An experimental PyTorch implementation of Blind Image Quality Assessment Using A Deep Bilinear CNN
DBCNN-Pytorch 官方复现论文代码详解
1、论文解读&&框架解释
2、代码实践
论文地址:https://arxiv.org/abs/1907.02665
代码地址:https://github.com/zwx8981/DBCNN-PyTorch
》》》》》》》》》》》》》》》》》》》》》》》》》论文理论部分》》》》》》》》》》》》》》》》》》》》》》》》
- 《基于深度双线性卷积神经网络的盲图像质量评估》论文解读
摘要部分:我们提出了一个深度双线性盲图像质量评估模型(BIQA),可以处理合成失真和真实失真。我们的模型由两个卷积神经网络(CNN)组成,每个卷积神经网络专门处理一个失真场景。对于合成失真,我们预先训练一个CNN来分类图像失真类型和级别,这样我们就可以获得大规模的训练数据。对于真实失真,我们采用预先训练的CNN进行图像分类。来自两个CNN的特征被双线性合并为一个统一的表示,用于最终的质量预测。然后,我们使用一种随机梯度下降的变体对目标主题评级数据库的整个模型进行微调。大量的实验表明,该模型在合成数据库和真实数据库上都具有较好的性能。在此基础上,利用群最大差分竞争验证了该方法在Waterloo Exploration Database上的可推广性。
主体框架:
1)CNN的合成失真(CNN for Synthetic Distortions)
数据集
①Waterloo Exploration Database :包含4744张原始质量的图像,具有四种合成失真,即JPEG压缩、JPEG2000压缩、高斯模糊和高斯噪声。
②PASCAL VOC Database:是一个用于对象识别的大型数据库,包含17,125张质量可接受的图像,包含20个语义类。
我们将两个数据库合并,得到21,869张源图像。除了上面提到的四种失真类型,我们还增加了五种——对比度拉伸、粉色噪声、带有颜色抖动的图像量化、过度曝光和曝光不足。我们确保添加的失真主导感知质量,因为一些源图像(特别是在PASCAL VOC数据库中)可能没有完美的质量。

>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> S-CNN框架图(采用了类似于VGG的结构)>>>>>>>>>>>>>>>>>>>>>
2)CNN的真实失真(CNN for Authentic Distortions)
与合成失真训练S-CNN不同,真实失真训练很难获得大量相关训练数据。同时,使用少量样本从零开始训练CNN往往会导致过拟合。在这里,我们使用VGG-16,它已经为ImageNet上的图像分类任务进行了预先训练,为真实失真的图像提取相关特征。由于ImageNet中的失真是摄影而不是模拟的自然结果,VGG-16特征表示极有可能适应真实的失真,并提高分类性能。
3)利用二值池化的DB-CNN(DB-CNN by Bilinear Pooling)
我们考虑双线性池,将S-CNN合成失真和VGG-16真实失真结合成一个统一的模型。双线性模型已被证明在建模双因素变化方面是有效的,如图像的风格和内容,细粒度识别的位置和外观,视频分析的空间和时间特征,以及问题回答的文本和视觉信息。我们用类似的哲学来处理BIQA问题,其中合成和真实的扭曲被建模为双因素变化,产生DB-CNN模型。
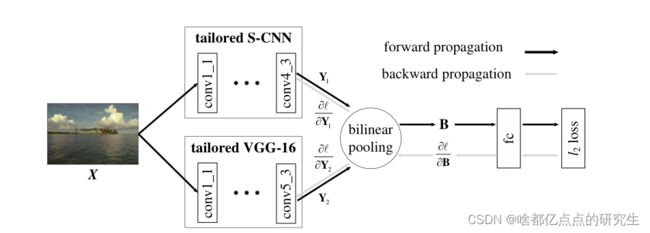
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> DB-CNN框架图>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
该结构通过把图片X分别输入S-CNN和VGG-16中,得到了不同网络输出的特征Y1和Y2,之后利用二值池化方式组合特征,得到融合特征B,把该特征输入到fc层进行损失计算。
实验细节:
数据集:主要实验在三个单扭曲合成IQA数据库LIVE、CSIQ和TID2013、多重扭曲合成数据集LIVE MD和真实的LIVE挑战数据库进行。
LIVE包含了从29个参考图像合成的779张失真图像,具有五种失真类型- JPEG压缩(JPEG),
JPEG2000压缩(JP2K),高斯模糊(GB),高斯白噪声(WN)和快速衰落错误(FF)在7到8个退化级别。对于每一幅图像,采集范围为[0,100]的差分MOS
(DMOS),其值越高表示感知质量越低。
