大数据生态系统组件基础学习
这是学习大数据这一整套各种组件MySQL,hive,spark,mapreduce等等的一些基础语法,日常更新,有不对的地方欢迎指正,资料也是自己收集来的,若有侵权,联系我立马删。
MySQL
(一)创建数据库及表
1.创建数据库database
create databases 数据库名
use 数据库名
创建表格
create table 表名 (
字段名1 数据类型 [约束条件],
字段名2 数据类型 [约束条件],
[其他约束条件]
) 其他条件(储存引擎,字符集条件等选项);
代码示例:
create database test;
use test;
set names utf8;
create table dome (
id int unsigned not null auto_increment,
title varchar(40) not null,
price decimal(11,2),
thumb varchar(225),
author varchar(20),
publisher varchar(50),
primary key(id)
) engine=myisam default charset=utf8;
查看正在使用的数据库:
select database();
2.删除数据表
丢掉:drop
表:table
删除数据表:drop table 数据表名称;
drop database 数据库名称
drop table 表名
drop database test;
drop table dome;
3.查看数据库表结构
describe 表名
简写desc 表名
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ITh35Xp2-1658977075600)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220701102836994.png)]
4.表的基础操作
I.向数据表中插入数据
基本语法:
插入:insert
向数据表中插入数据:
insert into 数据表名称([字段1,字段2…]) values (字段值1,字段值2…)
varchar类型的要输入双引号
代码示例:
insert into dome
values
(01,"apple",9.99,"yes","张三麻子","good");
II.修改字段数据类型
alter table 表名 modify column 字段名 类型 约束 [默认值, 注释];
alter table dome modify column id int(10) not null;
III.更新数据表中的记录
基本语法:
更新:update
update 数据表名称 set 字段(列) = 更新后的值,字段(列) = 更新后的值 where 条件;
IV.更新数据表中的记录
基本语法:
更新:update
update 数据表名称 set 字段(列) = 更新后的值,字段(列) = 更新后的值 where 条件;
update dome set author='替换值' where author='被替换的值';
V.数据表中删除数据(重点)
基本语法:
删除:delete
delete from 数据表名称 where 条件;
① delete from 数据表名称;
② truncate 数据表名称;
两者的功能都是删除所有数据,但是truncate删除的数据,其主键(primary key)会重新编号。而delete from删除后的数据,会继续上一次编号。
delete from dome where id=2;
(二)数据库常见操作
1.查看所有mysql的编码
show variables like 'character%';
#client connetion result 和客户端相关
database server system 和服务器端相关
将客户端编码修改为gbk.
set character_set_results=gbk; / set names gbk;
以上操作,只针对当前窗口有效果,如果关闭了服务器便失效。如果想要永久修改,通过以下方式:
在mysql安装目录下有my.ini文件
default-character-set=gbk 客户端编码设置
character-set-server=utf8 服务器端编码设置
注意:修改完成配置文件,重启服务
2.追加主键
Alter table 表名 add primary key(字段列表);
2.1更新主键 & 删除主键
没有办法更新主键: 主键必须先删除,才能增加.
Alter table 表名 drop primary key;
3.创建索引
建表的时候创建索引,也可以在已存在的表上添加索引。
CREATE TABLE 表名称(
......,
INDEX [索引名称] (字段),
......
);
3.1添加索引
CREATE INDEX 索引名称 ON 表名(字段); /*添加索引方式1*/
ALTER TABLE 表名 ADD INDEX 索引名称(字段); /*添加索引方式2*/
唯一索引:
CREATE UNIQUE INDEX 索引名称 ON 表名(字段)
联合索引:
CREATE INDEX 索引名称 ON 表名(字段1,字段2...)
3.2查询索引
SHOW INDEX FROM t_message;
3.3删除索引
/* 在t_message表中删除idx_type索引 */
DROP INDEX idx_type ON t_message;
3.4索引的使用原则
-
数据量很大,且经常被查询的数据表可以设置索引 (即读多写少的表可以设置索引)
-
索引只添加在经常被用作检索条件的字段上 (比如电子商城需要在物品名称关键字加索引)
3.不要在大字段上创建索引 (比如长度很长的字符串不适合做索引,因为查找排序时间变的很长)
(三)条件查询
语法:select 字段 from 数据库 where 条件;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IBTwn77B-1658977075601)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704151010931.png)]
1.like模糊查询
% 匹配任意个字符
下划线,只匹配一个字符
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-chfu1epS-1658977075601)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704151257699.png)]
2.排序——order by
语法:select 字段名 from 表名 order by 字段名(根据该来排序);
语法:select 字段名 from 表名 order by 字段名(根据该来排序) desc; (降序)
2.1.根据多行字段进行排序
eg:查询员工的工资和名字,并按照升序进行,但是工资相同需要通过姓名来排序
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZI6YYQhg-1658977075602)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704151644373.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YgeSWXli-1658977075602)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704151806872.png)]
2.2根据字段位置来进行排序
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UMHFpXDt-1658977075602)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704151921444.png)]
(四)函数及查询
1.大小写转换函数
select 函数名(字段名) from 表名;
lower将大写转化为小写
upper将小写转换为大写
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TX2i4rJr-1658977075603)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704152442520.png)]
2.substr 取子串
substr(需要截取的字段,起始下标,截取长度) 起始下标是以1开始的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cX2xjPHW-1658977075603)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704152804635.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SfgeYYyL-1658977075604)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704153046260.png)]
3.concat函数进行字符串的拼接
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Va5RT6CE-1658977075604)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704153409619.png)]
4.length 获取长度
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7VyWycdE-1658977075604)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704153844134.png)]
select LENGTH(ename) as mylength from emp;
5.trim 去空格
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rarjRP5j-1658977075605)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704154102307.png)]
6.round 四舍五入
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IfvZWBf4-1658977075605)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704154138091.png)]
select ROUND(123.889,2) from emp;
7.ifnull (空处理函数)
可以将null转换为具体值注意:在数据库中只要有null参与数学运算,最终结果为null,不管加减乘除。
使用方法:ifnull(数据,指定成相应的数据)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mIgaQhE4-1658977075606)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704155211788.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9r98BH9u-1658977075607)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704155222876.png)]
8.case when then when then else end
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LZ4MYIPa-1658977075607)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704155906643.png)]
SELECT
ename,
sal AS oldsal,
LOWER(job),
(
CASE job
WHEN 'manager' THEN
sal * 1.1
WHEN 'salesman' THEN
sal * 1.5
ELSE
sal
END
) AS newsal
FROM
emp;
9.分组函数(多行处理函数)
count 计数 max 最大值 min 最小值
avg 平均值 sum 总值 自动忽略null
select min(sal) from emp;
第一点:分组函数可以自动忽略null
第二点:count()和count(具体的字段)count():统计表当中的总行数count(具体的字段):表示统计该字段下所有不为null的字段
第三点:分组函数不能直接使用在where子句中
select job,sum(sal) from emp group by job;
10.分组查询(非常重要)
select ……
from ……
where ……
group by ……
order by ……
10.1 执行顺序步骤:
第一步:from
第二步:where
第三步:group by
第四步:select
第五步:order by
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9QgvSXkt-1658977075608)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704163532943.png)]
10.2 分组的条件查询 having
having 可以对分完组的数据进行再次筛选
注意:having不能单独使用,having也不能代替where,having必须和group by联合使用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-um3thFLf-1658977075608)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704172525199.png)]
SELECT job,avg(sal) from emp GROUP BY job HAVING avg(SAL)>2500;
SELECT
job,
avg(sal)
FROM
emp
GROUP BY
job
HAVING
avg(SAL) > 2500
ORDER BY
avg(SAL) DESC;
10.3对查询结果进行去除重复数据
distinct 要放在需要查重的字段前面
select distinct job from emp;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UfUDu6Yw-1658977075609)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705090558287.png)]
10.4统计工作岗位的数据
select count(distinct job) from emp;
11.连接查询
11.1连接查询概论
连接查询:是将多张表联合查询
11.2根据表的连接方式分类
内连接:
等值连接 非等值连接 自连接
外连接:
左外连接(左连接)右外连接(右连接)全连接(一般不用)
11.3笛卡尔积现象及解决办法
当两张表进行连接查询的时候,最后查询的结果是两张表行数的乘积,这种现象被称为笛卡尔积现象。
注意:表与表的联合查询,查询的次数表的行数乘以表的行数。
eg:查询员工名字和部门名字
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hCHM4URP-1658977075609)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705092635891.png)]
select ename,dname from emp,dept;
#这样联合查询会出现笛卡尔积现象,会导致数据爆炸
解决:笛卡尔积现象
只需在查询的时候加上筛选条件即可
eg:查询员工名字和部门名字
select ename,dname from emp,dept where emp.deptno=dept.deptno;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hJ0zIxtt-1658977075610)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705093439889.png)]
优化版:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A5wkzuDy-1658977075610)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705093654852.png)]
select e.ename,d.dname from emp as e,dept as d where e.deptno=d.deptno;
注意:通过笛卡尔积现象,说明了表连接越多,效率越低
11.4内连接
11.4.1内连接之等值连接
eg:查询每一个员工所在部门名称,显示员工名和部门名?
