Netron可视化Pytorch保存的网络模型
目录
一.理清网络的输入与输出
二. 将模型转换为onnx格式
三.Netron可视化工具
一.理清网络的输入与输出
我自定义的网络模型(主要看看前向传播函数即可):
import torch
import torch.nn as nn
#导入数据预处理之后的相关数据
from dataPreprocessing import n_categories
#*********************************** 参考这篇文章的图 https://www.cnblogs.com/lccxqk/p/14622532.html
class RNN(nn.Module):
# rnn = RNN(n_letters, 128, n_letters)说明有多少字符就有多少种输入情况,也就有多少种输出情况,所以最后需要一个Softmax层进行多元分类
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
#其实是两层?只不过i2h和i2o其实可以看做一层,只不过传递的方向不一样
self.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size)
self.o2o = nn.Linear(hidden_size + output_size, output_size)
#防止过拟合
self.dropout = nn.Dropout(0.1)
#多元分类,# 对列做Softmax,最后得到的每行和为1;dim=0则每列和为1
self.softmax = nn.LogSoftmax(dim=1)
# 前向传播,三个参数都是行向量,且前俩是one-hot矩阵
# 前向传播,三个参数都是行向量,结合这篇文章的前向传播那里的图进行分析 https://hanhan.blog.csdn.net/article/details/128062706
# hidden就是图中的a,即向右传的激活值,
# 一个单词的从左往右的所有字母依次进行前向传播,每次前向传播就对应图中的一列
# 三个线性层其实是两层
def forward(self, category, input, hidden):
'''
运行以下代码查看torch.cat的功能,即把这三个行向量连接起来
category=torch.zeros(1, 3)
print(category)
input=torch.ones(1,2)
print(input)
hidden=torch.zeros(1,2)
print(hidden)
input_combined = torch.cat((category, input, hidden), 1)
print(input_combined)
'''
input_combined = torch.cat((category, input, hidden), 1)
#往右传
hidden = self.i2h(input_combined)
#往上传
output = self.i2o(input_combined)
output_combined = torch.cat((hidden, output), 1)
output = self.o2o(output_combined)
output = self.dropout(output)
output = self.softmax(output)
return output, hidden
def initHidden(self):
#行向量(2维,即一行2列的矩阵)
return torch.zeros(1, self.hidden_size)二. 将模型转换为onnx格式
因为Netron不支持pytorch保存的模型格式,所以需要将模型进行一下格式转换。
PyTorch中自带的torch.onnx模块包含将模型导出到ONNX IR格式的函数。这些模型可以被ONNX库加载,然后将它们转换成可在其他深度学习框架上运行的模型。
torch.onnx.export(model, args, f, export_params=True, verbose=False, training=False, input_names=None, output_names=None)参数:
- model(torch.nn.Module)-要被导出的模型
- args(参数的集合)-模型的输入,例如,这种model(*args)方式是对模型的有效调用。任何非Variable参数都将硬编码到导出的模型中;任何Variable参数都将成为导出的模型的输入,并按照他们在args中出现的顺序输入。如果args是一个Variable,这等价于用包含这个Variable的1-ary元组调用它。(注意:现在不支持向模型传递关键字参数。)
- f-一个类文件的对象(必须实现文件描述符的返回)或一个包含文件名字符串。一个二进制Protobuf将会写入这个文件中。
- export_params(bool,default True)-如果指定,所有参数都会被导出。如果你只想导出一个未训练的模型,就将此参数设置为False。在这种情况下,导出的模型将首先把所有parameters作为参arguments,顺序由
model.state_dict().values()指定。 - verbose(bool,default False)-如果指定,将会输出被导出的轨迹的调试描述。
- training(bool,default False)-导出训练模型下的模型。目前,ONNX只面向推断模型的导出,所以一般不需要将该项设置为True。
- input_names(list of strings, default empty list)-按顺序分配名称到图中的输入节点。
- output_names(list of strings, default empty list)-按顺序分配名称到图中的输出节点。
.pth格式的模型转.onnx格式的模型的代码(注释中已有详细说明):
#RNN是我自己的自定义的一个网络
from buildModel import RNN
# 先创建模型对象并加载已经保存的模型参数
model=RNN(59, 128, 59)
model.load_state_dict(torch.load('./model/myRNN.pth'))
model.eval()
#给网络的输入和输出起名字(注意数量和顺序要和自定义网络的前向传播函数的参数对应起来)
input_names = ['名字种类','一个名字','隐藏状态']
output_names = ['预测结果','新隐藏状态']
#获取输入数据,注意,随便搞点输入数据也行,只要尺寸符合即可
from myTrain import randomTrainingExample
category_tensor, input_line_tensor, target_line_tensor=randomTrainingExample()
hidden=torch.zeros(1, 128)
#参数参考上面的说明
#args是输入模型中的数据,f是保存模型的路径
torch.onnx.export(model=model,args=(category_tensor,input_line_tensor[0],hidden),f='./model/myRNN.onnx',
input_names=input_names, output_names=output_names,verbose='True')三.Netron可视化工具
用上面的代码生成onnx格式的模型之后,再用netron(安装:pip install netron)生成网络结构图:
import netron
modelData='./model/myRNN.onnx'
netron.start(modelData)netron会自动打开浏览器显式,然后一些操作也很简单,自己点吧点吧就明白了。
贴一下我生成的网络图:
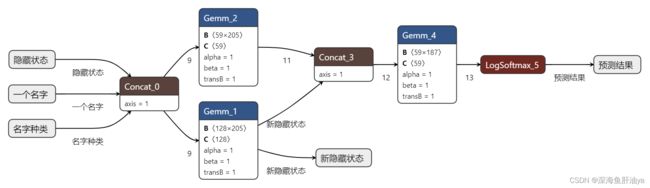
当然不一定非要先保存了模型再转换,也可以训练完就用torch.onnx模块来保存模型为onnx格式的模型,到时候用到再说吧,先这样。