CSIQ由30张参考图片生成的866张失真图片组成,包括6种失真类型,即JPEG、JP2K、GB、WN、对比度变化(CG)和粉色噪声(PN),在3到5个退化级别上。提供范围为[0,1]的DMOS作为基础真值。
TID2013包含从25张参考图片中选取了3000张畸变图片,其中24种畸变类型在5个退化级别上。提供MOS范围为[0,9]表示感知质量。
LIVE
MD包含从15个源图像在两种多重失真场景下生成的450张图像——模糊后JPEG压缩和模糊后高斯白噪声。DMOS在[0,100]的范围内作为主观意见。
LIVE
Challenge是一个真实的IQA数据库,它包含了1162张来自不同真实场景的图片,由众多拥有不同摄影技能水平的摄影师使用不同的相机设备拍摄。因此,这些图像经历了复杂的现实扭曲。MOS在[0,100]范围内,是通过一个在线众包平台从超过8,100名独特的人类评估者中收集的。
实验方法:具体来说,我们将目标IQA数据库中的失真图像分成两个部分,其中80%用于微调DB-CNN,其余20%用于测试。对于合成数据库LIVE、CSIQ、TID2013和LIVE MD,我们保证了微调和测试集之间的图像内容独立性。对所有数据库随机重复拆分过程10次,并计算平均结果。
评价指标:我们采用两个常用的指标来对BIQA模型进行基准测试:斯皮尔曼等级相关系数(SRCC)和皮尔逊线性相关系数(PLCC)。SRCC衡量预测的单调性,PLCC衡量预测的精度。
》》》》》》》》》》》》》》》》》》》》》》》》》代码实践部分》》》》》》》》》》》》》》》》》》》》》》》》
官方代码库详解:
- 版本要求:PyTorch 0.4+ Python 3.6
- 文件夹:dataset:>>存放数据集;db_models:>>存放模型文件;fc_models:>>存放微调模型;loss:>>存放常用loss函数;pretrained_scnn:>>存放预训练SCNN模型
- 文件:SCNN.py 用于训练和测试SCNN网络部分
import os
import matplotlib.pyplot as plt
import torch
import torchvision
import torch.nn.functional as F
import torch.nn as nn
import numpy as np
import WPFolder
from PIL import Image
torch.manual_seed(0)
torch.cuda.manual_seed_all(0)
#os.environ['CUDA_VISIBLE_DEVICES'] = '1'
def pil_loader(path):
# 打开PIL图片并强制转化格式为RGB
with open(path, 'rb') as f:
img = Image.open(f)
return img.convert('RGB')
def accimage_loader(path):
#利用这个包可以加速读取图片
import accimage
try:
return accimage.Image(path)
except IOError:
# Potentially a decoding problem, fall back to PIL.Image
return pil_loader(path)
def default_loader(path):
#定义默认图片加载方式
from torchvision import get_image_backend
if get_image_backend() == 'accimage':
return accimage_loader(path)
else:
return pil_loader(path)
#定义支持的图片类型
IMG_EXTENSIONS = ['.jpg', '.jpeg', '.png', '.ppm', '.bmp', '.pgm', '.tif']
def weight_init(net):
#权重初始化函数,一般用于对模型参数进行初始化
for m in net.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight.data,nonlinearity='relu')
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight.data,nonlinearity='relu')
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
class SCNN(nn.Module):
def __init__(self):
"""Declare all needed layers."""
