《动手深度学习》4.2多层感知机的从零开始实现 & 4.3简洁实现
4.2多层感知机的从零开始实现 & 4.3简洁实现
-
- 4.2多层感知机的从零开始实现
-
-
- 初始化模型参数
- 激活函数
- 构建模型
- 损失函数
- 训练
- 测试
- 调整超参数会有什么变化?
-
- 4.3. 多层感知机的简洁实现
-
-
- 模型
- 训练
-
4.2多层感知机的从零开始实现
依旧使用Fashion-MNIST数据集:
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
初始化模型参数
- Fashion-MNIST中的每个图像由28x28=784个灰度像素值组成。 所有图像共分为10个类别。将每个图像视为具有784个输入特征 和10个类的简单分类数据集。
- 首先,我们将实现一个具有单隐藏层的多层感知机, 它包含256个隐藏单元。注意,这两个变量(隐藏层和隐藏单元个数)都视为超参数。 通常选择2的若干次幂作为层的宽度。 因为内存在硬件中的分配和寻址方式,这么做往往可以在计算上更高效。
- 我们用几个张量来表示我们的参数。 注意,对于每一层我们都要记录一个权重矩阵和一个偏置向量。同时,要为损失关于这些参数的梯度分配内存。
num_inputs, num_outputs, num_hiddens = 784, 10, 256
# W1为784x256, b1为256; W2为256x10, b2为10
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
- torch.randn(): 返回一个填充了标准正态分布生成的随机数的张量(均值为0,方差为1)
激活函数
自己实现ReLU函数:①
def relu(X):
a = torch.zeros_like(X) #输出形状和x一致的矩阵,其元素全部为0
return torch.max(X, a)
构建模型
先把输入的X矩阵展平,再进行XW+b,然后送入ReLU得到隐藏层H;最后用HW+b完成输出。
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
损失函数
之前实现过,这次直接使用高级API中的内置函数来计算softmax和交叉熵损失。
loss = nn.CrossEntropyLoss(reduction='none')
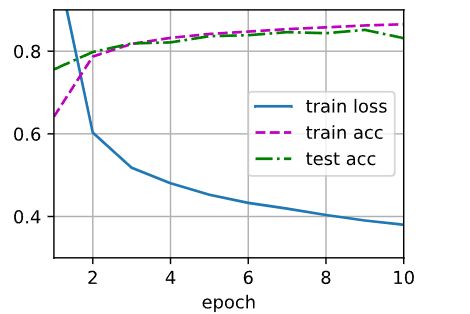
训练
多层感知机的训练过程与softmax回归的训练过程完全相同。 (因为此时输出为10,其实也就是一个多分类问题,只是给softmax多加了个隐藏层而已,训练过程没有区别)
So…直接调用d2l包的train_ch3函数(参见 3.6节 ), 将迭代周期数设置为10,并将学习率设置为0.1。
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
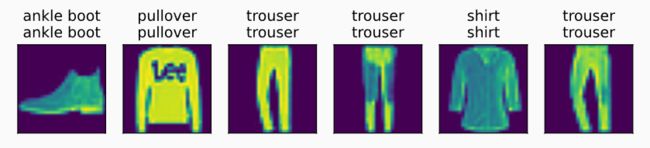
测试
d2l.predict_ch3(net, test_iter)
调整超参数会有什么变化?
设置num_hiddens=32, loss变大,test的准确率波动变大。
4.3. 多层感知机的简洁实现
import torch
from torch import nn
from d2l import torch as d2l
模型
- 与softmax回归的简洁实现( 3.7节)相比, 唯一的区别是我们添加了2个全连接层(之前我们只添加了1个全连接层)。
- 第一层是隐藏层,它包含256个隐藏单元,并使用了ReLU激活函数。 第二层是输出层。
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
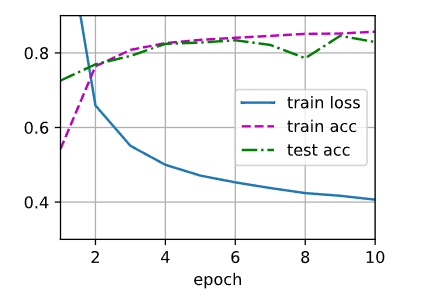
训练
训练过程的实现与实现softmax回归时完全相同, 这种模块化设计使我们能够将与模型架构有关的内容独立出来。
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)