Kubernetes详解
1、Kubernetes介绍
Kubernetes是一个完备的分布式系统支撑平台。Kubernetes具有完备的集群管理能力,包括多层次的安全防护和准入机制/多租户应用支撑能力、透明的服务注册和服务发现机制、内建智能负载均衡器、强大的故障发现和自我修复功能、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制,以及多粒度的资源配额管理能力。同时kubernetes提供了完善的管理工具,这些工具覆盖了包括开发、测试部署、运维监控在内的各个环节;因此kubernetes是一个全新的基于容器技术的分布式架构解决方案,并且是一个一站式的完备的分布式系统开发和支撑平台。
2、Master介绍
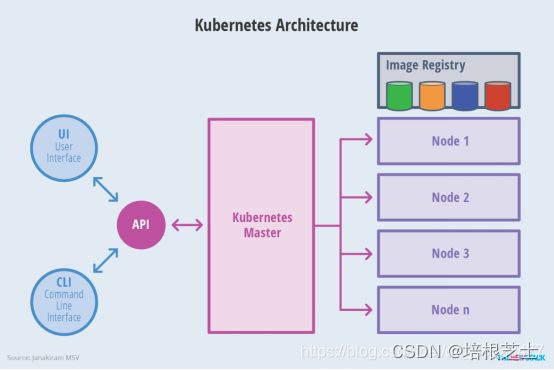
Kubernetes 里的Master指的是集群控制节点,每个Kubernetes集群里需要有一个Master节点来负责整个集群的管理和控制,基本上Kubernetes所有的控制命令都发给它,它负责具体的执行过程,我们后面执行的所有命令基本上都是在Master节点上运行的。如果Master宕机或不可用,那么集群内容器的管理都将失效master节点上运行一些关键进程:
- 1)k8s API server(kube-apiserver),提供了HTTP Rest接口的关键服务进程,是所有资源的增删改查的唯一入口,也是集群集群控制的入口进程。kubectl的命令会调用到api server,来实现资源的增删查改。
- 2)kube-controller-manager,k8s所有资源对象的自动化控制中心。
- 3)kube-scheduler,pod调度进程。
- 4)另外往往还启动了一个etcd服务,因为k8s里所有资源对象的数据全部是保存在etcd中的,etcd是一个高可用的键值存储系统,主要用于共享配置和服务发现。

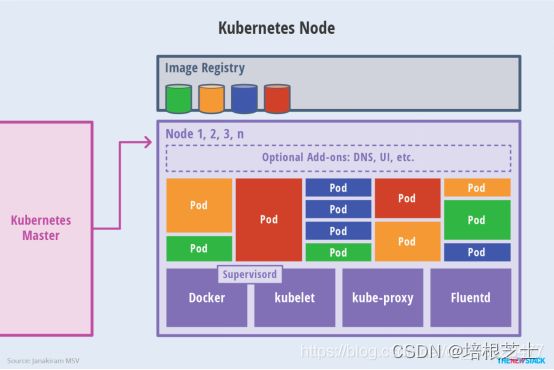
3、Node介绍
除了Master,集群中其他机器被称为Node节点,每个Node都会被Master分配一些工作负载docker容器,当某个Node宕机时,其上的工作负载会被Master自动转移到其他节点上去。
每个Node节点上都运行着以下一组关键进程:
- 1)kubelet:负责Pod对应容器的创建、停止等任务,同时与Master节点密切协作,实现集群管理的基本功能
- 2)kube-proxy:实现Kubernetes Service的通信与负载均衡机制的重要组件。
- 3)Docker Engine(Docker):Docker引擎,负责本机的容器创建和管理工作。
查看当前nodes:kubectl get nodes
然后通过下面命令查看某个node的详细信息:kubectl describe node
4、Kubernetes 中Master与Node工作内容
在集群管理方面,Kubernets将集群中的机器划分为一个Master节点和一群工作节点(Node),其中,在Master节点上运行着集群管理相关的一组进程kube-apiserver、kube-controller-manager和kube-scheduler,这些进程实现了整个集群的资源管理、Pod调度、弹性收缩、安全控制、系统监控和纠错等管理功能,并且都是全自动完成的。Node作为集群中的工作节点,运行真正的应用程序,在Node上Kubernetes管理的最小运行单元是Pod。Node上运行着Kubernetes的kubelet、kube-proxy服务进程,这些服务进程负责Pod创建、启动、监控、重启、销毁、以及实现软件模式的负载均衡
5、Pod介绍
Pod是kubernetes最重要也最基本的概念,如图所示是Pod的组成示意图,我们看到每个Pod都有一个特殊的被称为“根容器”的Pause容器对应的镜像属于Kubernetes的平台的一部分,除了Pause容器,每个Pod还包含一个或多个紧密相关的用户业务容器。

每个pod由一个根容器的pause容器,其他是业务容器。
k8s为每个pod分配了唯一的IP地址,一个pod里的多个容器共享pod IP。
pod其实有两种类型:普通的pod和静态pod,后者比较特殊,它并不存放在etcd存储中,而是存放在某个具体的Node上的一个具体文件中,并且只在此Node上启动运行。而普通的pod一旦被创建,就会被放入etcd中存储。随后被master调度到某个具体的Node上并进行绑定,随后该pod被对应的Node上的kubelet进程实例化成一组相关的docker容器并启动起来。
每个pod都可以对其使用的服务器上的计算资源设置限额,当前可以设置限额的源有CPU和memory两种。其中CPU的资源单位为CPU的数量。