super(SCNN, self).__init__()
# 定义分类的类别数
self.num_class = 39
#定义特征提取网络
self.features = nn.Sequential(nn.Conv2d(3,48,3,1,1),nn.BatchNorm2d(48),nn.ReLU(inplace=True),
nn.Conv2d(48,48,3,2,1),nn.BatchNorm2d(48),nn.ReLU(inplace=True),
nn.Conv2d(48,64,3,1,1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),
nn.Conv2d(64,64,3,2,1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),
nn.Conv2d(64,64,3,1,1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),
nn.Conv2d(64,64,3,2,1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),
nn.Conv2d(64,128,3,1,1),nn.BatchNorm2d(128),nn.ReLU(inplace=True),
nn.Conv2d(128,128,3,1,1),nn.BatchNorm2d(128),nn.ReLU(inplace=True),
nn.Conv2d(128,128,3,2,1),nn.BatchNorm2d(128),nn.ReLU(inplace=True))
weight_init(self.features) #调用权重初始化函数,对上面这些层的参数进行初始化
self.pooling = nn.AvgPool2d(14,1) #定义平均池化层
self.projection = nn.Sequential(nn.Conv2d(128,256,1,1,0), nn.BatchNorm2d(256), nn.ReLU(inplace=True),
nn.Conv2d(256,256,1,1,0), nn.BatchNorm2d(256), nn.ReLU(inplace=True))
weight_init(self.projection)
self.classifier = nn.Linear(256,self.num_class) #定义分类层
weight_init(self.classifier)
def forward(self, X):
N = X.size()[0] #记录单次训练批次大小
assert X.size() == (N, 3, 224, 224)
X = self.features(X) #提取特征
assert X.size() == (N, 128, 14, 14)
X = self.pooling(X) #对特征池化
assert X.size() == (N, 128, 1, 1)
X = self.projection(X) #特征映射
X = X.view(X.size(0), -1)
X = self.classifier(X) #对特征分类
assert X.size() == (N, self.num_class)
return X
class SCNNManager(object):
"""定义管理S-CNN的类训练模型
"""
def __init__(self, options, path):
"""Prepare the network, criterion, solver, and data.
Args:
options, dict: Hyperparameters.
"""
print('Prepare the network and data.')
self._options = options
self._path = path
self._epoch = 0
# 定义SCNN模型类.
network = SCNN()
weight_init(network) #初始化模型
self._net = torch.nn.DataParallel(network).cuda()
logspaced_LR = np.logspace(-1,-4, self._options['epochs'])
# 加载预训练模型文件
checkpoints_list = os.listdir(self._path['model'])
if len(checkpoints_list) != 0:
self._net.load_state_dict(torch.load(os.path.join(self._path['model'],'%s%s%s' % ('net_params', str(len(checkpoints_list)-1), '.pkl'))))
self._epoch = len(checkpoints_list)
self._options['base_lr'] = logspaced_LR[len(checkpoints_list)]
print(self._net)
# 定义损失
self._criterion = torch.nn.CrossEntropyLoss().cuda()
# 定义优化器
self._solver = torch.optim.SGD(
self._net.parameters(), lr=self._options['base_lr'],
momentum=0.9, weight_decay=self._options['weight_decay'])
#定义学习率的下降方法
lambda1 = lambda epoch: logspaced_LR[epoch]
self._scheduler = torch.optim.lr_scheduler.LambdaLR(self._solver,lr_lambda=lambda1)
#定义数据预处理方法
train_transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize(size=256), # Let smaller edge match
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.RandomCrop(size=224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
])
test_transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize(size=256),
torchvision.transforms.CenterCrop(size=224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
])
#定义数据加载的类
train_data = WPFolder.WPFolder(
root=self._path['waterloo_pascal'], loader = default_loader, extensions = IMG_EXTENSIONS,
transform=train_transforms,train = True, ratio = 0.8)
test_data = WPFolder.WPFolder(
root=self._path['waterloo_pascal'], loader = default_loader, extensions = IMG_EXTENSIONS,
transform=test_transforms, train = False, ratio = 0.8)
self._train_loader = torch.utils.data.DataLoader(
train_data, batch_size=self._options['batch_size'],
shuffle=True, num_workers=0, pin_memory=True)
self._test_loader = torch.utils.data.DataLoader(
test_data, batch_size=self._options['batch_size'],
shuffle=False, num_workers=0, pin_memory=True)
def train(self):
"""训练网络的函数."""
