Neighbor-Vote:使用邻近距离投票优化单目3D目标检测(ACM MM2021)
名字:Neighbor-Vote: Improving Monocular 3D Object Detection through Neighbor Distance Voting
链接:https://arxiv.org/pdf/2107.02493.pdf
摘要:随着摄像头在自动驾驶等新的应用领域的应用越来越广泛,对单目图像进行3D目标检测成为视觉场景理解的重要任务。单目3D目标检测的最新进展很多依赖于伪点云生成,即进行单目深度估计,将二维像素点提升为伪三维点。然而,单目图像的深度估计精度不高,必然会导致伪点云在目标内的位置发生偏移。因此,预测的边框可能存在不准确的位置和形状变形。在本文中,本文提出了一种新颖的邻居投票方法,该邻居预测有助于从严重变形的伪点云的改善目标检测。具体而言,每个特征点形成他们自己的预测,然后通过投票来构建“共识”。通过这种方式,本文可以有效地将邻居的预测与局部预测的预测相结合,实现更准确的3D检测。为了进一步放大ROI伪点和背景点之间的区别,本文还将2D前景像素点的ROI预测分数编码到相应的伪3D点上。本文在KITTI基准测试上验证本文提出的方法,在验证集上的鸟瞰检测结果优于目前的SOTA,特别是对于“困难”水平检测。
1.引言
3D目标检测是依赖于理解3D世界中的上下文的应用(例如自主驾驶)中最重要的任务之一。目前已出现很多基于点云的3D目标检测算法。尽管这些方法取得了优异的性能,然而,激光雷达仍然太昂贵,不能装备在每一辆车上。因此,廉价的替代品更受青睐,特别是相机,因为它们的价格低,帧率高。
另一方面,由于深度信息的缺少,在RGB图像,尤其是单眼图像上进行3D检测,仍然是艰巨的挑战。为了解决这一挑战,目前已经存在方法:首先从单目图像估计深度信息,然后将2D像素转换到伪3D。随后3D目标检测器可以应用于伪点云上。
与真实雷达点云相比,如上所述的伪点云存在一些问题。首先,由于单目深度估计必然存在不准确性,导致伪点云存在位置偏移和形状变形,这可能会破坏3D边框回归。其次,远距离目标深度估计的精度低于近距离目标深度估计的精度,导致远目标深度估计的失真明显增大。这些变形的伪点云将导致大量误检框的产生。
本文提出了一种叫做Neighbor-Vote(邻居投票)的方法。具体而言,本文认为特征图上的目标周围的每个点都是“选民”。选民需要从自己的视角出发投票给一定数量的附近目标。通过这个投票过程,误检目标比真目标的得票率要低得多,因此更容易被识别。
总之,本文做出了以下三点贡献:
设计了一种高效的单目图像3D检测网络。该网络主要包括四个主要步骤:伪点云生成、2D ROI分数关联、基于注意力的特征提取和邻局辅助预测。
本文设计了一种邻居投票方法,可以有效地消除伪点云预测中的误检框。本文可以自适应地结合邻居预测和局部预测,从而大大提高边框预测的精度。
结果表明,本文的方法在KITTI BEV基准上产生了最好的性能。
2. 邻居投票系统设计
2.1概述

图 1 Neighbor-Vote整体框架图
本文提出一种基于伪点云的框架Neighbor-Vote,旨在通过邻居特征的附加预测提升单目3D目标检测。如图1所示,本文提出的Neighbor-Vote是单阶段检测器,并由以下四个主要步骤组成:
(1)伪点云生成。
(2)2D ROI分数关联。
(3)基于自注意力的特征提取。
(4)邻居投票辅助目标预测。
本文在图1中展示了整个框架,并在下面逐一讨论四个步骤。
2.2伪点云生成

2.3前景伪点云似然关联
远距离目标的深度估计精度远低于近距离目标,导致伪激光点在较远距离处的位置偏移较大。为了补偿不准确的深度估计,在这一步中,本文尽力扩大前景感兴趣区域(ROI)和背景之间的差异,特别是远距离物体。为此,本文提出将每个前景2D像素的ROI得分与相应的伪激光点相关联,用分数来表示成为前景点的可能性。
本文发现,在2D图像中,一个远距离的物体虽然小且分辨率低,但通常仍保留一定程度的语义信息。事实上,就KITTI数据集的汽车类别而言,在许多2D检测器的iou阈值为0.7的困难水平目标上,平均精度(AP)已达到75%以上,如FCOS,CenterNet,Cascad R-CNN。根据这一结果,本文提出用2D检测器提取ROI区域,并将预测得分与相应的伪激光点相关联。
本文使用FCOS作为2D检测器。边界框中每个像素的得分被投影到3D空间中,然后,本文将该分数编码为伪点云的第四个通道,如下所示:

2.4自注意力特征提取
由于伪点云的严重位移和变形,需要依赖于目标周围特征点的空间上下文信息,以更好地识别目标的位置和形状,这些信息需要提取相对远距离的特征。在每个位置上使用多层堆叠的、具有固定接收域的卷积运算不能有效地提取足够长距离的特征。因此,本文在特征提取模块中结合了自注意力机制。

