深度学习经典网络(2)VGG网络结构详解
0.介绍
深度神经网络一般由卷积部分和全连接部分构成。卷积部分一般包含卷积(可以有多个不同尺寸的核级联组成)、池化、Dropout等,其中Dropout层必须放在池化之后。全连接部分一般最多包含2到3个全连接,最后通过Softmax得到分类结果,由于全连接层参数量大,现在倾向于尽可能的少用或者不用全连接层。神经网络的发展趋势是考虑使用更小的过滤器,如1*1,3*3等;网络的深度更深(2012年AlexNet 8层,2014年VGG 19层、GoogLeNet 22层,2015年ResNet 152层);减少全连接层的使用,以及越来越复杂的网络结构,如GoogLeNet引入的Inception模块结构。
VGGNet获得2014年ImageNet亚军,VGG是牛津大学 Visual Geometry Group(视觉几何组)的缩写,以研究机构命名。
VGG 在深度学习领域中非常有名,很多人 fine-tune 的时候都是下载 VGG 的预训练过的权重模型,然后在次基础上进行迁移学习。VGG 是 ImageNet 2014 年目标定位竞赛的第一名,图像分类竞赛的第二名,需要注意的是,图像分类竞赛的第一名是大名鼎鼎的 GoogLeNet,那么为什么人们更愿意使用第二名的 VGG 呢?
因为 VGG 够简单
VGG 最大的特点就是它在之前的网络模型上,通过比较彻底地采用 3x3 尺寸的卷积核来堆叠神经网络,从而加深整个神经网络的层级。
VGG 不是横空出世
我们都知道,最早的卷积神经网络 LeNet,但 2012 年 Krizhevsk 在 ISRVC 上使用的 AlexNet 一战成名,极大鼓舞了世人对神经网络的研究,后续人们不断在 AlexNet 的架构上进行改良,并且成绩也越来越好。
VGG在AlexNet基础上做了改进,整个网络全部使用了同样大小的3*3卷积核尺寸和2*2最大池化尺寸,网络结果简洁。一系列VGG模型的结构图:
VGG论文给出了一个非常振奋人心的结论:卷积神经网络的深度增加和小卷积核的使用对网络的最终分类识别效果有很大的作用。记得在AlexNet论文中,也做了最后指出了网络深度的对最终的分类结果有很大的作用。这篇论文则更加直接的论证了这一结论。
对于 AlexNet 的改进的手段有 2 个:
- 在第一层卷积层上采用感受野更小的的尺寸,和更小的 stride。
- 在 AlexNet 的基础上加深它的卷积层数量。
总结:
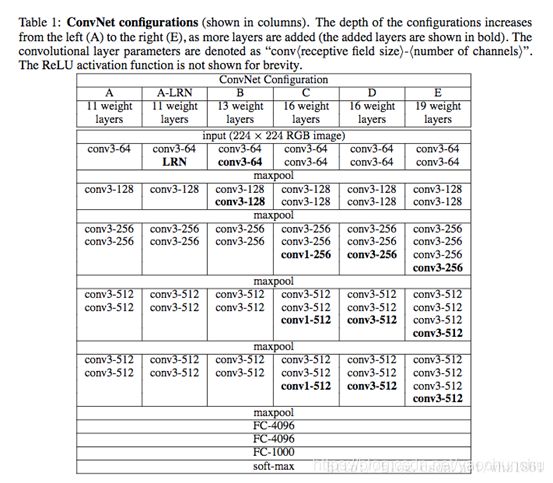
VGG16包含16层,VGG19包含19层。一系列的VGG在最后三层的全连接层上完全一样,整体结构上都包含5组卷积层,卷积层之后跟一个MaxPool。所不同的是5组卷积层中包含的级联的卷积层越来越多。
AlexNet中每层卷积层中只包含一个卷积,卷积核的大小是7*7,。在VGGNet中每层卷积层中包含2~4个卷积操作,卷积核的大小是3*3,卷积步长是1,池化核是2*2,步长为2,。VGGNet最明显的改进就是降低了卷积核的尺寸,增加了卷积的层数。
使用多个较小卷积核的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面作者认为相当于进行了更多的非线性映射,增加了网络的拟合表达能力。
VGGNet的图片预处理
VGG的输入224*224的RGB图像,预处理就是每一个像素减去了均值。
VGG的多尺度训练
VGGNet使用了Multi-Scale的方法做数据增强,将原始图像缩放到不同尺寸S,然后再随机裁切224×224的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。实践中,作者令S在[256,512]这个区间内取值,使用Multi-Scale获得多个版本的数据,并将多个版本的数据合在一起进行训练。VGG作者在尝试使用LRN之后认为LRN的作用不大,还导致了内存消耗和计算时间增加。
