深度学习机器学习面试题——GAN
深度学习机器学习笔试面试题——GAN
提示:互联网大厂可能会考的笔试面试题
GAN是用来干什么的,怎么用的,介绍一下
GANs的优缺点是什么?
GAN为什么不好收敛
为什么GAN中的优化器不常用SGD
生成对抗网络在哪里用到的,起什么作用,损失函数是什么
训练GAN的一些技巧
说说GAN的训练过程
Pix2pix和cycleGan的区别
文章目录
- 深度学习机器学习笔试面试题——GAN
-
- @[TOC](文章目录)
- GAN是用来干什么的,怎么用的,介绍一下
- DCGAN原理介绍
- GANs的优缺点是什么?
- GAN为什么不好收敛
- 为什么GAN中的优化器不常用SGD
- 生成对抗网络在哪里用到的,起什么作用,损失函数是什么
- 训练GAN的一些技巧
- 说说GAN的训练过程
- Pix2pix和cycleGan的区别
- 总结
文章目录
- 深度学习机器学习笔试面试题——GAN
-
- @[TOC](文章目录)
- GAN是用来干什么的,怎么用的,介绍一下
- DCGAN原理介绍
- GANs的优缺点是什么?
- GAN为什么不好收敛
- 为什么GAN中的优化器不常用SGD
- 生成对抗网络在哪里用到的,起什么作用,损失函数是什么
- 训练GAN的一些技巧
- 说说GAN的训练过程
- Pix2pix和cycleGan的区别
- 总结
GAN是用来干什么的,怎么用的,介绍一下
AN的主要灵感来源于博弈论中零和博弈的思想,应用到深度学习神经网络上来说,就是通过生成网络G(Generator)和判别网络D(Discriminator)不断博弈,进而使G学习到数据的分布。
最初GAN被应用到图片生成上,则训练完成后,G可以从一段随机数中生成逼真的图像。后来GAN的应用场景十分广泛,如图像生成、数据增强、图像编辑、恶意攻击检测、注意力预测、三维结构生成等。
GAN结构如下:
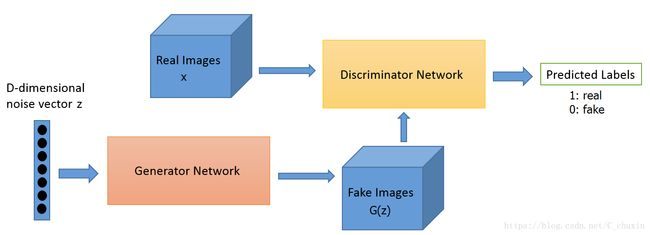
G, D的主要功能是:
G是一个生成式的网络,它接收一个随机的噪声z(随机数),通过这个噪声生成图像
D是一个判别网络,判别一张图片是不是“真实的”。
它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片
训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。
而D的目标就是尽量辨别出G生成的假图像和真实的图像。
这样,G和D构成了一个动态的“博弈过程”,最终的平衡点即纳什均衡点
最后博弈的结果是什么?
在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。
对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成图片。
如何用数学语言描述呢?这里直接摘录论文里的公式:
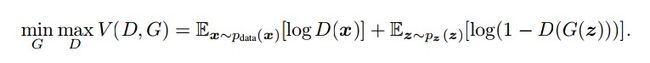
简单分析一下这个公式:
整个式子由两项构成。x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。
D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。
G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。
D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)
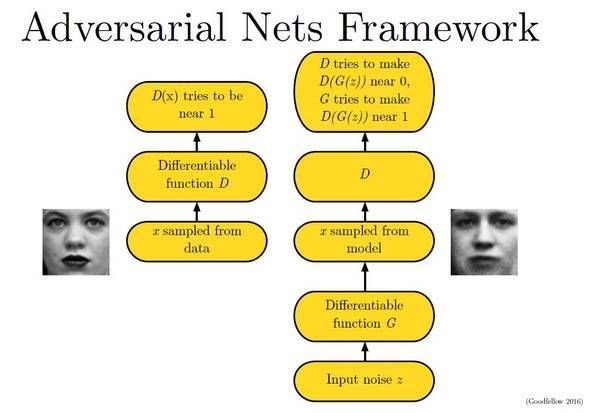
下面这幅图片很好地描述了这个过程:
那么如何用随机梯度下降法训练D和G?论文中也给出了算法:

这里红框圈出的部分是我们要额外注意的。
第一步我们训练D,D是希望V(G, D)越大越好,所以是加上梯度(ascending)。
第二步训练G时,V(G, D)越小越好,所以是减去梯度(descending)。
整个训练过程交替进行。
DCGAN原理介绍
我们知道深度学习中对图像处理应用最好的模型是CNN,那么如何把CNN与GAN结合?DCGAN是这方面最好的尝试之一
DCGAN的原理和GAN是一样的,这里就不在赘述。
