NLP机器阅读理解
机器阅读理解(Machine Reading Comprehension, MRC)是让机器具有阅读并理解文章的能力。机器阅读理解是自然语言处理的核心任务之一,在很多领域有着广泛的应用, 比如问答系统、搜索引擎、对话系统等。机器阅读理解包含完形填空式、选择式、抽取式 和生成式四种主要类型。
机器阅读理解发展历程
基于规则的MRC
早期的 MRC 系统都是基于规则的,其会根据不同的问题类型(WHO、WHAT、 WHEN、WHERE、WHY)设计不同的规则集来对句子打分并选择得分最高的句子作为答案句。

基于机器学习的MRC
随着机器学习技术的兴起,研究者们尝试将 MRC 定义为一种监督学习问题。他们希望将人工标注的(段落、问题、答案)三元组数据集训练为一个统计学模型,使得该模型可以在测试时将(段落、问题)映射到对应的答案。

基于深度学习的MRC
深度神经网络和大量大规模 MRC 数据集的出现极大的加快了 MRC 领域研究的进展。大量大规模数据集的出现使得使用深度神经网络模型解决阅读理解问题成为了可能。同时由于深度神经网络模型可以很好的捕获上下文信息,所以性能显著优于传统的方法,并在各个应用领域都得到了广泛的应用。
抽取式MRC任务
抽取式阅读理解,常见形式是给定文章和待回答的问题,要求机器需要从文章中挑选一个片段作为对该问题的回答。
案例分析:
文章:五岳为群山之尊,泰山为五岳之长。五岳是中国五大名山的总称,一般指东岳泰山(位 于山东)、西岳华山(位于陕西)、南岳衡山(位于湖南)、北岳恒山(位于山西)、中岳嵩山(位于河南)。泰山因其气势之磅礴,又有“天下名山第一”的美誉。
问题:五岳中哪一座山有“天下名山第一”的美誉?
回答:泰山
在上面这个例子中,机器阅读文章内容 P,根据问题 Q 在文章 P 中选择答案片段,
最终确定答案片段的起始位置是 88,结束位置是 89,即“泰山”是整个任务的预测答案。
抽取式阅读理解数据集:
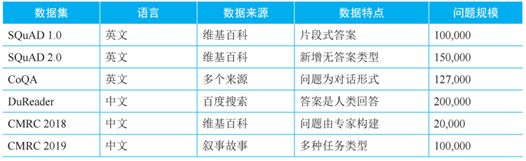
"question": "Beyonc\u00e9 was raised in what religion?",
"id": "56d440df2ccc5a1400d830d5",
"answers": [{
"text": "Methodist",
"answer_start": 578
}],
"is_impossible": false
"context": "Beyonc\u00e9 Giselle Knowles was born in Houston, Texas, to Celestine Ann \"Tina\" Knowles (n\u00e9e Beyinc\u00e9), a hairdresser and salon owner, and Mathew Knowles, a Xerox sales manager. Beyonc\u00e9's name is a tribute to her mother's maiden name. Beyonc\u00e9's younger sister Solange is also a singer and a former member of Destiny's Child. Mathew is African-American, while Tina is of Louisiana Creole descent (with African, Native American, French, Cajun, and distant Irish and Spanish ancestry). Through her mother, Beyonc\u00e9 is a descendant of Acadian leader Joseph Broussard. She was raised in a Methodist household."
发展历程:
SQuAD 数据集是学术界第一个包含大规模自然语言问题的抽取式阅读理解数据集,借助这一数据集,研究者们在几年内提出了大量基于深度学习的阅读理解模型。
BiDAF (Bi-Directional Attention Flow)是这个时期提出的经典模型,该模型使用双向注意力机制通过将上下文和问题进行交互来得到根据问题所表征的上下文编码结果。
但是基于深度神经网络的 MRC 模型仍然存在缺陷 :循环神经网络的依赖距离过长导致不能很好的支持并行计算、预定义的词向量不能很好的表示上下文敏感的词汇。2017 年自注意力机制的出现很好的解决了这些问题。
评价指标:
准确率:预测正确的问题数占全部测试样本集合数量的比例。
F1值:F1值是模型准确率和召回率的调和平均,在阅读理解任务中准确率通常使用预测回答与标准回答交集(以字为单位)的长度与预测回答长度(以字为单位)的比值,而召回率使用预测回答与标准回答交集(以字为单位)的长度与标准回答长度(以字为单位)的比值。

