KAGGLE 比赛学习笔记---OTTO---baseline解读3
使用手工规则的候选重新排序模型
在本笔记本中,我们介绍了一个使用手工规则的“候选人重新排名”模型。我们可以通过设计功能,将其合并到项目和用户,并训练一个重新排序模型(如XGB)来选择我们的最后20个。此外,为了优化和改进这个笔记本,我们应该构建一个本地CV方案来实验新的逻辑和/或模型。
更新:我在这里发布了一个笔记本,使用这里描述的Radek方案计算验证分数。
请注意,在本次比赛中,“会话”实际上意味着独特的“用户”。因此,我们的任务是预测1671803个测试“用户”(即“会话”)中的每一个将来会做什么。对于每个测试“用户”(即“会话”),我们必须预测他们在一周的剩余测试期间将单击、购物车和订购什么
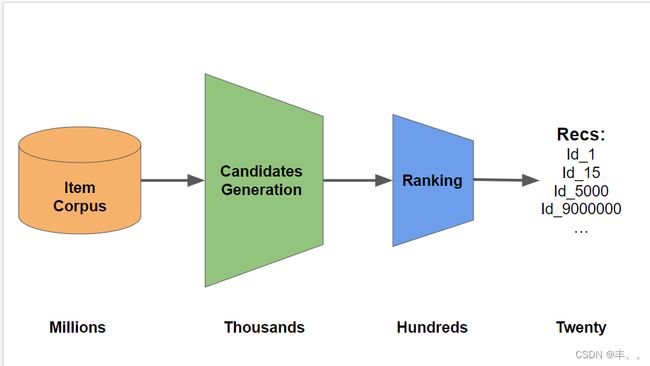
步骤1-生成候选
对于每个测试用户,我们生成可能的选择,即候选项。在本笔记本中,我们从5个来源生成候选项:
点击、购物车、订单的用户历史记录
测试周最受欢迎的20次点击、购物车和订单
点击/购物车/订单到购物车/订购的共访问矩阵(带类型权重)
购物车/订单到购物车/订购的共同访问矩阵称为buy2buy
点击/购物车/订单与时间加权的共同访问矩阵
步骤2-重新排名并选择20
鉴于候选名单,我们必须选择20个作为我们的预测。在这个笔记本中,我们用一套手工制定的规则来完成这项工作。我们可以通过训练XGBoost模型来改进我们的预测。我们手工制定的规则优先考虑:
最近访问过的项目
以前多次访问的项目
购物车或订单中以前的项目
购物车/订单到购物车/定单的共同访问矩阵
当前流行项目
信用
我们使用弗拉基米尔的共同访问矩阵思想。我们在这里的评论部分使用了Sinan的groupby排序逻辑。我们在这里使用Radek的重复预测删除逻辑。我们在这里使用Pietro的多次访问逻辑。这里我们使用Ingvaras的类型加权逻辑。我们在这里使用了我以前笔记本上的泄漏测试数据。
步骤1-使用RAPID生成候选项
对于候选生成,我们构建了三个共同访问矩阵。根据用户先前的点击/购物车/订单,计算购物车/订购的流行程度。我们将类型权重应用于此矩阵。根据用户先前的购物车/订单计算购物车/定单的流行程度。我们称之为“buy2buy”矩阵。一个计算用户先前点击/购物车/订单的点击率。我们对该矩阵应用时间加权。我们将使用RAPID cuDF GPU快速计算这些矩阵!
VER = 5
import pandas as pd, numpy as np
from tqdm.notebook import tqdm
import os, sys, pickle, glob, gc
from collections import Counter
import cudf, itertools
print('We will use RAPIDS version',cudf.__version__)
#Compute Three Co-visitation Matrices with RAPIDS
#We will compute 3 co-visitation matrices using RAPIDS cuDF on GPU. This is 30x faster than using Pandas CPU like other public notebooks! For maximum speed, set the variable DISK_PIECES to the smallest number possible based on the GPU you are using without incurring memory errors. If you run this code offline with 32GB GPU ram, then you can use DISK_PIECES = 1 and compute each co-visitation matrix in almost 1 minute! Kaggle's GPU only has 16GB ram, so we use DISK_PIECES = 4 and it takes an amazing 3 minutes each! Below are some of the tricks to speed up computation
#
#Use RAPIDS cuDF GPU instead of Pandas CPU
#Read disk once and save in CPU RAM for later GPU multiple use
#Process largest amount of data possible on GPU at one time
#Merge data in two stages. Multiple small to single medium. Multiple medium to single large.