2.5 结合邻居投票的边框预测
邻居投票 如前所述,伪点云在描述目标位置和形状方面不如真实点云准确。为了应对这一挑战,本文提出利用目标附近的特征点(本文称为“邻居”),并让它们协助判断目标的位置。具体来说,本文利用每个邻居点的个体观点,并尝试通过投票机制形成“共识”。考虑一个鸟瞰视角下的特征图,其中和分别表示x和z方向上的特征图的大小,????表示下采样率。靠近预测目标的特征点被视为有投票权的邻居或“投票者”。每个选民投两票。也就是说,他们可以投票支持两个最接近的目标,一个朝前和一个向后(在????方向上的相对定位)

其中P是预测目标的列表。和是前面和后面的选定目标。在这里,本文首先让所有特征点参与投票,然后过滤掉那些投票超出一定距离的特征点,这样使得所有有投票权的邻居确实在预测目标附近,投票过程如图2所示。

图 2 投票过程说明

3.实验
1.验证集上的比较结果。首先,本文与几个最近的单目3D目标检测模型比较了邻居投票的BEV和3D检测精度:
表 1 kitti验证集上的性能比较。“额外信息”意味着除了3D边框外的其他监督,其中“mask”是指分割任务的标签。

2.消融实验。本文对模型进行了消融实验,以分析验证各模块的作用,如表2所示。
表 2 KITTI验证集上的消融分析。本文量化了自注意力模块(SA)、ROI分数关联(RA)、邻居投票分支(V)和两个分类分支的融合(F)的影响。

3.Neighbor-Vote降低误检框的有效性。neighbor-vote背后的基本原理是,本文认为大多数特征点会投票支持真正的目标。因此,邻居投票机制可以有效地过滤掉误检框预测。为了确认这一原理,本文比较了baseline网络(仅包含伪点云生成模块和3D检测器)和本文的网络中不同IoU阈值的真阳性和假阳性的数量,如表3所示。具体来说,当一个预测边框和ground-truth之间的IoU大于预设的阈值,例如0.3、0.5或0.7,这个预测边框被认为是一个真正的目标框(TP);否则就是误检框。接下来,本文计算在baseline网络中但不在本文网络中的误检框(FP)的数量。这里,本文将判定两个边框重合的IoU阈值设为0.1——当两个边框的IoU都大于0.1时,认为这两个边框指向一样的目标。通过这种方式,本文报告了被本文的网络有效移除的误检框的下界。图3的结果表明,本文的网络消除了kitti验证集上73.8%(IoU = 0.5)和55.4%(IoU = 0.7)的误检框。
最后,本文还验证了本文的模型是否会同样移除大量的真实目标框(TP)。如图3(b)所示,只有一小部分TPs会丢失,e.g. 在IoU=0.5和IoU=0.7时分别是6.4%和4.8%。
表 3 KITTI验证集上FP数量和TP数量的相对变化。

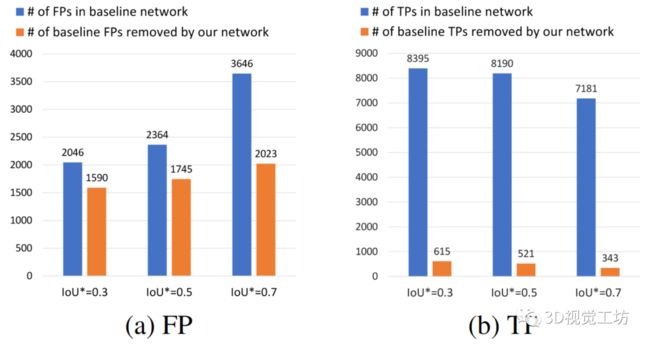
图 3 本文在(a)中报告了baseline网络中的FPs,以及在本文的网络中成功移除的FPs;在(b)中展示baseline网络中的TP的数量,以及意外删除的TP的数量。
4.总结
在这项工作中,本文提出了邻居投票的单目3D目标检测框架。与之前的工作的关键区别在于,本文考虑了目标周围邻居特征点的预测,以帮助改善严重变形的点云的检测。通过投票,每个特征点的个体、噪声预测可以共同形成一个有效的预测。此外,通过自适应权值将邻居预测与局部预测相结合,得到最终的预测结果。在KITTI数据集上的实验证明了该方法的有效性。
备注:作者也是我们「3D视觉从入门到精通」特邀嘉宾:一个超干货的3D视觉学习社区
原创征稿
初衷
3D视觉工坊是基于优质原创文章的自媒体平台,创始人和合伙人致力于发布3D视觉领域最干货的文章,然而少数人的力量毕竟有限,知识盲区和领域漏洞依然存在。为了能够更好地展示领域知识,现向全体粉丝以及阅读者征稿,如果您的文章是3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、硬件选型、求职分享等方向,欢迎砸稿过来~文章内容可以为paper reading、资源总结、项目实战总结等形式,公众号将会对每一个投稿者提供相应的稿费,我们支持知识有价!
投稿方式
邮箱:[email protected] 或者加下方的小助理微信,另请注明原创投稿。

▲长按加微信联系

▲长按关注公众号