不平衡数据采样方法整理
不平衡数据采样方法整理
在实际的分类问题中,数据集的分布经常是不均衡的。虽然不均衡的数据在分类时常常能得到较高的分类准确率,但对于某些情况而言,准确率的意义并不大,并不能提供任何有用的信息。
从数据层面上而言,对于不平衡数据主要通过重采样的方法对数据集进行平衡。重采样方法是通过增加小众训练样本数的上采样和减少大众样本数的下采样使不平衡样本分布变平衡,从而提高分类器对小众的识别率。
1.上采样
(1)朴素随机上采样算法
算法流程:
从小众样本中进行随机采样来增加新的样本。
优缺点:
随机采样最大的优点是简单,但由于小众样本被复制了多份,因此训练出来的模型会有一定的过拟合。
实现方法:
R:Sample;
Python:imblearn.over_sampling-RandomOverSampler;
参考资料:
https://www.cnblogs.com/kamekin/p/9824294.html
(2)SMOTE算法
SMOTE算法是一种简单有效的上采样方法,它利用小众样本在特征空间的相似性来人工合成新样本。
算法流程:
第一,对于小众中每一个样本x_i,计算该点与小众中其他样本点的距离,得到最近的k个近邻(即对小众点进行KNN算法)。
第二,根据样本不平衡比例设置一个采样比例以确定采样倍率,对于每一个小众样本x_i,从其k近邻中随机选择若干个样本,假设选择的近邻为(x_i ) ̂;
第三,对于每一个随机选出的近邻(x_i ) ̂,分别与原样本按照如下的公式构建新的样本:
x_new=x_i+((x_i ) ̂-x_i )×δ δ∈[0,1]
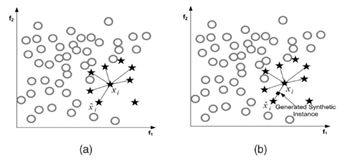
优缺点:
虽然加强了原始数据中小众的占比,但增加了类之间重叠的可能性,模糊了正负类边界,且容易生成一些没有提供有益信息的样本。
实现方法:
R:DmWR-Smote;
Python:imblearn.over_sampling-SMOTE;
参考资料:
N. V. Chawla, K. W. Bowyer. SMOTE: Synthetic Minority Over-sampling Technique
https://www.jianshu.com/p/e83a3ce2c837
https://blog.csdn.net/nlpuser/article/details/81265614
(3)Borderline-SMOTE算法
原始的SMOTE算法对所有的小众样本都是一视同仁的,但实际建模过程中发现那些处于边界位置的样本更容易被错分,因此利用边界位置的样本信息产生新样本可以给模型带来更大的提升。Borderline-SMOTE是一种自适应综合过采样方法,其解决思路是只为那些K近邻中有一半以上大众样本的小众样本生成新样本,因为这些样本往往是边界样本。在确定了为哪些小众样本生成新样本后,再利用SMOTE生成新样本。
Borderline SMOTE有两个版本:Borderline SMOTE-1和Borderline SMOTE-2。
算法流程:
Borderline SMOTE-1算法流程:
记整个训练集合为T,小众样本集合为P,大众样本集合为N。对P中的每一个样本pi,在整个训练集合T中搜索得到其最近的m个样本,记其中小众样本数量为m’,若m’= m, 则p是一个噪声,不做任何操作;若0 ≤m’ ≤m/2, 则说明p很安全,不做任何操作;若m/2 ≤ m’≤ m, 那么点p为危险点,需要在这个点附近利用SMOTE方法生成一些新的小众点。

Borderline SMOTE-2算法流程:
前半部分与Borderline SMOTE-1相同,在判断出哪些小众样本点属于危险集后,在危险集中的点不仅从P集中求最近邻并生成新的小众点,而且在N集中求最近邻,并生成新的小众点。首先从小众样本集合P和大众样本集合N中分别得到k个最近邻样本Pk和Nk。设定一个比例α,在Pk中选出α比例的样本点和xi作随机的线性插值产生新的小众样本,方法同Borderline SMOTE-1;在Nk中选出1−α比例的样本点和xi作随机的线性插值产生新的小众样本,此处的随机数范围选择的是(0,0.5),即使得产生的新的样本点更靠近小众样本。
优缺点:
两种Borderline SMOTE方法都可以加强边界处模糊样本的存在感,且Borderline SMOTE-2又能在此基础上使新增样本更加靠近真实值。
实现方法:
Python:imblearn.over_sampling-SMOTE,kind参数中可选borderline1或borderline2;
参考资料:
Hui Han1, Wen-Yuan Wang1, Bing-Huan Mao2.Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning
https://sci2s.ugr.es/keel/keel-dataset/pdfs/2005-Han-LNCS.pdf
https://blog.csdn.net/Scc_hy/article/details/84190080
(4)ADASYN算法
ADASYN是一种自适应综合过采样方法,其解决思路是根据数据分布情况为不同的小众样本生成不同数量的新样本。
算法流程:
第一,计算需要生成的新小众样本数量G,G=(|S_maj |-|S_min |)×β,其中,βϵ[0,1],表示期望在合成数据之后想要达到的平衡度;
第二,对于每个小众类中的样本,计算每个小众样本周围大众样本的比例r_i,r_i=Δ_i/K,其中,Δ_i表示距离最近的K个样本点中大众类的样本数量。再利用Γ_i=r_i/∑▒r_i 将r_i归一化处理,使得Γ_i满足条件:∑▒Γ_i =1。
第三.对于小众类中的每个样本,计算需要生成的合成数据的数量g_i,g_i=G×Γ_i;
第四,在每个待合成的小众样本周围k个邻居中选择1个小众样本,利用线性插值法x_new=x_i+(x ̂-x_i )×δ进行合成直至达到目标合成数目为止。
优缺点:
能够自适应的决定每个小众样本的合成数量,但不能抵抗噪声的干扰。
实现方法:
Python:imblearn.over_sampling-ADASYN
参考资料:
Xuchun Li,Lei Wang,Eric Sung.AdaBoost with SVM-based component classifiers.
https://blog.csdn.net/weixin_40118768/article/details/80226423
https://blog.csdn.net/hren_ron/article/details/81172044
(5)KM-SMOTE算法
KM-SMOTE算法是将K-means聚类与SMOTE相结合,增加小众样本数量的算法。
算法流程:
第一,选择小众样本数据对其进行K-means聚类,聚为K类,并记录每一类的簇心{c_1,c_2,⋯,c_n};
第二,利用每一类的簇心进行插值,得到
x_new=c_i+(X-c_i )×rand(0,1)
其中,x_new为新插值的样本;c_i 为簇心;X是以c_i 为簇心聚类中的原始样本数据;rand(0,1)表示0到1之间的随机数。
优缺点:
KM-SMOTE以聚类为区域进行插值,有助于数据集形成以簇为中心的数据集群,帮助有针对性的插值,能够有效的防止插值泛化;且插值的数据在簇心和原始数据点的连线上,不会出现泛边界的数据。
实现方法:
R:kmeans+smote
参考资料:
陈斌,苏一丹,黄山,基于km-smote和随机森林的不平衡数据分类
https://www.docin.com/p-1660963834.html
2.下采样
(1)朴素随机下采样算法
算法流程:
从大众样本中随机选择少量样本(分为有放回和无放回两种),再合并原有小众样本作为新的训练数据集。
优缺点:
在去除大众样本的时候,容易去除重要的样本信息。
实现方法:
Python:imblearn.under_sampling-RandomUnderSampler;
参考资料:
https://www.cnblogs.com/kamekin/p/9824294.html
(2)EasyEnsemble算法
算法流程:
第一,从大众类样本数据中有放回的随机采样T次,每次选取与小众样本数目近似的样本,得到T个样本集合{s_1,s_2,⋯,s_T}。
第二,将每一份抽取的大众样本与小众样本结合组成一组训练样本,得到{D_1,D_2,⋯,D_n},并在每一组训练样本上训练一个adaboost分类器H_i,每个H_i都是由s_i个弱分类器h_(i,j)组成,每个弱分类器的权重为α_(i,j),阈值为θ_i。
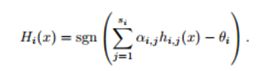
第三,当所有被抽出的子集都训练完成时,综合所有训练器,得到最终的集成分类器。
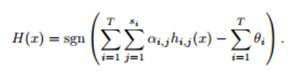
优缺点:
EasyEnsemble算法有效解决了数据不均衡问题,且减少了欠采样造成的大众样本信息损失。但该算法未考虑小众样本极度欠缺的情况,当小众样本数远小于正确训练分类器所需的样本数时,每个基学习器的分类性能都可能会很差,进而导致最终分类器的分类效果差。
实现方法:
Python: imblearn.ensemble-ensemble(n_subsets控制子集个数,replacement 决定是有放回还是无放回的随机采样)
参考资料:
Liu X Y,Wu J X,Zhou Z H.Exploratory Undersampling for Class-Imbalance Learning.