select e.ename,d.dname from emp as e,dept as d where e.deptno=d.deptno;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YktVP0C7-1658977075610)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705094613712.png)]
改进:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jfQkLISU-1658977075611)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705094628763.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ACXG55SV-1658977075611)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705094643366.png)]
select e.ename,d.dname from emp as e join dept as d on e.deptno=d.deptno;
内连接的基础语法:
select 字段名1,字段名2 from 表名1 join 表名2 on 具体条件
11.4.2 、内连接之非等值连接
eg:找到每一个员工的薪酬等级,要求显示员工名、薪资、薪资等级
select * from salgrade;
select e.name,e.sal,s.grade from emp as e join salgrade as s on sal between
SAPRK
1.spark的基本认知:
spark是一种快速通用可扩展性 的大数据分析引擎,hive是一个大数据存储框架。
什么叫做算子!!!就是对RDD进行操作的行为或者函数就叫算子。、
RDD的操作分为两类,一类是transformation(转化操作),另一类是Action(执行操作)
转换操作(Transformation) (如:map,filter,groupBy,sortBy,join等),转换操作也叫懒操作,也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,Spark在遇到转换操作时只会记录需要这样的操作,并不会去执行,需要等到有执行操作的时候才会真正启动计算过程进行计算。 Transformation算子根据输入参数,又可细分为处理Value型和处理Key-Value型的。
Value数据类型的Transformation算子,这种变换并不触发提交作业,针对处理的数据项是Value型的数据。
Key-Value数据类型的Transfromation算子,这种变换并不触发提交 作业,针对处理的数据项是Key-Value型的数据对。
那么什么又是懒操作呢?
懒操作就是你在使用transformation算子操作RDD的时候,是为了把RDD转化成为另外一种RDD,这种操作并不是立刻执行,只是spark会记录这样之中操作(相当于在此处写下了对RDD操作变换的脚本),并不去执行,只有触发ACtion算子操作的时候,才会去执行启动进程进行一个计算。
不管是Transformation里面的操作还是Action里面的操作,我们一般会把它们称之为算子,例如:map 算子、reduce算子
执行操作(Action) (如:count,collect,save,reduce等),执行操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。
像Action算子这样的执行操作,其实就是会返回结果的那种,会有数据写入存储系统的那种,同时也只有Action操作能够触发spark启动
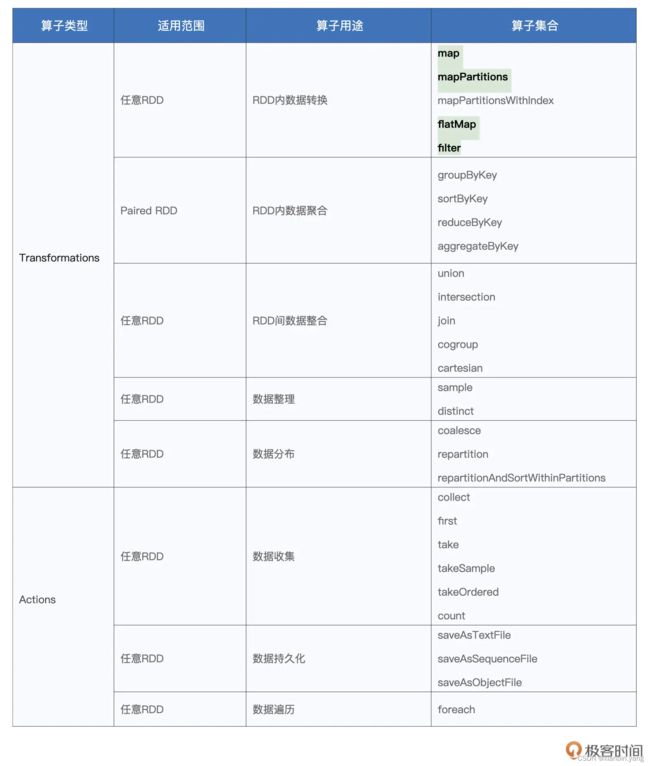
transformation算子[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CtNVge2J-1658977075612)(C:\Users\HP\Desktop\Typora笔记文档\image-20220711092335291.png)]
Action算子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tDyScgJt-1658977075613)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220711092411416.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LZEoQP6b-1658977075613)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220711095202268.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8rHJtZCe-1658977075613)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220711095216321.png)]
文件数据处理的生命周期
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5m6bakWc-1658977075614)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220711095405860.png)]
在 RDD 之上调用 toDebugString,Spark 可以帮我们打印出当前 RDD 的 DAG
RDD4大属性:
partitions:数据分片
partitioner:分片切割规则
dependencies:RDD
依赖compute:转换函数
RDD血缘
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
宽窄依赖
RDD 依赖关系
这里所谓的依赖关系,其实就是两个相邻 RDD 之间的关系:
RDD 窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用,
窄依赖我们形象的比喻为独生子女。
RDD 宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会
引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
Spark任务调度与运行
- Driver(包工头): 解析代码构建DAG、拆分DAG并分配task到executor执行、监控任务
- Executor(施工工人): 接收并执行task、汇报task任务状态
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W4Whqy0e-1658977075614)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220711100924851.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IG4FZG7U-1658977075614)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220711101652142.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TIyT9Nec-1658977075615)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220711101811839.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rj9Y9RKJ-1658977075615)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220711101901158.png)]
基础配置
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9iqsixhy-1658977075616)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220711102125060.png)]
(23条消息) 零基础入门 Spark(一):基础知识_xianbin.yang的博客-CSDN博客_spark 入门
每日复习一下
Spark内存管理
- Reserved Memory 用来存储 Spark 内部对象
- User Memory 用于存储开发者自定义的数据结构
- Execution Memory 用来执行分布式任务
- Storage Memory 用于缓存分布式数据集
广播变量&累加器
Driver 变量:分发是以 Task 为粒度[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VcZQaFBJ-1658977075616)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220712101607793.png)]
广播变量:分发以 Executors 为粒度
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bm0xCNOk-1658977075616)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220712101617703.png)]
- 累加器(Accumulators):全局计数(Global counter)
存储系统
- Spark 存储系统负责维护所有暂存在内存与磁盘中的数据,这些数据包括 Shuffle 中间文件、RDD Cache 以及广播变量
- 存储系统组件
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BjMqu8Ei-1658977075617)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220712101704265.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O97erTSs-1658977075617)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220708143224778.png)]
Spark Core:实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统 交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称 RDD)的 API 定义。
Spark SQL:是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比 如 Hive 表、Parquet 以及 JSON 等。
Spark Streaming:是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计
算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster
manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度 器,叫作独立调度器。
Spark 得到了众多大数据公司的支持,这些公司包括 Hortonworks、IBM、Intel、Cloudera、
MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的 Spark 已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用 GraphX 构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯 Spark 集群达到 8000 台的规模,是当前已知的世界上最大的 Spark 集群。
Spark的特点
Spark角色介绍及运行模式(1)快:与MapReduce相比,Spark基于内存运算要快100呗以上,基于硬盘运算也要快10倍以上,实现了高效的DAG执行引擎,通过基于内存来高效处理数据流。计算的中间结果基于内存。
(2)易用,基于java、scala、Python
(3)通用:Spark 提供了统一的解决方案。Spark 可以用于批处理、交互式查询(Spark SQL)、
实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类
型的处Spark角色介绍及运行模式人力成本和部署平台的物力成本。
(4)兼容性:Spark 可以非常方便地与其他的开源产品进行融合
Spark角色介绍及运行模式
| 运行环境 | 模式 | 描述 |
|---|---|---|
| local | 本地模式 | 常用于本地开发测试环节,由本地单线程和本地多线程模式 |
| StandAlone | 集群模式 | Spark自带的一个资源调度框架,支持完全分布式。存在的Master单点故障可由ZooKeeper来实现HA |
| Yarn | 集群模式 | 运行在yarn资源管理器框架之上,由yarn负责资源管理,Spark负责任务调度和计算 |
| mesos | 集群模式 | 运行在mesos资源管理器框架之上,由mesos负责资源管理,Spark负责任务调度和计算 |
| Kubernetes | 集群模式 | 运行在Kubernetes资源管理的集群上,目前Kubernetes调度程序是实验性的 |
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mQlcSFii-1658977075618)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220708144357174.png)]
Spark提交命令的方式
standalone
./bin/spark-submit --class org.apache.spark.examples.SparkPi
