通俗理解Transformer中的Attention机制
通俗理解Transformer中的Attention机制
- 前言
- 过一下Transformer中的Attention
- Q,K,V代表什么?
- 那么Q,K,V如何计算的?
- 如何根据Q,K,V计算注意力权重?
- 得到的内积分值有什么用?
- 总览图
前言
笔者最近在做与Attention机制的相关实验,在此复习Transformer中的Attention机制,以寻求创新点。
过一下Transformer中的Attention
先整体过一下Transformer中的Attention
首先计算q和k的点乘,然后除以 d k \sqrt{d_k} dk,经过softmax得到v上的权重分布,最后通过点乘计算v的加权值。
实际计算中为了并行计算,可以在一组queries上计算注意力函数,将多个query堆叠成Q,同理keys和values也被堆叠成K和V,通过下面的公式来计算矩阵输出:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V

最常用的两种注意力函数
- 加法注意力
- 点乘注意力
Transformer中的注意力函数主要使用点乘注意力。
Q,K,V代表什么?
Q,K,V代表query、key-value,attention抽象为对value的每个token进行加权,加权的weight就是attention weight,attention weight是根据query和key计算而成。
通俗的理解:
- Q:query要去查的
- K: 等着被查的
- V: 实际的特征信息
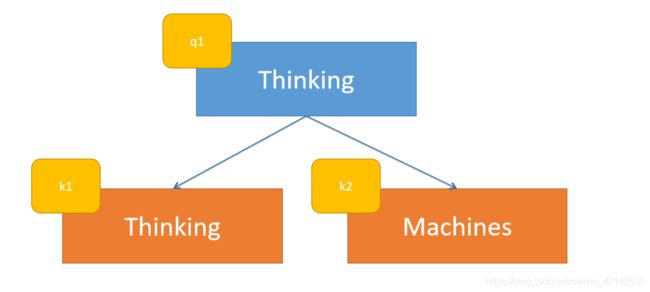
例如:Thinking Machines. 这句话。Attention就是关注每一个词在句子中所占比重,也就是Thinking占Thinking Machines的比重,和Machines占Thinking Machines的比重。
这么说太复杂了,我们用数学语言表达一下,以Thinking占Thinking Machines的比重为例,Thinking被赋予 q 1 q_1 q1,Thinking Machines被赋予 k 1 k_1 k1, k 2 k_2 k2。所以就可以表示为 q 1 q_1 q1占 k 1 k_1 k1和 k 2 k_2 k2的比重。而 v v v向量则是单词的特征向量。
如果实在无法理解,可以将Q,K,V理解为根据当前输入的句子,所计算出的不同的特征矩阵。那么Q,K,V如何计算。
每一个词都有一个Embedding以及Query、Key、Value向量

那么Q,K,V如何计算的?
以矩阵形式进行描述,X为输入的每个单词的Embedding表示,每一行代表一个词。在本例子中X的第一行代表Thinking,第二行代表Machines。 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV分别代表不同的参数矩阵。

如何根据Q,K,V计算注意力权重?
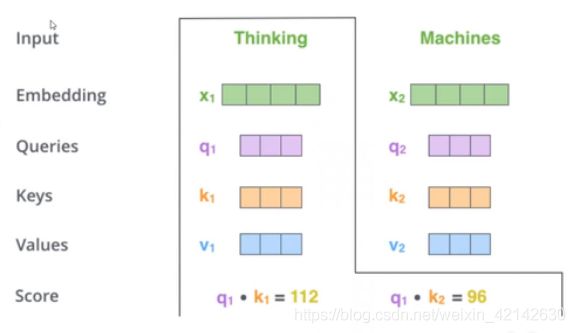
他是通过计算向量q和k的内积表示来计算两个词有多匹配。(用内积的定义是:参考线性代数中,向量线性无关,内积为0)
得到的内积分值有什么用?
通过上述的操作后,我们可以得到 q 1 q_1 q1和 k 1 k_1 k1, k 2 k_2 k2等的分值。那么我们的一个思路是先通过softmax然后归一化,得到的分数可以当作权重使用。

所以采用一下公式
s o f t m a x ( Q K T d k ) V = Z softmax(\frac{QK^T}{\sqrt{d_k}})V=Z softmax(dkQKT)V=Z
为什么分母是 d k \sqrt{d_k} dk,如果没有的话则会出现,句子越长数值越大,所以加入用以剥去维度影响。
总览图
至此,Transformer中的Attention机制介绍完了,接下来放出整体图回顾一下。

得到的向量 z z z可以认为是关注上下文的向量表示