print('Training.')
best_acc = 0.0
best_epoch = None
print('Epoch\tTrain loss\tTrain acc\tTest acc')
for t in range(self._epoch,self._options['epochs']):
epoch_loss = []
num_correct = 0.0
num_total = 0.0
batchindex = 0
for X, y in self._train_loader:
X = torch.tensor(X.cuda())
y = torch.tensor(y.cuda(async=True))
# 清空梯度
self._solver.zero_grad()
# 前向传播
score = self._net(X)
loss = self._criterion(score, y.detach())
epoch_loss.append(loss.item())
# 预测
_, prediction = torch.max(F.softmax(score.data), 1)
num_total += y.size(0)
num_correct += torch.sum(prediction == y)
# 反向传播
loss.backward()
self._solver.step()
batchindex = batchindex + 1
print('%d epoch done' % (t+1))
train_acc = 100 * num_correct.float() / num_total
if (t < 2) | (t > 20):
with torch.no_grad():
test_acc = self._accuracy(self._test_loader)
if test_acc > best_acc:
best_acc = test_acc
best_epoch = t + 1
print('*', end='')
print('%d\t%4.3f\t\t%4.2f%%\t\t%4.2f%%' %
(t+1, sum(epoch_loss) / len(epoch_loss), train_acc, test_acc))
pwd = os.getcwd()
modelpath = os.path.join(pwd,'models',('net_params' + str(t) + '.pkl'))
torch.save(self._net.state_dict(), modelpath)
self._scheduler.step(t)
print('Best at epoch %d, test accuaray %f' % (best_epoch, best_acc))
def _accuracy(self, data_loader):
"""用于计算训练或者测试准确度的函数
Args:
data_loader: Train/Test DataLoader.
Returns:
Train/Test accuracy in percentage.
"""
self._net.eval()
num_correct = 0.0
num_total = 0.0
batchindex = 0
for X, y in data_loader:
# Data.
batchindex = batchindex + 1
X = torch.tensor(X.cuda())
y = torch.tensor(y.cuda(async=True))
# 预测
score = self._net(X)
_, prediction = torch.max(score.data, 1)
num_total += y.size(0)
num_correct += torch.sum(prediction == y.data)
self._net.train() # Set the model to training phase
return 100 * num_correct.float() / num_total
def main():
"""主函数接口,调用前面实现的函数"""
import argparse
parser = argparse.ArgumentParser(
description='Train DB-CNN for BIQA.')
parser.add_argument('--base_lr', dest='base_lr', type=float, default=1e-1,
help='Base learning rate for training.')
parser.add_argument('--batch_size', dest='batch_size', type=int,
default=128, help='Batch size.')
parser.add_argument('--epochs', dest='epochs', type=int,
default=30, help='Epochs for training.')
parser.add_argument('--weight_decay', dest='weight_decay', type=float,
default=5e-4, help='Weight decay.')
args = parser.parse_args()
if args.base_lr <= 0:
raise AttributeError('--base_lr parameter must >0.')
if args.batch_size <= 0:
raise AttributeError('--batch_size parameter must >0.')
if args.epochs < 0:
raise AttributeError('--epochs parameter must >=0.')
if args.weight_decay <= 0:
raise AttributeError('--weight_decay parameter must >0.')