–master spark://node21:7077
–executor-memory 500m
–total-executor-cores 1
examples/jars/spark-examples_2.11-2.3.1.jar 10
Hadoop
(一)基础操作命令
1.启动命令
start-all.sh //启动hadoop集群(同时启动yarn和hdfs集群)
start-dfs.sh //单独启动hdfs集群
start--yarn.sh //单独启动yarn集群
2.操作命令
hadoop fs -put 要上传的文件 上传的hdfs路径 //上传文件到hdfs上
hadoop fs -put -p dirtest/ / //可以添加-p参数将dirtest文件夹直接上传到hdfs上
hadoop fs -mkdir 目录名 //创建目录,如果创建多级目录,添加-p参数
hadoop fs -rm 文件名 //删除文件,如果删除目录,需要添加-r参数
hadoop fs -count -q //查看当前文件夹下面的文件配额
hdfs dfs –mv /user/test.txt /user/ok.txt //将test.txt重命名为ok.txt
hadoop dfs –get /user/t/ok.txt /home/t //将hdfs上/user/t/下的ok.txt文件下载到 /home/t目录下
hadoop fs -chmod -r 755 //修改目录的权限
hadoop fs -chmod 755 //修改文件的权限
(二)mapreduce处理流程及原理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q1E6RKMM-1658977075618)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220706085915341.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kYPrlL5H-1658977075618)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220706090719956.png)]
为Split、Map、Shuffle、Reduce四个阶段,每个阶段在WordCount中的作用如下:
1.Split阶段:首先大文件被切分为多分,假设这里被切分成了3份,每一行代表一份。
2.Map阶段:解析出每个单词,并在后边机上数字1
3.Shuffle阶段:将每一份中的单词分组到一起,并默认按照字母进行排序。
4.Reduce阶段:将相同的单词进行累加。
5.输出结果
个人理解:
1.首先由split对数据按照要求进行切片,切分数据为一份一份的
2.由map阶段把数据处理成
3.由shuffle阶段初步合并聚合排序数据形成相同key的为一组这种形式传递给reduce
4.reduce阶段的接受这样的一组一组的数据,按照相同key进行聚合并排序
5.输出结果到HDFS上面
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bSiDnj95-1658977075619)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220707092602429.png)]
- 所有的MapTask任务完成后,启动相应数量的ReduceTask(和分区数量相同),并告知ReduceTask处理数据的范围
- ReduceTask会将MapTask处理完的数据拷贝一份到磁盘中,并合并文件和归并排序
- 最后将数据传给reduce进行处理,一次读取一组数据
- 最后通过OutputFormat输出
整个ReduceTask分为Copy阶段,Merge阶段,Sort阶段(Merge和Sort可以合并为一个),Reduce阶段。
- Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中
- Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多
- Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可
- Reduce阶段:reduce()函数将计算结果写到HDFS上
split
- 首先有一个200M的待处理文件
- 切片:在客户端提交之前,根据参数配置,进行任务规划,将文件按128M每块进行切片
- 提交:提交可以提交到本地工作环境或者Yarn工作环境,本地只需要提交切片信息和xml配置文件,Yarn环境还需要提交jar包;本地环境一般只作为测试用
- 提交时会将每个任务封装为一个job交给Yarn来处理(详细见后边的Yarn工作流程介绍),计算出MapTask数量(等于切片数量),每个MapTask并行执行
- MapTask中执行Mapper的map方法,此方法需要k和v作为输入参数,所以会首先获取kv值;
- 首先调用InputFormat方法,默认为TextInputFormat方法,在此方法调用createRecoderReader方法,将每个块文件封装为k,v键值对,传递给map方法
MAP
- map方法首先进行一系列的逻辑操作,执行完成后最后进行写操作
- map方法如果直接写给reduce的话,相当于直接操作磁盘,太多的IO操作,使得效率太低,所以在map和reduce中间还有一个shuffle操作
- map处理完成相关的逻辑操作之后,首先通过outputCollector向环形缓冲区写入数据,环形缓冲区主要两部分,一部分写入文件的元数据信息,另一部分写入文件的真实内容
- 环形缓冲区的默认大小是100M,当缓冲的容量达到默认大小的80%时,进行反向溢写
- 在溢写之前会将缓冲区的数据按照指定的分区规则进行分区和排序,之所以反向溢写是因为这样就可以边接收数据边往磁盘溢写数据
- 在分区和排序之后,溢写到磁盘,可能发生多次溢写,溢写到多个文件
- 对所有溢写到磁盘的文件进行归并排序
- 在9到10步之间还可以有一个Combine合并操作,意义是对每个MapTask的输出进行局部汇总,以减少网络传输量
- Map阶段的进程数比Reduce阶段要多,所以放在Map阶段处理效率更高
- Map阶段合并之后,传递给Reduce的数据就会少很多
- 但是Combiner能够应用的前提是不能影响最终的业务逻辑,而且Combiner的输出kv要和Reduce的输入kv类型对应起来
整个MapTask分为Read阶段,Map阶段,Collect阶段,溢写(spill)阶段和combine阶段
- Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value
- Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value
- Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中
- Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作
(三)HDFS的读写流程
1.HDFS文件写入过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r1NJN35s-1658977075619)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220708092756904.png)]
1.Client 发起文件上传请求, 通过 RPC 与 NameNode 建立通讯, NameNode 检查目标文件是否已存在, 父目录是否存在,是否具备上传权限, 回是否可以上传
2.client会根据上传文件大小将该文件划分成多个block块,例如300M,则会划分为128M,128M,128M
3.Client 请求NameNode第一个 block 该传输到哪些 DataNode 服务器上
4.NameNode 根据配置文件中指定的备份数量及机架感知原理进行文件分配, 返回可用的 DataNode 的地址如: A, B, C给Client,client就可以单独与DataNode建立联系了。
5.Hadoop 在设计时考虑到数据的安全与高效, 数据文件默认在 HDFS 上存放三份, 存储策略为本地一份, 同机架内其它某一节点上一份, 不同机架的某一节点上一份。
6.Client 请求 3 台 DataNode 中的一台 A 上传数据(本质上是一个 RPC 调用,建立 pipeline ), A 收到请求会继续调用 B, 然后 B 调用 C, 将整个 pipeline 建立完成, 后逐级返回 client
7.Client 开始往 A 上传第一个 block(先从磁盘读取数据放到一个本地内存缓存),将block划分为多个packet, 以 packet 为单位(默认64K), A 收到一个 packet 就会传给 B, B 传给 C. A 每传一个 packet 会放入一个应答队列等待应答
8.数据被分割成一个个 packet 数据包在 pipeline 上依次传输, 在 pipeline 反方向上, 逐个发送 ack(命令正确应答), 最终由 pipeline 中第一个 DataNode 节点 A 将 pipelineack 发送给 Client
9.当一个 block 传输完成之后, Client 再次请求 NameNode 上传第二个 block 到服务 1
2.HDFS的读取流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2VTwgONN-1658977075620)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220708093511258.png)]
1.Client向NameNode发起RPC请求,NameNode收到请求后需要做权限检查(是否有操作改文件的权限),文件block列表检查,来确定请求文件block所在的位置并返回Client;
2.NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode 都会返回含有该 block 副本的 DataNode 地址; 这些返回的 DN 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
3.Client 选取排序靠前的 DataNode建立pipeline 来读取 block,client会与3个block都建立pipeline同时并行读取数据,如果客户端本身就是DataNode,那么将从本地直接获取数据(短路读取特性);
4.底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
5.当读完列表的 block 后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表;
6.读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
7.read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回Client请求包含块的DataNode地址,并不是返回请求块的数据;
8.最终读取来所有的 block 会合并成一个完整的最终文件。
Hive
(一)分区的增删
hive与各大数据库的区别
Hive和HBase的区别
Hive是为了简化编写MapReduce程序而生的,使用MapReduce做过数据分析的人都知道,很多分析程序除业务逻辑不同外,程序流程基本一样。在这种情况下,就需要Hive这样的用戶编程接口。Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑,就是些表的定义等,也就是表的元数据。使用SQL实现Hive是因为SQL大家都熟悉,转换成本低,类似作用的Pig就不是SQL。
HBase为查询而生的,它通过组织起节点內所有机器的內存,提供一個超大的內存Hash表,它需要组织自己的数据结构,包括磁盘和內存中的,而Hive是不做这个的,表在HBase中是物理表,而不是逻辑表,搜索引擎使用它來存储索引,以满足查询的实时性需求。
hive类似CloudBase,也是基于hadoop分布式计算平台上的提供data warehouse的sql功能的一套软件。使得存储在hadoop里面的海量数据的汇总,即席查询简单化。hive提供了一套QL的查询语言,以sql为基础,使用起来很方便。
HBase是一个分布式的基于列存储的非关系型数据库。HBase的查询效率很高,主要由于查询和展示结果。
hive是分布式的关系型数据库。主要用来并行分布式处理大量数据。hive中的所有查询除了"select * from table;"都是需要通过Map\Reduce的方式来执行的。由于要走Map\Reduce,即使一个只有1行1列的表,如果不是通过select * from table;方式来查询的,可能也需要8、9秒。但hive比较擅长处理大量数据。当要处理的数据很多,并且Hadoop集群有足够的规模,这时就能体现出它的优势。
通过hive的存储接口,hive和Hbase可以整合使用。
1、hive是sql语言,通过数据库的方式来操作hdfs文件系统,为了简化编程,底层计算方式为mapreduce。
2、hive是面向行存储的数据库。
3、Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。
4、HBase为查询而生的,它通过组织起节点內所有机器的內存,提供一個超大的內存Hash表 。
5、hbase不是关系型数据库,而是一个在hdfs上开发的面向列的分布式数据库,不支持sql。
6、hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。
7、hbase是列存储。
Hive和Hbase有各自不同的特征:hive是高延迟、结构化和面向分析的,hbase是低延迟、非结构化和面向编程的。Hive数据仓库在hadoop上是高延迟的。
其中HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
转:
觉得在问区别之前,我应该显示说相同点,这么一想,又糊涂了,hive和hbase哪里像了,好像哪里都不像,既然哪里都不像,又何来的“区别是什么”这一问题,他俩所有的都算区别。
那么,hive是什么?
