Python项目实战 —— 03. 数据分析师岗位需求分析
Python项目实战
- Python项目实战--目录
- Python项目实战 —— 03. 数据分析师岗位需求分析
-
- 一、背景
- 二、解题思路
- 三、数据分析
-
- 3.1 数据清理
- 3.2 数据分析&可视化
-
- 3.2.1 整体情况 - 岗位数、薪资情况
- 3.2.2 整体情况 - 学历、工作经验
- 3.2.3 TopN行业/公司的岗位数、薪资情况
- 3.2.4 岗位对能力的要求
- 3.2.5 对某城市进行细分
- 四、结论
- 五、可视化代码
-
- 5.1 整体代码
- 5.2 城市代码
Python项目实战–目录
Python项目实战 —— 03. 数据分析师岗位需求分析
一、背景
在《中国经济的数字化转型:人才与就业》报告中提到,因国家政策趋势,数据分析人才紧缺,预计到2025年将达到230万。此外,还了解到2020年9月浙江八年级新增Python课程,日后‘人均会数据分析’将成常态。因此,我们可以分析下对数据分析师岗位的需求~
点此下载数据集
二、解题思路
从以下几个角度,分析数据分析师岗位的招聘需求:
① 总体情况,如岗位数、薪资情况、学历要求、工作经验要求等;
② TopN行业/公司的岗位数、薪资情况等;
③ 岗位对能力的要求;
④ 对某城市进行细分;
三、数据分析
3.1 数据清理
查重 ➔ 缺失值处理 ➔ 数据加工 ➔ 按上述思路,对数据分组
import pandas as pd
import matplotlib.pyplot as plt
import jieba
from pyecharts.charts import *
import pyecharts.options as opts
''' →数据加工← '''
df = pd.read_csv('/XXXXXX/boss.csv',names=['公司','职位','地区','薪资','经验','行业','要求能力'])
# 对原数据进行处理,即去重、整理字段等
print('文件中有{}行重复数据,已删除.'.format(len(df[df.duplicated()])))
df.drop_duplicates(inplace=True)
df['学历1']=df.经验.str[-2:]
df['学历']=df.学历1.apply(lambda x:'大专以下' if ((x=='高中') or (x=='中技')) else x)
df['工作经验1']=df.经验.str[:-2].str.replace('学历','').str.replace('中专/','')
df['工作经验']=df.工作经验1.apply(lambda x:'应届生' if (('天/周' in x) or (x=='在校/应届')) else x)
df['薪资类型']=df.薪资.map(lambda x:'日薪' if ('元/天' in x) else '月薪')
df['薪资min']=df.薪资.apply(lambda x:x.split('·')[0].replace('K','').replace('元/天','').split('-')[0]).astype(float)
df['薪资max']=df.薪资.apply(lambda x:x.split('·')[0].replace('K','').replace('元/天','').split('-')[1]).astype(float)
print('因为原数据中,薪资有按月&按天计算的,所以按天计算的需转换成月薪资(一个月有22个工作日).')