options = {
'base_lr': args.base_lr,
'batch_size': args.batch_size,
'epochs': args.epochs,
'weight_decay': args.weight_decay,
}
#存放训练数据集的路径和模型路径
path = {
'waterloo_pascal': 'Z:\Waterloo\exploration_database_and_code\image',
'model': 'D:\zwx_Project\dbcnn_pytorch\models'
}
#定义SCNN网络管理类
manager = SCNNManager(options, path)
manager.train()
if __name__ == '__main__':
main()
DBCNN.py文件整体框架的训练
import os
import torch
import torchvision
import torch.nn as nn
from SCNN import SCNN
from PIL import Image
from scipy import stats
import random
import torch.nn.functional as F
import numpy as np
#用于指定系统中哪一张显卡进行训练
#os.environ['CUDA_VISIBLE_DEVICES'] = '1'
#数据加载函数,不在赘述
def pil_loader(path):
with open(path, 'rb') as f:
img = Image.open(f)
return img.convert('RGB')
def accimage_loader(path):
import accimage
try:
return accimage.Image(path)
except IOError:
# Potentially a decoding problem, fall back to PIL.Image
return pil_loader(path)
def default_loader(path):
from torchvision import get_image_backend
if get_image_backend() == 'accimage':
return accimage_loader(path)
else:
return pil_loader(path)
#定义DBCNN整体框架
class DBCNN(torch.nn.Module):
def __init__(self, scnn_root, options):
"""初始化函数中对所有层进行申明"""
nn.Module.__init__(self)
# VGG-16用于提取特征
self.features1 = torchvision.models.vgg16(pretrained=True).features
self.features1 = nn.Sequential(*list(self.features1.children()) [:-1])
#定义SCNN模块
scnn = SCNN()
scnn = torch.nn.DataParallel(scnn).cuda()
#需要加载预训练权重,即前面SCNN.py训练得到的权重文件
scnn.load_state_dict(torch.load(scnn_root))
self.features2 = scnn.module.features
# 线性分类层,框架图中fc
self.fc = torch.nn.Linear(512*128, 1)
#增加判断条件,决定是否对fc层参数进行更新
if options['fc'] == True:
# 冻结参数,features1和features2参数都不更新
for param in self.features1.parameters():
param.requires_grad = False
for param in self.features1.parameters():
param.requires_grad = False
# 初始化fc层参数.
nn.init.kaiming_normal_(self.fc.weight.data)
if self.fc.bias is not None:
nn.init.constant_(self.fc.bias.data, val=0)
def forward(self, X):
"""网络前向传播过程"""
#图像经过VGG16提取特征
N = X.size()[0]
X1 = self.features1(X)
H = X1.size()[2]
W = X1.size()[3]
assert X1.size()[1] == 512 #断言,判断数据维度是否符合要求
#图像经过SCNN提取特征
X2 = self.features2(X)
H2 = X2.size()[2]
W2 = X2.size()[3]
assert X2.size()[1] == 128
if (H != H2) | (W != W2):
X2 = F.upsample_bilinear(X2,(H,W))
#对两个特征进行B值计算
X1 = X1.view(N, 512, H*W)
X2 = X2.view(N, 128, H*W)
X = torch.bmm(X1, torch.transpose(X2, 1, 2)) / (H*W) # Bilinear
assert X.size() == (N, 512, 128)
X = X.view(N, 512*128) #B值的维度变化
X = torch.sqrt(X + 1e-8)
X = torch.nn.functional.normalize(X) #标准化
X = self.fc(X) #通过fc层输出预测结果
assert X.size() == (N, 1)
return X
class DBCNNManager(object):
def __init__(self, options, path):
"""在这个类中定义了网络,损失,优化器和数据类
Args:
options, dict: Hyperparameters.
"""
print('Prepare the network and data.')
self._options = options
self._path = path
# 网络部分.
self._net = torch.nn.DataParallel(DBCNN(self._path['scnn_root'], self._options), device_ids=[0]).cuda()
if self._options['fc'] == False:
self._net.load_state_dict(torch.load(path['fc_root']))
print(self._net)
# 损失.
self._criterion = torch.nn.MSELoss().cuda()