白话一点再加不严格一点,hive可以认为是map-reduce的一个包装。hive的意义就是把好写的hive的sql转换为复杂难写的map-reduce程序。
于是,hbase是什么?
同样白话一点加不严格一点,hbase可以认为是hdfs的一个包装。他的本质是数据存储,是个NoSql数据库;hbase部署于hdfs之上,并且克服了hdfs在随机读写方面的缺点。
所以要问hive和hbase的区别,就应该问问map-reduce和hdfs之间的区别,问区别,就要先说说他俩哪里像。
(27条消息) Hive、Hbase、mysql区别_vipyeshuai的博客-CSDN博客_hive和mysql
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E2xT1GuI-1658977075620)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220714090529495.png)]
1、HDFS
为分布式存储提供文件系统
针对存储大尺寸的文件进行优化,不需要对HDFS上的文件进行随机读写
直接使用文件
数据模型不灵活
使用文件系统和处理框架
优化一次写入,多次读取的方式
2、HBase
提供表状的面向列的数据存储
针对表状数据的随机读写进行优化
使用key-vale操作数据
提供灵活的数据模型
使用表状存储,支持MapReduce,依赖HDFS
优化了多次读,以及多次写
主要用来存储非结构化数据和半结构化的数据
3、MySQL
传统关系型数据库
注重关系
支持事务
4、Redis
分布式缓存
基于内存,
强调缓存,
支持数据的持久化,
支持事务的操作,
NoSql类型的Key/value数据库
支持List、Set等丰富的类型
5、Hive
hive是基于Hadoop的数据仓库工具
可以将结构化数据文件映射为数据库表
并提供sql功能,可以将sql转化为mr任务运行
sql学习成本低,不必专门开发mr应用
i> Hive:负责廉价的数据仓库存储,其内容还是存储在HDFS上面,分布式存储系统
ii>Spark Sql:负责高速的计算
iii> DataFrame:负责复杂的数据挖掘
hive与mysql 的区别
hive不支持更新操作,只能读,mysql 可以更新数据
1.查询语言不同:hive是hql语言,mysql是sql语句;
2.数据存储位置不同:hive是把数据存储在hdfs上,而mysql数据是存储在自己的系统中;
3.数据格式:hive数据格式可以用户自定义,mysql有自己的系统定义格式;
4.数据更新:hive不支持数据更新,只可以读,不可以写,而sql支持数据更新;
5.索引:hive没有索引,因此查询数据的时候是通过mapreduce很暴力的把数据都查询一遍,也造成了hive查询数据速度很慢的原因,而mysql有索引;
6.延迟性:hive延迟性高,原因就是上边一点所说的,而mysql延迟性低;
7.数据规模:hive存储的数据量超级大,而mysql只是存储一些少量的业务数据;
8.底层执行原理:hive底层是用的mapreduce,而mysql是excutor执行器;
1.删除分区
ALTER TABLE tableName DROP IF EXISTS PARTITION (date_id='2019-01-07');
alter table 表名 drop if exists partition (date_id='2019-01-07')
2.增加分区
ALTER TABLE tableName ADD PARTITION (date_id = '2019-01-07') location 'hdfs://wecloud-cluster/project/logcenter/dw_logs/2019-01-07';
alter table 表名 add partition (date_id = '2019-01-07') location '路径'
(二)字段的增删
1.修改字段
alter table 表名 change column 原字段名 现字段名 字段类型
2.添加字段
alter table table_name add columns (column_1 string,column_2 int)
查看分区
describe formatted tableName partition(date_id="2019-01-07");
查看table在hdfs上的存储路径及建表语句
show create table tableName ;
操作分区和表语句
alter table tableName add IF NOT EXISTS partition(date_id="$year-$mon-$day") location "${dest}";
删除分区
ALTER TABLEtableName DROP IF EXISTS PARTITION (date_id='2019-01-07');
新增分区
ALTER TABLE tableName ADD PARTITION (date_id = '2019-01-07') location 'hdfs://wecloud-cluster/project/logcenter/dw_logs/2019-01-07';
添加分区
ALTER TABLE table_name ADD PARTITION (partCol = 'value1') location 'loc1'; //示例
ALTER TABLE table_name ADD IF NOT EXISTS PARTITION (date_id='2019-01-07') LOCATION '/user/hadoop/warehouse/table_name/date_id=20190107'; //一次添加一个分区
ALTER TABLE page_view ADD PARTITION (date_id='2019-01-07', country='us') location '/path/to/us/part1' PARTITION (date_id='2019-01-07', country='us') location '/path/to/us/part2'; //一次添加多个分区
删除分区
ALTER TABLE tableName DROP IF EXISTS PARTITION (date_id='2019-01-07');
ALTER TABLE tableName DROP IF EXISTS PARTITION (date_id='2019-01-07', country='us');
修改分区
ALTER TABLE tableName PARTITION (date_id='2019-01-07') SET LOCATION "new location";
ALTER TABLE tableName PARTITION (date_id='2019-01-07') RENAME TO PARTITION (date_id='20190107');
添加列
ALTER TABLE tableName ADD COLUMNS (col_name STRING); //在所有存在的列后面,但是在分区列之前添加一列
修改列
CREATE TABLE tableName (a int, b int, c int);
// will change column a's name to a1
ALTER TABLE tableName CHANGE a a1 INT;
// will change column a's name to a1, a's data type to string, and put it after column b. The new table's structure is: b int, a1 string, c int
ALTER TABLE tableName CHANGE a a1 STRING AFTER b;
// will change column b's name to b1, and put it as the first column. The new table's structure is: b1 int, a string, c int
ALTER TABLE tableName CHANGE b b1 INT FIRST;
修改表属性
alter table tableName set TBLPROPERTIES ('EXTERNAL'='TRUE'); //内部表转外部表
alter table tableName set TBLPROPERTIES ('EXTERNAL'='FALSE'); //外部表转内部表
表的重命名
ALTER TABLE tableName RENAME TO newTableName
增加字段
ALTER TABLE tableName ADD COLUMNS(other STRING COMMENT '这里是列注释!');
--将 a 列的名字改为 a1.
ALTER TABLE tableName CHANGE a a1 INT;
--将 a 列的名字改为 a1,a 列的数据类型改为 string,并将它放置在列 b 之后。新的表结构为: b int, a1 string, c int.
ALTER TABLE tableName CHANGE a a1 STRING AFTER b;
--将 b 列的名字修改为 b1, 并将它放在第一列。新表的结构为: b1 int, a string, c int.
ALTER TABLE tableName CHANGE b b1 INT FIRST;
修改表注释:
ALTER TABLE tableName SET TBLPROPERTIES('comment' = '这是表注释!');
修改字段注释:
ALTER TABLE tableName CHANGE COLUMN column newColumn STRING COMMENT '这里是列注释!';
剔除不可见符号
regexp_replace("内容",'<[^>^<]*>|&|nbsp|rdquo|&|"|\n|\r|[\\000-\\037]','')
(三)常规操作
1.不启动/不退出 hive CLI 实现shell与hive命令的交互
hive -e “hive语句”
hive -f hql脚本文件
hql文件中可以有一个或多个hive语句
注:用hive -e 或 -f 将查询结果重定向时会将WARN信息一同输入,如:
针对这两条WARN信息的解决办法:
echo "export HIVE_SKIP_SPARK_ASSEMBLY=true" >> /etc/profile
source /etc/profile
2.在hive内执行shell命令
source /root/tmp/demo.hql;
执行shell命令,在命令前加叹号“!”,以分号“;”结尾
! pwd ;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4ydaf165-1658977075620)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220706142459189.png)]
3.在hive内执行hadoop dfs 命令
将hadoop 关键字去掉,以分号“;”结尾
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YGW5mR43-1658977075621)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220706142546940.png)]
(四)库表操作
1.数据库操作
(1)查看所有数据库
show databases;
(2)创建数据库
create database [ if not exists ] demo [comment ‘注释信息’];
加上 if not exists若数据库已存在则不报错
(3)查看数据库信息
describe database demo1;
或简写为
desc database demo1;
(4)删除数据库
drop database [ if exists ] demo1;
若数据库中已经创建数据表,则需要先删除表再删除库,或者命令后加cascade可以直接删除库和表
drop database [ if exists ] demo1 cascade;
(5)切换到数据库
use demo;
正常查询数据表需要指定数据库db_name.tb_name,切换到数据库后,再查询demo库中的表可以不指定库名直接写表名
2.数据表操作
(1)查看库中表
show tables in db_name;
或
use db_name;
show tables;
可以用正则表达式过滤
show tables ‘tmp*’;
(2)查看表信息
desc tb_name;
desc formatted tb_name; #内容更详细,包括创建者、创建时间、在hdfs 上的目录等
(3)新建表
这里要介绍一下hive中的四种表:内部表,外部表;分区表,桶表
1.内部表
内部表也叫管理表,删除内部表的时候表中的数据同时也会删除,且内部表不方便共享数据,所以我们常用外部表
create table [ if not exist ] table_name
( 字段名称 字段类型 [ comment '注释' ], 字段名称 字段类型 [ comment '注释' ] ) #字段之间以逗号分隔
[ row format delimited fields terminated by '\t' ] #指定列之间的分隔符
[ stored as textfile] #指定文件的存储格式
;
也可以通过克隆或查询复制已有表的方式创建新表
#克隆表结构,会复制元数据,但不会复制源表的数据
create table tb_name2 like tb_name1;
#复制源表数据及表结构,可以只选择部分列,也可以对数据进行筛选处理
create table tb_name2
