机器学习笔记之受限玻尔兹曼机(五)基于含隐变量能量模型的对数似然梯度
机器学习笔记之受限玻尔兹曼机——基于含隐变量能量模型的对数似然梯度
- 引言
-
- 回顾:
-
- 包含配分函数的概率分布
- 受限玻尔兹曼机——场景构建
- 对比散度
- 基于含隐变量能量模型的对数似然梯度
引言
上一节介绍了对比散度(Constractive Divergence)思想,本节将介绍基于含隐变量能量模型的对数似然梯度。
回顾:
包含配分函数的概率分布
在一些基于概率图模型,特别是马尔可夫随机场(无向图) 的基础上,对概率模型分布进行假设:
-
以马尔可夫随机场(Markov Random Field,MRF)为例,已知随机变量集合 X = { x 1 , x 2 , ⋯ , x p } \mathcal X = \{x_1,x_2,\cdots,x_p\} X={x1,x2,⋯,xp},它的概率分布 P ( X ) \mathcal P(\mathcal X) P(X)表示如下:
P ( X ) = 1 Z ∑ i = 1 K ψ i ( x C i ) \mathcal P(\mathcal X) = \frac{1}{\mathcal Z} \sum_{i=1}^{\mathcal K} \psi_i(x_{\mathcal C_i}) P(X)=Z1i=1∑Kψi(xCi)
其中 ψ i ( x C i ) \psi_i(x_{\mathcal C_i}) ψi(xCi)是描述极大团 C i \mathcal C_i Ci内随机变量之间关系信息的势函数(Potential Function);而 Z \mathcal Z Z表示配分函数(Partition Function)。实际上, ψ i ( x C i ) \psi_i(x_{\mathcal C_i}) ψi(xCi)才是真正描述随机变量关系信息的函数,但它并不是概率分布,需要使用配分函数进行归一化处理,才能得到真正的概率结果。
-
而受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)在马尔可夫随机场的基础上,针对玻尔兹曼机概率图结构复杂的问题,对结点间的边进行约束。具体约束要求是:观测变量 v v v,隐变量 h h h的随机变量集合内部无连接,只有 h h h和 v v v之间存在连接:
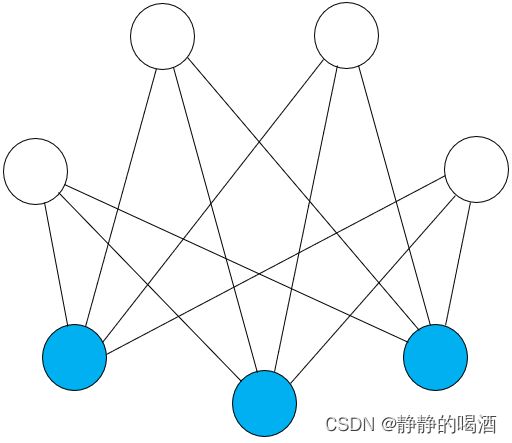
受限玻尔兹曼机——场景构建
基于上图,蓝色结点表示观测变量集合 v v v,白色结点表示隐变量集合 h h h。为后续计算表达方便,使用向量形式进行表示:
h = ( h 1 , h 2 , ⋯ , h m ) m × 1 T v = ( v 1 , v 2 , ⋯ , v n ) n × 1 T h = (h_1,h_2,\cdots,h_m)_{m \times 1}^T \\ v = (v_1,v_2,\cdots,v_n)_{n \times 1}^T h=(h1,h2,⋯,hm)m×1Tv=(v1,v2,⋯,vn)n×1T
受限玻尔兹曼机关于随机变量集合 X \mathcal X X可表示为如下形式:
P ( X ) = P ( h , v ) = 1 Z exp { − E [ h , v ] } = 1 Z exp [ v T W h + b T v + c T h ] = 1 Z exp { ∑ j = 1 m ∑ i = 1 n v i ⋅ w i j ⋅ h j + ∑ i = 1 n b i v i + ∑ j = 1 m c j h j } s . t . Z = ∑ h , v exp { − E [ h , v ] } \begin{aligned} & \mathcal P(\mathcal X) = \mathcal P(h,v) \\ & = \frac{1}{\mathcal Z} \exp \{- \mathbb E[h,v]\} \\ & = \frac{1}{\mathcal Z} \exp \left[v^T\mathcal W h + b^T v + c^Th\right] \\ & = \frac{1}{\mathcal Z} \exp \left\{\sum_{j=1}^m \sum_{i=1}^n v_i \cdot w_{ij} \cdot h_j + \sum_{i=1}^n b_iv_i + \sum_{j=1}^m c_j h_j\right\} \\ & s.t.\quad \mathcal Z = \sum_{h,v} \exp \{- \mathbb E[h,v]\} \end{aligned} P(X)=P(h,v)=Z1exp{−E[h,v]}=Z1exp[vTWh+bTv+cTh]=Z1exp{j=1∑mi=1∑nvi⋅wij⋅hj+i=1∑nbivi+j=1∑mcjhj}s.t.Z=h,v∑exp{−E[h,v]}
