迁移学习Transfer Learning
pytorch学习(十二)—迁移学习Transfer Learning

侠之大者_7d3f关注
0.6992019.01.02 10:28:59字数 1,001阅读 5,532
前言
在训练深度学习模型时,有时候我们没有海量的训练样本,只有少数的训练样本(比如几百个图片),几百个训练样本显然对于深度学习远远不够。这时候,我们可以使用别人预训练好的网络模型权重,在此基础上进行训练,这就引入了一个概念——迁移学习(Transfer Learning)。
迁移学习
What(什么是迁移学习)
迁移学习(Transfer Learning,TL)对于人类来说,就是掌握举一反三的学习能力。比如我们学会骑自行车后,学骑摩托车就很简单了;在学会打羽毛球之后,再学打网球也就没那么难了。对于计算机而言,所谓迁移学习,就是能让现有的模型算法稍加调整即可应用于一个新的领域和功能的一项技术
How(如何进行迁移学习)
-
首先需要选择一个预训练好的模型,需要注意的是该模型的训练过程最好与我们要进行训练的任务相似。比如我们要训练一个Cat,dog图像分类的模型,最好应该选择一个图像分类的预训练模型。
-
针对实际任务,对网络结构进行调整。比如找到了一个预训练好的AlexNet(1000类别), 但是我们实际的任务的2分类,因此需要把最后一层的全连接输出改为2.
Why(为何要使用迁移学习)
https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html
In practice, very few people train an entire Convolutional Network from scratch (with random initialization), because it is relatively rare to have a dataset of sufficient size. Instead, it is common to pretrain a ConvNet on a very large dataset (e.g. ImageNet, which contains 1.2 million images with 1000 categories), and then use the ConvNet either as an initialization or a fixed feature extractor for the task of interest.
目的
- 了解ResNet
- 基于预训练好的ResNet-18, 进行一个图像二分类迁移学习
开发/测试环境
- Ubuntu 18.04
- pycharm
- Anaconda3, python3.6
- pytorch1.0, torchvision
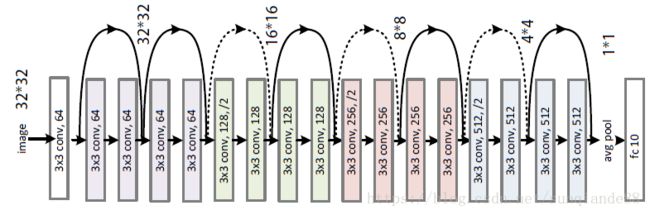
ResNet-18
image.png
实验内容
准备数据集
- 训练集合
- 验证集合
数据集下载链接
下载好之后,复制到工程 /data/ 路径下