as
select col1,col2
from tb_name1
where col1 is not null;
2.外部表
创建外部表时需要指定关键字external,删除外部表的时候只会删除表的元数据,表中的数据依然存在hdfs上
#除增加关键字external外与创建内部表一样
create external table table_name(id int, name string) row format delimited fields terminated by '\t' stored as textfile;
3.分区表
当一张表的数据量很大时,我们可以通过partitioned by 指定一个或多个分区将数据分类,比如按日期分区,我们查询某一天数据的时候只会遍历当天分区里的数据而不会扫描全表,提高查询效率。分区又分为动态分区和静态分区,向表中导入数据的时候有所差别,将在后面介绍
#指定year为分区键,注意分区键不能同时出现在table_name后面,否则会报错
create table table_name(id int, name string) partitioned by(year int) row format delimited fields terminated by '\t' stored as textfile;
4.桶表
当分区表中分区的数据量很大时,我们可以通过clustered by 指定字段进行hash运算,并指定分桶个数,使用hash值除以桶的个数取余进行分桶,这样按照指定字段查询时效率更高。此外还有可选项sorted by 指定桶中的数据按哪个字段排序,在join操作时可以提高效率
在创建分桶表之前要执行命令
set hive.enforce.bucketing=true; //开启对分桶表的支持 set mapreduce.job.reduces=4; //设置与桶相同的reduce个数(默认只有一个reduce)
#该表按照year进行分区,每个分区又分成4个桶
create table table_name(id int, name string) partitioned by(year int) clustered by(id) into 4 buckets;
#意思是通过ID这一列进行hash,出来的相同的hash值则进行分组,设成4个文件块
(4)向表中加载数据
1.将文件中的数据加载进表
load data local inpath ‘文件位置’ overwrite into table 表名;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pi2OfiJ4-1658977075621)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220706152221163.png)]
2.将查询结果导入表
insert overwrite table tb_name2 select * from tb_name1;
也可以一次查询多次插入,比分次性能更高
from tb_name
insert overwrite table log1 select * where event_id=‘001’
insert overwrite table log2 select * where event_id=‘002’
3.查看分区
show partitions tb_name;
3.查询语法
1.基本查询语法
select col_name,函数列/算数运算列
from tb_name
where 过滤条件
limit 返回条数 ;
select语句的几种写法
select * from tb_name; #查询所有字段
select col1,col2 from tb_name; #指定字段查询
select t.col1 from tb_name t; #使用表别名
2.嵌套子查询
select * from ( select col1,col2 from tb_name ) a;
还有一种定义临时表的方式,语句特别复杂的时候代码可读性更高
with t1 as (select col1,col2 from tb_name)
select * from t1;
grep ocdc -rl /app/web/sitemap grep |xargs sed -i "s/ocdc/替换内容/g"
sed -i "s/原字符串/新字符串/g" `grep 原字符串 -rl 所在目录`
sed -i "s/oldString/newString/g" `grep oldString -rl /path`
3.with … as (子查询)
必须和其他语句一起用,定义多个临时表之间用逗号","连接,with 只需要写一次,as 之后的语句要用括号括起来
with t1 as (
select * from tb_name
),
t2 as (
select * from tb_name
)
select * from t1;
4.case … when … then
select name,class,score,
case
when score >= 90 then 'genius'
when score >= 60 and score < 80 then 'excellent'
else 'fighting'
end as a
from test.demo_score
where class = 'math';
5.gourp by 语句
通常和聚合函数一起使用,按照一个或多个列对结果进行分组,然后对每个组进行聚合操作
如test.demo_score表中字段分别为名字,分数,科目
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dIhaCow1-1658977075622)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220706165923274.png)]
select name,sum(score) from test.demo_score group by name;
按名字分组将分数相加,执行命令,结果为:
a 182
b 140
c 116
w 126
having子句可以对group by产生的结果进行过滤:
select name,sum(score) from test.demo_score group by name having sum(score) >= 140 ;
在group by分组的时候,不能使用where,只能使用having进行条件查询结果:
a 182
b 140
6.join表连接
hive只支持等值连接,on子句指定连接条件,多个连接条件只能用and并列,不支持or
(1)inner join 内连接
连接的表中,只有同时满足连接条件的记录才会输出
如test.demo表中name值为abcde,test.demo_score中name值为abcw,通过name字段inner join后只有name为abc对应的数据保留
select a.name,a.id,b.name,b.class
from
test.demo a
inner join
test.demo_score b
on a.name = b.name
a 1 a math
a 1 a english
b 2 b math
b 2 b english
c 3 c math
c 3 c english
(2)left join 左连接
左侧表的数据全部保留,右侧表只有符合on条件的数据才保留,如右表中name没有de值,则返回null
select a.name,a.id,b.name,b.class
from
test.demo a
left join
test.demo_score b
on a.name = b.name
a 1 a math
a 1 a english
b 2 b math
b 2 b english
c 3 c math
c 3 c english
d 4 NULL NULL
e 5 NULL NULL
(3)right join 右连接
和左连接规则相反,右侧数据全部保留,其他地方为null
a 1 a math
a 1 a english
b 2 b math
b 2 b english
c 3 c math
c 3 c english
NULL NULL w math
NULL NULL w english
(4)full join 全连接
两侧表的数据全部保留
(5)left semi join 左半开连接
返回左表的记录,但前提是右表满足on条件。相当于执行效率更高的inner join,但是又有点区别,select中不能出现右表的字段
select a.name,a.id
from
test.demo a
left semi join
test.demo_score b
on a.name = b.name;
a 1
b 2
c 3
left semi join只返回左边的记录,右表的数据相当于一个过滤条件。由于右表abc的记录都有两条inner join的结果会是
a 1
a 1
b 2
b 2
c 3
c 3
(6)笛卡尔积连接
select * from a join b ;
不加on 连接条件
结果是左表中的每一条数据和右表中的每一条数据进行连接,产生的数据量是左表行数乘右表行数。在严格模式下禁止用户执行笛卡尔积连接。
(21条消息) 零基础学习hive(简单实用)_吾岸WAN的博客-CSDN博客_hive学习
7.排序
(1)order by 全局排序
select * from test.dome_score order by score desc;
#desc 从大到小,叫降序排列,不加desc是从小到大的正序排列
由于是全局排序,order by 的操作要在map 后所有的数据都汇集到一个reduce 上执行,如果数据量大执行的时间会很久
相当于要走完一整个mapreduce的流程,速度会比较慢
(2)sort by 局部排序
sort by 是在每一个reduce 中进行排序,但相同字段可能会被分配到多个reduce 上,因此局部排序的结果未必在全局上也排好顺序
select score from test.dome_score sort by score desc;
sort by 经常和distribute by 一起使用,distribute by name可以指定相同name的数据分配到同一个reduce 上处理,但依然不是全局排序
如果distribute by 和sort by 的字段为同一个,可以简写为cluster by
select * from test.demo_score distribute by score sort by score;
等同于
select * from test.demo_score cluster by score;
7.union all 对多个查询进行合并
union all 可以将多个查询进行合并,但每一个union 子查询必须具有相同的列,且字段的类型一致。多用于将多个表的数据进行合并。
select a.name,a.id,a.source from
(
select name,id,'demo' as source from test.demo
union all
select name,score as id,'demo_score' as source from test.demo_score
)a ;
shell编程基础
1、Shell概述
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sPO4PaL1-1658977075622)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220713092102610.png)]
/bin/bash --version
1.2 shell功能
Linux 系统中所有可执行文件都可以在Shell中执行。
Linux中5类可执行文件 :
- Linux命令
- 内置命令
- 实用程序
- 用户程序
- Shell脚本
1.3 shell命令执行过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2oAxY6Dg-1658977075622)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220713092203388.png)]
在查找外部命令时有两种情况:1)若给出用户路径,则按照给出的路径查找。2)若用户未给出路径,则在环境变量$PATH所指定的路径中查找。
环境变量PATH的信息可以使用下面命令查看,注意大写PATH:
echo $PATH
2 shell 技巧
2.1 输入输出重定向
输入重定向
输入重定向运算符“ < ”,指定右值为左值的输入
命令<文件名1
输出重定向
输出重定向运算符“ > ”,指定右值为左值的输出
命令>文件名1
(追加用 >>)
例如:
cat file1 > file # 清空file中的内容,file1中内容覆盖
cat file2 >> file # file2中内容追加到file1后面
错误重定向
命令 2>文件名
注意:
在错误重定向中使用了标准错误文件的编号2。其实在输入/输出重定向中,也可以添加相应对应的文件编号,如下:
命令 0 < 文件名
命令 1 > 文件名
命令 1 >> 文件名
只是当标准输入、标准输出的文件编号出现在重定向的左侧时,可以被省略。
掌握“&”运算符----表示 “等同于”
eg: 2>&1 : 将标准错误的输出重定向到指定的标准输入输出文件。若在此之前,标准输出文件已经被修改,则命令执行过程中的错误不会输入到默认的标准输出文件,而是输出到当前指定的标准输出文件。
如下:
标准输出已经重定向到空设备文件,因此标准错误输出也重定向到空设备文件。
1 > /dev/null
2 > &1
2.2 管道
可以将简单的命令连接起来,使一个命令的输出作为另外一个命名的输入,由此实现更加复杂的功能。符号:" | ".