#Write result as parquet instead of dictionary
%%time
# CACHE FUNCTIONS
def read_file(f):
return cudf.DataFrame( data_cache[f] )
def read_file_to_cache(f):
df = pd.read_parquet(f)
df.ts = (df.ts/1000).astype('int32')
df['type'] = df['type'].map(type_labels).astype('int8')
return df
# CACHE THE DATA ON CPU BEFORE PROCESSING ON GPU
data_cache = {}
type_labels = {'clicks':0, 'carts':1, 'orders':2}
files = glob.glob('../input/otto-chunk-data-inparquet-format/*_parquet/*')
for f in files: data_cache[f] = read_file_to_cache(f)
# CHUNK PARAMETERS
READ_CT = 5
CHUNK = int( np.ceil( len(files)/6 ))
print(f'We will process {len(files)} files, in groups of {READ_CT} and chunks of {CHUNK}.')
#1) "Carts Orders" Co-visitation Matrix - Type Weighted
%%time
type_weight = {0:1, 1:6, 2:3}
# USE SMALLEST DISK_PIECES POSSIBLE WITHOUT MEMORY ERROR
DISK_PIECES = 4
SIZE = 1.86e6/DISK_PIECES
# COMPUTE IN PARTS FOR MEMORY MANGEMENT
for PART in range(DISK_PIECES):
print()
print('### DISK PART',PART+1)
# MERGE IS FASTEST PROCESSING CHUNKS WITHIN CHUNKS
# => OUTER CHUNKS
for j in range(6):
a = j*CHUNK
b = min( (j+1)*CHUNK, len(files) )
print(f'Processing files {a} thru {b-1} in groups of {READ_CT}...')
# => INNER CHUNKS
for k in range(a,b,READ_CT):
# READ FILE
df = [read_file(files[k])]
for i in range(1,READ_CT):
if k+i<b: df.append( read_file(files[k+i]) )
df = cudf.concat(df,ignore_index=True,axis=0)
df = df.sort_values(['session','ts'],ascending=[True,False])
# USE TAIL OF SESSION
df = df.reset_index(drop=True)
df['n'] = df.groupby('session').cumcount()
df = df.loc[df.n<30].drop('n',axis=1)
# CREATE PAIRS
df = df.merge(df,on='session')
df = df.loc[ ((df.ts_x - df.ts_y).abs()< 24 * 60 * 60) & (df.aid_x != df.aid_y) ]
# MEMORY MANAGEMENT COMPUTE IN PARTS
df = df.loc[(df.aid_x >= PART*SIZE)&(df.aid_x < (PART+1)*SIZE)]
# ASSIGN WEIGHTS
df = df[['session', 'aid_x', 'aid_y','type_y']].drop_duplicates(['session', 'aid_x', 'aid_y'])
df['wgt'] = df.type_y.map(type_weight)
df = df[['aid_x','aid_y','wgt']]
df.wgt = df.wgt.astype('float32')
df = df.groupby(['aid_x','aid_y']).wgt.sum()
# COMBINE INNER CHUNKS
if k==a: tmp2 = df
else: tmp2 = tmp2.add(df, fill_value=0)
print(k,', ',end='')
print()
# COMBINE OUTER CHUNKS
if a==0: tmp = tmp2
else: tmp = tmp.add(tmp2, fill_value=0)
del tmp2, df
gc.collect()
# CONVERT MATRIX TO DICTIONARY
tmp = tmp.reset_index()
tmp = tmp.sort_values(['aid_x','wgt'],ascending=[True,False])
# SAVE TOP 40
tmp = tmp.reset_index(drop=True)
tmp['n'] = tmp.groupby('aid_x').aid_y.cumcount()
tmp = tmp.loc[tmp.n<15].drop('n',axis=1)
# SAVE PART TO DISK (convert to pandas first uses less memory)
tmp.to_pandas().to_parquet(f'top_15_carts_orders_v{VER}_{PART}.pqt')
#2) "Buy2Buy" Co-visitation Matrix
%%time
# USE SMALLEST DISK_PIECES POSSIBLE WITHOUT MEMORY ERROR
DISK_PIECES = 1
SIZE = 1.86e6/DISK_PIECES
# COMPUTE IN PARTS FOR MEMORY MANGEMENT
for PART in range(DISK_PIECES):
print()
print('### DISK PART',PART+1)
# MERGE IS FASTEST PROCESSING CHUNKS WITHIN CHUNKS
# => OUTER CHUNKS
for j in range(6):
a = j*CHUNK
b = min( (j+1)*CHUNK, len(files) )
print(f'Processing files {a} thru {b-1} in groups of {READ_CT}...')
