基于时间的反向传播算法BPTT(Backpropagation through time)
本文是读“Recurrent Neural Networks Tutorial, Part 3 – Backpropagation Through Time and Vanishing Gradients”的读书笔记,加入了自己的一些理解,有兴趣可以直接阅读原文。
1. 算法介绍
这里引用原文中的网络结构图
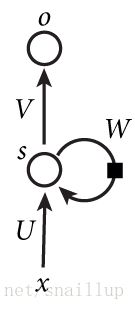
其中 x x x为输入, s s s为隐藏层状态,o为输出,按时间展开

为了与文献中的表示一致,我们用 y ^ \hat y y^来代替o,则
s t = t a n h ( U x t + W s t − 1 ) y ^ = s o f t m a t ( V s t ) s_t=tanh(Ux_t+Ws_{t-1}) \\ \hat y=softmat(Vs_t) st=tanh(Uxt+Wst−1)y^=softmat(Vst)
使用交叉熵(cross entropy)作为损失函数
E t ( y , y ^ ) = − y t l o g y ^ E ( y , y ^ ) = ∑ t E t ( y t , y ^ t ) = − ∑ t y t l o g y ^ E_t(y,\hat y)=-y_tlog\hat y \\ E(y, \hat y) = \sum_t E_t(y_t, \hat y_t)=-\sum_t y_tlog\hat y Et(y,y^)=−ytlogy^E(y,y^)=t∑Et(yt,y^t)=−t∑ytlogy^
我们使用链式法则来计算后向传播时的梯度,以网络的输出 E 3 E_3 E3为例,
y ^ 3 = e z 3 ∑ i e z i E 3 = − y 3 l o g y ^ 3 = − y 3 ( z 3 − l o g ∑ i e z i ) z 3 = V s 3 s 3 = t a n h ( U x 3 + W s 2 ) \hat y_3=\frac{e^{z_3}}{\sum_ie^{z_i}} \\ E_3=-y_3log\hat y_3=-y_3(z_3-log\sum_ie^{z_i}) \\ z_3=Vs_3 \\ s_3=tanh(Ux_3+Ws_2) y^3=∑ieziez3E3=−y3logy^3=−y3(z3−logi∑ezi)z3=Vs3s3=tanh(Ux3+Ws2)
因此可以求V的梯度
∂ E 3 ∂ V = ∂ E 3 ∂ z ^ 3 ∂ z 3 ∂ V = y 3 ( y ^ 3 − 1 ) ∗ s 3 \frac{\partial E_3}{\partial V}=\frac{\partial E_3}{\partial \hat z_3}\frac{\partial z_3}{\partial V}=y_3(\hat y_3-1)*s3 ∂V∂E3=∂z^3∂E3∂V∂z3=y3(y^3−1)∗s3
这里求导时将 y ^ 3 \hat y_3 y^3带入消去了,求导更直观,这里给出的是标量形式,改成向量形式应该是 y ^ − 1 3 \hat y-1_3 y^−13,也就是输出概率矩阵中,对应结果的那个概率-1,其他不变,而输入y恰好可以认为是对应结果的概率是1,其他是0,因此原文中写作
∂ E 3 ∂ V = ( y ^ 3 − y 3 ) ⊗ s 3 \frac{\partial E_3}{\partial V}=(\hat y_3-y_3)\otimes s_3 ∂V∂E3=(y^3−y3)⊗s3
相对V的梯度,因为 s t s_t st是W,U的函数,而且含有的 s t − 1 s_{t-1} st−1在 求导时,不能简单的认为是一个常数,因此在求导时,如果不加限制,需要对从t到0的所有状态进行回溯,在实际中一般按照场景和精度要求进行截断。
∂ E 3 ∂ W = ∂ E 3 ∂ z ^ 3 ∂ z 3 ∂ s 3 ∂ s 3 ∂ s k ∂ s k ∂ W \frac{\partial E_3}{\partial W}=\frac{\partial E_3}{\partial \hat z_3}\frac{\partial z_3}{\partial s_3}\frac{\partial s_3}{\partial s_k}\frac{\partial s_k}{\partial W} ∂W∂E3=∂z^3∂E3∂s3∂z3∂sk∂s3∂W∂sk
其中 s 3 s_3 s3对W的求导是一个分部求导
∂ s t ∂ W = ( 1 − s t 2 ) ( s t − 1 + W ∗ ∂ s t − 1 ∂ s W ) \frac{\partial s_t}{\partial W}=(1-s_t^2)(s_{t-1}+W*\frac{\partial s_{t-1}}{\partial s_{W}}) ∂W∂st=(1−st2)(st−1+W∗∂sW∂st−1)
U的梯度类似
∂ s t ∂ U = ( 1 − s t 2 ) ( x t + W ∗ ∂ s t − 1 ∂ s U ) \frac{\partial s_t}{\partial U}=(1-s_t^2)(x_t+W*\frac{\partial s_{t-1}}{\partial s_{U}}) ∂U∂st=(1−st2)(xt+W∗∂sU∂st−1)
2. 代码分析
首先我们给出作者自己实现的完整的BPTT,再各部分分析
def bptt(self, x, y):
T = len(y)
# Perform forward propagation
o, s = self.forward_propagation(x)
# We accumulate the gradients in these variables
dLdU = np.zeros(self.U.shape)
dLdV = np.zeros(self.V.shape)
dLdW = np.zeros(self.W.shape)
delta_o = o
delta_o[np.arange(len(y)), y] -= 1.