m = df.query(" 薪资类型=='日薪' ").drop('薪资类型',axis=1)
m['salary_min'] = m.薪资min*22/1000
m['salary_max'] = m.薪资max*22/1000
n = df.query(" 薪资类型=='月薪' ").drop('薪资类型',axis=1)
n['salary_min'] = n.薪资min
n['salary_max'] = n.薪资max
df0 = pd.concat([m,n],ignore_index=True)
df0['salary_avg'] = (df0.salary_min + df0.salary_max)/2
df0.drop(columns=['薪资min','薪资max','工作经验1','学历1'],axis=1,inplace=True)
''' →数据分组←
df1_1 : 从城市角度分析(按岗位数排序)
df1_2 : 从学历/工作经验角度分析
df1_3 : 从行业/公司角度分析
df1_4 : 从能力角度分析 - jieba&%tb计每个词出现的次数
m/n : top5/bottom5城市薪资情况 '''
df1_1 = df0.groupby('地区').agg({'职位':'count','salary_min':'mean','salary_max':'mean','salary_avg':'mean'})
df1_1.columns = ['岗位数','最低工资','最高工资','平均工资']
df1_1.sort_values(by='岗位数',ascending=False,inplace=True)
a1 = str(df1_1.岗位数.sum()).center(7)+'\n--------\n'.center(8)+'岗位数'.center(8)
a2 = str(df1_1.mean().round(2)[1]).center(7)+'\n--------\n'.center(8)+'最低工资'
a3 = str(df1_1.mean().round(2)[2]).center(7)+'\n--------\n'.center(8)+'最高工资'
a4 = str(df1_1.mean().round(2)[3]).center(7)+'\n--------\n'.center(8)+'平均工资'
df1_2 = df0.groupby(['学历','工作经验']).agg({'职位':'count','salary_min':'mean','salary_max':'mean',\
'salary_avg':'mean'}).reset_index()
df1_2.columns = ['学历','工作经验','岗位数','最低工资','最高工资','平均工资']
a5 = df1_2.groupby('学历').agg({'岗位数':'sum','最低工资':'mean','最高工资':'mean',\
'平均工资':'mean'}).sort_values('平均工资',ascending=False)
a6 = df1_2.groupby('工作经验').agg({'岗位数':'sum','最低工资':'mean','最高工资':'mean',\
'平均工资':'mean'}).sort_values('平均工资',ascending=False)
m = df1_1.iloc[:5,:].round(1) # top5城市
n = df1_1.iloc[-5:,:].round(1) # bottom5城市
df1_3 = df0.groupby(['行业','公司']).agg({'职位':'count','salary_avg':'mean'}).reset_index()
df1_3.columns = ['行业','公司','岗位数','平均工资']
a7 = df1_3.groupby('行业').agg({'岗位数':'sum','平均工资':'mean'}).sort_values('岗位数',ascending=False)
a8 = df1_3.groupby('公司').agg({'岗位数':'sum','平均工资':'mean'}).sort_values('岗位数',ascending=False)
a7_1 = a7.iloc[:5,:] # top5行业
a8_1 = a8.iloc[:10,:] # top10公司
s = ''.join(df0.要求能力) # 字符串
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_{|}~《》?!,。:()…的是了':
s = s.replace(ch,'')
jieba.add_word('Python') # 向分词词典添加新的词语(一次的)
jieba.add_word('MySQL')
jieba.add_word('Pandas')
jieba.add_word('Excel')
jieba.add_word('BI')
jieba.add_word('Tableau')
df1_4 = pd.DataFrame(jieba.lcut(s),columns=['能力']).能力.value_counts().sort_values(ascending=False)
a9 = df1_4.iloc[1:int(df1_4.shape[0]*0.2)] # 前20%的能力,根据实际情况分析
3.2 数据分析&可视化
从已下载的数据集可以看出,文件中只有部分数据,所以以解题思路为准,可视化结果仅供参考,谢谢!
3.2.1 整体情况 - 岗位数、薪资情况

3.2.2 整体情况 - 学历、工作经验


3.2.3 TopN行业/公司的岗位数、薪资情况


3.2.4 岗位对能力的要求

3.2.5 对某城市进行细分


四、结论
① 在boss上发布的数据分析师岗位,共计2526个、最低工资11.02k、最高工资18.46k、平均工资14.74k;