# => INNER CHUNKS
for k in range(a,b,READ_CT):
# READ FILE
df = [read_file(files[k])]
for i in range(1,READ_CT):
if k+i<b: df.append( read_file(files[k+i]) )
df = cudf.concat(df,ignore_index=True,axis=0)
df = df.loc[df['type'].isin([1,2])] # ONLY WANT CARTS AND ORDERS
df = df.sort_values(['session','ts'],ascending=[True,False])
# USE TAIL OF SESSION
df = df.reset_index(drop=True)
df['n'] = df.groupby('session').cumcount()
df = df.loc[df.n<30].drop('n',axis=1)
# CREATE PAIRS
df = df.merge(df,on='session')
df = df.loc[ ((df.ts_x - df.ts_y).abs()< 14 * 24 * 60 * 60) & (df.aid_x != df.aid_y) ] # 14 DAYS
# MEMORY MANAGEMENT COMPUTE IN PARTS
df = df.loc[(df.aid_x >= PART*SIZE)&(df.aid_x < (PART+1)*SIZE)]
# ASSIGN WEIGHTS
df = df[['session', 'aid_x', 'aid_y','type_y']].drop_duplicates(['session', 'aid_x', 'aid_y'])
df['wgt'] = 1
df = df[['aid_x','aid_y','wgt']]
df.wgt = df.wgt.astype('float32')
df = df.groupby(['aid_x','aid_y']).wgt.sum()
# COMBINE INNER CHUNKS
if k==a: tmp2 = df
else: tmp2 = tmp2.add(df, fill_value=0)
print(k,', ',end='')
print()
# COMBINE OUTER CHUNKS
if a==0: tmp = tmp2
else: tmp = tmp.add(tmp2, fill_value=0)
del tmp2, df
gc.collect()
# CONVERT MATRIX TO DICTIONARY
tmp = tmp.reset_index()
tmp = tmp.sort_values(['aid_x','wgt'],ascending=[True,False])
# SAVE TOP 40
tmp = tmp.reset_index(drop=True)
tmp['n'] = tmp.groupby('aid_x').aid_y.cumcount()
tmp = tmp.loc[tmp.n<15].drop('n',axis=1)
# SAVE PART TO DISK (convert to pandas first uses less memory)
tmp.to_pandas().to_parquet(f'top_15_buy2buy_v{VER}_{PART}.pqt')
#3) "Clicks" Co-visitation Matrix - Time Weighted
%%time
# USE SMALLEST DISK_PIECES POSSIBLE WITHOUT MEMORY ERROR
DISK_PIECES = 4
SIZE = 1.86e6/DISK_PIECES
# COMPUTE IN PARTS FOR MEMORY MANGEMENT
for PART in range(DISK_PIECES):
print()
print('### DISK PART',PART+1)
# MERGE IS FASTEST PROCESSING CHUNKS WITHIN CHUNKS
# => OUTER CHUNKS
for j in range(6):
a = j*CHUNK
b = min( (j+1)*CHUNK, len(files) )
print(f'Processing files {a} thru {b-1} in groups of {READ_CT}...')