其中模型参数包含如下三个部分:
W = ( w 11 , w 12 , ⋯ , w 1 n w 21 , w 22 , ⋯ , w 2 n ⋮ w m 1 , w m 2 , ⋯ , w m n ) m × n b = ( b 1 b 2 ⋮ b n ) n × 1 c = ( c 1 c 2 ⋮ c m ) m × 1 \mathcal W = \begin{pmatrix} w_{11},w_{12},\cdots,w_{1n} \\ w_{21},w_{22},\cdots,w_{2n} \\ \vdots \\ w_{m1},w_{m2},\cdots,w_{mn} \end{pmatrix}_{m \times n} \quad b = \begin{pmatrix} b_1 \\ b_2 \\ \vdots \\ b_n \end{pmatrix}_{n \times 1} \quad c = \begin{pmatrix} c_1\\c_2\\ \vdots \\ c_m \end{pmatrix}_{m \times 1} W=⎝⎜⎜⎜⎛w11,w12,⋯,w1nw21,w22,⋯,w2n⋮wm1,wm2,⋯,wmn⎠⎟⎟⎟⎞m×nb=⎝⎜⎜⎜⎛b1b2⋮bn⎠⎟⎟⎟⎞n×1c=⎝⎜⎜⎜⎛c1c2⋮cm⎠⎟⎟⎟⎞m×1
对比散度
在求解包含配分函数概率分布的模型参数过程中,以极大似然估计为例,使用梯度上升法,将最优模型参数 θ ^ \hat \theta θ^表述为如下形式:
这里借助蒙特卡洛方法的逆向表述:将样本集合X = { x ( i ) } i = 1 N \mathcal X = \{x^{(i)}\}_{i=1}^N X={x(i)}i=1N看作是从‘真实分布’P d a t a \mathcal P_{data} Pdata中采集到的样本,在此基础上,将均值结果近似表示为期望形式。
1 N ∑ i = 1 N ∇ θ log P ^ ( x ( i ) ; θ ) ≈ E P d a t a [ ∇ θ log P ^ ( X ; θ ) ] \frac{1}{N}\sum_{i=1}^N \nabla_{\theta} \log \hat \mathcal P(x^{(i)};\theta) \approx\mathbb E_{\mathcal P_{data}} [\nabla_{\theta} \log \hat \mathcal P(\mathcal X;\theta)] N1i=1∑N∇θlogP^(x(i);θ)≈EPdata[∇θlogP^(X;θ)]关于∇ θ log Z ( θ ) \nabla_{\theta} \log \mathcal Z(\theta) ∇θlogZ(θ)的推导过程详见配分函数——对数似然梯度
∇ θ log Z ( θ ) = E P m o d e l [ ∇ θ log P ^ ( X ; θ ) ] \nabla_{\theta} \log \mathcal Z(\theta) = \mathbb E_{\mathcal P_{model}} \left[\nabla_{\theta} \log \hat \mathcal P(\mathcal X;\theta)\right] ∇θlogZ(θ)=EPmodel[∇θlogP^(X;θ)]
最终结果可表示为:
θ ( t + 1 ) ⇐ θ ( t ) + η ∇ θ L ( θ ) ∇ θ L ( θ ) = 1 N ∑ i = 1 N [ ∇ θ log P ^ ( x ( i ) ; θ ) ] − ∇ θ log Z ( θ ) = E P d a t a [ ∇ θ log P ^ ( X ; θ ) ] − E P m o d e l [ ∇ θ log P ^ ( X ; θ ) ] \theta^{(t+1)} \Leftarrow \theta^{(t)} + \eta \nabla_{\theta} \mathcal L(\theta) \\ \begin{aligned} \nabla_{\theta}\mathcal L(\theta) & = \frac{1}{N} \sum_{i=1}^N \left[\nabla_{\theta} \log \hat \mathcal P(x^{(i)};\theta)\right] - \nabla_{\theta} \log \mathcal Z(\theta) \\ & = \mathbb E_{\mathcal P_{data}} \left[\nabla_{\theta} \log \hat \mathcal P(\mathcal X;\theta)\right] - \mathbb E_{\mathcal P_{model}} \left[\nabla_{\theta} \log \hat \mathcal P(\mathcal X;\theta)\right] \end{aligned} θ(t+1)⇐θ(t)+η∇θL(θ)∇θL(θ)=N1i=1∑N[∇θlogP^(x(i);θ)]−∇θlogZ(θ)=EPdata[∇θlogP^(X;θ)]−EPmodel[∇θlogP^(X;θ)]
在对数似然梯度一节中简单提到过,受限玻尔兹曼机是一个典型的正相易求解,负相难求解的模型。通常对负相使用对比散度思想进行求解:
其中 P 0 , P ∞ \mathcal P_0,\mathcal P_{\infty} P0,P∞分别表示 P d a t a , P m o d e l \mathcal P_{data},\mathcal P_{model} Pdata,Pmodel;而 P k \mathcal P_k Pk表示第 k k k次迭代步骤的吉布斯采样产生的分布,可以将其理解为 P 0 , P ∞ \mathcal P_0,\mathcal P_{\infty} P0,P∞之间某一迭代步骤的‘过渡’。
θ ^ = arg min θ { K L [ P d a t a ( X ) ∣ ∣ P m o d e l ( X ; θ ) ] } ⇓ θ ^ = arg min θ [ K L ( P 0 ∣ ∣ P ∞ ) − K L ( P k ∣ ∣ P ∞ ) ] \begin{aligned} \hat \theta = \mathop{\arg\min}\limits_{\theta} & \{\mathcal K\mathcal L [\mathcal P_{data} (\mathcal X)\text{ } || \text{ }\mathcal P_{model}(\mathcal X;\theta)]\} \\ & \Downarrow \\ \hat \theta = \mathop{\arg\min}\limits_{\theta} & \left[\mathcal K\mathcal L(\mathcal P_0 \text{ } || \text{ }\mathcal P_{\infty}) - \mathcal K\mathcal L(\mathcal P_k \text{ } || \text{ } \mathcal P_{\infty})\right] \\ \end{aligned} θ^=θargminθ^=θargmin{KL[Pdata(X) ∣∣ Pmodel(X;θ)]}⇓[KL(P0 ∣∣ P∞)−KL(Pk ∣∣ P∞)]
基于含隐变量能量模型的对数似然梯度
回顾受限玻尔兹曼机的模型表示(Representation),它明显是一个无向图模型,它的联合概率分布包含配分函数 Z \mathcal Z Z,这意味着需要对这个 包含配分函数的概率分布进行求解。并且该模型包含隐变量。以该模型为例,介绍包含隐变量能量模型的学习任务。
首先观察似然函数(Log-Likelihood):
事先定义一个训练集 V = { v ( 1 ) , v ( 2 ) , ⋯ , v ( ∣ V ∣ ) } \mathcal V = \{v^{(1)},v^{(2)},\cdots,v^{(|\mathcal V|)}\} V={v(1),v(2),⋯,v(∣V∣)},实际上指的就是‘观测变量’————样本集合就是可观测的。因而有 v ( i ) ∈ R n ( i = 1 , 2 , ⋯ , ∣ V ∣ ) , n v^{(i)} \in \mathcal R^n(i=1,2,\cdots,|\mathcal V|),n v(i)∈Rn(i=1,2,⋯,∣V∣),n表示观测变量的维度(观测变量v中随机变量的数量)
L ( θ ) = 1 N ∑ v ( i ) ∈ V log P ( v ( i ) ; θ ) \mathcal L(\theta) = \frac{1}{N} \sum_{v^{(i)} \in \mathcal V} \log \mathcal P(v^{(i)};\theta) L(θ)=N1v(i)∈V∑logP(v(i);θ)