# 优化器.
if self._options['fc'] == True:
self._solver = torch.optim.SGD(
self._net.module.fc.parameters(), lr=self._options['base_lr'],
momentum=0.9, weight_decay=self._options['weight_decay'])
else:
self._solver = torch.optim.Adam(
self._net.module.parameters(), lr=self._options['base_lr'],
weight_decay=self._options['weight_decay'])
#数据增强定义
if (self._options['dataset'] == 'live') | (self._options['dataset'] == 'livec'):
if self._options['dataset'] == 'live':
crop_size = 432
else:
crop_size = 448
train_transforms = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.RandomCrop(size=crop_size),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
])
elif (self._options['dataset'] == 'csiq') | (self._options['dataset'] == 'tid2013'):
train_transforms = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
])
elif self._options['dataset'] == 'mlive':
train_transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize((570,960)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
])
test_transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
])
#这里主要针对不同数据集进行选择进行定义
if self._options['dataset'] == 'live':
import LIVEFolder
train_data = LIVEFolder.LIVEFolder(
root=self._path['live'], loader = default_loader, index = self._options['train_index'],
transform=train_transforms)
test_data = LIVEFolder.LIVEFolder(
root=self._path['live'], loader = default_loader, index = self._options['test_index'],
transform=test_transforms)
elif self._options['dataset'] == 'livec':
import LIVEChallengeFolder
train_data = LIVEChallengeFolder.LIVEChallengeFolder(
root=self._path['livec'], loader = default_loader, index = self._options['train_index'],
transform=train_transforms)
test_data = LIVEChallengeFolder.LIVEChallengeFolder(
root=self._path['livec'], loader = default_loader, index = self._options['test_index'],
transform=test_transforms)
else:
raise AttributeError('Only support LIVE and LIVEC right now!')
self._train_loader = torch.utils.data.DataLoader(
train_data, batch_size=self._options['batch_size'],
shuffle=True, num_workers=0, pin_memory=True)
self._test_loader = torch.utils.data.DataLoader(
test_data, batch_size=1,
shuffle=False, num_workers=0, pin_memory=True)
def train(self):
""训练函数"""
print('Training.')
best_srcc = 0.0
best_epoch = None
print('Epoch\tTrain loss\tTrain_SRCC\tTest_SRCC\tTest_PLCC')
for t in range(self._options['epochs']):
epoch_loss = []
pscores = []
tscores = []
num_total = 0
for X, y in self._train_loader:
# Data.
X = torch.tensor(X.cuda())
y = torch.tensor(y.cuda(async=True))
# Clear the existing gradients.
self._solver.zero_grad()
# Forward pass.
score = self._net(X)
loss = self._criterion(score, y.view(len(score),1).detach())
epoch_loss.append(loss.item())
# Prediction.
num_total += y.size(0)
pscores = pscores + score.cpu().tolist()
tscores = tscores + y.cpu().tolist()
# Backward pass.
loss.backward()
self._solver.step()
train_srcc, _ = stats.spearmanr(pscores,tscores)
test_srcc, test_plcc = self._consitency(self._test_loader)
if test_srcc > best_srcc:
best_srcc = test_srcc
best_epoch = t + 1
print('*', end='')
pwd = os.getcwd()
if self._options['fc'] == True:
modelpath = os.path.join(pwd,'fc_models',('net_params' + '_best' + '.pkl'))
else:
modelpath = os.path.join(pwd,'db_models',('net_params' + '_best' + '.pkl'))
torch.save(self._net.state_dict(), modelpath)
print('%d\t%4.3f\t\t%4.4f\t\t%4.4f\t%4.4f' %
(t+1, sum(epoch_loss) / len(epoch_loss), train_srcc, test_srcc, test_plcc))
print('Best at epoch %d, test srcc %f' % (best_epoch, best_srcc))
return best_srcc
def _consitency(self, data_loader):
"""" 测试函数"""
self._net.train(False)
num_total = 0
pscores = []
tscores = []
for X, y in data_loader:
# 数据.
X = torch.tensor(X.cuda())
y = torch.tensor(y.cuda(async=True))
# 预测.
score = self._net(X)
pscores = pscores + score[0].cpu().tolist()
tscores = tscores + y.cpu().tolist()
num_total += y.size(0)
test_srcc, _ = stats.spearmanr(pscores,tscores)
test_plcc, _ = stats.pearsonr(pscores,tscores)
self._net.train(True) # Set the model to training phase
return test_srcc, test_plcc
def main():
"""主函数."""
import argparse
#参数包,里面可以针对不同参数进行选择,包括base_lr学习率,batch_size单次训练批次大小,epochs所有数据训练多少次,weight_decay学习率衰减率,dataset可供选择的数据集
parser = argparse.ArgumentParser(
description='Train DB-CNN for BIQA.')