虽然网络层数加深,但VGG在训练的过程中比AlexNet收敛的要快一些,主要因为:
(1)使用小卷积核和更深的网络进行的正则化;
(2)在特定的层使用了预训练得到的数据进行参数的初始化。对于较浅的网络,如网络A,可以直接使用随机数进行随机初始化,而对于比较深的网络,则使用前面已经训练好的较浅的网络中的参数值对其前几层的卷积层和最后的全连接层进行初始化。
VGGNet改进点总结
一、使用了更小的3*3卷积核,和更深的网络。两个3*3卷积核的堆叠相对于5*5卷积核的视野,三个3*3卷积核的堆叠相当于7*7卷积核的视野。这样一方面可以有更少的参数(3个堆叠的3*3结构只有7*7结构参数数量的(3*3*3)/(7*7)=55%);另一方面拥有更多的非线性变换,增加了CNN对特征的学习能力。
二、在VGGNet的卷积结构中,引入1*1的卷积核,在不影响输入输出维度的情况下,引入非线性变换,增加网络的表达能力,降低计算量。
三、训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。
四、采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率
1.网络结构
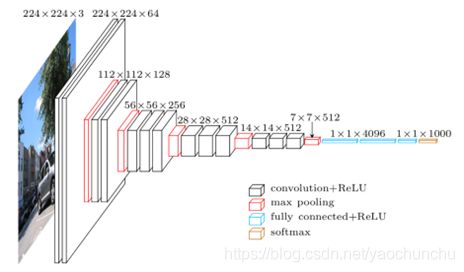
论文指出:
- VGG不仅在ILSVRC的分类和检测任务中取得了the state-of-the-art的精度
- 在其他数据集上也具有很好的推广能力
结构Architecture
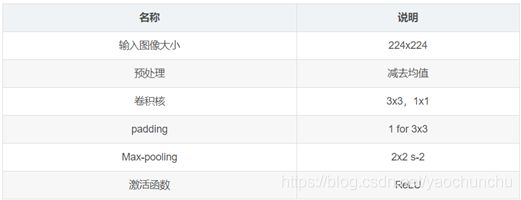
说明:
1x1卷积核:降维,增加非线性性
3x3卷积核:多个卷积核叠加,增加空间感受野,减少参数
论文中,作者指出,虽然LRN(Local Response Normalisation)在AlexNet对最终结果起到了作用,但在VGG网络中没有效果,并且该操作会增加内存和计算,从而作者在更深的网络结构中,没有使用该操作。
VGG网络结构
VGG 的细节之 3x3 卷积核
VGG 和 AlexNet 最大的不同就是 VGG 用大量的 3x3 卷积核替换了 AlexNet 的卷积核。
3x3 卷积核是能够感受到上下、左右、重点的最小的感受野尺寸。
2 个 3x3 的卷积核叠加,它们的感受野等同于 1 个 5x5 的卷积核,3 个叠加后,它们的感受野等同于 1 个 7x7 的效果
既然,感受野的大小是一样的,那么用 3x3 有什么好处呢?
答案有 2,一是参数更少,二是层数加深了。
现在解释参数变少的问题。(为什么是C^2还是感觉有问题,我理解就是C)
假设现在有 3 层 3x3 卷积核堆叠的卷积层,卷积核的通道是 C 个,那么它的参数总数是 3x(3Cx3C) = 27C^2。同样和它感受野大小一样的一个卷积层,卷积核是 7x7 的尺寸,通道也是 C 个,那么它的参数总数就是 49C^2。通过计算很容易得出结论,3x3 卷积方案的参数数量比 7x7 方案少了 81% 多,并且它的层级还加深了。
VGG 的细节之 1x1 卷积核
堆叠后的 3x3 卷积层可以对比之前的常规网络的基础上,减少参数数量,而加深网络。但是,如果我们还需要加深网络,怎么办呢?堆叠更多的的卷积层,但有 2 个选择。
选择 1:继续堆叠 3x3 的卷积层,比如连续堆叠 4 层或者以上。
选择 2:在 3x3 的卷积层后面堆叠一层 1x1 的卷积层。
1x1 卷积核的好处是不改变感受野的情况下,进行升维和降维,同时也加深了网络的深度。
VGG 其它细节汇总
大家一般会听说 VGG-16 和 VGG-19 这两个网络,其中 VGG-16 更受欢迎。
16 和 19 对应的是网络中包含权重的层级数,如卷积层和全连接层,大家可以仔细观察文章前面贴的配置图信息。
所有的 VGG 网络中,卷积核的 stride 是 1,padding 是 1.
max-pooling 的滑动窗口大小是 2x2 ,stride 也是 2.
