多层感知机+代码实现
感知机
给定输入X,权重w,偏移b,感知机输出
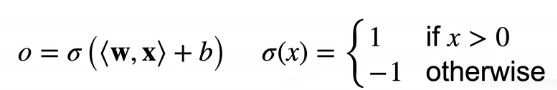
训练感知机
initialize w=0 and b=0 #此处的w直接取0
reprat
if yi[<wi,xi>+b]≤0 then
#此处表示预测错误,要使得≤0,若[+b]≤0,对应如上公式,yi=-1,如此yi[+b]必定不会≤0。反之同理
w<-w+yixi and b<-b+yi#对w和b进行更新
end if
until all classified correctly#直到所有类都分类正确
等价于使用批量大小为1的梯度下降,并使用如下损失函数

此处max(0,)相当于代码中的if语句,如果该类分类正确,(-y
收敛定理

分截面对所有分类都正确,且有余量。
感知机的问题
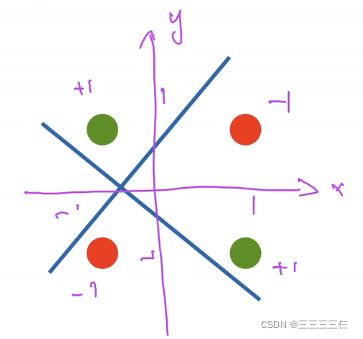
感知机不能拟合XOR问题,只能产生线性分割面
多层感知机
学习XOR问题

按照单线性模型分类行不通因此可以分几步进行。
按照蓝线分类,按照黄线分类。
隐藏层
在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型。 要做到这一点,最简单的方法是将许多全连接层堆叠在一起。 每一层都输出到上面的层,直到生成最后的输出。 我们可以把前 −1 层看作表示,把最后一层看作线性预测器。 这种架构通常称为多层感知机(multilayer perceptron),通常缩写为MLP。
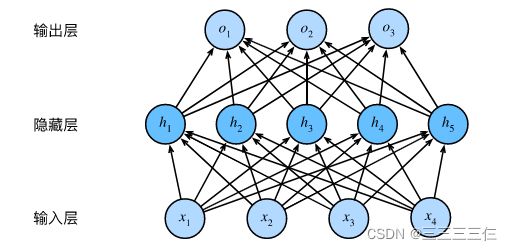
这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。 输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算。 因此,这个多层感知机中的层数为2。 注意,这两个层都是全连接的。 每个输入都会影响隐藏层中的每个神经元, 而隐藏层中的每个神经元又会影响输出层中的每个神经元。
具有全连接层的多层感知机的参数开销可能会高得令人望而却步。 即使在不改变输入或输出大小的情况下, 可能在参数节约和模型有效性之间进行权衡。
从线性到非线性
我们通过矩阵 ∈ℝ× 来表示 个样本的小批量, 其中每个样本具有 个输入特征。 对于具有 ℎ 个隐藏单元的单隐藏层多层感知机, 用 ∈ℝ×ℎ 表示隐藏层的输出, 称为隐藏表示(hidden representations)。 在数学或代码中, 也被称为隐藏层变量(hidden-layer variable) 或隐藏变量(hidden variable)。 因为隐藏层和输出层都是全连接的, 所以我们有隐藏层权重 (1)∈ℝ×ℎ 和隐藏层偏置 (1)∈ℝ1×ℎ 以及输出层权重 (2)∈ℝℎ× 和输出层偏置 (2)∈ℝ1× 。 形式上,我们按如下方式计算单隐藏层多层感知机的输出 ∈ℝ× :
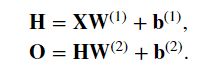
问题: 仿射函数的仿射函数本身就是仿射函数, 但是我们之前的线性模型已经能够表示任何仿射函数。
为了发挥多层架构的潜力, 我们还需要一个额外的关键要素: 在仿射变换之后对每个隐藏单元应用非线性的激活函数(activation function) 。 激活函数的输出(例如, (⋅) )被称为活性值(activations)。 一般来说,有了激活函数,就不可能再将我们的多层感知机退化成线性模型:

为了构建更通用的多层感知机, 我们可以继续堆叠这样的隐藏层, 例如 (1)=1((1)+(1)) 和 (2)=2((1)(2)+(2)) , 一层叠一层,从而产生更有表达能力的模型。
激活函数
ReLU函数
最受欢迎的激活函数是修正线性单元(Rectified linear unit,ReLU), 因为它实现简单,同时在各种预测任务中表现良好。 [ReLU提供了一种非常简单的非线性变换]。 给定元素 ,ReLU函数被定义为该元素与 0 的最大值:
ReLU()=max(,0).
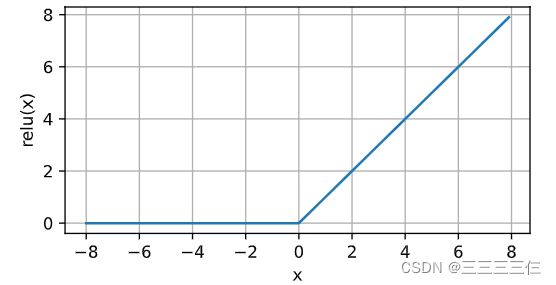
通俗地说,ReLU函数通过将相应的活性值设为0,仅保留正元素并丢弃所有负元素。 为了直观感受一下,我们可以画出函数的曲线图。 正如从图中所看到,激活函数是分段线性的。
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.relu(x)
d2l.plot(x.detach(), y.detach(), 'x', 'relu(x)', figsize=(5, 2.5))
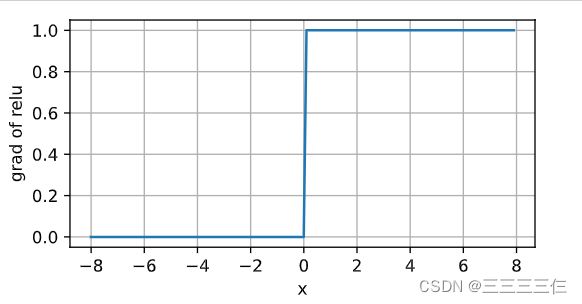
当输入为负时,ReLU函数的导数为0,而当输入为正时,ReLU函数的导数为1。
当输入值精确等于0时,ReLU函数不可导。 在此时,我们默认使用左侧的导数,即当输入为0时导数为0。 我们可以忽略这种情况,因为输入可能永远都不会是0。
y.backward(torch.ones_like(x), retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of relu', figsize=(5, 2.5))
使用ReLU的原因是,它求导表现得特别好:要么让参数消失,要么让参数通过。 这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题(稍后将详细介绍)。
注意,ReLU函数有许多变体,包括参数化ReLU(Parameterized ReLU,pReLU) 函数 :cite:He.Zhang.Ren.ea.2015。 该变体为ReLU添加了一个线性项,因此即使参数是负的,某些信息仍然可以通过:
pReLU()=max(0,)+min(0,)
sigmoid函数
对于一个定义域在 ℝ 中的输入, sigmoid函数将输入变换为区间(0, 1)上的输出。 因此,sigmoid通常称为挤压函数(squashing function): 它将范围(-inf, inf)中的任意输入压缩到区间(0, 1)中的某个值:
sigmoid()=1/(1+exp(−))
sigmoid函数是一个平滑的、可微的阈值单元近似。 当我们想要将输出视作二元分类问题的概率时, sigmoid仍然被广泛用作输出单元上的激活函数 (你可以将sigmoid视为softmax的特例)。 然而,sigmoid在隐藏层中已经较少使用, 它在大部分时候被更简单、更容易训练的ReLU所取代。 在后面关于循环神经网络的章节中,我们将描述利用sigmoid单元来控制时序信息流的架构。
下面,我们绘制sigmoid函数。 注意,当输入接近0时,sigmoid函数接近线性变换。
y = torch.sigmoid(x)
d2l.plot(x.detach(), y.detach(), 'x', 'sigmoid(x)', figsize=(5, 2.5))

sigmoid函数的导数为下面的公式:
(/)sigmoid()=exp(−)/(1+exp(−))²=sigmoid()(1−sigmoid()).
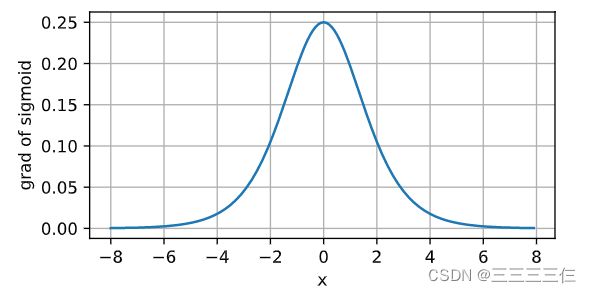
sigmoid函数的导数图像如下所示。 注意,当输入为0时,sigmoid函数的导数达到最大值0.25; 而输入在任一方向上越远离0点时,导数越接近0。
# 清除以前的梯度
x.grad.data.zero_()
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of sigmoid', figsize=(5, 2.5))
tanh函数
与sigmoid函数类似, [tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上]。 tanh函数的公式如下:
tanh()=1−exp(−2)/(1+exp(−2))
下面我们绘制tanh函数。 注意,当输入在0附近时,tanh函数接近线性变换。 函数的形状类似于sigmoid函数, 不同的是tanh函数关于坐标系原点中心对称。
y = torch.tanh(x)
d2l.plot(x.detach(), y.detach(), 'x', 'tanh(x)', figsize=(5, 2.5))
 tanh函数的导数是:
tanh函数的导数是:
(/)tanh()=1−tanh2().
tanh函数的导数图像如下所示。 当输入接近0时,tanh函数的导数接近最大值1。 与我们在sigmoid函数图像中看到的类似, 输入在任一方向上越远离0点,导数越接近0。
# 清除以前的梯度
x.grad.data.zero_()
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of tanh', figsize=(5, 2.5))