一般而言,一个CPU的配额已经算是相当大的一个资源配额,所以在k8s中,通常以千分之一的CPU配额为最小单位,以m来表示,通常一个容器的CPU配额为100-300m,即占用0.1-0.3个CPU。这个配额是个绝对值,不是占比。
在k8s中,一个计算资源进行配额限定需要设定两个参数:
requests,资源的最小申请量,系统必须满足要求
6、Label
一个label是一个key=value的键值组合,然后可以通过label selector(标签选择器)查询和筛选拥有某些label的资源对象。
(Label 相当于我们熟悉的标签,给某个资源对象定义一个Label,就相当于给它打了一个标签,随后可以通过Label Selector 标签选择器 查询和筛选有某些Label的资源对象。Kubernetes通过这种方式实现了类似SQL的简单又通用的对象查询机制)。
label的重要使用场景:
kube-controller进程通过资源对象RC上定义的label selector来筛选要监控的pod的数量,从而实现全自动控制流程。
kube-proxy进程通过service的label selector来选择对应的pod,自动建立起每个service到对应pod的请求转发路由表。从而实现service的智能负载均衡机制。
7、RC(Replication Controller)
当我们定义了一个RC并提交到Kubernetes集群中以后,Master节点上的Controller Manager组件就得到通知,定期巡检系统中当前存活的目标Pod,并确保目标Pod实力的数量刚好等于此RC的期望值,如果有过多的Pod副本在运行,系统就会停掉一些Pod,否则系统就会再自动创建一些Pod。 可以说,通过RC,Kubernetes实现了用户应用集群的高可用性,并大大减少了传统IT需要手动的工作
RC定义了如下
- Pod期待的副本数(replicas)
- 用于筛选目标Pod的Label Seletcor(标签选择器)
- 当Pod的副本小于预期(replicas)时,用于创建新Pod的Pod模板(template)
删除RC并不会影响通过该RC已创建号的Pod。为了删除所有Pod,可以设置replicas的值为0,然后更新该RC。另外,kubectl提供了stop和delete命令来一次性删除RC和RC控制的全部Pod
8、HPA(horizontal Pod Autoscaler Pod横向自动扩容)
通过手动执行kubectl scale命令,可以通过RC实现pod扩容。
HPA,pod横向自动扩容,实现原理是通过追踪分析RC控制的所有目标Pod的负载变化情况,来确定是否需要针对性地挑战目标pod的副本数。
有两种方式作为pod负载的度量指标。
- CPU utilization percentage
- 应用程序自定义的度量指标,比如服务在每秒内的相应的请求数。
CPU utilization percentage是一个算术平均值,目标pod所有副本自身的CPU利用率的平均值。一个Pod自身的CPU利用率是该Pod当前CPU使用量除以它的Pod request的值。比如当我们定义一个Pod的pod request为0.4,而当前pod的cpu使用量为0.2,则使用率为50%。如此可以得出一个平均值,如果某一个时刻CPU utilization percentage超过80%,则表示当前副本数不够,需要进行扩容。
9、service
Service是Kubernetes里最核心的资源对象之一,Service定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口地址访问其背后的一组由Pod副本组成的集群实力。 Service与其后端Pod副本集群之间则是通过Label Selector来实现"无缝对接"。而RC的作用实际上是保证Service 的服务能力和服务质量处于预期的标准
每个pod会被分配一个独立的IP地址,也就是每个pod都提供一个独立的endpoint(IP+port)以被访问,那多个pod如何被客户端访问呢,k8s通过运行在每个Node上的kube-proxy进程,负责将对service的请求转发到后端某个pod实例上,也就实现了类似负载均衡器的功能,至于具体转发到哪个pod,则由负载均衡器的算法所决定。并且service不是共用一个负载均衡器的IP地址,而是每一个service分配了一个全局唯一的虚拟IP,这样每个服务就变成了具有唯一IP的通信节点,服务调用也就变成了最为基础的TCP通信问题。
pod的Endpoint地址会随着Pod的销毁和重新创建而发生改变,因为新的Pod地址与之前的旧的Pod不同。而Service一旦被创建,Kubernetes就会自动为它分配一个可用的Cluster IP,而且在Service的整个声明周期内,它的Cluster IP不会发生改变。所以只要将Service的name与Service的Cluster IP地址做一个DNS域名映射即可解决问题。