VGG 不同配置的表现
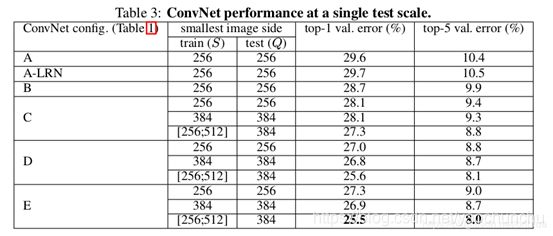
VGG-19 表现的结果自然最好。但是,VGG-19 的参数比 VGG-16 的参数多了好多。所以,综合考虑大家似乎更喜欢 VGG-16。
VGG网络参数

Q1: 为什么3个3x3的卷积可以代替7x7的卷积?
- 3个3x3的卷积,在卷积层之后添加使用了3个非线性激活函数,增加了非线性表达能力,使得分割平面更具有可分性。同时使得网络层次加深了。
- 减少参数个数。对于C个通道的单个卷积核,7x7含有参数7x7×C, 3个3x3的参数个数为3x3x3×C,49/27≈1.81 参数大大减少。
2个3×3卷积核叠加可以当做1个5×5卷积核,3个3×3卷积核叠加可以当做1个7×7卷积核。但是大的卷积核拆成3×3叠加之后可以进一步减少参数个数,但是实际的感受野不会发生改变。
Q2: 1x1卷积核的作用
- 在不影响感受野的情况下,增加一个1×1卷积就是增加网络深度。通常一个卷积过程包括一个激活函数,比如 Sigmoid 和 ReLU。增加了非线性,这将增强神经网络的表达能力
- 降维/升维,主要拿来减少需要参数的个数
Q3: 网络深度对结果的影响(同年google也独立发布了深度为22层的网络GoogleNet)
- VGG与GoogleNet模型都很深
- 都采用了小卷积
- VGG只采用3x3,而GoogleNet采用1x1, 3x3, 5x5,模型更加复杂(模型开始采用了很大的卷积核,来降低后面卷积层的计算)
模型框架
VGG采用了min-batch gradient descent去优化multinomial logistic regression objective
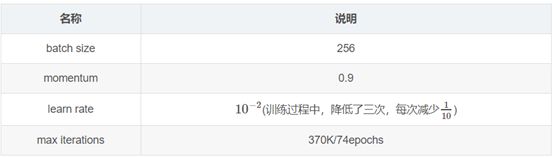
正则化方法:

说明:虽然模型的参数和深度相比AlexNet有了很大的增加,但是模型的训练迭代次数却要求更少:
a)正则化+小卷积核,
b)特定层的预初始化
初始化策略:
- 首先,随机初始化网络结构A(A的深度较浅)
- 利用A的网络参数,给其他的模型进行初始化(初始化前4层卷积+全连接层,其他的层采用正态分布随机初始化,mean=0,var=10−2, biases = 0)最后证明,即使随机初始化所有的层,模型也能训练的很好
训练输入:
采用随机裁剪的方式,获取固定大小224x224的输入图像。并且采用了随机水平镜像和随机平移图像通道来丰富数据。
Training image size: 令S为图像的最小边,如果最小边S=224,则直接在图像上进行224x224区域随机裁剪,这时相当于裁剪后的图像能够几乎覆盖全部的图像信息;如果最小边S>>224,那么做完224x224区域随机裁剪后,每张裁剪图,只能覆盖原图的一小部分内容。
Multi-scale训练
首先对原始图片进行等比例缩放,使得短边要大于224,然后在图片上随机提取224x224窗口,进行训练。由于物体尺度变化多样,所以多尺度(Multi-scale)可以更好地识别物体。
方法1:在不同的尺度下,训练多个分类器:
参数S为短边长。训练S=256和S=384两个分类器,其中S=384的分类器用S=256的进行初始化,且将步长调为10e-3
方法2:直接训练一个分类器,每次数据输入的时候,每张图片被重新缩放,缩放的短边S随机从[256,512]中选择一个。
Multi-scale其实本身不是一个新概念,学过图像处理的同学都知道,图像处理中已经有这个概念了,我们学过图像金字塔,那就是一种多分辨率操作
