redis进阶-读写锁,缓存击穿、穿透、雪崩,双写不一致,key过期策略

工作学习的同时不能忘了生活
管道
redis官方的定义:A Request/Response server can be implemented so that it is able to process new requests even if the client hasn't already read the old responses. This way it is possible to send multiple commands to the server without waiting for the replies at all, and finally read the replies in a single step.一个请求发送同时发送很多命令到服务端,不用等服务器响应,可以去处理新的请求,最终只需一次性读取所有响应,这是我个人理解。这就相当于节省了很多个网络请求和响应的时间,大幅提升效率。
lua脚本
在redis2.6中允许开发中发送lua脚本语言到redis服务器中执行。有如下几个优点:
1、减少网络开销,提升性能。可以同时发送多个redis命令到redis服务器执行,较少网络开销。这跟管道类似
2、具有原子性。redis将整个lua脚本当做一个整体执行,中间不会有其他命令插入执行,要么失败要么成功
3、redis事务功能。lua脚本可以替代redis事务功能。
redis内部通过EVAL命令对lua脚本进行执行:
public static void main(String[] args) {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setMinIdle(5);
//连接超时和读写超时
JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.195.128", 6379, 30000);
Jedis jedis = jedisPool.getResource();
System.out.println(jedis.get("rick"));
//redis管道操作:可以把一连串的命令给redis执行,较少命令传输,提升效率
// Pipeline pipeline = jedis.pipelined();
// for (int i = 0; i < 10; i++) {
// pipeline.incr("pipelinekey");
// pipeline.set("ricky" + i, i + "");
// //模拟管道报错,不支持事务,报错了继续执行命令
// pipeline.setbit("rick", 15, false);
// }
// System.out.println(pipeline.syncAndReturnAll());
//lua脚本原子操作:
jedis.set("product_stock_id", "15");
String script = " local count = redis.call('get', KEYS[1]) " +
" local a = tonumber(count) " +
" local b = tonumber(ARGV[1]) " +
" if a >= b then " +
" redis.call('set', KEYS[1], a-b) " +
" return 1 " +
" end " +
" return 0 ";
//KEYS[1]:第一个数组参数的第一个元素;ARGV[1]第二个数组参数的第一个元素
Object eval = jedis.eval(script, Arrays.asList("product_stock_id"), Arrays.asList("5"));
System.out.println(eval);
}setnx命令
SETNX key value: Set the value of a key, only if the key does not exist
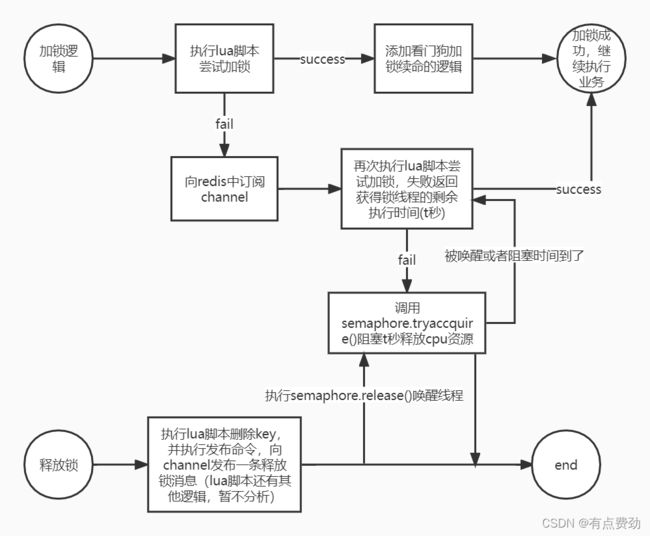
setnx命令是向redis发出一个设置key-value对的请求,如果设置成功表示redis中不存在该key,相反如果设置失败表示redis中存在重复的key。不难看出他比较适合做分布式锁,设置成功相当于获取到分布式锁,否则获取分布式失败。但是如果获取到分布式锁的线程假死或者进入死循环导致释放锁失败,就会导致死锁,我们可以给key设置一个缓存失效时间,防止业务线程获得锁没有释放锁。但是这里会引入新的问题,当业务线程获得锁执行业务逻辑的时间超过缓存失效时间就有可能导致其他竞争分布式锁的线程也会获得锁,此时就会出现数据安全问题;这个怎么解决呢?redisson已经帮我们想好了,通过看门狗进行锁续命,获得锁的业务线程fork一个子进程监听业务线程,每隔10秒钟去检查业务线程是否执行完成,如果没有则对key的缓存失效时间重置一次(默认30秒)