它只是把上述的G和D换成了两个卷积神经网络(CNN)。
但不是直接换就可以了,DCGAN对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变有:
取消所有pooling层。G网络中使用转置卷积(transposed convolutional layer)进行上采样,D网络中用加入stride的卷积代替pooling。
在D和G中均使用batch normalization
去掉FC层,使网络变为全卷积网络
G网络中使用ReLU作为激活函数,最后一层使用tanh
D网络中使用LeakyReLU作为激活函数
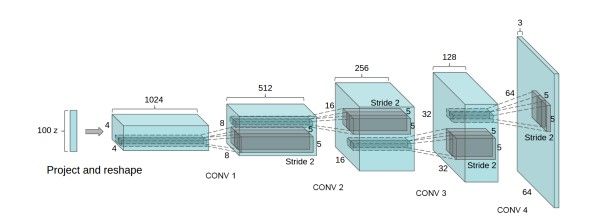
DCGAN中的G网络示意:
GANs的优缺点是什么?
GAN的优缺点
优点:
(1)GANs是一种以半监督方式训练分类器的方法,在没有很多带标签的训练集的时候,可以不做任何修改的直接使用GANs的代码
(2)GAN是一种生成式模型,相比较其他生成模型(玻尔兹曼机和GSNs)只用到了反向传播,而不需要复杂的马尔科夫链
(3)相比其他所有模型, GAN可以产生更加清晰,真实的样本
(4)相比VAE, GANs没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布.换句话说,GANs是渐进一致的,但是VAE是有偏差的
(5)GAN扩展到其他场景中十分简单,比如图片风格迁移,超分辨率,图像补全,去噪,避免了损失函数设计的困难,不管三七二十一,只要有一个的基准,直接上判别器,剩下的就交给对抗训练
缺点:
(1)训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到。我们还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的
(2)GAN不适合处理离散形式的数据,比如文本
(3)GAN训练不稳定。
GAN为什么不好收敛
(1)很难使一对模型(G和D 同时)收敛。
这也会造成以下第(2)点提到的模式崩溃。
大多深度模型的训练都使用优化算法寻找损失函数比较低的值。
优化算法通常是个可靠的“下山”过程。
生成对抗神经网络要求双方在博弈的过程中达到势均力敌(均衡)。
每个模型在更新的过程中(比如生成器)成功的“下山”,但同样的更新可能会造成博弈的另一个模型(比如判别器)“上山”。
甚至有时候博弈双方虽然最终达到了均衡,但双方在不断的抵消对方的进步并没有使双方同时达到一个有用的地方。
对所有模型同时梯度下降使得某些模型收敛但不是所有模型都达到收敛最优。
(2)生成器G发生模式崩溃(mode collapse,即所有的输入图像生成相同的输出)
对于不同的输入生成相似的样本,最坏的情况仅生成一个单独的样本,判别器的学习会拒绝这些相似甚至相同的单一样本。
在实际应用中~~,完全的模式崩溃很少~~ ,局部的模式崩溃很常见。
局部模式崩溃是指生成器使不同的图片包含相同的颜色或者纹理主题,或者不同的图片包含同一只狗的不同部分。
MinBatch GAN缓解了模式崩溃的问题但同时也引发了counting, perspective和全局结构等问题,这些问题通过设计更好的模型框架有可能解决。
(3)生成器梯度消失问题
当判别器D非常准确时,判别器的损失很快收敛到0,从而无法提供可靠的路径使生成器的梯度继续更新,造成生成器梯度消失。
GAN的训练因为一开始随机噪声分布,与真实数据分布相差距离太远,两个分布之间几乎没有任何重叠的部分,这时候判别器能够很快的学习把真实数据和生成的假数据区分开来达到判别器的最优,造成生成器的梯度无法继续更新甚至梯度消失。
为什么GAN中的优化器不常用SGD
SGD容易震荡,容易使GAN 训练不稳定,
GAN的目的是在高维非凸的参数空间中找到纳什均衡点,
GAN的纳什均衡点是一个鞍点,
但是SGD 只会找到局部极小值,
因为SGD解决的是一个寻找最小值的问题,GAN是一个博弈问题。
生成对抗网络在哪里用到的,起什么作用,损失函数是什么
GAN的主要灵感来源于博弈论中零和博弈的思想,应用到深度学习神经网络上来说,就是通过生成网络G(Generator)和判别网络D(Discriminator)不断博弈,进而使G学习到数据的分布。