② 从学历角度分析,招聘的岗位有85%是面向本科及其以上的,本科占比为79%;工资大致分为3个阶段:博士为第一阶段,平均薪资为34.17k;硕士&本科为第二阶段,平均薪资为17.8k;大专及其以下为第三阶段,平均薪资为7k;
③ 从工作经验角度分析,3-5年的占比较多,其次是1-3年的;薪资情况如上图所示(在这一方面,个人认为数据量较少,影响最终结果的判断;结果图仅供参考);
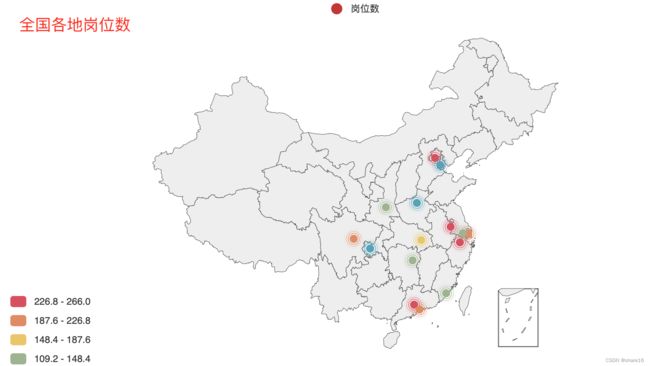
④ 从全国分布角度分析,该岗位主要分布在北京、广东、江苏、浙江等省份;招聘岗位最多的to5城市有北京、上海、广州、杭州、南京,平均工资达22.12k;较少的城市有重庆、西安、天津等,工资可达8.7k;
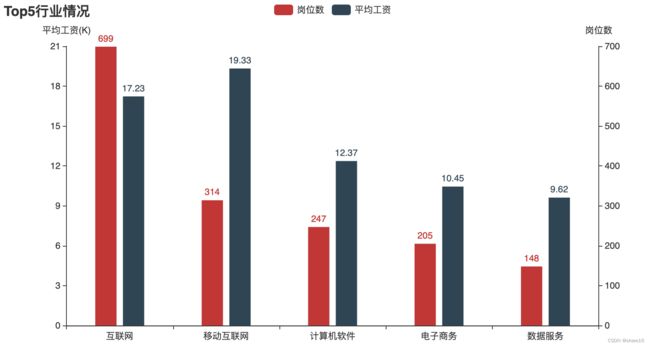
⑤ 从行业角度分析,招聘岗位最多有互联网、计算机软件、电子商务、数据服务等行业,其中互联网行业工资最高可达19k;
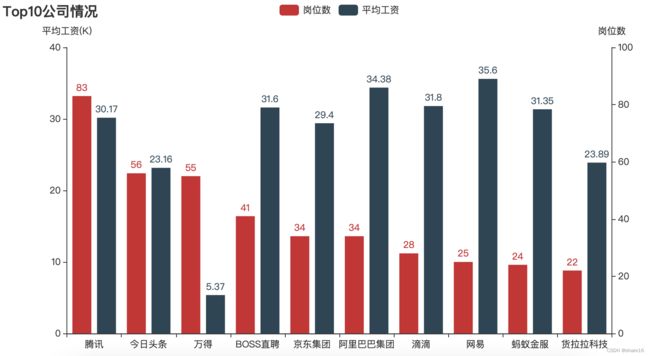
⑥ 从公司角度分析,招聘岗位最多有腾讯、头条、万得、boss直聘、京东、阿里、滴滴等,这些公司的工资均高于23k;
⑦ 从能力角度分析,大部分要求有懂业务、数据/商业分析、建模、Mysql、python、可视化、算法等能力;
⑧ 从某城市角度分析,查看该城市在各行业的招聘情况、对学历&工作经验的要求和薪资情况,查看明细等等;
五、可视化代码
5.1 整体代码
plt.text(x=0,y=3.65,s='数据分析师招聘情况:',bbox=dict(facecolor='yellow',alpha=0.8),size=36)
plt.text(x=0,y=3.5,s=a1,size=26)
plt.text(x=0.6,y=3.5,s=a2,size=26)
plt.text(x=1.2,y=3.5,s=a3,size=26)
plt.text(x=1.8,y=3.5,s=a4,size=26)
plt.xlim((0,1.5))
plt.ylim((3.5,3.8))
plt.axis('off')
pie1 = Pie()
pie1.add('',list(a5.岗位数.to_dict().items()),radius='30%',center=['15%','50%'],
label_opts=opts.LabelOpts(formatter='{b}:{d}%',position='left'))
l1 = Line()
l1.add_xaxis(list(a5.平均工资.round(2).index))
l1.add_yaxis('最低工资',list(a5.最低工资.round(2)),label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_='average',name='平均值')]))
l1.add_yaxis('最高工资',list(a5.最高工资.round(2)),label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_='average',name='平均值')]))
l1.add_yaxis('平均工资',list(a5.平均工资.round(2)),label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_='average',name='平均值')]))
l1.set_global_opts(legend_opts=opts.LegendOpts(is_show=False))
g1 = Grid()
g1.add(l1,grid_opts=opts.GridOpts(pos_left='40%',pos_right='5%'))
g1.add(pie1,grid_opts=opts.GridOpts(pos_top='1%',pos_left='1%'))
pie2 = Pie()
pie2.add('',list(a6.岗位数.to_dict().items()),radius='30%',center=['15%','50%'],
label_opts=opts.LabelOpts(formatter='{b}:{d}%',position='left'))
l2 = Line()
l2.add_xaxis(list(a6.平均工资.round(2).index))
l2.add_yaxis('最低工资',list(a6.最低工资.round(2)),label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_='average',name='平均值')]))
l2.add_yaxis('最高工资',list(a6.最高工资.round(2)),label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_='average',name='平均值')]))
l2.add_yaxis('平均工资',list(a6.平均工资.round(2)),label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_='average',name='平均值')]))
l2.set_global_opts(legend_opts=opts.LegendOpts(is_show=False))
g2 = Grid()
g2.add(l2,grid_opts=opts.GridOpts(pos_left='40%',pos_right='5%'))
g2.add(pie2,grid_opts=opts.GridOpts(pos_top='1%',pos_left='1%'))
p1 = Geo()
p1.add_schema(maptype='china',is_roam=False,)
p1.add('岗位数',list(df1_1.岗位数.to_dict().items()),type_='effectScatter',symbol_size=10,
label_opts=opts.LabelOpts(is_show=False))