BiDAF模型介绍:
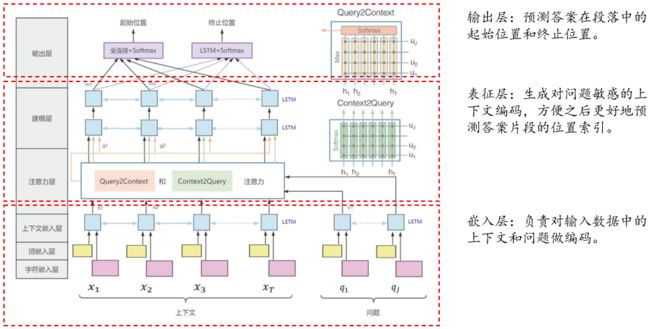
输入为问题={_1,…,_},上下文段落={_1,…, _},即问题长度为,上下文段落长度为。
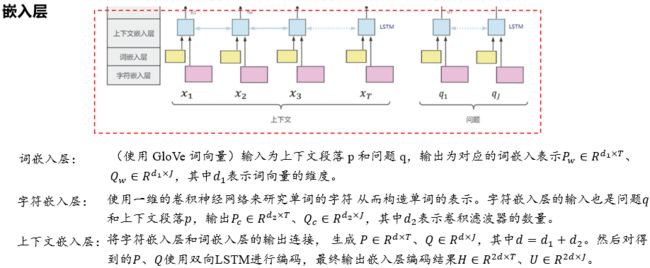
输入为嵌入层对上下文段落和问题的编码输出结果∈(2×)、∈(2×)。
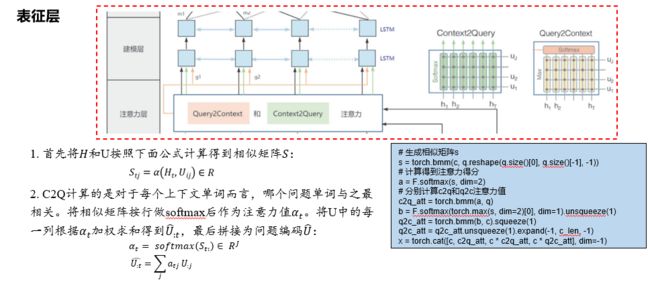


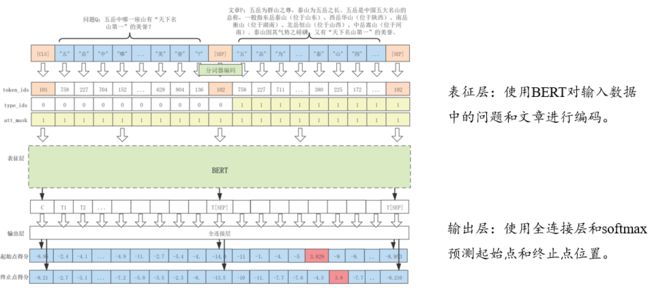
抽取式阅读理解经典模型 BiDAF,以及基于 BERT 的抽取式阅读理解模型,它们都是通过问题和文章进行交互来得到语义信息,并通过全连接层和 softmax 函数来对答案片段起始点和终止点进行预测。
选择式MRC任务
选择式阅读理解,常见形式是给定文章和待回答的问题,以及多个选项1, 2…,要求机器需要从多个选项中选择一个选项作为对该问题的答案。
案例分析:
文章:燕山大学校徽以“书籍”、“海燕”和“海洋”为基本造型元素。书籍体现学校教书育人之根本 ;海燕体现的是燕大的“燕”字,因学校背靠燕山而得 ;海洋体现的是燕山 大学的地域因素,因秦皇岛地处渤海之滨,面朝大海,象征燕大学子遨游在知识的海洋, 勇于探索真理和未知的科学精神 ;蓝色是燕山大学大学标志的主色,代表理性、智慧、天空一样广阔的未来。
问题:燕山大学校徽中“书籍”标识有什么含义?
选项:
1:体现了学校教育的本质 ;
2:表示燕大的“燕”字 ;
3:意味着燕山大学的地域因素,因秦皇岛地处渤海之滨,面朝大海,象征燕大 学子遨游在知识的海洋,勇于探索真理和未知的科学精神;
4:象征理性、智慧、天空一样广阔的未来 ;
发展历程:
MMRC 模型通常首先对上下文、问题和选项编码,然后通过下游的匹配网络计算每个选项的得分。最初的匹配网络分为两种 :第一种是将问题和候选答案连接后与段落匹配 ;第二种先将段落与问题进行匹配, 然后再将其匹配结果与候选项匹配。然而这两种匹配方式都损失了问题和候选项之间交互的信息。
之后提出的 Co-Match 模型首次实现了将文章同时与问题和候选项做匹配,解决了这 个问题,并在 RACE 数据集上取得了当时最好的效果。
2019 年 BERT 预训练模型的提出极大的增强了模型的文本表示能力,基于 BERT 设计的方案在各个 MMRC 数据集测评上都达到了当时最好效果。后续产生了许多基于预训练模型的选择式阅读理解模型。如 DCMN 模型,其主要改进思路:实现对文章、问题、选项两两交互、添加选项之间的比较信息。
评价指标:
准确率:预测正确的问题数占全部测试样本集合数量的比例。
CoMatch模型介绍:

嵌入层的输入为上下文段落、问题和候选选项。(注意,对于每个选项我们都会生成一个最终表示,最后通过全连接层和softmax对每个选项的最终表示进行打分,选取得分最高的选项作为模型的预测答案候选项)此处展示的是对一个选项进行表示和编码的过程:
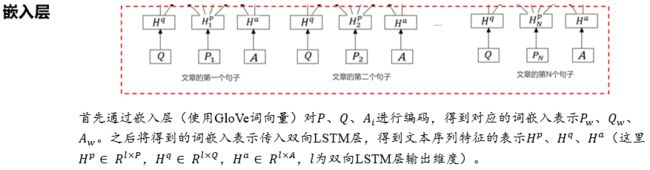
表征层的输入为嵌入层的输出Hp,Hq,Ha。
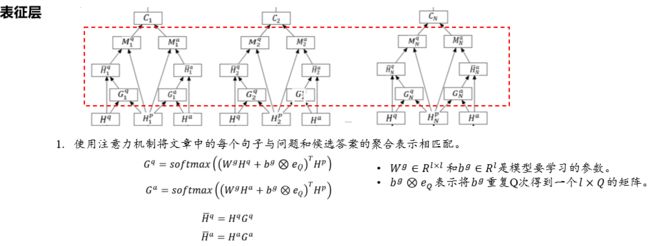
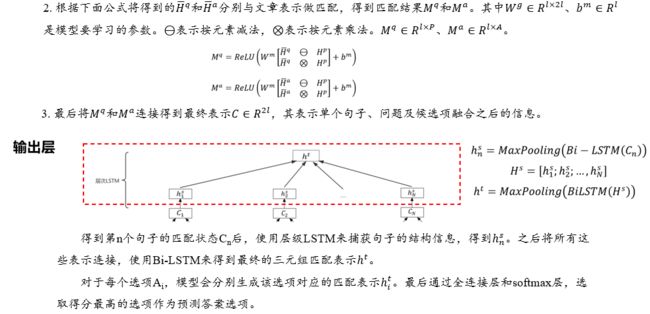
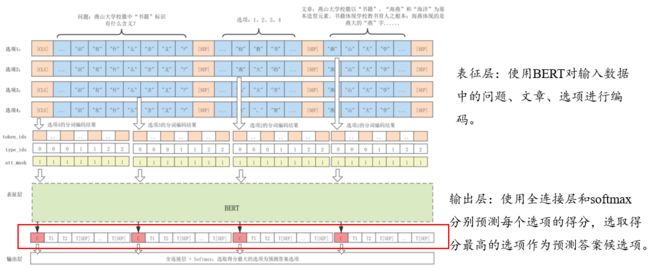
选择式阅读理解模型CoMatch和基于 BERT 的选择式阅读理解模型,它们都是将每个选项与问题和文章进行语义交互得到每个选项匹配的语义信息,并通过全连接层和 softmax 函数对每个选项匹配的语义信息进行打分,最终选取得分最高选项作为模型的预测答案。