# For each output backwards...
for t in np.arange(T)[::-1]:
dLdV += np.outer(delta_o[t], s[t].T)
# Initial delta calculation: dL/dz
delta_t = self.V.T.dot(delta_o[t]) * (1 - (s[t] ** 2))
# Backpropagation through time (for at most self.bptt_truncate steps)
for bptt_step in np.arange(max(0, t-self.bptt_truncate), t+1)[::-1]:
# print "Backpropagation step t=%d bptt step=%d " % (t, bptt_step)
# Add to gradients at each previous step
dLdW += np.outer(delta_t, s[bptt_step-1])
dLdU[:,x[bptt_step]] += delta_t
# Update delta for next step dL/dz at t-1
delta_t = self.W.T.dot(delta_t) * (1 - s[bptt_step-1] ** 2)
return [dLdU, dLdV, dLdW]
2.1. 初始化
结合完整的代码,我们可知梯度的维度
#100*8000
dLdU = np.zeros(self.U.shape)
#8000*100
dLdV = np.zeros(self.V.shape)
#100*100
dLdW = np.zeros(self.W.shape)
2.2. 公共部分
对照上面的理论可知,无论是V,还是U,W,都有 ∂ E 3 ∂ z ^ 3 \frac{\partial E_3}{\partial \hat z_3} ∂z^3∂E3,这部分可以预先计算出来,也就是代码中的delta_o
#o是forward的输出,T(句子的实际长度)*8000维,每一行是8000维的,就是词表中所有词作为输入x中每一个词的后一个词的概率
delta_o = o
#[]中是索引操作,对y中的词对应的索引的概率-1
delta_o[np.arange(len(y)), y] -= 1.
2.3. V的梯度
s [ t ] . T s[t].T s[t].T是取 s [ t ] s[t] s[t]的转置,numpy.outer是将第一个参数和第二个参数中的所有元素分别按行展开,然后拿第一个参数中的数因此乘以第二个参数的每一行,例如 a = [ a 0 , a 1 , . . . , a M ] a=[a_0, a_1, ..., a_M] a=[a0,a1,...,aM], b = [ b 0 , b 1 , . . . , b N ] b=[b_0, b_1, ..., b_N] b=[b0,b1,...,bN],则相乘后变成
[ [ a 0 ∗ b 0 a 0 ∗ b 1 . . . a 0 ∗ b N ] [ a 1 ∗ b 0 a 1 ∗ b 1 . . . a 1 ∗ b N ] . . . [ a M ∗ b 0 a M ∗ b 1 . . . a M ∗ b N ] ] [[a_0*b_0\quad a_0*b_1 \quad ... \quad a_0*b_N] \\ [a_1*b_0\quad a_1*b_1 \quad ... \quad a_1*b_N] \\ ... \\ [a_M*b_0\quad a_M*b_1 \quad ... \quad a_M*b_N]] [[a0∗b0a0∗b1...a0∗bN][a1∗b0a1∗b1...a1∗bN]...[aM∗b0aM∗b1...aM∗bN]]
结果是M*N维的
#delta_o是1*8000维向量,s[t]是1*100的向量,转不转置对outer并没有什么区别,其实和delta_o[t].T * s[t]等价,*是矩阵相乘,结果是8000*100维的矩阵
dLdV += np.outer(delta_o[t], s[t].T)
2.4. W和U的梯度
对比W和U的梯度公式,我们可以看到,两者+号的第二部分前面的系数是一样的,也就是 ( 1 − s t 2 ) ∗ W (1-s_t^2)*W (1−st2)∗W,这部分可以存起来减少计算量,也就是代码中的delta_t
delta_t = self.V.T.dot(delta_o[t]) * (1 - (s[t] ** 2))
# Backpropagation through time (for at most self.bptt_truncate steps)
#截断
for bptt_step in np.arange(max(0, t-self.bptt_truncate), t+1)[::-1]:
# print "Backpropagation step t=%d bptt step=%d " % (t, bptt_step)
# Add to gradients at each previous step
#计算+号的第一部分,第二部分本次还没得到,下次累加进来
dLdW += np.outer(delta_t, s[bptt_step-1])
#x为单词的位置向量,与delta_t相乘相当于dLdU按x取索引(对应的词向量)直接与delta_t相加
dLdU[:,x[bptt_step]] += delta_t
# Update delta for next step dL/dz at t-1
#更新第二部分系数
delta_t = self.W.T.dot(delta_t) * (1 - s[bptt_step-1] ** 2)