stable-baselines3学习之自定义策略网络(Custom Policy Network)
stable-baselines3学习之自定义策略网络(Custom Policy Network)
stable-baselines3为图像 (CnnPolicies)、其他类型的输入特征 (MlpPolicies) 和多个不同的输入 (MultiInputPolicies) 提供policy networks。
1.SB3 policy
SB3网络分为两个主要部分:
- 一个特征提取器(通常在适用时在actor和critic之间共享),作用是从高维observation中提取特征转换为特征向量,例如用CNN从图像中提取特征。使用
features_extractor_class参数,通过传递features_extractor_kwargs参数可以改变特征提取器的默认参数。 - 一个全连接网络,映射特征到action或者value,它的网络结构由
net_arch参数控制。
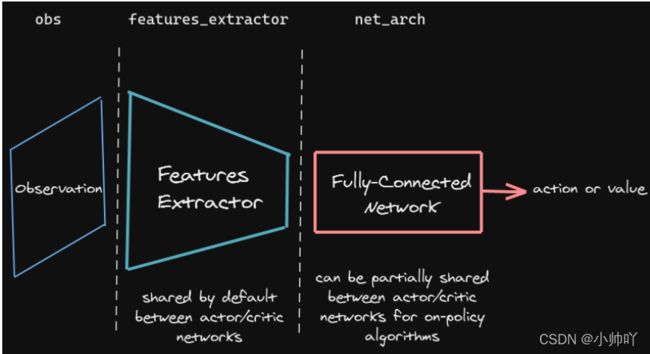
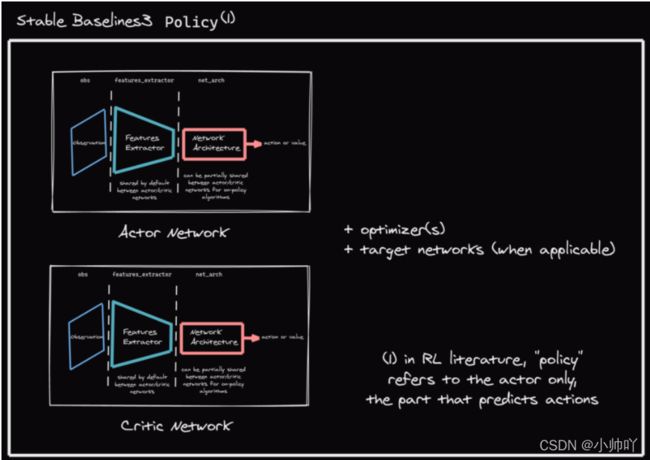
SB3 policies通常由多个网络(actor/critic+target network(适用时))和optimizers组成,这些网络都有一个feature extractor和一个fully-connected network。
注:在SB3中的提到的policy并不是指RL中actor对应的那个policy,而是所有训练中用到的网络的类。
2.自定义网络结构
自定义策略网络架构的一种方法是在创建模型时使用policy_kwargs传递参数:
import gym
import torch as th
from stable_baselines3 import PPO
# Custom actor (pi) and value function (vf) networks
# of two layers of size 32 each with Relu activation function
policy_kwargs = dict(activation_fn=th.nn.ReLU,
net_arch=[dict(pi=[32, 32], vf=[32, 32])])
# Create the agent
model = PPO("MlpPolicy", "CartPole-v1", policy_kwargs=policy_kwargs, verbose=1)
# Retrieve the environment
env = model.get_env()
# Train the agent
model.learn(total_timesteps=100000)
# Save the agent
model.save("ppo_cartpole")
del model
# the policy_kwargs are automatically loaded
model = PPO.load("ppo_cartpole", env=env)
3.自定义特征提取器
如果你想有一个自定义的特征提取器(例如使用图像时自定义 CNN),你可以定义派生自BaseFeaturesExtractor的类,然后在训练时将其传递给模型。
注:默认情况下,特征提取器在actor和critic之间共享以节省计算(如果适用)。但是,在on-policy 算法定义自定义policy时或者在policy_kwargs中设置share_features_extractor=False的off-policy 算法时不共享。
import gym
import torch as th
import torch.nn as nn
from stable_baselines3 import PPO
from stable_baselines3.common.torch_layers import BaseFeaturesExtractor
class CustomCNN(BaseFeaturesExtractor):
"""
:param observation_space: (gym.Space)
:param features_dim: (int) Number of features extracted.