最初GAN被应用到图片生成上,则训练完成后,G可以从一段随机数中生成逼真的图像。后来GAN的应用场景十分广泛,如图像生成、数据增强、图像编辑、恶意攻击检测、注意力预测、三维结构生成等。
GAN的损失函数是JS散度
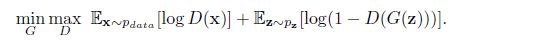
一切损失计算都是在D(判别器)输出处产生的,而D的输出一般是fake/true的判断,所以整体上采用的是二进制交叉熵函数。
左边包含两部分minG和maxD。
首先看一下maxD部分,因为训练一般是先保持G(生成器)不变训练D的。D的训练目标是正确区分fake/true,如果我们以1/0代表true/fake,则对第一项E因为输入采样自真实数据所以我们期望D(x)趋近于1,也就是第一项更大。同理第二项E输入采样自G生成数据,所以我们期望D(G(z))趋近于0更好,也就是说第二项又是更大。所以是这一部分是期望训练使得整体更大了,也就是maxD的含义了。
第二部分保持D不变,训练G,这个时候只有第二项E有用了,关键来了,因为我们要迷惑D,所以这时将label设置为1(我们知道是fake,所以才叫迷惑),希望D(G(z))输出接近于1更好,也就是这一项越小越好,这就是minG。当然判别器哪有这么好糊弄,所以这个时候判别器就会产生比较大的误差,误差会更新G,那么G就会变得更好了
大概就是这样一个博弈过程了。
训练GAN的一些技巧
(1)输入规范化到(-1,1)之间,最后一层的激活函数使用tanh(BEGAN除外)
(2)使用wassertein GAN的损失函数,
(3)如果有标签数据的话,尽量使用标签,也有人提出使用反转标签效果很好,另外使用标签平滑,单边标签平滑或者双边标签平滑
(4)使用mini-batch norm, 如果不用batch norm 可以使用instance norm 或者weight norm
(5)避免使用RELU和pooling层,减少稀疏梯度的可能性,可以使用leakrelu激活函数
(6)优化器尽量选择ADAM,学习率不要设置太大,初始1e-4可以参考,另外可以随着训练进行不断缩小学习率,
(7)给D的网络层增加高斯噪声,相当于是一种正则
说说GAN的训练过程
G, D的主要功能是:
G是一个生成式的网络,它接收一个随机的噪声z(随机数),通过这个噪声生成图像
D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片
训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。
而D的目标就是尽量辨别出G生成的假图像和真实的图像。
交替训练
这样,G和D构成了一个动态的“博弈过程”,最终的平衡点即纳什均衡点
Pix2pix和cycleGan的区别
pix2pix模型,其贡献点在于提出了用GAN来解决图像转换问题的通用方法,并且证明了其方法的有效性。
pix2pix模型虽然可以取得较好的效果,但是它的训练需要成对的数据,而对于很多图像转换问题,成对数据是很难获取的甚至不可能。
CycleGAN背后的关键思想是它们可以建立在PIX2PIX架构的强大功能之上,但允许将模型指向两个离散的,不成对的图像集合。
CycleGAN的创新点在于训练loss,而基本上与无网络结构关系不大。但是相比pix2pix模型,CycleGAN训练难度依然很大。具体到训练细节上,CycleGAN的对抗loss采用最小方差损失,而且训练判别器时采用一些历史生成数据。
(1)pix2pix模型和CycleGAN都可以用于图像转换。
(2)pix2pix模型的训练需要成对的数据;CycleGAN则不需要
(3)pix2pix模型的损失函数是cGan loss + L1;CycleGAN的损失函数是Gan loss + 循环一致loss(cycle consistency loss)
(4)pix2pix模型效果会更好;CycleGAN更容易训练。
总结
提示:重要经验:
1)生成式对抗网络GAN的结构,目的,均衡效果,训练过程,优缺点,这些都做简要的了解。
2)G的目标是生成尽可能真实的图片,欺骗D,D的目标是鉴别图片的真伪,尽量让自己更有判别性,交替训练,最终达到纳什均衡
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。