【3D目标跟踪】Probabilistic 3D Multi-Modal, Multi-Object Tracking for Autonomous Driving阅读笔记(2020)
1、为什么要做这个研究(理论走向和目前缺陷) ?
之前的3D多目标跟踪,相似度计算基本都不考虑目标的几何和外观特征,也很少会把点云和图像特征融合在一块做,生命周期管理无一例外都是基于经验来设置一个固定参数。不好。
2、他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
主要创新就是加了三个可训练的模块:1)特征融合模块:融合图像(maskrcnn)和点云(centerpoint)的特征,计算检测和跟踪的特征相似度。2)距离组合模块:组合融合的深度特征距离和马氏距离作为相似度度量。3)跟踪初始化模块:基于融合的深度(几何+表观)特征决定新出现的目标是否加入跟踪队列。
3、发现了什么(总结结果,补充和理论的关系)?
效果比centerpoint要好,但是用的可训练网络太多,文中未报告时间消耗。
和上一篇博客的分析的论文(ProbabilisticTracking)同一作者,甚至连论文题目都几乎一样。
摘要:提高跟踪准确度的关键点就是:数据关联以及生命周期管理。本文提出由不同的可训练模块组成的概率、多模态、多目标跟踪算法。首先,设计了一个可学习的融合2D图像和3Dlidar点云表观特征和几何信息的模块。其次,设计了一个可学习的衡量检测与跟踪相似度(混合了马氏距离和特征距离)的模块。再者,提出了一个可学习的决定何时为没有匹配的检测进行初始化的模块。效果在NBuScenes数据集上很好。
1 引言
之前的3D多目标跟踪的相似度度量都是中心点的欧式距离或3D框的马氏距离,只是根据距离差异或者3D框的尺寸朝向差异来决定是否关联,完全不考虑表观特征和几何信息,这就导致卡尔曼滤波预测的位置信息等如果不准的话,准确率就大打折扣。
除了数据关联的度量问题外,跟踪的生命周期管理也很重要,会很影响FP和IDSwitch指标。之前的方法:连续跟踪几帧后再加入跟踪队列,连续丢几帧后就从跟踪队列总删除。本文提出利用即几何和表观特征决定是否加入跟踪队列。
2 相关研究
A.3D目标检测:本文用的CenterPoint检测器
B.3D多目标跟踪:AB3DMOT(3DIOU),ProbabilisticTracking(马氏距离),CenterPoint(中心点欧氏距离)
结合特征和表观特征进行关联的方法:GNN3DMOT,PnPNet。
3 本文方法
三个可训练模块:
1)特征融合模块:融合lidar和图像特征
2)距离组合模块:组合深度特征距离和马氏距离作为相似度度量
3)跟踪初始化模块:基于其深度(几何+表观)特征决定新出现的目标是否加入跟踪队列
A.卡尔曼滤波
状态空间模型(同ProbabilisticTracking,匀速运动模型):
![]()
但是量测用的是centerpoint的检测结果,跟一般的不同的是,这个检测结果除了正常的中心点3D位置+朝向+3D尺寸外还包含了两个额外参数(dx, dy),可认为是相对上一帧同一目标中心点的位移,通过计算 中心点速度x两帧时间差 获取。
观测噪声矩阵和过程噪声矩阵同ProbabilisticTracking,也是从训练集中统计获取的。
跟踪模型的总体架构如下图:
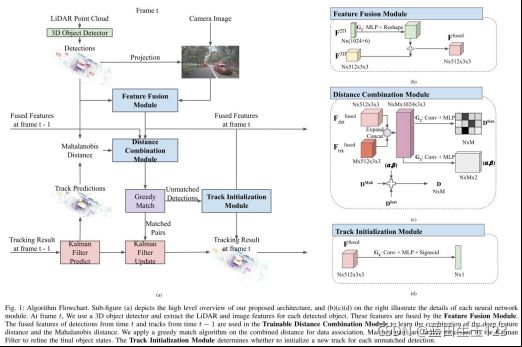
B.2D和3D特征的融合
对于每个检测结果,将其在世界坐标系下的2D位置(x,y)转换到3D目标检测器的中间2D特征图的位置(xmap, ymap) in,从这个特征图上提取到这个实例的512x3x3的点云特征。然后把3D检测框映射到2D图像上,再用预训练的Mask RCNN主干网络提取特征,再经RoIAlign后得到一个1024维的向量,这个向量再连接一个6维的one-hot向量(用于3D框映射到了哪个相机平面?),得到最终的2D特征。最后用一个MLP将两个特征向量融合,得到最终的Nx512x3x3维的融合特征,其中N代表检测个数,G1代表MLP+reshape,公式如下:
![]()
C.距离组合模块
马氏距离和融合特征的距离如何权衡问题。如下公式:
![]()
alpha和beta是两个系数矩阵, Dfeat是前后帧融合特征距离,它们是用神经网络计算得到的,这个神经网络见框架图中的©。
1)融合特征距离计算公式表达:
![]()
G2是一个卷积神经网络,通过将其视为一个二分类问题进行监督。由于对于前后帧预测没有真实ground truth,只能选择离其中心点最近的gt框作为匹配的标注框,如果前后帧的这个两个标注框的id相同并且两个检测中心的欧式距离小于2m,二分类的监督K = 0,否则K = 1。监督过程的交叉熵损失公式:
![]()
2)组合系数alpha和beta
G3也是一个卷积神经网络:
![]()
训练这个网络的损失函数参考了PnPNet,用了max-margin(最大边缘)+contrastive对比损失训练。对于一对组合系数(alpha,beta),训练的结果应使利用这对组合系数计算出来的检测和正例跟踪的组合距离di小于和负例跟踪的组合距离dj:
![]()
每一帧训练的这个总的损失公式表达:

(这里感觉损失需要取反?)
其中Pos和Neg分别代表正确的和错误的跟踪匹配对。
(下面这一块没看太懂,这两个其它的最大边缘损失作用是什么?如何发挥作用?)
为了同时使用学习的融合距离D来拒绝在推断中匹配失败的外点。定义两个其它的最大边缘损失如下:

其中,C_pos和C_neg定义为固定边缘,以及T是固定的阈值来拒绝匹配失败的外点。总的损失函数定义如下:
![]()
实际中,选择T = 11,C_contr = 6,C_pos = C_neg = 3。
最后关联时用的贪心算法进行匹配。
D.跟踪初始化模块
本文将是否跟踪初始化(将检测加入跟踪队列)视为一个二分类任务,用一个卷积神经网络(G4)预测是否进行跟踪初始化:
![]()
训练此网络用交叉熵损失:
![]()
如果有GT和检测匹配的话,监督标签P_target=1,否则为0。推断阶段,P>0.5就进行初始化。
4 实验
A.数据集:NuScenes
B.评估指标:AMOTA(在不同召回率下的平均跟踪准确率,参考NuScenes挑战赛)
C.量化结果
只在NuScenes验证集上做了实验,实验结果如下:
和单模态跟踪模型的对比:

目前在Nuscenes排行榜排名(本文方法第11名)截图:

和多模态跟踪模型的对比:

D.消融研究
围绕三个新加的可训练模块展开对比分析:

比较好的结果可视化:

5 结论
未来的工作:1)考虑加入更多的模态信息生成融合特征,比如地图信息。2)测试更好的检测算法。3)改进运动模型。4)考虑利用可微分的滤波框架,利用递归滤波的算法先验,对运动和观测模型进行端到端的微调。