(一)反向传播算法理解 (Back-Propagation)
本文参考deeplearningbook.org一书第六章 6.5 Back-Propagation and Other Differentiation
Algorithms
反向传播算法分为两篇来讲,第一篇讲概念理解,第二篇用RNN简单推导。
第一篇就是本文 (一)反向传播算法理解 (Back-Propagation)
第二篇的链接(二)RNN 的 反向传播算法详细推导
下面我们就开始吧~
首先明确反向传播算法用来做什么:求梯度。
一、前向传播 foward propagation
“反向传播算法”,其中 反向 两个字顾名思义,先有一个前向的过程,才有反向一说。所以要搞懂反向传播之前,需先把前向传播弄清楚。简易地画了一个流程图如下:(图中的LOSS是一个实数值)。

上图中,前向传播路径是从输入到LOSS ,反向传播路径是从LOSS到参数(因为我们求梯度只要求参数的梯度就好了)。
前向和反向有两点不同的地方,一是方向相反,二是计算的内容不同,它两也有一样的地方,那就是一步步的向前走/向后走。反向传播求梯度就是一步步的求,而不是一步到位。
二、为什么要用反向传播算法求梯度
首先,我们可用数值法求得梯度(根据导数的定义来求解梯度),但是有个缺点,那就是参数多时,特别费时间,很慢。此方法排除。
再者,从输入到LOSS会有一个完整的函数表达式,直接根据这个函数式推导得到参数的导数表达式,再代入数值计算得到导数不就好了嘛。推导参数的导数表达式有两种方式,一是化简直接求导,二是链式求导。
假设 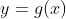 并且
并且 ![]() ,我们求 z 对 x 的导数:
,我们求 z 对 x 的导数:
直接求导:![]() (式一)
(式一)
链式求导:![]() (式二)
(式二)
对于直接求导方式, 式一 中要先求出 h 函数,即对 f(g(x)) 进行化简,当嵌套的函数较多或者函数复杂的时候,化简会比较复杂,并且化简得到的表达式也较难简单到很容易求导的地步,感觉没必要多走这么一步。此方法排除。
因此我们现在只讨论式二,即运用链式求导法,但是在实际应用中会涉及到在前向传播过程中是否保存中间计算结果的问题,如下图所示标明了两者的区别:

图中前向1在进行过程中不保存中间结果 y,那么在反向计算![]() 时需要先把 y 算出来。也就是在前向传播过程中要算
时需要先把 y 算出来。也就是在前向传播过程中要算  ,然后计算
,然后计算 ![]() ,算完
,算完![]() 之后把y占用的内存释放掉。在反向计算梯度的时候要算,然后算
之后把y占用的内存释放掉。在反向计算梯度的时候要算,然后算![]() ,然后算
,然后算![]() 。如此说来是计算了两遍的。
。如此说来是计算了两遍的。
图中前向2在进行过程中保存中间结果 y ,那么在反向求梯度的时候就不会再计算。也就是 在前向传播过程中要算 ,然后计算 ![]() ,保存 y 的数据。在反向计算梯度的时候要算
,保存 y 的数据。在反向计算梯度的时候要算![]() ,然后算
,然后算![]() 。如此说来只计算了一遍。
。如此说来只计算了一遍。
类似 g 函数这种中间函数越多,重复计算的函数就越多。比如一个函数![]() ,求导表达式如下:
,求导表达式如下:
如果在前向中不保存中间结果,前向传播时要计算![]() ,然后算
,然后算![]() 紧接着释放w占用内存,然后算
紧接着释放w占用内存,然后算![]() 紧接着释放 v 占用内存,然后算
紧接着释放 v 占用内存,然后算![]() 紧接着释放 y 占用内存。在反向计算梯度时要算
紧接着释放 y 占用内存。在反向计算梯度时要算![]() ,
,![]() ,
,![]() ,
,![]() ,算
,算![]() ,
,![]() ,
,![]() ,算
,算![]() ,
,![]() ,算
,算![]() (此时反向计算时也没保存中间结果)。我们可以算一下在反向传播的时候
(此时反向计算时也没保存中间结果)。我们可以算一下在反向传播的时候![]() 要计算3次,
要计算3次,![]() 要计算2次,
要计算2次,![]() 要计算1次,其实这些在前向传播时已经算过一遍了。如果将
要计算1次,其实这些在前向传播时已经算过一遍了。如果将![]() ,
, ![]() ,
,![]() 保存起来,反向传播的时候只需要计算
保存起来,反向传播的时候只需要计算![]() ,
,![]() ,
,![]() ,
,![]() 就好了。
就好了。
但是保存中间数据的代价就是会消耗内存资源。不保存中间数据就消耗计算资源。
反向传播算法是一种保存中间数据的运用链式求导的求梯度算法,是一种以空间换取时间的算法。
三、计算图
上文已经讲过如果在前向计算中存储中间结果,那么在反向计算中只需要求 ![]() ,
,![]() ,
,![]() ,
,![]() 就好了,那求这几个有没有顺序呢?是有的。我们上式都是在求最终结果 z 对最底层变量 x 的梯度,其实在深度学习中,中间层有很多的参数,每一层的参数都不一样,我们想要求的是 z 对中间层各个参数的梯度,那么我们在反向传播的时候要先计算
就好了,那求这几个有没有顺序呢?是有的。我们上式都是在求最终结果 z 对最底层变量 x 的梯度,其实在深度学习中,中间层有很多的参数,每一层的参数都不一样,我们想要求的是 z 对中间层各个参数的梯度,那么我们在反向传播的时候要先计算![]() ,然后
,然后![]() ,然后
,然后![]() ,然后
,然后![]() ,按照这个顺序,可以把中间层各个变量的梯度都求出来。下边解释。
,按照这个顺序,可以把中间层各个变量的梯度都求出来。下边解释。
上文说反向传播和前向传播一样是一步步算的,这个一步步就体现在计算顺序上,这就要涉及计算图。
我们拿这个式子举例子。
计算图以变量为结点,以操作为边。我们可以把上式的计算图画出来:

然后反向传播的时候计算梯度的顺序如下:

先算![]() ,并且保存;然后算
,并且保存;然后算![]() ,紧接着和保存起来的
,紧接着和保存起来的![]() 相乘,就算得了
相乘,就算得了![]() ,并且保存;
,并且保存;
然后算![]() ,紧接着和保存起来的
,紧接着和保存起来的![]() 相乘,就算得了
相乘,就算得了![]() ,并且保存;
,并且保存;
然后算![]() , 紧接着和保存起来的
, 紧接着和保存起来的![]() 相乘,就算得了
相乘,就算得了![]() ,并且保存。
,并且保存。
也就是说从后往前依次算,可以算得 z (LOSS) 对中间各个变量的梯度。
四、总结
总结来讲反向传播算法就是以空间换时间,运用链式求导一步步从后往前求梯度的算法。
反向传播算法的大体理解就讲完啦,有不正确的地方欢迎各位大佬指正~