关于 L ( θ ) \mathcal L(\theta) L(θ)的梯度可表示为:
∇ θ L ( θ ) = ∂ ∂ θ [ 1 N ∑ v ( i ) ∈ V log P ( v ( i ) ; θ ) ] \nabla_{\theta}\mathcal L(\theta) = \frac{\partial }{\partial \theta} \left[\frac{1}{N} \sum_{v^{(i)} \in \mathcal V} \log \mathcal P(v^{(i)};\theta)\right] ∇θL(θ)=∂θ∂⎣⎡N1v(i)∈V∑logP(v(i);θ)⎦⎤
将模型表示代入,观察 log P ( v ( i ) ; θ ) \log \mathcal P(v^{(i)};\theta) logP(v(i);θ):
这里仅针对某单个样本,并且模型中存在与其相对应的隐变量 h ( i ) ∈ R m h^{(i)} \in \mathcal R^m h(i)∈Rm.
log P ( v ( i ) ; θ ) = log [ ∑ h ( i ) P ( h ( i ) , v ( i ) ; θ ) ] = log [ ∑ h ( i ) 1 Z ( i ) exp { − E [ h ( i ) , v ( i ) ] } ] Z ( i ) = ∑ h ( i ) , v ( i ) exp { − E [ h ( i ) , v ( i ) ] } \begin{aligned} \log \mathcal P(v^{(i)};\theta) & = \log \left[\sum_{h^{(i)}} \mathcal P(h^{(i)},v^{(i)};\theta)\right] \\ & = \log \left[\sum_{h^{(i)}} \frac{1}{\mathcal Z^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\}\right] \quad \mathcal Z^{(i)} = \sum_{h^{(i)},v^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\} \end{aligned} logP(v(i);θ)=log[h(i)∑P(h(i),v(i);θ)]=log[h(i)∑Z(i)1exp{−E[h(i),v(i)]}]Z(i)=h(i),v(i)∑exp{−E[h(i),v(i)]}
由于 1 Z ( i ) \frac{1}{\mathcal Z^{(i)}} Z(i)1和 h ( i ) h^{(i)} h(i)之间没有关系(被积分掉了),因而将其提到 ∑ h ( i ) \sum_{h^{(i)}} ∑h(i)前面,表示为如下形式:
再使用 Z ( i ) \mathcal Z^{(i)} Z(i)的完整形式进行替换。
log P ( v ( i ) ; θ ) = log [ 1 Z ( i ) ∑ h ( i ) exp { − E [ h ( i ) , v ( i ) ] } ] = log 1 Z ( i ) + log [ ∑ h ( i ) exp { − E [ h ( i ) , v ( i ) ] } ] = log [ ∑ h ( i ) exp { − E [ h ( i ) , v ( i ) ] } ] − log Z ( i ) = log [ ∑ h ( i ) exp { − E [ h ( i ) , v ( i ) ] } ] − log [ ∑ h ( i ) , v ( i ) exp { − E [ h ( i ) , v ( i ) ] } ] \begin{aligned} \log \mathcal P(v^{(i)};\theta) & = \log \left[\frac{1}{\mathcal Z^{(i)}} \sum_{h^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\}\right] \\ & = \log \frac{1}{\mathcal Z^{(i)}} + \log \left[\sum_{h^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\}\right] \\ & = \log \left[\sum_{h^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\}\right] - \log \mathcal Z^{(i)} \\ & = \log \left[\sum_{h^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\}\right] - \log \left[\sum_{h^{(i)},v^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\}\right] \end{aligned} logP(v(i);θ)=log[Z(i)1h(i)∑exp{−E[h(i),v(i)]}]=logZ(i)1+log[h(i)∑exp{−E[h(i),v(i)]}]=log[h(i)∑exp{−E[h(i),v(i)]}]−logZ(i)=log[h(i)∑exp{−E[h(i),v(i)]}]−log⎣⎡h(i),v(i)∑exp{−E[h(i),v(i)]}⎦⎤
至此,对 θ \theta θ求解梯度:
∇ θ [ log P ( v ( i ) ; θ ) ] = ∂ ∂ θ [ log P ( v ( i ) ; θ ) ] = ∂ ∂ θ { log [ ∑ h ( i ) exp { − E [ h ( i ) , v ( i ) ] } ] } − ∂ ∂ θ { log [ ∑ h ( i ) , v ( i ) exp { − E [ h ( i ) , v ( i ) ] } ] } = Δ 1 − Δ 2 \begin{aligned} \nabla_{\theta} \left[\log \mathcal P(v^{(i)};\theta)\right] & = \frac{\partial}{\partial \theta} \left[\log \mathcal P(v^{(i)};\theta)\right] \\ & = \frac{\partial}{\partial \theta} \left\{ \log \left[\sum_{h^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\}\right]\right\} - \frac{\partial}{\partial \theta} \left\{\log \left[\sum_{h^{(i)},v^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\}\right]\right\} \\ & = \Delta_1 - \Delta_2 \end{aligned} ∇θ[logP(v(i);θ)]=∂θ∂[logP(v(i);θ)]=∂θ∂{log[h(i)∑exp{−E[h(i),v(i)]}]}−∂θ∂⎩⎨⎧log⎣⎡h(i),v(i)∑exp{−E[h(i),v(i)]}⎦⎤⎭⎬⎫=Δ1−Δ2
-
首先观察第一项:
根据‘牛顿-莱布尼兹公式’,将求导符号与连加符号互换。
链式求导法则~将负号提到最前面
Δ 1 = ∂ ∂ θ { log [ ∑ h ( i ) exp { − E [ h ( i ) , v ( i ) ] } ] } = − 1 ∑ h ( i ) exp { − E [ h ( i ) , v ( i ) ] } ∑ h ( i ) { exp [ − E ( h ( i ) , v ( i ) ) ] ∂ ∂ θ [ E ( h ( i ) , v ( i ) ) ] } \begin{aligned} \Delta_1& = \frac{\partial}{\partial \theta} \left\{ \log \left[\sum_{h^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\}\right]\right\} \\ & = - \frac{1}{\sum_{h^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\}} \sum_{h^{(i)}} \left\{\exp[- \mathbb E(h^{(i)},v^{(i)})] \frac{\partial}{\partial \theta} \left[\mathbb E(h^{(i)},v^{(i)})\right]\right\} \end{aligned} Δ1=∂θ∂{log[h(i)∑exp{−E[h(i),v(i)]}]}=−∑h(i)exp{−E[h(i),v(i)]}1h(i)∑{exp[−E(h(i),v(i))]∂θ∂[E(h(i),v(i))]}