k8s的服务发现机制:每个service都有一个唯一的cluster IP以及唯一的名字,而名字是由开发者自己定义的,部署的时候也没必要改变,所以完全可以固定在配置中,接下来的问题 就是如何通过service的名字找到对应的cluster IP。
外部系统访问service的问题:
k8s中有三种IP:
- Node IP:node节点的IP地址
- Pod IP:pod的IP地址
- cluster IP:service IP
首先,Node IP是k8s集群中每个节点的物理网卡的IP地址,这是一个真实存在的物理网络,所有属于这个网络的服务器之间都能直接通信,不管属不属于k8s集群。这也表明了k8s集群之外的节点访问k8s集群之内的某个节点后者TCP/IP服务的时候,必须要通过Node IP通信。
其次,pod IP是每个Pod的IP地址,它是根据docker网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,因此不同pod之间的通信就是通过Pod IP所在的虚拟二层网络进行通信的。而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出的。
Cluster IP,它是一个虚拟IP,但更像是一个伪造的IP网络
(1)Cluster IP仅仅作用于Kubernetes Service对象,并由Kubernetes管理和分配IP地址(来源于Cluster IP地址池)
(2)Cluster IP无法被Ping,因为没有一个"实体网络对象"来响应
(3)在Kubernetes集群内,Node IP、Pod IP、Cluster IP之间的通信,采用的是Kubernetes自己设计的特殊路由规则
10、Volume 存储卷
Volume是pod中能够被多个容器访问的共同目录。也就是被定义在pod上,然后被一个pod中的多个容器挂载到具体的文件目录下,其次,volume与pod生命周期相同,但与容器生命周期不相关,当容器终止或重启,volume中的数据也不会丢失
11、namespace命名空间
大多数情况下用于实现多租户的资源隔离,namespace通过将集群内部的资源对象分配到不同的namespace中,形成逻辑上分组的不同项目、小组,便于不同的分组在共享使用整个集群的资源的同时还能被分别管理。
namespace的定义很简单,如下所示的yaml定义了名为development的namespace
apiVersion: v1
kind: Namespace
metadata:
name: development
一旦创建了Namespace,我们在创建资源对象时就可以指定这个资源对象属于哪个namespace,比如下面,定义了名为busybox的Pod,放入development这个namespace里:
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: development
12、kubernetes基础命令
kubectl getkubectl get命令用来获取资源信息列表,可用来查看pod是否健康,当前的运行状态,重启了几次,生命周期等,是最常用的命令之一
kubectl get pod获取pod资源列表,默认获取default命名空间
kubectl get pod -n kube-system获取kube-system命名空间的pod资源列表
kubectl get pod --all-namespaces获取所有命名空间的pod资源列表
kubectl get pod -n kube-system kube-apiserver-k8s-01获取kube-system命名空间中指定的pod:kube-apiserver-k8s-01的信息
当查看某个具体的pod时,必须指明该pod所在的命名空间,像–all-namespaces参数是不能使用的
kubectl get pod -n kube-system kube-apiserver-k8s-01 -o wide获取kube-system命名空间中指定的pod:kube-apiserver-k8s-01的信息,并且展示更多信息,包括pod ip,所在节点等信息
kubectl get pod -n kube-system kube-apiserver-k8s-01 -o yaml获取kube-system命名空间中指定的pod:kube-apiserver-k8s-01的信息,并且以yaml格式展示pod详细信息
