播
有了残差链接之后假设卷积层学习的变换为() ,残差结构的输出是() ,则有:
那计算梯度(求导)的时候:
无论’()为多大,总的梯度至少有个1,从而保证了梯度的回传,网络得到更好的训练。
也就是说:
- 残差结构能够避免普通的卷积层堆叠存在信息丢失问题,保证前向信息流的顺畅。
- 残差结构能够应对梯度反传过程中的梯度消失问题,保证反向梯度流的通顺。
3.2.2 ResNet中卷积块设计
ResNet使用两种残差单元,如下图所示。左图对应的是浅层网络,而右图对应的是深层网络。对于短路连接,当输入和输出维度一致时,可以直接将输入加到输出上。但是当维度不一致时(对应的是维度增加一倍),这就不能直接相加。有两种策略:(1)采用zero-padding增加维度,此时一般要先做一个下采样,可以采用strde=2的pooling,这样不会增加参数(2)采用新的映射(projection shortcut),一般采用1x1的卷积,这样会增加参数,也会增加计算量。短路连接除了直接使用恒等映射,当然都可以采用projection shortcut。

两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),其目的主要就是为了降低参数的数目。左图是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,右图是第一个1x1的卷积把256维通道降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,右图的参数数量比左图减少了16.94倍,因此,右图的主要目的就是为了减少参数量,从而减少计算量。对于常规的ResNet,可以用于34层或者更少的网络中(左图);对于更深的网络(如101层),则使用右图,其目的是减少计算和参数量。
3.2.3 不同跳跃连接

从上图图可以看出,怎么有一些跳跃链接是实线,有一些是虚线,有什么区别呢?
因为经过跳跃链接后,H(x)=F(x)+x,如果F(x)和x的通道相同,则可直接相加,那么通道不同怎么相加呢。上图中的实线、虚线就是为了区分这两种情况的:
- 实线的Connection部分,表示通道相同,如上图的第一个粉色矩形和第三个粉色矩形,都是3x3x64的特征图,由于通道相同,所以采用计算方式为() = () +
- 虚线的的Connection部分,表示通道不同,如上图的第一个绿色矩形和第三个绿色矩形,分别是3x3x64和3x3x128的特征图,通道不同,采用的计算方式为() = () + w,其中w是卷积操作,用来调整x维度的。
3.3 RenNet创新点
- 提出了一种残差模块,通过堆叠残差模块可以构建任意 深度的神经网络,而不会出现“退化”现象。
- 提出了批归一化方法来对抗梯度消失,该方法降低了网 络训练过程对于权重初始化的依赖;
- 提出了一种针对ReLU激活函数的初始化方法;
4.1 总结
为什么残差网络性能这么好?
一种典型的解释:残差网络可以看作是一种集成模型!
残差网络可以看作由多个小模型集成起来,那么集成模型它的集成,它的性能肯定就强。这是一个例子,这是一个残差结构,他等同于是这样的几个网络来联合起来的。

如上图所示,残差结构展开后可以看作4种子网络的集成,既然有多个子网络进行求和,不是原来的一个网络,他学习到的特征就更多,所以它的分类性能就会很好。这是对ResNet的一个理解,当然研究人员们也去验证了这个事情,既然是集成网络。那我随便干掉一个是不是就不应该影响整个网络的性能?是ResNet这个网络特别神奇的地方,你把网络中间随便干掉几层,你把它拼接起来,他还是能很好的工作。但是如果你把VGG中间一层干掉,比如说你把第五个卷积层给你干掉,你把他的拼接起来,他们能工作吗?很显然不行,因为它后面的层是依赖于前面层的特征的学习的时候都是有这种依赖关系,你把它去掉就不行了。
而ResNet可能在前三层在学一个特征在学习某一个东西,后面三层的学另一个事情,你即使把前三层干掉了,请通过后面上层,他也能进行分类。所以这就是这个残差网络的这个优势,至于这个网络,他真正在学好了以后,他可能只选择了其中子网络组网,可能这两个网络可能这里面的权值都是重要的,其他的子网络都给踢掉,所以这也是有可能的,所以残差网络,他自己在组合,我到底哪几哪几层要增强同一类信息,那些都是他自己来决定。他有可能第二层继续干第一层的事情,觉得第一层处理的好,我继续加强。第三层继续干第二层的事情,第四层继续干第三层的事情,这就类似于VGG,后面的层在前层的基础上不断深化,但是有可能到第五层他有可能觉得这几个特征已经到这了,再加强对分类性能影响不大了。我要转向去加强另外一个信号,对它进行更细粒度的区分,第六层又是转向加强别的信号。那么这样的话,可以直接使用前四层的网络,我可以做分类,或者甚至用第五层到第十层,他可能学到另一种模式,它也可以进行分类,你把前四层干掉,把输入接到第五层后面,他也可能也可以工作。(个人感觉有点像Dropout)