多层感知机的从零开始实现
导入包和数据集
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
初始化模型参数
忽略像素之间的空间结构, 我们可以将每个图像视为具有784个输入特征 和10个类的简单分类数据集。 首先,我们将[实现一个具有单隐藏层的多层感知机, 它包含256个隐藏单元]。 注意,我们可以将这两个变量都视为超参数。 通常,我们选择2的若干次幂作为层的宽度。 因为内存在硬件中的分配和寻址方式,这么做往往可以在计算上更高效。
num_inputs, num_outputs, num_hiddens = 784, 10, 256#隐藏层设置256
#nn.Parameter声明
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
激活函数
def relu(X):
a = torch.zeros_like(X)#数据类型一致,元素全为0
return torch.max(X, a)
模型
def net(X):
X = X.reshape((-1, num_inputs))#二维矩阵
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
损失函数
在这里我们直接使用高级API中的内置函数来计算softmax和交叉熵损失。
loss = nn.CrossEntropyLoss(reduction='none')
训练
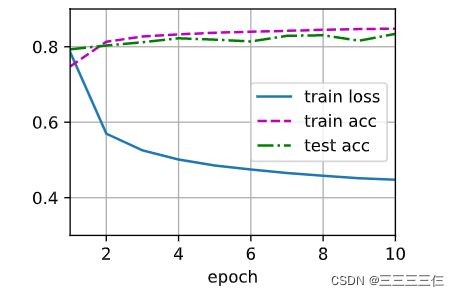
[多层感知机的训练过程与softmax回归的训练过程完全相同]。 可以直接调用d2l包的train_ch3函数。
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)

下图是softmax回归的结果,大家可以对比一下。
多层感知机的简洁实现
导包和数据集
import torch
from torch import nn
from d2l import torch as d2l
模型
与从零开始实现相比, 唯一的区别是我们添加了2个全连接层(之前我们只添加了1个全连接层)。 第一层是[隐藏层],它(包含256个隐藏单元,并使用了ReLU激活函数)。 第二层是输出层。
net = nn.Sequential(nn.Flatten(),#变成二维
nn.Linear(784, 256),#线性层
nn.ReLU(),#ReLu的激活函数
nn.Linear(256, 10))#输出
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
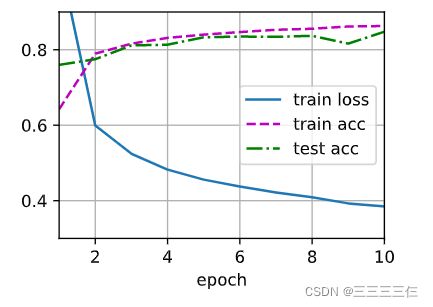
训练
与softmax几乎相同
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')#损失函数
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
问题
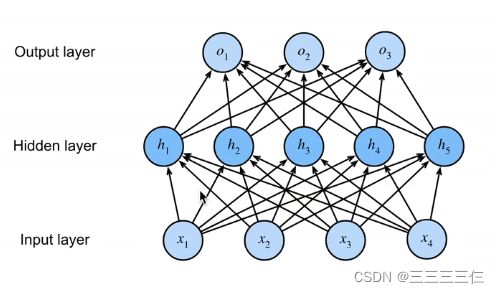
1.神经网络中的一层网络到底是指什么?是一层神经元经过线性变换后称为一层网络,还是一层神经元经过线性变化加非线性变换后称为一层?
神经网络中,一层是包含有激活函数的。
通常的一层是指带有权重的一层。
如下图,这里是有两层。每个箭头都表示一个权重。
2.为什么神经网络要增加隐藏层的层数而不是神经元的个数?
在学习过程中,增加神经元的个数容易造成过拟合,但是增加隐层层的个数,即一层一层堆起来,每一层完成一个小目标,最后形成输出结果,也就是深度学习