命令1 | 命令2 | 命令...
2.3 命令连接符
- ;连接符
命令按照先后次序执行 - &&连接符
前面命令执行成功,后面的才执行 - ||连接符
前面命令执行失败,后面的才执行
2.4 文本提取器命令
awk
3 shell编程
注意的细节:
- 单引号中间的变量会被视为字符串,不能够被解析
- 变量定义,等号两侧不能有空格
- if中的test命令[],在使用时,距离两个中括号内侧都要有空格
- 在脚本中使用 expr 命令,要用 tab上面的反引号括起来,不是单引号。
执行shell
(1))chmod +x 文件名
./文件名
(2)sh 文件名
3.1 shell中的变量及基本操作
# 定义变量
var='hello'
# 使用变量,加{}是良好的编程习惯
$var
${var}
# 返回变量长度
${#var}
# 从命令行读取数据,即用户交互输入
read 变量名
# 位置变量
$0 :脚本的名称
$1 :脚本的第一个参数
$2 :脚本的第二个参数
$# : 传递到脚本的参数量,这里是2个
# 运算
let
expr
- let
let命令可以进行算术运算和数值表达式测试。
let 表达式
在脚本中使用,我目前在终端直接运行没有结果输出:
脚本如下:
#!/bin/bash
i=1
echo "i="$i
let i=i+2
echo "i="$i
let "i=i+4"
echo "i="$i
echo "*************"
((i+=3))
echo "i="$i
exit 0
let命令也可以使用 (()) 替代, 根据上述脚本
((算术表达式))
- expr
操作符和数据之间需要用空格,可以直接在终端使用
[user]$ expr 2 + 2
4
expr在脚本里面的话需要使用tab上面的反引号进行括起来
#!/bin/bash
a=10
b=20
value=`expr $a + $b `
echo "value is $value"
exit 0
结果:
value is 30
3.2 if语句
条件判断:
test 命令:
test 选项 参数
检查文件是否存在:
if test -f file
then
...
fi
test命令可以使用 命令 [ 来替代,两者都可以起到判断作用
if [ -f file ]
then
...
fi
[ 命令也是命令,命令与选项及参数之间应有空格。
因此在 [] 符号与其中的条件检查之间需要留出空格,否则将会产生错误。
#!/bin/bash
# 单分支if语句
read filename
if [ -d $filename ]
then
echo $filename "是个目录"
fi
# 双分支语句
read filename2
if [ -d $filename2 ]
then
echo $filename2"是个目录"
else
echo $filename2"不是目录"
fi
# 多分支if语句
read filename3
if [ -d $filename3 ]
then
ls $filename3
elif [ -x $filename ];then
echo "这是一个可执行文件"
else
echo "该文件不可执行"
fi
exit 0
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WsS0dOeG-1658977075623)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220713101938079.png)]
2.if [];then else fi 语句
if [ expression ];then
executed Statement_expression_true
else
executed Statement_expression_false
fi
if [ expression1 ];then
executed Statement_expression1_true
elif [ expression2 ];then
executed Statement_expression2_true
else
executed Statement_expression1_2_false
fi
.if语句常用命令选项有:
== or =: 等于
-eq : 等于
-ne :不等于
-gt :大于
-ge :大于等于
-lt :小于
-le :小于等于
一般if循环还是选择if…elif…else…fi
这样比较简便并且代码清晰明了
if [ a = b ] a与b是否相等 (a、b是数值)
if [ a -ge b ] a 是否大于等于 b
if [ a -gt b ] a 是否大于 b
if [ a -le b ] a 是否小于等于 b
if [ a -lt b ] a 是否小于 b
if [ a -ne b ] a 是否不等于 b
if [ str1 = str2 ] str1是否与str2相同(str1、str2是字符串)
if [ str1 != str2 ] str1是否与str2不同
if [ str1 < str2 ] str1是否小于str2
if [ str1| str2 ] str1是否da于str2
if [ -n str ] 判断str长度是否非零
if [ -z str ] str长度是否为0
if [ -d file ] 判断file是否为一个目录
if [ -e file ] 判断file是否存在
if [ -f file ] 检查file文件是否存在
if [ -r file ] 判断file是否存在并可读
if [ -s file ] 判断file是否存在并非空
if [ -w file ] 判断file是否存在并可写
if [ -x file ] 判断file是否存在并可执行
3.3 select语句
可以将列表做出类似目录的形式,以交互的形式选择在列表中的数据。break是跳出
#!/bin/bash
echo "what you want to choice"
select subject in "C++" "C" "java"
do
echo "you have select $subject"
break
done
exit 0
3.4 case语句
将一个变量的内容与多个选项进行匹配,匹配成功,则执行相关语句;
每个匹配条件以 ;; 结尾相当于 break
最后一个匹配项 * ,类似于C语言中的default,是一个通配符,该匹配项末尾不需要 ;;
#!/bin/bash
echo -e "a:\c"
read a
echo -e "b:\c"
read b
echo -e "select(+-):\c"
read var
case $var in
'+')echo "a+b="`expr $a + $b` ;;
'-')echo "a-b=" `expr $a - $b ` ;;
*)echo "error"
esac
exit 0
[(26条消息) Shell编程_多尝试多记录多积累的博客-CSDN博客_shell编程](https://blog.csdn.net/wy_______/article/details/124558659?ops_request_misc=%7B%22request%5Fid%22%3A%22165767461516782395337790%22%2C%22scm%22%3A%2220140713.130102334…%22%7D&request_id=165767461516782395337790&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-2-124558659-null-null.142v32new_blog_fixed_pos,185v2control&utm_term=shell 编程&spm=1018.2226.3001.4187)
下次接着复习
Scala
三种输出方式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dmfjEtr2-1658977075623)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220713111804175.png)]
输入的三种样式
var str1:String="hello"
var str2:String="scala"
println(s"str1+str2=${str1+str2}")
println("str1+str2="+{str1+str2})
println("=="*20)
var name:String="TOM"
var age:Int=10
var sal:Float=10.6f
var height:Double=180.15
//格式化输出
printf("名字%s 年龄%d 薪水%.2f 身高%.3f",name,age,sal,height)
println("=="*20)
println(s"\n个人信息如下所示 \n姓名:$name \n年龄:$age \n薪水:$sal \n身高:$height ")
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cwkX0wDY-1658977075624)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220713113021080.png)]
//var的值是可以修改的,但是类型不行,因为Scala啊是强类型语言,val的值也不可以修改,但是使用val的话没有线程安全的问题,效率较高推荐使用。
//因为在大多数时候使用都是创建一个对象,引用对象的属性而不改变对象本身,所以对象可以使用val,如果对象需要改变的话,那就使用var
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aD86YnWy-1658977075624)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220713141715304.png)]
5.程序中 +号的使用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DEEgbeQc-1658977075624)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220713141920503.png)]
1.数据类型
Scala和Java一样,有8种数据类型(AnyVal): 7种数值类型Byte、Char、Short、Int、Long、Float和Double(无包装类型)和一个Boolean类型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pkiWHIjG-1658977075625)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220714144239942.png)]
2、条件[表达式]
if 【条件】 【执行语句】 else 【执行语句】
val x:Int=1
val y = if (x>0) -8 else -3
println(y)
val z=if (x>1) 80 else "error"
println(z)
scala中没有三目运算符,因为根本不需要。scala中if else表达式是有返回值的,如果if或者else返回的类型不一样,就返回Any类型(所有类型的公共超类型)。
如果缺少一个判断,什么都没有返回,但是Scala认为任何表达式都会有值,对于空值,使用Unit类,写做(),叫做无用占位符,相当于java中的void。
尖叫提示: 行尾的位置不需要分号,只要能够从上下文判断出语句的终止即可。但是如果在单行中写多个语句,则需要分号分割。在Scala中,{}快包含一系列表达式,其结果也是一个表达式。块中最后一个表达式的值就是块的值。
package cn.bigdata.scala
object BlockExpressionDemo {
def main(args: Array[String]) {
val x = 0
//在scala中{}中包含一系列表达式,块中最后一个表达式的值就是块的值
//下面就是一个块表达式
val result = {
if (x < 0){
-1
} else if(x >= 1) {
1
} else {
"error"
}
}
//result的值就是块表达式的结果
println(result)
val res01 = {
1+2
4+5
4>5
}
println(res01)
}
}
if (x>0){
1
}else{"error"}
val res01={
1+2
4+5
}
最后输出的是9,快里面最后一个表达式的值
3.循环
在scala中有for循环、while、do~while循环,用for循环比较多
(1)while表达式
Scala提供和Java一样的while和do~while循环,与If语句不同,While语句本身没有值,即整个While语句的结果是Unit类型的()。
while循环
var n = 1;
val while1 = while(n <= 10){
n += 1
}
println(while1)
println(n)
var m=1
while (m<10){
m+=1
println(m)
}
1,2,3,4,5,6,7,8,9,10
(2)for表达式
for循环语法结构:for (i <- 表达式/数组/集合)
to,until都表示范围,二者有何区别?