p1.set_global_opts(visualmap_opts=opts.VisualMapOpts(min_=70,max_=266,is_piecewise=True))
p2 = Bar()
p2.add_xaxis(list(m.index))
p2.add_yaxis('最高工资',list(m.最高工资),label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(name='平均值',type_='average')]))
p2.add_yaxis('平均工资',list(m.平均工资),label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(name='平均值',type_='average')]))
p2.add_yaxis('最低工资',list(m.最低工资),label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(name='平均值',type_='average')]))
p2.extend_axis(yaxis=opts.AxisOpts(name='工资(K)',position='left'))
p2.extend_axis(yaxis=opts.AxisOpts(name='岗位数',position='right'))
l2_1 = Line()
l2_1.add_xaxis(list(m.index))
l2_1.add_yaxis('岗位数',list(m.岗位数),yaxis_index=2,z=2,symbol_size=10,is_smooth=True,
linestyle_opts=opts.LineStyleOpts(width=6,color='green'))
p2.overlap(l2_1)
p2.set_global_opts(title_opts=opts.TitleOpts('Top5城市薪资情况'))
p3 = Bar()
p3.add_xaxis(list(n.index))
p3.add_yaxis('最高工资',list(n.最高工资),label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(name='平均值',type_='average')]))
p3.add_yaxis('平均工资',list(n.平均工资),label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(name='平均值',type_='average')]))
p3.add_yaxis('最低工资',list(n.最低工资),label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(name='平均值',type_='average')]))
p3.extend_axis(yaxis=opts.AxisOpts(name='工资(K)',position='left'))
p3.extend_axis(yaxis=opts.AxisOpts(name='岗位数',position='right'))
l3_1 = Line()
l3_1.add_xaxis(list(n.index))
l3_1.add_yaxis('岗位数',list(n.岗位数),yaxis_index=2,z=2,symbol_size=10,is_smooth=True,
linestyle_opts=opts.LineStyleOpts(width=6,color='green'))
p3.overlap(l3_1)
p3.set_global_opts(title_opts=opts.TitleOpts('Bottom5城市薪资情况'))
p4 = Bar()
p4.extend_axis(yaxis=opts.AxisOpts(name='平均工资(K)',position='left'))
p4.extend_axis(yaxis=opts.AxisOpts(name='岗位数',position='right'))
p4.add_xaxis(list(a7_1.index))
p4.add_yaxis('岗位数',list(a7_1.岗位数),bar_width='20%',yaxis_index=2)
p4.add_yaxis('平均工资',list(a7_1.平均工资.round(2)),bar_width='20%')
p4.set_global_opts(title_opts=opts.TitleOpts('Top5行业情况'))
p5 = Bar()
p5.extend_axis(yaxis=opts.AxisOpts(name='平均工资(K)',position='left'))
p5.extend_axis(yaxis=opts.AxisOpts(name='岗位数',position='right'))
p5.add_xaxis(list(a8_1.index))
p5.add_yaxis('岗位数',list(a8_1.岗位数),yaxis_index=2)
p5.add_yaxis('平均工资',list(a8_1.平均工资.round(2)))
p5.set_global_opts(title_opts=opts.TitleOpts('Top10公司情况'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(interval=0)))
p6 = WordCloud()
p6.add('',list(a9.to_dict().items()))#亦可添加 mask_image='/XXXXXX/12.jpeg'
t = Tab()
t.add(g1,'学历-整体情况')
t.add(g2,'工作经验-整体情况')
t.add(p1,'全国各地岗位数')
t.add(p2,'Top5城市情况')
t.add(p3,'Bottom5城市情况')
t.add(p4,'Top5行业')