parser.add_argument('--base_lr', dest='base_lr', type=float, default=1e-5,
help='Base learning rate for training.')
parser.add_argument('--batch_size', dest='batch_size', type=int,
default=8, help='Batch size.')
parser.add_argument('--epochs', dest='epochs', type=int,
default=50, help='Epochs for training.')
parser.add_argument('--weight_decay', dest='weight_decay', type=float,
default=5e-4, help='Weight decay.')
parser.add_argument('--dataset',dest='dataset',type=str,default='live',
help='dataset: live|csiq|tid2013|livec|mlive')
args = parser.parse_args()
if args.base_lr <= 0:
raise AttributeError('--base_lr parameter must >0.')
if args.batch_size <= 0:
raise AttributeError('--batch_size parameter must >0.')
if args.epochs < 0:
raise AttributeError('--epochs parameter must >=0.')
if args.weight_decay <= 0:
raise AttributeError('--weight_decay parameter must >0.')
options = {
'base_lr': args.base_lr,
'batch_size': args.batch_size,
'epochs': args.epochs,
'weight_decay': args.weight_decay,
'dataset':args.dataset,
'fc': [],
'train_index': [],
'test_index': []
}
path = {
'live': os.path.join('dataset','databaserelease2'),
'csiq': os.path.join('dataset','CSIQ'),
'tid2013': os.path.join('dataset','TID2013'),
'livec': os.path.join('dataset','ChallengeDB_release'),
'mlive': os.path.join('dataset','LIVEmultidistortiondatabase'),
'fc_model': os.path.join('fc_models'),
'scnn_root': os.path.join('pretrained_scnn','scnn.pkl'),
'fc_root': os.path.join('fc_models','net_params_best.pkl'),
'db_model': os.path.join('db_models')
}
if options['dataset'] == 'live':
index = list(range(0,29))
elif options['dataset'] == 'csiq':
index = list(range(0,30))
elif options['dataset'] == 'tid2013':
index = list(range(0,25))
elif options['dataset'] == 'mlive':
index = list(range(0,15))
elif options['dataset'] == 'livec':
index = list(range(0,1162))
lr_backup = options['base_lr']
srcc_all = np.zeros((1,10),dtype=np.float)
for i in range(0,10):
#随机的拆分训练和测试集
random.shuffle(index)
train_index = index[0:round(0.8*len(index))]
test_index = index[round(0.8*len(index)):len(index)]
options['train_index'] = train_index
options['test_index'] = test_index
#仅训练全连接层
options['fc'] = True
options['base_lr'] = 1e-3
manager = DBCNNManager(options, path)
best_srcc = manager.train()
#微调所有模型参数
options['fc'] = False
options['base_lr'] = lr_backup
manager = DBCNNManager(options, path)
best_srcc = manager.train()
srcc_all[0][i] = best_srcc
srcc_mean = np.mean(srcc_all)
print(srcc_all)
print('average srcc:%4.4f' % (srcc_mean))
return best_srcc
if __name__ == '__main__':
main()
其他文件夹:
SCNN3.py 存放着以残差网络结构ResNet的框架,其他部分同SCNN.py
DualCNN.py 对应一种双流网络,主要是结构上差异,和DBCNN.py类似
simple_demo.py 主要用于训练完成之后对实验结果的一个演示程序
TRILINEAR.py 三线性池化的方式,中间使用了注意力机制
WPFolder.py 是用来加载Waterloo Exploration Database数据集的程序
NetVLAD.py NetVLAD层实现的文档
MPNCOV.py 矩阵功率归一化协方差池实现的文档
LIVEFolder.py 和 LIVEChallengeFolder.py,Koniq_10k.py分别是对应数据集的加载程序
CBP.py 里面存放着紧凑双线性池Compact Bilinear Pooling实现方法
BCNN.py 对应着线性CNN的双线性池化(Bilinear Pool implementation of Bilinear CNN)实现
BaseCNN.py 一个基础的CNN网络框架,SCNN和DBCNN均模仿这个文件夹编写的。