只不过VGG网络第一次在神经网络的训练过程中提出也要来搞多尺寸。目的是为了提取更多的特征信息。像后来做分割的网络如DeepLab也采用了图像金字塔的操作。
注:因为训练数据的输入为224x224,从而图像的最小边S,不应该小于224
数据生成方式:首先对图像进行放缩变换,将图像的最小边缩放到S大小,然后

预测方式:作者考虑了两种预测方式:
- 方法1: multi-crop,即对图像进行多样本的随机裁剪,然后通过网络预测每一个样本的结构,最终对所有结果平均
- 方法2: densely, 利用FCN的思想,将原图直接送到网络进行预测,将最后的全连接层改为1x1的卷积,这样最后可以得出一个预测的score map,再对结果求平均
上述两种方法分析:
- Szegedy et al.在2014年得出multi-crops相对于FCN效果要好
- multi-crops相当于对于dense evaluatio的补充,原因在于,两者在边界的处理方式不同:multi-crop相当于padding补充0值,而dense evaluation相当于padding补充了相邻的像素值,并且增大了感受野
- multi-crop存在重复计算带来的效率的问题
最终,作者认为相对于multi-crop的在精度上的提高并不能弥补其在计算量上的消耗,但作者最后还是对比了这两种方法的效果
效果分析
单尺度
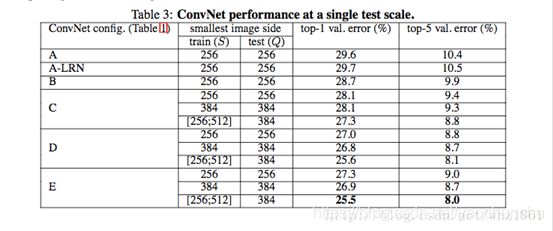
结论:
- 模型E(VGG19)的效果最好,即网络越深,效果越好
- 同一种模型,随机scale jittering的效果好于固定S大小的256,384两种尺度,即scale jittering数据增强能更准确的提取图像多尺度信息
多尺度
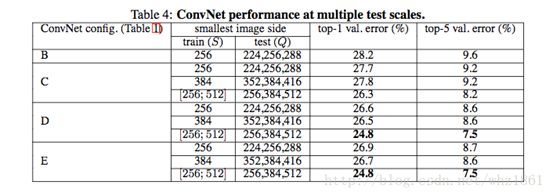
结论:
- 对比单尺度预测,多尺度综合预测,能够提升预测的精度
- 同单尺度预测,多尺度预测也证明了scale jittering的作用
多尺度裁剪
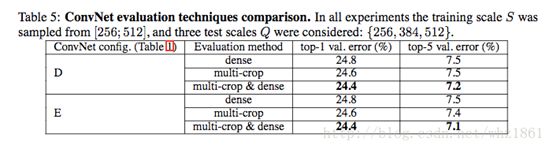
结论:
- 数据生成方式multi-crop效果略优于dense,但作者上文也提高,精度的提高不足以弥补计算上的损失
- multi-crop于dense方法结合的效果最后,也证明了作者的猜想:multi-crop和dense两种方法互为补充
模型融合
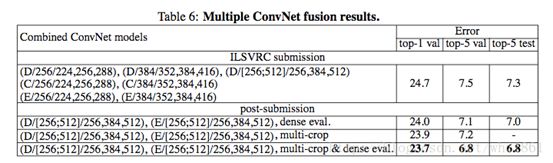
结论:
- 通过多种模型融合输出最终的预测结果,能达到the state-of-the-art的效果
对比
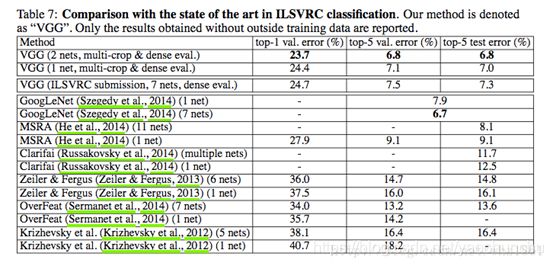
结论:
- 与其他模型对比发现,VGG也能达到非常好的效果。
总结
作者指出,VGG模型不仅能够在大规模数据集上的分类效果很好,其在其他数据集上的推广能力也非常出色。
参考文献
https://arxiv.org/pdf/1409.1556.pdf
http://blog.csdn.net/wangsidadehao/article/details/54311282
https://blog.csdn.net/whz1861/article/details/78111606
https://blog.csdn.net/briblue/article/details/83792394