This corresponds to the number of unit for the last layer.
"""
def __init__(self, observation_space: gym.spaces.Box, features_dim: int = 256):
super(CustomCNN, self).__init__(observation_space, features_dim)
# We assume CxHxW images (channels first)
# Re-ordering will be done by pre-preprocessing or wrapper
n_input_channels = observation_space.shape[0]
self.cnn = nn.Sequential(
nn.Conv2d(n_input_channels, 32, kernel_size=8, stride=4, padding=0),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=0),
nn.ReLU(),
nn.Flatten(),
)
# Compute shape by doing one forward pass
with th.no_grad():
n_flatten = self.cnn(
th.as_tensor(observation_space.sample()[None]).float()
).shape[1]
self.linear = nn.Sequential(nn.Linear(n_flatten, features_dim), nn.ReLU())
def forward(self, observations: th.Tensor) -> th.Tensor:
return self.linear(self.cnn(observations))
policy_kwargs = dict(
features_extractor_class=CustomCNN,
features_extractor_kwargs=dict(features_dim=128),
)
model = PPO("CnnPolicy", "BreakoutNoFrameskip-v4", policy_kwargs=policy_kwargs, verbose=1)
model.learn(1000)
4.多个输入和字典类型观察
Stable Baselines3 支持处理多个输入使用DictGym 空间。这可以使用MultiInputPolicy来完成 ,默认情况下使用CombinedExtractor特征提取器将多个输入转换为单个向量,由net_arch网络处理。
默认情况下,CombinedExtractor按如下方式处理多个输入:
- 如果输入是图像(自动检测,请参阅
common.preprocessing.is_image_space),则使用 Nature Atari CNN 网络处理图像并输出大小为 的潜在向量256。 - 如果输入不是图像,则将其展平(无图层)。
- 将所有先前的向量连接成一个长向量并将其传递给策略。
与上面非常相似,您可以定义自定义特征提取器。以下示例假设环境在观察空间字典中有两个键:“image”是 (1,H,W) 图像(通道优先),“vector”是 (D,) 维向量。我们使用简单的下采样处理“图像”,使用单个线性层处理“矢量”。
import gym
import torch as th
from torch import nn
from stable_baselines3.common.torch_layers import BaseFeaturesExtractor
class CustomCombinedExtractor(BaseFeaturesExtractor):
def __init__(self, observation_space: gym.spaces.Dict):
# We do not know features-dim here before going over all the items,
# so put something dummy for now. PyTorch requires calling
# nn.Module.__init__ before adding modules
super(CustomCombinedExtractor, self).__init__(observation_space, features_dim=1)
extractors = {}
total_concat_size = 0
# We need to know size of the output of this extractor,
# so go over all the spaces and compute output feature sizes
for key, subspace in observation_space.spaces.items():
if key == "image":
# We will just downsample one channel of the image by 4x4 and flatten.
# Assume the image is single-channel (subspace.shape[0] == 0)
extractors[key] = nn.Sequential(nn.MaxPool2d(4), nn.Flatten())
total_concat_size += subspace.shape[1] // 4 * subspace.shape[2] // 4
elif key == "vector":
# Run through a simple MLP
extractors[key] = nn.Linear(subspace.shape[0], 16)
total_concat_size += 16
self.extractors = nn.ModuleDict(extractors)
# Update the features dim manually
self._features_dim = total_concat_size
def forward(self, observations) -> th.Tensor:
encoded_tensor_list = []
# self.extractors contain nn.Modules that do all the processing.
for key, extractor in self.extractors.items():
encoded_tensor_list.append(extractor(observations[key]))
# Return a (B, self._features_dim) PyTorch tensor, where B is batch dimension.
return th.cat(encoded_tensor_list, dim=1)
5.On-Policy Algorithms
Shared Networks
A2C and PPO policies的 net_arch 参数允许特定数量和大小的隐藏层并且有些是共享的在policy network和value network。它假定有下面结构的列表:
-
任意大小(允许为零)的整数个数,每个整数指定共享层中的单元数。如果整数的数量为零,则不会有共享层。
-
一个可选的字典,用于为价值网络和策略网络指定以下非共享层。它的格式类似于
dict(vf=[. 如果它缺少任何键(pi 或 vf),则假定没有非共享层(空列表)。], pi=[ ])
简而言之格式如下: [.