观察前面的分数项:由于 h ( i ) h^{(i)} h(i)被积分掉,因此分数项对于 h ( i ) h^{(i)} h(i)相当于常数。可将该分数项带回积分号内:
负号就留在外面吧~
Δ 1 = − ∑ h ( i ) { exp [ − E ( h ( i ) , v ( i ) ) ] ∑ h ( i ) exp { − E [ h ( i ) , v ( i ) ] } ⋅ ∂ ∂ θ [ E ( h ( i ) , v ( i ) ) ] } \begin{aligned} \Delta_1 = - \sum_{h^{(i)}} \left\{\frac{\exp[- \mathbb E(h^{(i)},v^{(i)})]}{\sum_{h^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\}} \cdot \frac{\partial}{\partial \theta} \left[\mathbb E(h^{(i)},v^{(i)})\right]\right\} \end{aligned} Δ1=−h(i)∑{∑h(i)exp{−E[h(i),v(i)]}exp[−E(h(i),v(i))]⋅∂θ∂[E(h(i),v(i))]}
观察大括号内第一项:将分子分母同乘 1 Z ( i ) \frac{1}{\mathcal Z^{(i)}} Z(i)1:
并且1 Z ( i ) \frac{1}{\mathcal Z^{(i)}} Z(i)1和h ( i ) h^{(i)} h(i)无关,直接写到∑ h ( i ) \sum_{h^{(i)}} ∑h(i)内部。
1 Z ( i ) exp [ − E ( h ( i ) , v ( i ) ) ] ∑ h ( i ) 1 Z ( i ) exp { − E [ h ( i ) , v ( i ) ] } = P ( h ( i ) , v ( i ) ) ∑ h ( i ) P ( h ( i ) , v ( i ) ) = P ( h ( i ) , v ( i ) ) P ( v ( i ) ) \begin{aligned} \frac{\frac{1}{\mathcal Z^{(i)}}\exp[- \mathbb E(h^{(i)},v^{(i)})]}{\sum_{h^{(i)}} \frac{1}{\mathcal Z^{(i)}}\exp \{- \mathbb E[h^{(i)},v^{(i)}]\}} = \frac{\mathcal P(h^{(i)},v^{(i)})}{\sum_{h^{(i)}}\mathcal P(h^{(i)},v^{(i)})} = \frac{\mathcal P(h^{(i)},v^{(i)})}{\mathcal P(v^{(i)})} \end{aligned} ∑h(i)Z(i)1exp{−E[h(i),v(i)]}Z(i)1exp[−E(h(i),v(i))]=∑h(i)P(h(i),v(i))P(h(i),v(i))=P(v(i))P(h(i),v(i))
最终,根据条件概率公式,该项就是隐变量 h ( i ) h^{(i)} h(i)的后验概率:
1 Z ( i ) exp [ − E ( h ( i ) , v ( i ) ) ] ∑ h ( i ) 1 Z ( i ) exp { − E [ h ( i ) , v ( i ) ] } = P ( h ( i ) ∣ v ( i ) ) \frac{\frac{1}{\mathcal Z^{(i)}}\exp[- \mathbb E(h^{(i)},v^{(i)})]}{\sum_{h^{(i)}} \frac{1}{\mathcal Z^{(i)}}\exp \{- \mathbb E[h^{(i)},v^{(i)}]\}} = \mathcal P(h^{(i)} \mid v^{(i)}) ∑h(i)Z(i)1exp{−E[h(i),v(i)]}Z(i)1exp[−E(h(i),v(i))]=P(h(i)∣v(i))
至此, Δ 1 \Delta_1 Δ1可表示为:
Δ 1 = − ∑ h ( i ) { P ( h ( i ) ∣ v ( i ) ) ⋅ ∂ ∂ θ [ E ( h ( i ) , v ( i ) ) ] } \Delta_1 = - \sum_{h^{(i)}} \left\{\mathcal P(h^{(i)} \mid v^{(i)}) \cdot \frac{\partial}{\partial \theta} \left[\mathbb E(h^{(i)},v^{(i)})\right]\right\} Δ1=−h(i)∑{P(h(i)∣v(i))⋅∂θ∂[E(h(i),v(i))]} -
同理,继续观察第二项 Δ 2 \Delta_2 Δ2:
两项的求解过程非常相似~
Δ 2 = ∂ ∂ θ { log [ ∑ h ( i ) , v ( i ) exp { − E [ h ( i ) , v ( i ) ] } ] } = − 1 ∑ h ( i ) , v ( i ) exp { − E [ h ( i ) , v ( i ) ] } ∑ h ( i ) , v ( i ) { exp { − E [ h ( i ) , v ( i ) ] } ⋅ ∂ ∂ θ [ E ( h ( i ) , v ( i ) ) ] } = − ∑ h ( i ) , v ( i ) { exp { − E [ h ( i ) , v ( i ) ] } ∑ h ( i ) , v ( i ) exp { − E [ h ( i ) , v ( i ) ] } ⋅ ∂ ∂ θ [ E ( h ( i ) , v ( i ) ) ] } \begin{aligned} \Delta_2 & = \frac{\partial}{\partial \theta}\left\{\log \left[\sum_{h^{(i)},v^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\}\right]\right\} \\ & = - \frac{1}{\sum_{h^{(i)},v^{(i)}} \exp \{- \mathbb E[h^{(i)},v^{(i)}]\}} \sum_{h^{(i)},v^{(i)}} \left\{\exp \{- \mathbb E[h^{(i)},v^{(i)}]\} \cdot \frac{\partial}{\partial \theta}\left[\mathbb E(h^{(i)},v^{(i)})\right]\right\} \\ & = -\sum_{h^{(i)},v^{(i)}} \left\{\frac{\exp\{- \mathbb E[h^{(i)},v^{(i)}]\}}{\sum_{h^{(i)},v^{(i)}} \exp\{- \mathbb E[h^{(i)},v^{(i)}]\}} \cdot \frac{\partial}{\partial \theta} \left[\mathbb E(h^{(i)},v^{(i)})\right]\right\} \end{aligned} Δ2=∂θ∂⎩⎨⎧log⎣⎡h(i),v(i)∑exp{−E[h(i),v(i)]}⎦⎤⎭⎬⎫=−∑h(i),v(i)exp{−E[h(i),v(i)]}1h(i),v(i)∑{exp{−E[h(i),v(i)]}⋅∂θ∂[E(h(i),v(i))]}=−h(i),v(i)∑{∑h(i),v(i)exp{−E[h(i),v(i)]}exp{−E[h(i),v(i)]}⋅∂θ∂[E(h(i),v(i))]}
观察大括号内第一项:
exp { − E [ h ( i ) , v ( i ) ] } ∑ h ( i ) , v ( i ) exp { − E [ h ( i ) , v ( i ) ] } = 1 Z exp { − E [ h ( i ) , v ( i ) ] } = P ( h ( i ) , v ( i ) ) \frac{\exp\{- \mathbb E[h^{(i)},v^{(i)}]\}}{\sum_{h^{(i)},v^{(i)}} \exp\{- \mathbb E[h^{(i)},v^{(i)}]\}} = \frac{1}{\mathcal Z}\exp\{- \mathbb E[h^{(i)},v^{(i)}]\} = \mathcal P(h^{(i)},v^{(i)}) ∑h(i),v(i)exp{−E[h(i),v(i)]}exp{−E[h(i),v(i)]}=Z1exp{−E[h(i),v(i)]}=P(h(i),v(i))