image.png
训练集合,验证集合

image.png
训练集,验证集 分别包含2个子文件夹,这是一个2分类问题。分类对象:蚂蚁,蜜蜂
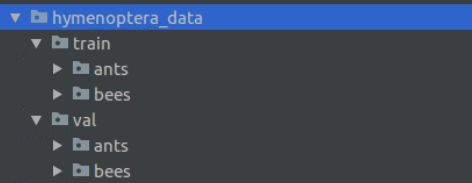
image.png
- 代码
因为训练一个2分类的模型,数据集加载直接使用pytorch提供的API——ImageFolder最方便。原始图像为jpg格式,在制作数据集时候进行了变换transforms。 加入对GPU的支持,首先判断torch.cuda.is_available(),然后决定使用GPU or CPU
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.utils.data import DataLoader
import torchvision
from torchvision.transforms import transforms
from torchvision import models
from torchvision.models import ResNet
import numpy as np
import matplotlib.pyplot as plt
import os
import utils
data_dir = './data/hymenoptera_data'
train_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'train'),
transform=transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
]))
val_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'val'),
transform=transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
]))
train_dataloader = DataLoader(dataset=train_dataset, batch_size=4, shuffle=4)
val_dataloader = DataLoader(dataset=val_dataset, batch_size=4, shuffle=4)
# 类别名称
class_names = train_dataset.classes
print('class_names:{}'.format(class_names))
# 训练设备 CPU/GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('trian_device:{}'.format(device.type))
# 随机显示一个batch
plt.figure()
utils.imshow(next(iter(train_dataloader)))
plt.show()
获取预训练模型
torchvision.models
torchvision中包含了一些常见的预训练模型:
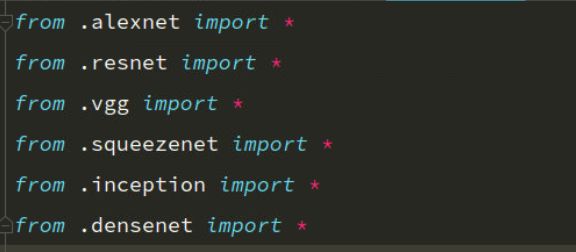
image.png
AlexNet, VGG, SqueezeNet, Resnet,Inception, DenseNet
此次实验采用ResNet18网络模型。
在torchvision.models中包含resnet18,首先会实例化一个ResNet网络, 然后model.load_dict()加载预训练好的模型。
def resnet18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
torchvision 默认将模型保存在/home/.torch/models路径。
image.png
预训练模型文件:
image.png
- 代码
加载预训练模型。需要注意的地方:修改ResNet最后一个全连接层的输出个数,二分类问题需要将输出个数改为2。
# -------------------------模型选择,优化方法, 学习率策略----------------------
model = models.resnet18(pretrained=True)
# 全连接层的输入通道in_channels个数
num_fc_in = model.fc.in_features
# 改变全连接层,2分类问题,out_features = 2
model.fc = nn.Linear(num_fc_in, 2)
# 模型迁移到CPU/GPU
model = model.to(device)
# 定义损失函数
loss_fc = nn.CrossEntropyLoss()
# 选择优化方法
optimizer = optim.SGD(model.parameters(), lr=0.0001, momentum=0.9)
# 学习率调整策略
# 每7个epoch调整一次
exp_lr_scheduler = lr_scheduler.StepLR(optimizer=optimizer, step_size=10, gamma=0.5) # step_size
训练,测试网络
Epoch: 训练50个epoch
注意地方: 训练时候,需要调用model.train()将模型设置为训练模式。测试时候,调用model.eval() 将模型设置为测试模型,否则训练和测试结果不正确。
# ----------------训练过程-----------------
num_epochs = 50
for epoch in range(num_epochs):
running_loss = 0.0
exp_lr_scheduler.step()
for i, sample_batch in enumerate(train_dataloader):
inputs = sample_batch[0]
labels = sample_batch[1]
model.train()
# GPU/CPU
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
# foward
outputs = model(inputs)
# loss
loss = loss_fc(outputs, labels)
# loss求导,反向
loss.backward()
# 优化
optimizer.step()
#
running_loss += loss.item()
# 測試
if i % 20 == 19:
correct = 0
total = 0
model.eval()
for images_test, labels_test in val_dataloader:
images_test = images_test.to(device)
labels_test = labels_test.to(device)
outputs_test = model(images_test)
_, prediction = torch.max(outputs_test, 1)
correct += (torch.sum((prediction == labels_test))).item()
# print(prediction, labels_test, correct)
total += labels_test.size(0)
print('[{}, {}] running_loss = {:.5f} accurcay = {:.5f}'.format(epoch + 1, i + 1, running_loss / 20,
correct / total))
running_loss = 0.0
# if i % 10 == 9:
# print('[{}, {}] loss={:.5f}'.format(epoch+1, i+1, running_loss / 10))
# running_loss = 0.0
print('training finish !')
torch.save(model.state_dict(), './model/model_2.pth')
训练输出结果
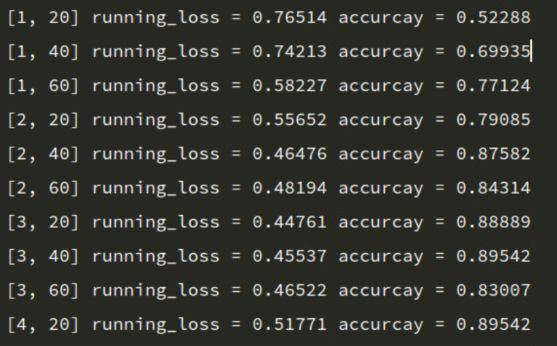
image.png
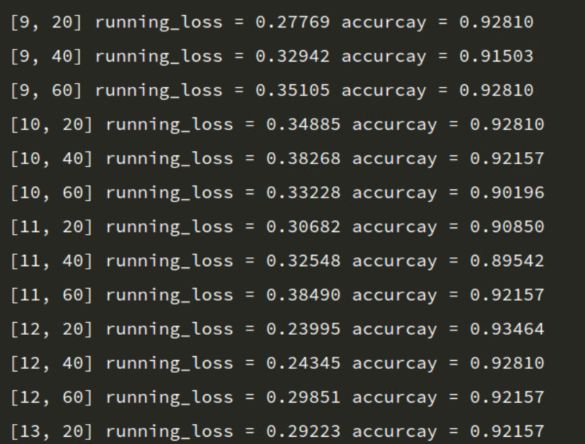
image.png
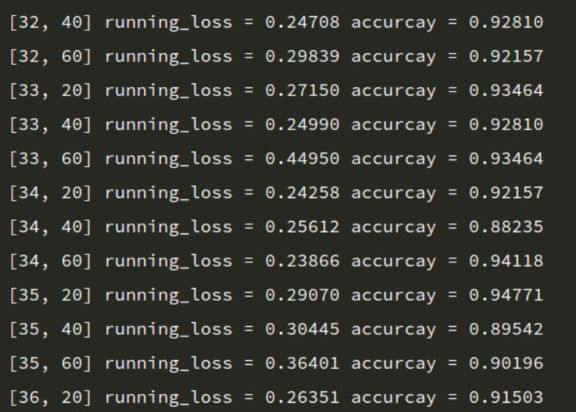
image.png
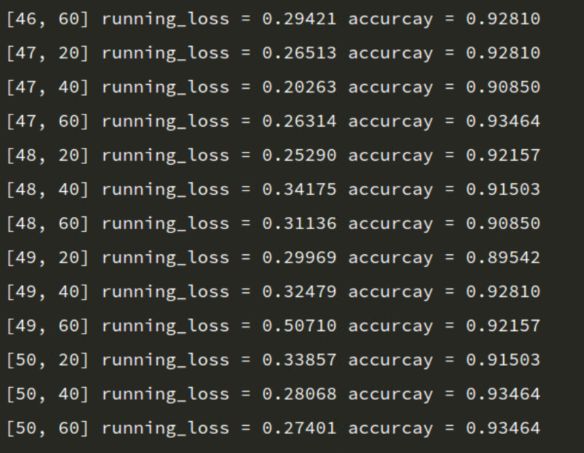
image.png
随着训练次数增加,accuracy基本上是上升趋势,最终达到93%的准确率。