to为包含上限的闭区间,如:1 to 3,Range为1,2,3;
until不包含上限,如:1 until 3, Range为1,2
在需要使用从0到n-1的区间时,可以使用until方法。
for(i <- 1 to 3){
print(i)
}
println()
for(i <- 1 until 3) {
print(i)
}
println()
1.基本语法
for ( 循环变量 <- 数据集 ) {
循环体
}
这里的数据集可以是任意类型的数据集合,如字符串,集合,数组等,
object ScalaLoop {
def main(args: Array[String]): Unit = {
for ( i <- Range(1,5) ) { // 范围集合
println("i = " + i )
}
for ( i <- 1 to 5 ) { // 包含5
println("i = " + i )
}
for ( i <- 1 until 5 ) { // 不包含5
println("i = " + i )
}
}
2.循环守卫
循环时可以增加条件来决定是否继续循环体的执行,这里的判断条件我们称之为循环守卫
object ScalaLoop {
def main(args: Array[String]): Unit = {
for ( i <- Range(1,5) if i != 3 ) {
println("i = " + i )
}
}
3.循环步长
scala的集合也可以设定循环的增长幅度,也就是所谓的步长step
object ScalaLoop {
def main(args: Array[String]): Unit = {
for ( i <- Range(1,5,2) ) {
println("i = " + i )
}
for ( i <- 1 to 5 by 2 ) {
println("i = " + i )
}
}
4.循环嵌套
object ScalaLoop {
def main(args: Array[String]): Unit = {
for ( i <- Range(1,5); j <- Range(1,4) ) {
println("i = " + i + ",j = " + j )
}
for ( i <- Range(1,5) ) {
for ( j <- Range(1,4) ) {
println("i = " + i + ",j = " + j )
}
}
}
5.引入变量
object ScalaLoop {
def main(args: Array[String]): Unit = {
for ( i <- Range(1,5); j = i - 1 ) {
println("j = " + j )
}
}
6.循环返回值
scala所有的表达式都是有返回值的。但是这里的返回值并不一定都是有值的哟。
如果希望for循环表达式的返回值有具体的值,需要使用关键字yield
object ScalaLoop {
def main(args: Array[String]): Unit = {
val result = for ( i <- Range(1,5) ) yield {
i * 2
}
println(result)
}
def main(args: Array[String]): Unit = {
for(i <- 1 to 3 by 1 ) {
println(s"i=$i")
}
}
4.函数训练
def main(args: Array[String]): Unit = {
def func(yAge:Int,mAge:Int):String={
val a:Boolean=yAge>=mAge
val str:String=if (a){"哥哥"} else{ "弟弟"}
str
}
println(func(80,20))
}
方法
def m1(x : Int , y : Int ) : Int = {x + y} //三种声明方式
def m2(x:Int , y:Int) {print(x+y)}
def m3(x:Int , y:Int){x+y}
解释:m1是方法名 xy是int型的参数 括号外的int是返回值类型 x+y是方法
调用:m1 (3,4)
函数
val f1 = (x:Int , y:Int) => x+y //声明
val f1 = (x:Int , y:Int) =>{
val sum = x+y
sum*100} //最后一句作为函数的返回值 函数没有返回值类型
回车之后会看到
f1: (Int, Int) => Int =
这里的function2中的2指的是参数的个数
调用:f1 (3,4) //与方法的调用一致
方法的写法
def m(x:Int,y:Int):Int={x+y}
调用m(1,2)
函数的写法
val f=(x:Int,y:Int)=>{x+y}
调用f(1,2)
scala> import scala.math._
scala> sqrt(100)
apply与update方法
apply方法是调用时可以省略方法名的方法。用于构造和获取元素:
"Hello"(4) 等同于 "Hello".apply(4)
Array(1,2,3) 等同于 Array.apply(1,2,3)
如:
println("Hello"(4))
println("Hello".apply(4))
option类型
val map1 = Map("Alice" -> 20, "Bob" -> 30)
println(map1.get("Alice"))
println(map1.get("Jone"))
Try…catch
def divider(x: Int, y: Int): Float= {
if(y == 0) throw new Exception("0作为了除数")
else x / y
}
def main(args: Array[String]): Unit = {
try {
println(divider(10, 0))
} catch {
case ex: Exception => println("捕获了异常:" + ex)
}
输出
捕获了异常:java.lang.Exception: 0作为了除数
5.数组
\1) 定长数组
//定义
val arr1 = new Array[Int](10)
//赋值
arr1(1) = 7
或:
//定义
val arr1 = Array(1, 2)
\2) 变长数组
//定义
val arr2 = ArrayBuffer[Int]()
//追加值
arr2.append(7)
//重新赋值
arr2(0) = 7
\3) 定长数组与变长数组的转换
arr1.toBuffer
arr2.toArray
\4) 多维数组
//定义
val arr3 = Array.ofDim[Double](3,4)
//赋值
arr3(1)(1) = 11.11
\5) 与Java数组的互转
Scal数组转Java数组:
val arr4 = ArrayBuffer("1", "2", "3")
//Scala to Java
import scala.collection.JavaConversions.bufferAsJavaList
val javaArr = new ProcessBuilder(arr4)
println(javaArr.command())
Java数组转Scala数组:
import scala.collection.JavaConversions.asScalaBuffer
import scala.collection.mutable.Buffer
val scalaArr: Buffer[String] = javaArr.command()
println(scalaArr)
\6) 数组的遍历
for(x <- arr1) {
println(x)
}
6.元组 Tuple
元组也是可以理解为一个容器,可以存放各种相同或不同类型的数据。
- 元组的创建
val tuple1 = (1, 2, 3, "heiheihei")
println(tuple1)
- 元组数据的访问,注意元组元素的访问有下划线,并且访问下标从1开始,而不是0
val value1 = tuple1._4
println(value1)
- 元组的遍历
方式1:
for (elem <- tuple1.productIterator) {
print(elem)
}
println()
方式2:
tuple1.productIterator.foreach(i => println(i))
tuple1.productIterator.foreach(print())
7.列表 List
如果List列表为空,则使用Nil来表示。
\1) 创建List
val list1 = List(1, 2)
println(list1)
\2) 访问List元素
val value1 = list1(1)
println(value1)
\3) List元素的追加
val list2 = list1 :+ 99
println(list2)
val list3 = 100 +: list1
println(list3)
\4) List的创建与追加,符号“::”,注意观察去掉Nil和不去掉Nil的区别
val list4 = 1 :: 2 :: 3 :: list1 :: Nil
println(list4)
8.队列 Queue
队列数据存取符合先进先出策略
\1) 队列的创建
import scala.collection.mutable
val q1 = new mutable.Queue[Int]
println(q1)
不可变集合:scala.collection.immutable
可变集合: scala.collection.mutable
\2) 队列元素的追加
q1 += 1;
println(q1)
\3) 向队列中追加List
q1 ++= List(2, 3, 4)
println(q1)
\4) 按照进入队列的顺序删除元素
q1.dequeue()
println(q1)
\5) 塞入数据
q1.enqueue(9, 8, 7)
println(q1)
\6) 返回队列的第一个元素
println(q1.head)
\7) 返回队列最后一个元素
println(q1.last)
\8) 返回除了第一个以外的元素
println(q1.tail)
9. 映射 Map
这个地方的学习,就类比Java的map集合学习即可。
\1) 构造不可变映射
val map1 = Map("Alice" -> 10, "Bob" -> 20, "Kotlin" -> 30)
\2) 构造可变映射
val map2 = scala.collection.mutable.Map("Alice" -> 10, "Bob" -> 20, "Kotlin" -> 30)
\3) 空的映射
val map3 = new scala.collection.mutable.HashMap[String, Int]
\4) 对偶元组
val map4 = Map(("Alice", 10), ("Bob", 20), ("Kotlin", 30))
\5) 取值
如果映射中没有值,则会抛出异常,使用contains方法检查是否存在key。如果通过 映射.get(键) 这样的调用返回一个Option对象,要么是Some,要么是None。
val value1 = map1("Alice")//建议使用get方法得到map中的元素
println(value1)
\6) 更新值
map2("Alice") = 99
println(map2("Alice"))
或:
map2 += ("Bob" -> 99)
map2 -= ("Alice", "Kotlin")
println(map2)
或:
val map5 = map2 + ("AAA" -> 10, "BBB" -> 20)
println(map5)
\7) 遍历
for ((k, v) <- map1) println(k + " is mapped to " + v)
for (v <- map1.keys) println(v)
for (v <- map1.values) println(v)
for(v <- map1) prinln(v)
-> 是映射
<- 是遍历
10.集 Set
集是不重复元素的结合。集不保留顺序,默认是以哈希集实现。
如果想要按照已排序的顺序来访问集中的元素,可以使用SortedSet(已排序数据集),已排序的数据集是用红黑树实现的。
默认情况下,Scala 使用的是不可变集合,如果你想使用可变集合,需要引用 scala.collection.mutable.Set 包。
\1) Set不可变集合的创建
val set = Set(1, 2, 3)
println(set)
\2) Set可变集合的创建,如果import了可变集合,那么后续使用默认也是可变集合
import scala.collection.mutable.Set
val mutableSet = Set(1, 2, 3)
\3) 可变集合的元素添加
mutableSet.add(4)
mutableSet += 6
// 注意该方法返回一个新的Set集合,而非在原有的基础上进行添加
mutableSet.+(5)
\4) 可变集合的元素删除
mutableSet -= 1
mutableSet.remove(2)
println(mutableSet)
\5) 遍历
