Transformer
一、背景
Transformer在CV领域很火,Transformer是2017年Google在Computation and Language上发表的,当时主要是针对自然语言处理领域提出的(之前的RNN模型记忆长度有限且无法并行化,只有计算完这一 时刻后的数据才能计算下一时刻的数据,但Transformer都可以做到)。在这篇文章中作者提出了Self-Attention的概念,然后在此基础上提出Multi-Head Attention,对Self-Attention以及Multi-Head Attention的理论进行总结。
二、Self-Attention
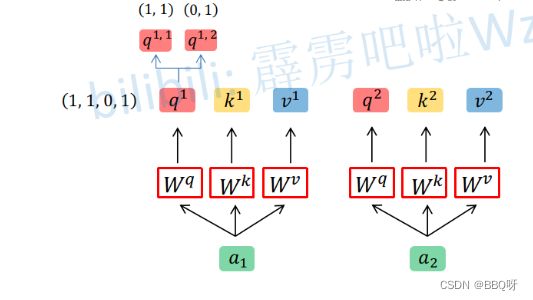
假设输入的序列长度为2,输入就两个节点x1 , x2,然后通过Input Embedding也就是图中的将输入映射到a1 , a2 ,分别通过三个变换矩阵Wq , Wk , Wv ,这三个参数是可训练的,是共享的)得到对应的q1,k1,v1,q2,k2,v(这里在源码中是直接使用全连接层实现的,这里为了方便理解,忽略偏执)根号d代表向量k的维度。


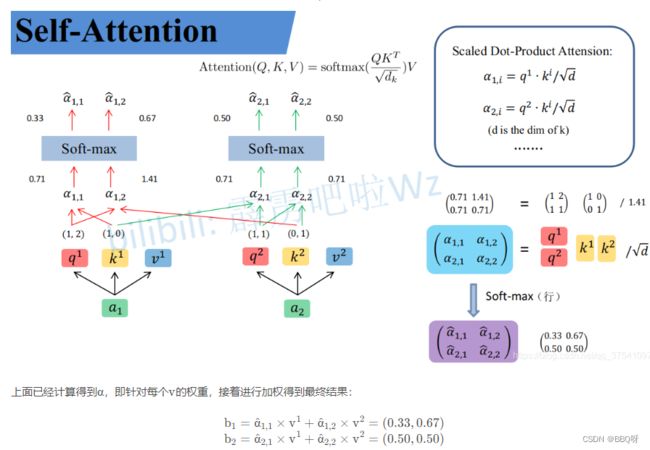

其中d代表向量k的长度,在本示例中等于2,除以d 的原因在论文中的解释是“进行点乘后的数值很大,导致通过softmax后梯度变的很小”,所以通过除以d来进行缩放。
三、Multi-Head Attention
四、Vision Transformer
论文:《 An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale》
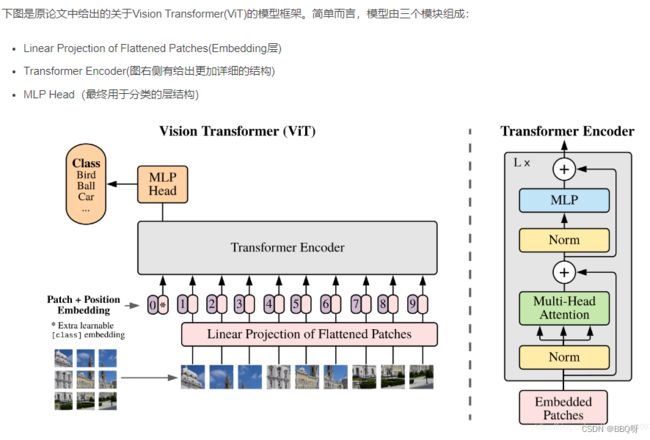
1.Embedding
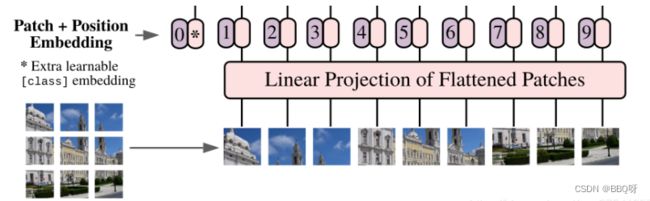
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim],如下图,token0-9对应的都是向量,以ViT-B/16为例,每个token向量长度为768。
对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。如下图所示,首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到( 224/16)*(224/16)= 196个Patches。接着通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(后面都直接称为token)。[16, 16, 3] -> [768]。