举例:
(1)两个大小为128的共享层:net_arch=[128, 128]

(2)比策略网络更深的价值网络,第一层共享:net_arch=[128, dict(vf=[256, 256])]

(3)先共享然后发散:[128, dict(vf=[256], pi=[16])]

更高级的示例
如果您的任务需要对actor/value架构进行更精细的控制,您可以直接重新定义策略:
from typing import Callable, Dict, List, Optional, Tuple, Type, Union
import gym
import torch as th
from torch import nn
from stable_baselines3 import PPO
from stable_baselines3.common.policies import ActorCriticPolicy
class CustomNetwork(nn.Module):
"""
Custom network for policy and value function.
It receives as input the features extracted by the feature extractor.
:param feature_dim: dimension of the features extracted with the features_extractor (e.g. features from a CNN)
:param last_layer_dim_pi: (int) number of units for the last layer of the policy network
:param last_layer_dim_vf: (int) number of units for the last layer of the value network
"""
def __init__(
self,
feature_dim: int,
last_layer_dim_pi: int = 64,
last_layer_dim_vf: int = 64,
):
super(CustomNetwork, self).__init__()
# IMPORTANT:
# Save output dimensions, used to create the distributions
self.latent_dim_pi = last_layer_dim_pi
self.latent_dim_vf = last_layer_dim_vf
# Policy network
self.policy_net = nn.Sequential(
nn.Linear(feature_dim, last_layer_dim_pi), nn.ReLU()
)
# Value network
self.value_net = nn.Sequential(
nn.Linear(feature_dim, last_layer_dim_vf), nn.ReLU()
)
def forward(self, features: th.Tensor) -> Tuple[th.Tensor, th.Tensor]:
"""
:return: (th.Tensor, th.Tensor) latent_policy, latent_value of the specified network.
If all layers are shared, then ``latent_policy == latent_value``
"""
return self.policy_net(features), self.value_net(features)
def forward_actor(self, features: th.Tensor) -> th.Tensor:
return self.policy_net(features)
def forward_critic(self, features: th.Tensor) -> th.Tensor:
return self.value_net(features)
class CustomActorCriticPolicy(ActorCriticPolicy):
def __init__(
self,
observation_space: gym.spaces.Space,
action_space: gym.spaces.Space,
lr_schedule: Callable[[float], float],
net_arch: Optional[List[Union[int, Dict[str, List[int]]]]] = None,
activation_fn: Type[nn.Module] = nn.Tanh,
*args,
**kwargs,
):
super(CustomActorCriticPolicy, self).__init__(
observation_space,
action_space,
lr_schedule,
net_arch,
activation_fn,
# Pass remaining arguments to base class
*args,
**kwargs,
)
# Disable orthogonal initialization
self.ortho_init = False
def _build_mlp_extractor(self) -> None:
self.mlp_extractor = CustomNetwork(self.features_dim)
model = PPO(CustomActorCriticPolicy, "CartPole-v1", verbose=1)
model.learn(5000)
6.Off-Policy Algorithms
如果你需要一个网络架构他相比于SAC,DDPG或者TD3有不同actor/critic结构,可以用以下结构的字典结构dict(qf=[
比如你想要一个不同架构的actor(pi)和critic(qf)网络,你可以net_arch=dict(qf=[400, 300], pi=[64, 64]).
或者你的actor和critic共享相同的网络结构,你可以net_arch=[256, 256](两个隐藏层每个有256个单元)
from stable_baselines3 import SAC
# Custom actor architecture with two layers of 64 units each
# Custom critic architecture with two layers of 400 and 300 units
policy_kwargs = dict(net_arch=dict(pi=[64, 64], qf=[400, 300]))
# Create the agent
model = SAC("MlpPolicy", "Pendulum-v1", policy_kwargs=policy_kwargs, verbose=1)
model.learn(5000)
注:相比于 on-policy counterparts, 除了特征提取以外不允许有共享网络层 (防止 target networks 出现问题).