kubectl get pod -n kube-system kube-apiserver-k8s-01 -o json获取kube-system命名空间中指定的pod:kube-apiserver-k8s-01的信息,并且以json格式展示pod详细信息
kubectl get pod --all-namespaces --watch监控pod资源的变化
上述命令中的pod为kubernetes集群中的一种资源对象,其它资源对象,例如:deployment、deamonset、endpoint、ingress、services、secrets等等,都可以用get命令,全部的资源对象详见这里
kubectl describe打印所选资源的详细描述信息,当pod启动异常的时候也可以用该命令排查问题
kubectl describe -n kube-system pod kube-apiserver-k8s-01描述pod:kube-apiserver-k8s-01的详细信息
kubectl describe -n kube-system secrets kubernetes-dashboard-token-9mvxp
描述secrets详细信息,例如该命令可查询登录dashboard所需的token信息
kubectl exec与docker exec命令一样,kubectl exec 也是用来进入容器内部的
kubectl exec -it -n kube-system kube-apiserver-k8s-01 sh进入kube-system命名空间下的kube-apiserver-k8s-01容器内部
仅当pod内只有一个容器的时候适用
kubectl exec -it -n kube-system calico-node-rw4c2 -c install-cni sh-it:开启虚拟终端tty,并将标准输入传入容器中
-i, --stdin=false: Pass stdin to the container
-t, --tty=false: Stdin is a TTY
当pod中有多个容器,需要进入指定的容器时适用,比上一条命令多了-c container_name
container_name可以通过kubectl describe命令获得
kubectl describe pod calico-node-rw4c2 -n kube-system | grep -B 1 “Container ID”kubectl logskubectl logs用来查看容器的日志,在定位问题时非常有用
kubectl logs -n kube-system -f --tail 10 kube-apiserver-k8s-01-f: 动态打印日志
–tail 10: 打印最后10行日志,不加该参数时默认会打印全部的日志,在日志非常多的时候非常有用
kubectl scalekubectl scale用来对deployement、replicaset、statefulset等资源进行伸缩
kubectl scale deployment -n kube-system --replicas=2 kubernetes-dashboard–replicas=2: 指定副本数量为2
先设置replicas=0,再设置replicas=1可实现pod重启操作
kubectl apply通过传入文件名或者标准输入来创建资源或配置
kubectl apply -f .创建或更新当前目录所有的yaml文件描述的配置或资源
kubectl apply -f /home/agms/创建或更新指定目录所有的yaml文件描述的配置或资源
kubectl apply -f /home/agms/a.yaml创建或更新指定yaml文件描述的配置或资源
kubectl delete
kubectl delete -f .删除当前目录所有的yaml文件描述的配置或资源
kubectl delete -f /home/agms/删除指定目录所有的yaml文件描述的配置或资源
kubectl delete -f /home/agms/a.yaml删除指定yaml文件描述的配置或资源
kubectl delete nodes k8s-01按照节点名删除集群中的节点(慎用)
kubectl explain *列出受支持资源的字段、版本,各字段的描述、类型等,在编写yaml文件时非常有用
kubectl explain deployment.spec描述deployment资源的spec字段
kubectl create通过命令行创建kubernetes资源或配置信息
kubectl create namespace fpi-inc创建一个fpi-inc的命名空间
一般建议通过kubectl apply的方式来进行资源或配置的创建