在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
在输入Transformer Encoder之前注意需要加上[class]token以及Position Embedding。 在原论文中,作者说参考BERT,在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,Cat([1, 768], [196, 768]) -> [197, 768]。然后关于Position Embedding就是之前Transformer中讲到的Positional Encoding,这里的Position Embedding采用的是一个可训练的参数(1D Pos. Emb.),是直接叠加在tokens上的(add),所以shape要一样。以ViT-B/16为例,刚刚拼接[class]token后shape是[197, 768],那么这里的Position Embedding的shape也是[197, 768]。
2.Transformer Encoder

3.MLP Head
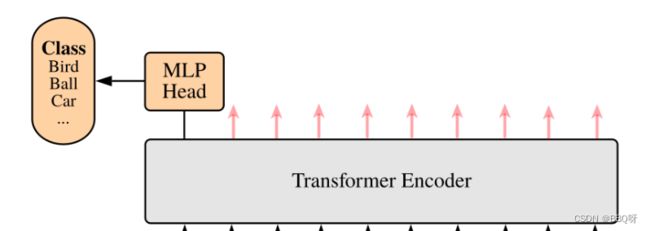
上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者自己的数据上时,只用一个Linear即可。
4.Hybrid模型
就是将传统CNN特征提取和Transformer进行结合。下图绘制的是以ResNet50作为特征提取器的混合模型,但这里的Resnet与之前讲的Resnet有些不同。首先这里的R50的卷积层采用的StdConv2d不是传统的Conv2d,然后将所有的BatchNorm层替换成GroupNorm层。在原Resnet50网络中,stage1重复堆叠3次,stage2重复堆叠4次,stage3重复堆叠6次,stage4重复堆叠3次,但在这里的R50中,把stage4中的3个Block移至stage3中,所以stage3中共重复堆叠9次。
通过R50 Backbone进行特征提取后,得到的特征矩阵shape是[14, 14, 1024],接着再输入Patch Embedding层,注意Patch Embedding中卷积层Conv2d的kernel_size和stride都变成了1,只是用来调整channel。