for(x <- mutableSet) {
println(x)
}
\6) Set更多常用操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7WCA8MFf-1658977075625)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220720082942787.png)]
11. 集合元素与函数的映射
\1) map:将集合中的每一个元素映射到某一个函数
val names = List("Alice", "Bob", "Nick")
println(names.map(_.toUpperCase))
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8A2TOk6m-1658977075626)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220720083744471.png)]
\2) flatmap:flat即压扁,压平,扁平化
效果就是将集合中的每个元素的子元素映射到某个函数并返回新的集合
val names = List("Alice", "Bob", "Nick")
println(names.flatMap(_.toUpperCase()))
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uo2WrMN7-1658977075626)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220720083726992.png)]
12.化简、折叠、扫描
1.折叠,化简
将二元函数引用于集合中的函数
val list = List(1, 2, 3, 4, 5)
val i1 = list.reduceLeft(_ - _)
val i2 = list.reduceRight(_ - _)
println(i1)
println(i2)
reduceLeft=1-2-3-4-5
reduceRight=
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PvhmDwTL-1658977075627)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220720084128874.png)]
\2) 折叠,化简:fold
fold函数将上一步返回的值作为函数的第一个参数继续传递参与运算,直到list中的所有元素被遍历。可以把reduceLeft看做简化版的foldLeft。相关函数:fold,foldLeft,foldRight,可以参考reduce的相关方法理解。
val list2 = List(1, 9, 2, 8)
val i4 = list2.fold(5)((sum, y) => sum + y)
println(i4)
相当于fold把List2里面的值放到sum里面,作为函数的第一个参数进行参与运算,5作为第二个参数被放进函数
foldRight
val list4 = List(1, 9, 2, 8)
val i5 = list3.foldRight(100)(_ - _)
println(i5)
val i5=list4.foldRight(100)(_ - _)
i5: Int = 86
val i5=list4.foldLeft(100)(_ - _)
i5: Int = 80
*尖叫提示:foldLeft和foldRight有一种缩写方法对应分别是/:和:*
例如:
foldLeft
val list4 = List(1, 9, 2, 8)
val i6 = (0 /: list4)(_ - _)
println(i6)
- 统计一句话中,各个文字出现的次数
val sentence = "一首现代诗《笑里藏刀》:哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈刀哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈"
//m + (“一” -> 1, “首” -> 1, “哈” -> 1)
val i7 = (Map[Char, Int]() /: sentence)((m, c) => m + (c -> (m.getOrElse(c, 0) + 1)))
println(i7)
下次继续
(28条消息) Scala_涵死_的博客-CSDN博客
问题作业
hadoop Job允许map task失败的比例
set mapred.max.map.failures.percent=10
比例为总map task的10%
表示开启动态分区功能
set hive.exec.dynamic.partition=true
set hive.exec.dynamic.partition =true(默认false),表示开启动态分区功能
set hive.exec.dynamic.partition.mode = nonstrict
set hive.exec.dynamic.partition.mode = nonstrict (默认strict),表示允许所有分区都是动态的,否则必须有静态分区字段
set hive.exec.max.dynamic.partitions.pernode=1000
–单个节点上的mapper/reducer允许创建的最大分区
默认值:100
在每个执行MR的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。
比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,如果使用默认值100,则会报错。
set hive.exec.max.dynamic.partitions=1500;
–允许动态分区的最大数量
默认值:1000
在所有执行MR的节点上,最大一共可以创建多少个动态分区。
同上参数解释。
spark.sql.shuffle.partitions=50
外层对表的主键进行分组开窗,其实就是最后一步进行shuffle。由于是主键,所以不存在数据倾斜问题,性能影响不大,数据重新均匀打散,再spark.sql.shuffle.partitions参数生成指定分区数量
避免调用hive一直合成小文件,提高执行速度
mapreduce.map.memory.mb:
一个Map Task可使用的资源上限(单位:MB),默认为1024。如果Map Task实际使用的资源量超过该值,则会被强制杀死。
**mapreduce.reduce.memory.mb**:
一个Reduce Task可使用的资源上限(单位:MB),默认为1024。如果Reduce Task实际使用的资源量超过该值,则会被强制杀死。
set mapred.map.tasks=10
调整map的数量
set mapred.reduce.tasks=10
调整reduce的数量
hadoop fs -count -q /sunwg
1024 1021 10240 10132 2 1 108 hdfs://sunwg:9000/sunwg
在count后面增加-q选项可以查看当前文件夹的限额使用情况,
第一个数值1024,表示总的文件包括文件夹的限额
第二个数值1021表示目前剩余的文件限额,即还可以创建这么多的文件或文件夹
第三个数值10240表示当前文件夹空间的限额
第四个数值10132表示当前文件夹可用空间的大小,这个限额是会计算多个副本的
剩下的三个数值与-count的结果一样
(names.flatMap(_.toUpperCase()))
[外链图片转存中...(img-uo2WrMN7-1658977075626)]
## 12.化简、折叠、扫描
### 1.折叠,化简
将二元函数引用于集合中的函数
val list = List(1, 2, 3, 4, 5)
val i1 = list.reduceLeft(_ - )
val i2 = list.reduceRight( - _)
println(i1)
println(i2)
reduceLeft=1-2-3-4-5
reduceRight=
[外链图片转存中...(img-PvhmDwTL-1658977075627)]
\2) 折叠,化简:fold
fold函数将上一步返回的值作为函数的第一个参数继续传递参与运算,直到list中的所有元素被遍历。可以把reduceLeft看做简化版的foldLeft。相关函数:fold,foldLeft,foldRight,可以参考reduce的相关方法理解。
val list2 = List(1, 9, 2, 8)
val i4 = list2.fold(5)((sum, y) => sum + y)
println(i4)
相当于fold把List2里面的值放到sum里面,作为函数的第一个参数进行参与运算,5作为第二个参数被放进函数
foldRight
val list4 = List(1, 9, 2, 8)
val i5 = list3.foldRight(100)(_ - _)
println(i5)
val i5=list4.foldRight(100)(_ - _)
i5: Int = 86
val i5=list4.foldLeft(100)(_ - _)
i5: Int = 80
*尖叫提示:foldLeft和foldRight有一种缩写方法对应分别是/:和:\*
例如:
foldLeft
```scala
val list4 = List(1, 9, 2, 8)
val i6 = (0 /: list4)(_ - _)
println(i6)
- 统计一句话中,各个文字出现的次数
val sentence = "一首现代诗《笑里藏刀》:哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈刀哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈"
//m + (“一” -> 1, “首” -> 1, “哈” -> 1)
val i7 = (Map[Char, Int]() /: sentence)((m, c) => m + (c -> (m.getOrElse(c, 0) + 1)))
println(i7)
下次继续
问题作业
hadoop Job允许map task失败的比例
set mapred.max.map.failures.percent=10
比例为总map task的10%
表示开启动态分区功能
set hive.exec.dynamic.partition=true
set hive.exec.dynamic.partition =true(默认false),表示开启动态分区功能
set hive.exec.dynamic.partition.mode = nonstrict
set hive.exec.dynamic.partition.mode = nonstrict (默认strict),表示允许所有分区都是动态的,否则必须有静态分区字段
set hive.exec.max.dynamic.partitions.pernode=1000
–单个节点上的mapper/reducer允许创建的最大分区
默认值:100
在每个执行MR的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。
比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,如果使用默认值100,则会报错。
set hive.exec.max.dynamic.partitions=1500;
–允许动态分区的最大数量
默认值:1000
在所有执行MR的节点上,最大一共可以创建多少个动态分区。
同上参数解释。
spark.sql.shuffle.partitions=50
外层对表的主键进行分组开窗,其实就是最后一步进行shuffle。由于是主键,所以不存在数据倾斜问题,性能影响不大,数据重新均匀打散,再spark.sql.shuffle.partitions参数生成指定分区数量
避免调用hive一直合成小文件,提高执行速度
mapreduce.map.memory.mb:
一个Map Task可使用的资源上限(单位:MB),默认为1024。如果Map Task实际使用的资源量超过该值,则会被强制杀死。
**mapreduce.reduce.memory.mb**:
一个Reduce Task可使用的资源上限(单位:MB),默认为1024。如果Reduce Task实际使用的资源量超过该值,则会被强制杀死。
set mapred.map.tasks=10
调整map的数量
set mapred.reduce.tasks=10
调整reduce的数量
hadoop fs -count -q /sunwg
1024 1021 10240 10132 2 1 108 hdfs://sunwg:9000/sunwg
在count后面增加-q选项可以查看当前文件夹的限额使用情况,
第一个数值1024,表示总的文件包括文件夹的限额
第二个数值1021表示目前剩余的文件限额,即还可以创建这么多的文件或文件夹
第三个数值10240表示当前文件夹空间的限额
第四个数值10132表示当前文件夹可用空间的大小,这个限额是会计算多个副本的
剩下的三个数值与-count的结果一样