https://blog.csdn.net/march_on/article/details/48656391
https://www.cnblogs.com/kamekin/p/9824294.html
(3)BalanceCascade算法
BalanceCascade算法前半部分与EasyEnsemble算法相同,都需要对大众样本进行下采样训练出一个分类器,对于那些分类正确的大众样本不放回,然后对剩余的大众样本重新下采样产生训练集,训练第二个分类器,以此类推。
算法流程:
第一,初始化:i表示迭代次数,T表示最大迭代次数,H_i表示每一次训练得到的分类器,s_i表示H_i中的弱分类器的数量,误报率(把一个大众类的样本分类成小众类)为f=√(T-1&|S_min |/|S_maj | );
第二,从大众样本中随机抽取一个子集E,子集E的样本数量与小众样本数量相当。
第三,使用E与小众样本集S_min作为训练集训练分类器H_i,每个H_i都是由s_i个弱分类器h_(i,j)组成,每个弱分类器的权重为α_(i,j),阈值为θ_i,得到

第四,重新计算分类误报率,并据此调整θ_i
第五,从大众样本中删除掉已被H_i正确分类的大众样本;
第六,重复以上步骤,直到达到最大迭代次数T,最终输出一个集成分类器:

在这个方法中,每一次迭代过程都会造成数据集中大众的数量减少,而且每一步的集成分类器都是由平衡的数据集训练得到的。只有当所有的H_i都预测为正例的时候,最终的分类器才会预测为正例。
优缺点:
这种方法有效减少了欠采样造成的大众样本信息损失的问题,且在每次迭代过程中,在有限的样本空间里可以充分利用尽可能多的信息,但同样未考虑小众样本极度欠缺的情况。
实现方法:
Python: imblearn.ensemble-BalanceCascade
参考资料:
https://www.cnblogs.com/kamekin/p/9824294.html
https://blog.csdn.net/hren_ron/article/details/81172044
(4)NearMiss算法
NearMiss本质上是从大众样本中选取最具代表性的样本用于训练,主要是为了缓解随机欠采样中的信息丢失问题,总结起来有以下几类:
NearMiss-1:在大众样本中选择与最近的K个小众样本的平均距离最小的样本。
NearMiss-2:在大众样本中选择与最远的K个小众样本的平均距离最小的样本。
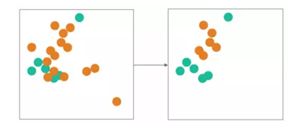
NearMiss-3:对于每个小众样本,选择离它最近的K个大众样本,目的是保证每个小众样本都被大众样本包围。
优缺点:
NearMiss-1考虑的是与最近的K个小众样本的平均距离,是局部的,易受离群点的影响;NearMiss-2考虑的是与最远的K个小众样本的平均距离,是全局的。而NearMiss-3方法则会使得每一个小众样本附近都有足够多的大众样本,显然这会使得模型的精确度高、召回率低。有论文中证明了在某些数据下NearMiss-2方法的效果最好。但三种方法的计算量普遍都很大。
实现方法:
Python:imblearn.under_sampling-NearMiss(version可用于设置具体方法)
参考资料:
Haibo He, Member, IEEE, and Edwardo A. Garcia. Learning from Imbalanced Data
https://www.jianshu.com/p/e83a3ce2c837
https://www.cnblogs.com/kamekin/p/9824294.html