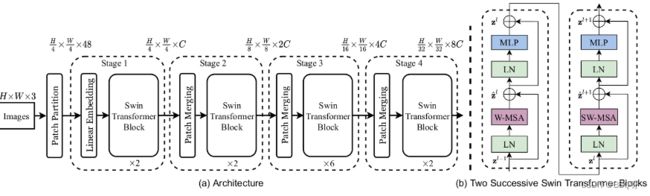
六、Swin-Transformer网络结构模型简介
Swin Transformer是2021年微软研究院发表在ICCV上的一篇文章,并且已经获得ICCV 2021 best paper的荣誉称号。
在Swin Transformer中使用了Windows Multi-Head Self-Attention(W-MSA)的概念,比如在下图的4倍下采样和8倍下采样中,将特征图划分成了多个不相交的区域(Window),并且Multi-Head Self-Attention只在每个窗口(Window)内进行。相对于Vision Transformer中直接对整个(Global)特征图进行Multi-Head Self-Attention,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候。这样做虽然减少了计算量但也会隔绝不同窗口之间的信息传递,所以在论文中作者又提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过此方法能够让信息在相邻的窗口中进行传递
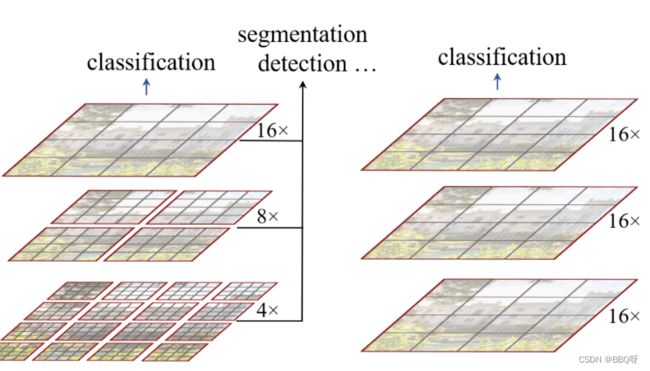
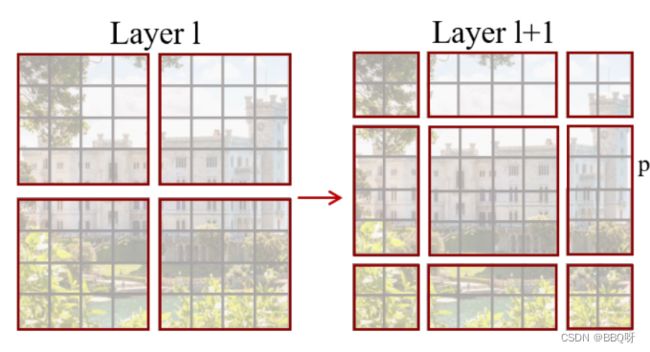
1.Swin Transformer使用了类似卷积神经网络中的层次化构建方法。
比如特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。而在之前的Vision Transformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变。
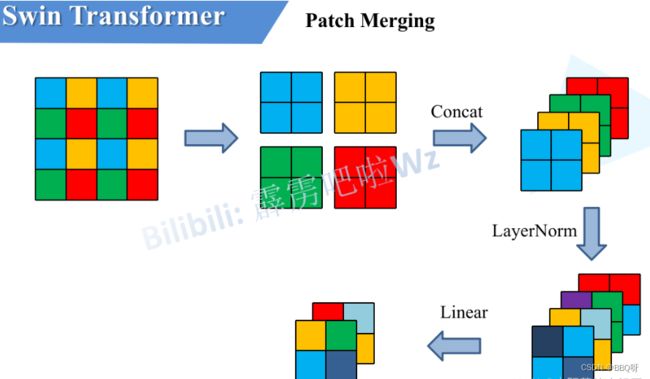
2.Patch Merging模块
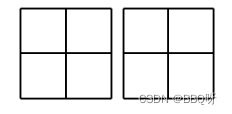
3.W-MSA模块,减少计算量

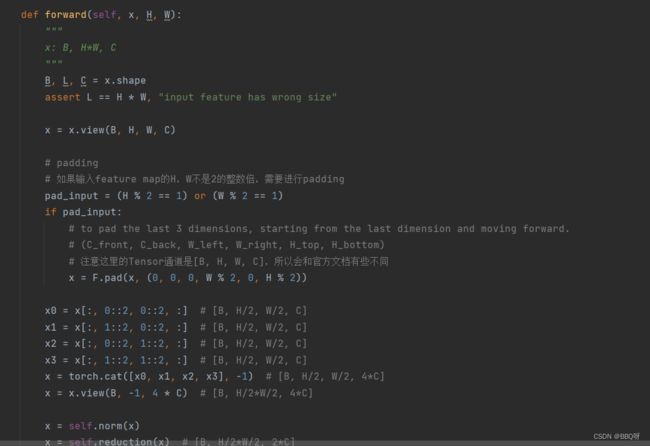
4.SW-MSA模块
采用W-MSA模块时,只会在每个窗口内进行自注意力计算,所以窗口与窗口之间是无法进行信息传递的。为了解决这个问题,作者引入了Shifted Windows Multi-Head Self-Attention(SW-MSA)模块,即进行偏移的W-MSA。
5.Relative Position Bias 相对位置偏执
6.代码复现