t.add(p5,'Top10公司')
t.add(p6,'要求的能力')
t.render_notebook()
5.2 城市代码
print('城市:{}'.format(' '.join(df0.地区.unique())))
x = input('\n请输入城市:')
y = input('\n是否选择行业,输入1或0(1代表是,0代表否):')
if eval(y) == 1:
print('\n行业:{}'.format(' '.join(df0.query('地区==@x').行业.unique())))
z = input('\n请输入行业:')
if eval(y) == 0:
t = x+' - all'+'行业'
select0 = df0.query('地区==@x')
else:
t = x+' - '+z+'行业'
select0 = df0.query('地区==@x and 行业==@z')
select1 = select0.groupby(['行业','学历','工作经验']).agg({'职位':'count','salary_avg':'mean'}).reset_index()
select1.columns = ['行业','学历','工作经验','岗位数', '平均工资']
from pyecharts.components import Table
ps0 = Liquid()
ps0.add('全国占比',[round(len(select0)/len(df0),4)],center=['50%','50%'])
ps0.set_global_opts(title_opts=opts.TitleOpts(title=t,subtitle='\n\n发布岗位在全国的占比',pos_top='10%',
title_textstyle_opts=opts.TextStyleOpts(font_size=45)))
s1 = select1.groupby('行业').agg({'岗位数':'sum','平均工资':'mean'}).sort_values('岗位数',ascending=False)
ps1 = Line()
ps1.extend_axis(yaxis=opts.AxisOpts(name='岗位数',position='left'))
ps1.extend_axis(yaxis=opts.AxisOpts(name='平均工资',position='right'))
ps1.add_xaxis(list(s1.index))
ps1.add_yaxis('岗位数',list(s1.岗位数),label_opts=opts.LabelOpts(is_show=False))
ps1.add_yaxis('平均工资',list(s1.平均工资.round(2)),yaxis_index=2,label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(name='平均值',type_='average')]))
s2 = select1.groupby('学历').agg({'岗位数':'sum','平均工资':'mean'}).sort_values('岗位数',ascending=False)
ps2 = Line()
ps2.extend_axis(yaxis=opts.AxisOpts(name='岗位数',position='left'))
ps2.extend_axis(yaxis=opts.AxisOpts(name='平均工资',position='right'))
ps2.add_xaxis(list(s2.index))
ps2.add_yaxis('岗位数',list(s2.岗位数),label_opts=opts.LabelOpts(is_show=False))
ps2.add_yaxis('平均工资',list(s2.平均工资.round(2)),yaxis_index=2,label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(name='平均值',type_='average')]))
s3 = select1.groupby('工作经验').agg({'岗位数':'sum','平均工资':'mean'}).sort_values('岗位数',ascending=False)
ps3 = Line()
ps3.extend_axis(yaxis=opts.AxisOpts(name='岗位数',position='left'))
ps3.extend_axis(yaxis=opts.AxisOpts(name='平均工资',position='right'))
ps3.add_xaxis(list(s3.index))
ps3.add_yaxis('岗位数',list(s3.岗位数),label_opts=opts.LabelOpts(is_show=False))
ps3.add_yaxis('平均工资',list(s3.平均工资.round(2)),yaxis_index=2,label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(name='平均值',type_='average')]))
select2 = select0[['公司','职位','地区','薪资','经验','行业','要求能力']].sort_values('公司')
ps4 = Table()
ps4.add(headers=list(select2.columns),rows=select2.values.tolist())
pg = Page(layout=Page.DraggablePageLayout)
pg.add(ps0,ps1,ps2,ps3,ps4)
pg.render()
pg.save_resize_html(source='render.html',
cfg_file='/XXXXXX/chart_config.json',
dest='/XXXXXX/chart.html')
谢谢大家