李宏毅机器学习L6 GAN
GAN网络
by 熠熠发光的白
distribution
当进行视频预测的时候,有时会出现分裂预测的情况,这是因为在训练过程中,有向左与向右的训练集,所以可能在预测的情况下有残影预测的出现。这种时候就需要提供一个simple distribution来给出一个概率分布,也就是此时的输出包含了向左和向右的可能。
unconditional generation
不带x,仅输入simple distribution给出输出y
conditional generation
带x的输出
GAN网络通过generator和discriminator的不断对抗,进行逐渐进步(discriminator需要不断地进行改善)
GAN网络的算法
第一步:固定用于生成的G算法,不断升级用于分辨的D算法。通过database里的图像取出部分进行sample,来训练discriminator
第二步:固定D算法,升级G算法,通过调整G算法的参数来进行调整,相当于将D和G拼接,并不改变D来试着将最后的得分提高,通过gradient ascent来让输出越大越好(在视频中0为完全不符,1为完全符合,因此这里不是使用gradient descent)
后面进行迭代执行
GAN背后的理论部分
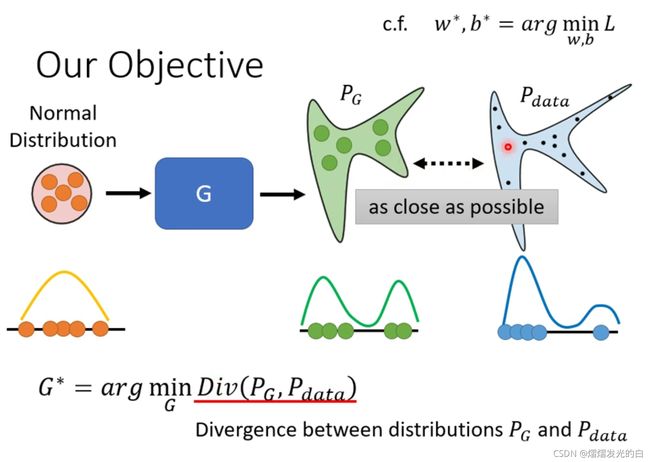
这里的loss function为 P G P_G PG和 P d a t a P_{data} Pdata的差距,虽然无法计算出这个divergence,但是GAN可以突破不知道怎么计算divergence的限制,也就是不需要知道 P G P_G PG和 P d a t a P_{data} Pdata的公式长什么样子,只要能sample就能计算divergence。
通过discriminator给sampled的数据打高分,给从 P G P_G PG中取样的数据打低分来进行计算。
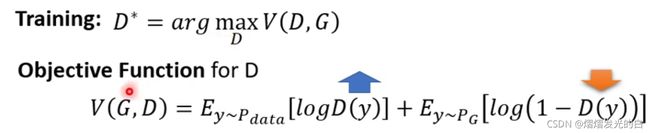
如图所示,在如果y是从 P d a t a P_{data} Pdata出来的,则是越大越好,y是从 P G P_G PG出来的,则是越小越好,通过找到一个合适的D来使V最大化,同样的,当两个数据集的差距很大的时候,所得到的的Objective function的值也就来的越大,两个数据集差距较小时,值也就越小
将 D ∗ D^* D∗的公式代入G中,就得到了一个min-max 的问题,即在最大的 P G P_G PG和 P d a t a P_{data} Pdata的差别下想办法修改Generator来得到个最小的值,为了得到这样的结果也就需要进行上节所说到的迭代。
Wasserstein distance
穷举所有的moving plan,然后从中找出让移动平均距离最短,作为Wasserstein distance
这样的好处是可以观察到divergence的优化过程,而不是像discriminator只能检测出一样的好或一样的差
而WGAN就是用Wasserstein distance来取代JS divergence 得到的结果

如图所示,这个就是求Wasserstein distance的方法,但是D必须要相对平滑,如果不够平滑会使得training无法收敛
通过weight的定义来调整WGAN,如果大于c则调整至c,如果小于-c则调整至-c,来让WGAN变得更平滑,更多调整可以查看待看文献
GAN for sequence generation
在使用GAN进行文字类型学习的时候,decoder产生一点点的变化对于discriminator的变化其实不大,因此可能计算出的 D m a x D_{max} Dmax并不会产生变化,在遇到这种问题的时候,可以使用reinforcement learning进行学习,但是由于GAN和RL的难度都很大,所以会导致这样十分难训练
Evaluation for Generation
最先是通过人脸来辨识,这样会不客观不稳定,所以使用了影像的分类系统,输入图片,输出几率分布,如果几率分布越集中,说明辨识效果更好。但是这个方法会被mode collapse所影响,也就是围绕一个真实图片进行模仿。如下图所示,这种情况目前唯一的解决方法就是时刻保存train point并在mode collapse发生之前暂停并选取之前的一个train point作为最终的模型。

同样的,如果generated data只是围绕着real data的一部分做识别的话,真实资料的多样性分布就难以被发现,解决方案是通过classify来进行分类,如果分类之后的类型较为集中,则说明多样性不够。
还有一种识别方法,即FID,通过取分类经过softmax层前的向量进行分类,即最后的hidden layer上的向量。将最后真实图片和生成图片出来的向量假设为两个Gaussian Distribution,而FID指的就是两个Gaussian之间的Fréchet distance。在代码测评时会同时看人脸的数量和FID来作为测评指标,从而得到比较合理而又精确的结果。
Conditional Generation
通过给特征和样例照片,来得出结果,可以用于给图片上色 https://arxiv.org/abs/1611.07004,也称为pix2pix,即image translation
GAN也可以和supervised learning进行配合使用,增加稳定性
同样,也可以应用于sound-to-image来通过听到的声音生成图片。
https://wjohn1483.github.io/audio_to_scene/index.html
Learning from Unpaired Data
GAN也可以帮我们在没有成对的资料进行学习的情况下进行转换,这里就要引入Cycle GAN
通过将domain x进行G转换为domain y,再进行G转换为domain x,要使两个图片尽量相似,就会让generator不断地进行调整,虽然没有理论能够证明,但是GAN偏向于使用相似的来进行转换而不是选择复杂的操作。
Cycle GAN同样也可以用于seq2seq的工作。
待看文献
https://arxiv.org/abs/1704.00028 Gradient penalty 保持gradient靠近在1
https://arxiv.org/abs/1802.05957 光谱正则化,使得所有地方的梯度都保持在比1小,效果最好的SNGAN
https://github.com/soumith/ganhacks tips from soumith
https://arxiv.org/abs/1511.06434 Tips in DCGAN: Guideline for network architecture design for image generation
https://arxiv.org/abs/1606.03498 improved techniques for training GANs
https://arxiv.org/abs/1809.11096 Tips from BigGAN
https://arxiv.org/abs/2007.02798 Gradient Origin Networks通过supervised learning来进行训练
https://arxiv.org/abs/1703.05192 Disco GAN
https://arxiv.org/abs/1704.02510 Dual GAN
https://arxiv.org/abs/1703.10593 Cycle GAN