# => INNER CHUNKS
for k in range(a,b,READ_CT):
# READ FILE
df = [read_file(files[k])]
for i in range(1,READ_CT):
if k+i<b: df.append( read_file(files[k+i]) )
df = cudf.concat(df,ignore_index=True,axis=0)
df = df.sort_values(['session','ts'],ascending=[True,False])
# USE TAIL OF SESSION
df = df.reset_index(drop=True)
df['n'] = df.groupby('session').cumcount()
df = df.loc[df.n<30].drop('n',axis=1)
# CREATE PAIRS
df = df.merge(df,on='session')
df = df.loc[ ((df.ts_x - df.ts_y).abs()< 24 * 60 * 60) & (df.aid_x != df.aid_y) ]
# MEMORY MANAGEMENT COMPUTE IN PARTS
df = df.loc[(df.aid_x >= PART*SIZE)&(df.aid_x < (PART+1)*SIZE)]
# ASSIGN WEIGHTS
df = df[['session', 'aid_x', 'aid_y','ts_x']].drop_duplicates(['session', 'aid_x', 'aid_y'])
df['wgt'] = 1 + 3*(df.ts_x - 1659304800)/(1662328791-1659304800)
df = df[['aid_x','aid_y','wgt']]
df.wgt = df.wgt.astype('float32')
df = df.groupby(['aid_x','aid_y']).wgt.sum()
# COMBINE INNER CHUNKS
if k==a: tmp2 = df
else: tmp2 = tmp2.add(df, fill_value=0)
print(k,', ',end='')
print()
# COMBINE OUTER CHUNKS
if a==0: tmp = tmp2
else: tmp = tmp.add(tmp2, fill_value=0)
del tmp2, df
gc.collect()
# CONVERT MATRIX TO DICTIONARY
tmp = tmp.reset_index()
tmp = tmp.sort_values(['aid_x','wgt'],ascending=[True,False])
# SAVE TOP 40
tmp = tmp.reset_index(drop=True)
tmp['n'] = tmp.groupby('aid_x').aid_y.cumcount()
tmp = tmp.loc[tmp.n<20].drop('n',axis=1)
# SAVE PART TO DISK (convert to pandas first uses less memory)
tmp.to_pandas().to_parquet(f'top_20_clicks_v{VER}_{PART}.pqt')
# FREE MEMORY
del data_cache, tmp
_ = gc.collect()
第 2 步 - 使用手工规则重新排序
#Step 2 - ReRank (choose 20) using handcrafted rules¶
def load_test():
dfs = []
for e, chunk_file in enumerate(glob.glob('../input/otto-chunk-data-inparquet-format/test_parquet/*')):
chunk = pd.read_parquet(chunk_file)
chunk.ts = (chunk.ts/1000).astype('int32')
chunk['type'] = chunk['type'].map(type_labels).astype('int8')
dfs.append(chunk)
return pd.concat(dfs).reset_index(drop=True) #.astype({"ts": "datetime64[ms]"})
test_df = load_test()
print('Test data has shape',test_df.shape)
test_df.head()
%%time
def pqt_to_dict(df):
return df.groupby('aid_x').aid_y.apply(list).to_dict()
# LOAD THREE CO-VISITATION MATRICES
top_20_clicks = pqt_to_dict( pd.read_parquet(f'top_20_clicks_v{VER}_0.pqt') )
for k in range(1,DISK_PIECES):
top_20_clicks.update( pqt_to_dict( pd.read_parquet(f'top_20_clicks_v{VER}_{k}.pqt') ) )
top_20_buys = pqt_to_dict( pd.read_parquet(f'top_15_carts_orders_v{VER}_0.pqt') )
for k in range(1,DISK_PIECES):
top_20_buys.update( pqt_to_dict( pd.read_parquet(f'top_15_carts_orders_v{VER}_{k}.pqt') ) )
top_20_buy2buy = pqt_to_dict( pd.read_parquet(f'top_15_buy2buy_v{VER}_0.pqt') )
# TOP CLICKS AND ORDERS IN TEST
top_clicks = test_df.loc[test_df['type']=='clicks','aid'].value_counts().index.values[:20]
top_orders = test_df.loc[test_df['type']=='orders','aid'].value_counts().index.values[:20]
print('Here are size of our 3 co-visitation matrices:')
print( len( top_20_clicks ), len( top_20_buy2buy ), len( top_20_buys ) )
#type_weight_multipliers = {'clicks': 1, 'carts': 6, 'orders': 3}
type_weight_multipliers = {0: 1, 1: 6, 2: 3}