image.png

image.png

image.png
完整代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.utils.data import DataLoader
import torchvision
from torchvision.transforms import transforms
from torchvision import models
from torchvision.models import ResNet
import numpy as np
import matplotlib.pyplot as plt
import os
import utils
data_dir = './data/hymenoptera_data'
train_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'train'),
transform=transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
]))
val_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'val'),
transform=transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
]))
train_dataloader = DataLoader(dataset=train_dataset, batch_size=4, shuffle=4)
val_dataloader = DataLoader(dataset=val_dataset, batch_size=4, shuffle=4)
# 类别名称
class_names = train_dataset.classes
print('class_names:{}'.format(class_names))
# 训练设备 CPU/GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('trian_device:{}'.format(device.type))
# 随机显示一个batch
#plt.figure()
#utils.imshow(next(iter(train_dataloader)))
#plt.show()
# -------------------------模型选择,优化方法, 学习率策略----------------------
model = models.resnet18(pretrained=True)
# 全连接层的输入通道in_channels个数
num_fc_in = model.fc.in_features
# 改变全连接层,2分类问题,out_features = 2
model.fc = nn.Linear(num_fc_in, 2)
# 模型迁移到CPU/GPU
model = model.to(device)
# 定义损失函数
loss_fc = nn.CrossEntropyLoss()
# 选择优化方法
optimizer = optim.SGD(model.parameters(), lr=0.0001, momentum=0.9)
# 学习率调整策略
# 每7个epoch调整一次
exp_lr_scheduler = lr_scheduler.StepLR(optimizer=optimizer, step_size=10, gamma=0.5) # step_size
# ----------------训练过程-----------------
num_epochs = 50
for epoch in range(num_epochs):
running_loss = 0.0
exp_lr_scheduler.step()
for i, sample_batch in enumerate(train_dataloader):
inputs = sample_batch[0]
labels = sample_batch[1]
model.train()
# GPU/CPU
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
# foward
outputs = model(inputs)
# loss
loss = loss_fc(outputs, labels)
# loss求导,反向
loss.backward()
# 优化
optimizer.step()
#
running_loss += loss.item()
# 測試
if i % 20 == 19:
correct = 0
total = 0
model.eval()
for images_test, labels_test in val_dataloader:
images_test = images_test.to(device)
labels_test = labels_test.to(device)
outputs_test = model(images_test)
_, prediction = torch.max(outputs_test, 1)
correct += (torch.sum((prediction == labels_test))).item()
# print(prediction, labels_test, correct)
total += labels_test.size(0)
print('[{}, {}] running_loss = {:.5f} accurcay = {:.5f}'.format(epoch + 1, i + 1, running_loss / 20,
correct / total))
running_loss = 0.0
# if i % 10 == 9:
# print('[{}, {}] loss={:.5f}'.format(epoch+1, i+1, running_loss / 10))
# running_loss = 0.0
print('training finish !')
torch.save(model.state_dict(), './model/model_2.pth')
End
参考:
https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html
https://blog.csdn.net/sunqiande88/article/details/80100891
11人点赞
日记本
"感谢您对我的支持与肯定"
赞赏支持还没有人赞赏,支持一下
侠之大者_7d3f热爱钻研,喜欢软硬件设计与开发,计算机视觉,嵌入式DSP/ARM爱好者。
总资产30 (约2.81元)共写了3.4W字获得406个赞共310个粉丝
关注
全部评论15只看作者
按时间倒序
按时间正序