http://www.sohu.com/a/83919557_415148
(5)Tomek links方法
假设样本点x_i和x_j属于不同的类别,d( x_i 〖,x〗_j )表示两个样本点之间的距离。如果不存在第三个样本点x_l使得 d( x_l 〖,x〗_i )< d( x_i 〖,x〗_j )或者 d( x_l 〖,x〗_j )< d( x_i 〖,x〗_j )成立,则称( x_i 〖,x〗_j )为一个Tomek link对。

如果两个样本称为Tomek links,说明其中一个是噪声或者两个都是接近边界。
因此,Tomek link对一般有两种用途:
欠采样:将Tomek link对中属于多数类的样本剔除。
数据清洗:将Tomek link对中的两个样本都剔除。
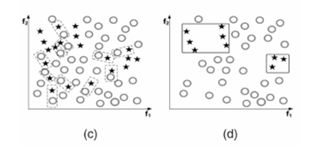
优缺点:
可以减少不同类别之间的样本重叠,但当作为欠采样时,无法控制欠采样的数量,能剔除的大众样本比较有限,故最好作为数据清洗的方法,结合其他方法使用。
实现方法:
Python:imblearn.under_sampling-TomekLinks(ratio='auto’为移除多数类的样本, 当ratio='all’时, 两个样本均被移除。)
参考资料:
https://blog.csdn.net/qq_31813549/article/details/79964973#3221-tomeks-links
https://www.cnblogs.com/massquantity/p/9382710.html
https://blog.csdn.net/mmc2015/article/details/51721282
(6)ENN方法
对于属于大众样本集的一个样本,如果其K个近邻点有超过一半都不属于大众样本,则这个样本会被剔除。这个方法的另一个变种是所有的K个近邻点都不属于大众样本,则这个样本会被剔除。

优缺点:
可以减少不同类别之间的样本重叠,但能剔除的大众样本比较有限,故最好作为数据清洗的方法,结合其他方法使用。
实现方法:
Python:imblearn.under_sampling- EditedNearestNeighbours、RepeatedEditedNearestNeighbours(kind_sel='mode’时去除K近邻超过一半都不属于大众样本的点,kind_sel='all’时去除全部K近邻样本都不属于大众样本的点);RepeatedEditedNearestNeighbours函数可以不断的重复删除过程,直到无法再删除为止。
参考资料:
https://blog.csdn.net/qq_31813549/article/details/79964973#3221-tomeks-links
3. 综合采样
目前为止我们使用的重采样方法几乎都是只针对某一类样本:对大众样本欠采样,对小众样本过采样。也经常有人将欠采样和过采样综合起来,解决样本类别分布不平衡和过拟合问题,如:SMOTE + Tomek links或SMOTE + ENN。即利用SMOTE方法生成新的小众样本,得到扩充后的数据集T,再用Tomek links方法剔除T中的Tomek links对,或利用ENN算法剔除T中超过一半近邻点都不属于大众样本的样本点。
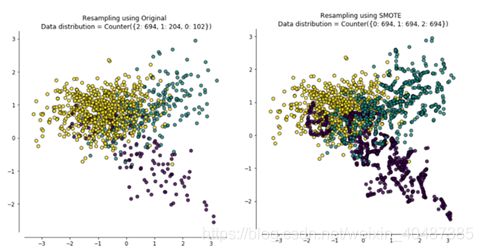
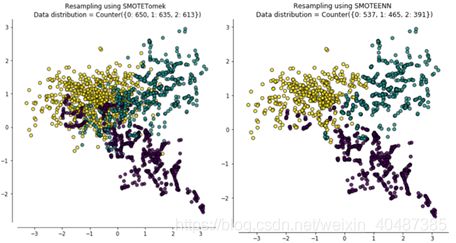
优缺点:
增加了小众样本的数量,且减少了不同类别之间的样本重叠。
参考资料:
https://www.cnblogs.com/massquantity/p/9382710.html