def suggest_clicks(df):
# USER HISTORY AIDS AND TYPES
aids=df.aid.tolist()
types = df.type.tolist()
unique_aids = list(dict.fromkeys(aids[::-1] ))
# RERANK CANDIDATES USING WEIGHTS
if len(unique_aids)>=20:
weights=np.logspace(0.1,1,len(aids),base=2, endpoint=True)-1
aids_temp = Counter()
# RERANK BASED ON REPEAT ITEMS AND TYPE OF ITEMS
for aid,w,t in zip(aids,weights,types):
aids_temp[aid] += w * type_weight_multipliers[t]
sorted_aids = [k for k,v in aids_temp.most_common(20)]
return sorted_aids
# USE "CLICKS" CO-VISITATION MATRIX
aids2 = list(itertools.chain(*[top_20_clicks[aid] for aid in unique_aids if aid in top_20_clicks]))
# RERANK CANDIDATES
top_aids2 = [aid2 for aid2, cnt in Counter(aids2).most_common(20) if aid2 not in unique_aids]
result = unique_aids + top_aids2[:20 - len(unique_aids)]
# USE TOP20 TEST CLICKS
return result + list(top_clicks)[:20-len(result)]
def suggest_buys(df):
# USER HISTORY AIDS AND TYPES
aids=df.aid.tolist()
types = df.type.tolist()
# UNIQUE AIDS AND UNIQUE BUYS
unique_aids = list(dict.fromkeys(aids[::-1] ))
df = df.loc[(df['type']==1)|(df['type']==2)]
unique_buys = list(dict.fromkeys( df.aid.tolist()[::-1] ))
# RERANK CANDIDATES USING WEIGHTS
if len(unique_aids)>=20:
weights=np.logspace(0.5,1,len(aids),base=2, endpoint=True)-1
aids_temp = Counter()
# RERANK BASED ON REPEAT ITEMS AND TYPE OF ITEMS
for aid,w,t in zip(aids,weights,types):
aids_temp[aid] += w * type_weight_multipliers[t]
# RERANK CANDIDATES USING "BUY2BUY" CO-VISITATION MATRIX
aids3 = list(itertools.chain(*[top_20_buy2buy[aid] for aid in unique_buys if aid in top_20_buy2buy]))
for aid in aids3: aids_temp[aid] += 0.1
sorted_aids = [k for k,v in aids_temp.most_common(20)]
return sorted_aids
# USE "CART ORDER" CO-VISITATION MATRIX
aids2 = list(itertools.chain(*[top_20_buys[aid] for aid in unique_aids if aid in top_20_buys]))
# USE "BUY2BUY" CO-VISITATION MATRIX
aids3 = list(itertools.chain(*[top_20_buy2buy[aid] for aid in unique_buys if aid in top_20_buy2buy]))
# RERANK CANDIDATES
top_aids2 = [aid2 for aid2, cnt in Counter(aids2+aids3).most_common(20) if aid2 not in unique_aids]
result = unique_aids + top_aids2[:20 - len(unique_aids)]
# USE TOP20 TEST ORDERS
return result + list(top_orders)[:20-len(result)]
Create Submission CSV
%%time
pred_df_clicks = test_df.sort_values(["session", "ts"]).groupby(["session"]).apply(
lambda x: suggest_clicks(x)
)
pred_df_buys = test_df.sort_values(["session", "ts"]).groupby(["session"]).apply(
lambda x: suggest_buys(x)
clicks_pred_df = pd.DataFrame(pred_df_clicks.add_suffix("_clicks"), columns=["labels"]).reset_index()
orders_pred_df = pd.DataFrame(pred_df_buys.add_suffix("_orders"), columns=["labels"]).reset_index()
carts_pred_df = pd.DataFrame(pred_df_buys.add_suffix("_carts"), columns=["labels"]).reset_index()
pred_df = pd.concat([clicks_pred_df, orders_pred_df, carts_pred_df])
pred_df.columns = ["session_type", "labels"]
pred_df["labels"] = pred_df.labels.apply(lambda x: " ".join(map(str,x)))
pred_df.to_csv("submission.csv", index=False)
pred_df.head()
运行结果
We will process 17 files, in groups of 5 and chunks of 3.