momo_f474
7楼 07.20 16:55
您好,感谢分享!有几个问题请教。1.请问迁移前后的输入数据的维度,比如通道数,或者图片大小,是否必须相同呢?2.网络结构的特征层的结构一般不能改变,是吗?再次感谢~
赞 回复
侠之大者_7d3f作者
07.20 18:17
1.是的,迁移学习前后输入数据维度必须相同。 2.迁移学习一般任务特征提取层范化能力强,因此特征提取层结构不变,只需要网络后面的fc层以适应特定的任务
回复
momo_f474
07.20 22:04
@侠之大者_7d3f 好的。非常感谢~
回复
添加新评论

皮克厂长
6楼 05.26 09:44
请问这个测试的代码 为什么在训练模型的循环里,如果要测试的话必须要接着循环一次嘛
赞 回复
侠之大者_7d3f作者
06.01 12:37
测试代码可以不在训练的循环里面,本文的代码中,是为了验证训练过程每迭代一定的次数模型的准确度,因此把测试代码写在训练的循环里面
回复
添加新评论

贝叶斯学者
5楼 04.17 10:14
不需要冻结网络层吗?
赞 回复
侠之大者_7d3f作者
04.17 11:06
看需求,如果打算只重新更新fc层参数则选择冻结feature层参数。
回复
添加新评论

Ccc_zzz
4楼 02.13 13:48
您好,请教一下测试第一行if i % 20 == 19: 代表什么意思?这个20 19 是不是根据测试集大小需要调整?
赞 回复
侠之大者_7d3f作者
02.13 16:41
@Ccc_zzz 每迭代20次打印输出当前的信息
回复
Ccc_zzz
02.13 16:48
@侠之大者_7d3f 明白了,谢谢!
回复
添加新评论

3156d6025202
3楼 01.02 16:11
model.train() :启用BatchNormalization和Dropout
model.eval() :不启用BatchNormalization和Dropout
赞 回复
侠之大者_7d3f作者
04.17 11:10
train和eval用于控制bn dropout的行为。因为bn,dropout层比较特殊,2者在training和inference阶段的计算方法不同。例如bn,training阶段需要计算running-mean和running-var,但是在inference阶段不需要计算这2个参数,这2个参数来自训练阶段整个数据集的mean var。
回复
添加新评论
3156d6025202
2楼 2019.12.30 16:43
没有utils这个模块是怎么回事?
赞 回复
侠之大者_7d3f作者
2019.12.30 18:21
@3156d6025202 这个utils模块是自定义的python脚本,提供一些工具
回复
3156d6025202
01.02 16:12
@侠之大者_7d3f 好吧,自己写的吗?
回复
添加新评论