由于分母将 h ( i ) , v ( i ) h^{(i)},v^{(i)} h(i),v(i)全部积分掉了,因而分母就是配分函数 Z \mathcal Z Z,该分数项就是联合概率分布 P ( h ( i ) , v ( i ) ) \mathcal P(h^{(i)},v^{(i)}) P(h(i),v(i))。至此, Δ 2 \Delta_2 Δ2可表示为:
Δ 2 = − ∑ h ( i ) , v ( i ) { P ( h ( i ) , v ( i ) ) ⋅ ∂ ∂ θ [ E ( h ( i ) , v ( i ) ) ] } \Delta_2 = -\sum_{h^{(i)},v^{(i)}} \left\{\mathcal P(h^{(i)},v^{(i)}) \cdot \frac{\partial}{\partial \theta} \left[\mathbb E(h^{(i)},v^{(i)})\right]\right\} Δ2=−h(i),v(i)∑{P(h(i),v(i))⋅∂θ∂[E(h(i),v(i))]}
最终,关于能量函数给定观测变量(单个样本 v ( i ) v^{(i)} v(i))条件下,对数似然梯度可表示为:
∇ θ [ log P ( v ( i ) ; θ ) ] = Δ 1 − Δ 2 = ∑ h ( i ) , v ( i ) { P ( h ( i ) , v ( i ) ) ⋅ ∂ ∂ θ [ E ( h ( i ) , v ( i ) ) ] } − ∑ h ( i ) { P ( h ( i ) ∣ v ( i ) ) ⋅ ∂ ∂ θ [ E ( h ( i ) , v ( i ) ) ] } \begin{aligned} \nabla_{\theta} \left[\log \mathcal P(v^{(i)};\theta)\right] & = \Delta_1 - \Delta_2 \\ & = \sum_{h^{(i)},v^{(i)}} \left\{\mathcal P(h^{(i)},v^{(i)}) \cdot \frac{\partial}{\partial \theta} \left[\mathbb E(h^{(i)},v^{(i)})\right]\right\} - \sum_{h^{(i)}} \left\{\mathcal P(h^{(i)} \mid v^{(i)}) \cdot \frac{\partial}{\partial \theta} \left[\mathbb E(h^{(i)},v^{(i)})\right]\right\} \end{aligned} ∇θ[logP(v(i);θ)]=Δ1−Δ2=h(i),v(i)∑{P(h(i),v(i))⋅∂θ∂[E(h(i),v(i))]}−h(i)∑{P(h(i)∣v(i))⋅∂θ∂[E(h(i),v(i))]}
最终,根据牛顿-莱布尼兹公式,关于 L ( θ ) \mathcal L(\theta) L(θ)梯度可表示为:
∇ θ L ( θ ) = ∂ ∂ θ [ 1 N ∑ v ( i ) ∈ V log P ( v ( i ) ; θ ) ] = 1 N ∑ v ( i ) ∈ V ∇ θ [ log P ( v ( i ) ; θ ) ] \begin{aligned} \nabla_{\theta} \mathcal L(\theta) & = \frac{\partial }{\partial \theta} \left[\frac{1}{N} \sum_{v^{(i)} \in \mathcal V} \log \mathcal P(v^{(i)};\theta)\right] \\ & = \frac{1}{N} \sum_{v^{(i)} \in \mathcal V} \nabla_{\theta}\left[\log \mathcal P(v^{(i)};\theta)\right] \end{aligned} ∇θL(θ)=∂θ∂⎣⎡N1v(i)∈V∑logP(v(i);θ)⎦⎤=N1v(i)∈V∑∇θ[logP(v(i);θ)]
说明:上述基于能量函数的概率图模型,给定观测变量,其对数似然梯度的表达结果,它并不仅仅局限于受限玻尔兹曼机,因为上述推导过程至始至终都没有拆开能量函数。它可以是一个通式表达。
下一节将针对受限玻尔兹曼机介绍其学习任务。
相关参考:
直面配分函数:5-Log-Likelihood of Energy-based Model with Latent Variable(具有隐变量能量模型)