### DISK PART 1
Processing files 0 thru 2 in groups of 5...
0 ,
Processing files 3 thru 5 in groups of 5...
3 ,
Processing files 6 thru 8 in groups of 5...
6 ,
Processing files 9 thru 11 in groups of 5...
9 ,
Processing files 12 thru 14 in groups of 5...
12 ,
Processing files 15 thru 16 in groups of 5...
15 ,
### DISK PART 2
Processing files 0 thru 2 in groups of 5...
0 ,
Processing files 3 thru 5 in groups of 5...
3 ,
Processing files 6 thru 8 in groups of 5...
6 ,
Processing files 9 thru 11 in groups of 5...
9 ,
Processing files 12 thru 14 in groups of 5...
12 ,
Processing files 15 thru 16 in groups of 5...
15 ,
### DISK PART 3
Processing files 0 thru 2 in groups of 5...
0 ,
Processing files 3 thru 5 in groups of 5...
3 ,
Processing files 6 thru 8 in groups of 5...
6 ,
Processing files 9 thru 11 in groups of 5...
9 ,
Processing files 12 thru 14 in groups of 5...
12 ,
Processing files 15 thru 16 in groups of 5...
15 ,
### DISK PART 4
Processing files 0 thru 2 in groups of 5...
0 ,
Processing files 3 thru 5 in groups of 5...
3 ,
Processing files 6 thru 8 in groups of 5...
6 ,
Processing files 9 thru 11 in groups of 5...
9 ,
Processing files 12 thru 14 in groups of 5...
12 ,
Processing files 15 thru 16 in groups of 5...
15 ,
### DISK PART 1
Processing files 0 thru 2 in groups of 5...
0 ,
Processing files 3 thru 5 in groups of 5...
3 ,
Processing files 6 thru 8 in groups of 5...
6 ,
Processing files 9 thru 11 in groups of 5...
9 ,
Processing files 12 thru 14 in groups of 5...
12 ,
Processing files 15 thru 16 in groups of 5...
15 ,
### DISK PART 1
Processing files 0 thru 2 in groups of 5...
0 ,
Processing files 3 thru 5 in groups of 5...
3 ,
Processing files 6 thru 8 in groups of 5...
6 ,
Processing files 9 thru 11 in groups of 5...
9 ,
Processing files 12 thru 14 in groups of 5...
12 ,
Processing files 15 thru 16 in groups of 5...
15 ,
### DISK PART 2
Processing files 0 thru 2 in groups of 5...
0 ,
Processing files 3 thru 5 in groups of 5...
3 ,
Processing files 6 thru 8 in groups of 5...
6 ,
Processing files 9 thru 11 in groups of 5...
9 ,
Processing files 12 thru 14 in groups of 5...
12 ,
Processing files 15 thru 16 in groups of 5...
15 ,
### DISK PART 3
Processing files 0 thru 2 in groups of 5...
0 ,
Processing files 3 thru 5 in groups of 5...
3 ,
Processing files 6 thru 8 in groups of 5...
6 ,
Processing files 9 thru 11 in groups of 5...
9 ,
Processing files 12 thru 14 in groups of 5...
12 ,
Processing files 15 thru 16 in groups of 5...
15 ,
### DISK PART 4
Processing files 0 thru 2 in groups of 5...
0 ,
Processing files 3 thru 5 in groups of 5...
3 ,
Processing files 6 thru 8 in groups of 5...
6 ,
Processing files 9 thru 11 in groups of 5...
9 ,
Processing files 12 thru 14 in groups of 5...
12 ,
Processing files 15 thru 16 in groups of 5...
15 ,
Test data has shape (6928123, 4)
Here are size of our 3 co-visitation matrices:
691799 168826 691799
[Finished in 1329.2s]