redisson
redisson通过lua脚本的原子性实现分布式锁,并实现了看门狗锁续命的逻辑
@PostMapping("/subtractStock/{productId}")
public String productSubtractStock(@PathVariable String productId) {
//单机锁,不适用于集群
// synchronized (this) {
//redis setnx获取分布式锁,30秒, 如果业务执行时间超过30秒,key失效,
// 其他线程会获得锁,导致并发安全问题,可以使用看门狗进行延时
// String lockValue = UUID.randomUUID().toString();
String lockKey = PRODUCT_LOCK_PREFIX + productId;
// Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent(lockKey,
// lockValue,30, TimeUnit.SECONDS);
// if (!lock) {
// log.warn("获取锁失败");
// return "failed";
// }
// redisson通过sexnx命令实现分布式锁,并实现看门狗延时功能
RLock lock = redisson.getLock(lockKey);
lock.lock();
try {
Integer count = Integer.valueOf(stringRedisTemplate.opsForValue().get(PRODUCT_STOCK_COUNT + productId));
if (count > 0) {
stringRedisTemplate.opsForValue().set(PRODUCT_STOCK_COUNT + productId, String.valueOf(count - 1));
log.info("扣减库存成功,剩余库存: " + (count - 1));
} else {
log.info("扣减库存失败");
return "failed, cause stock not enough!";
}
} finally {
//不具有原子性,可能被打断执行
// if (lockValue.equals(stringRedisTemplate.opsForValue().get(lockKey))) {
// stringRedisTemplate.delete(PRODUCT_LOCK_PREFIX + productId);
// }
lock.unlock();
}
return "success";
}缓存击穿和缓存穿透
博主之前一直在区分缓存穿透和缓存击穿的区别,看了又忘,忘了又看。如今我看“透”了,两者之间的差别就在这个“透”字,缓存穿透代表web服务器收到请求后先去redis中匹配,发现没有,再去数据库中查找还是没有,穿透。。。了;而缓存击穿(失效)则是同一时间大批量缓存失效导致大量请求击穿redis打到数据库,瞬间导致数据库压力激增无法及时响应甚至可能导致挂掉。
如何解决这两个问题呢?
缓存击穿可以将批量的key设置随机的过期时间。而缓存穿透在查询数据的时候加分布式锁,请求相同数据的请求只有一个请求能到达数据库,然后将key-null设置到redis,而这种方式存在隐患,如果收到恶意攻击redis会缓存大量null值;另一种比较好的解决方案就是布隆过滤器,布隆过滤器的作用就是判断某个值存在时,这个值可能不存在;判断某个值不存在时,这个值肯定不存在。
布隆过滤器的使用:
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.195.128:6379");
RedissonClient redisson = Redisson.create(config);
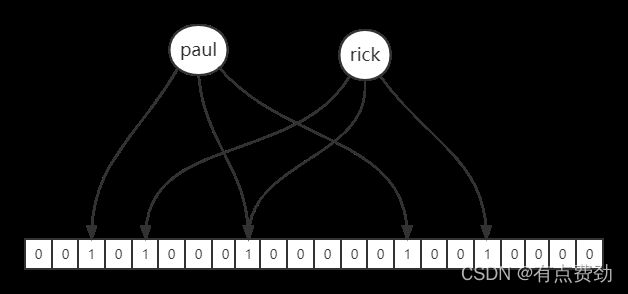
RBloomFilter布隆过滤器是通过大型位数组和多个不同的无偏hash函数实现,当向布隆过滤器中添加元素时,布隆过滤器通过多个不同的hash函数对元素分别计算hashCode,并将多个hashCode对位数组的长度取模计算,计算的结果会落到数组中对应下标,该下标对应的位就会被置为1。
缓存雪崩
缓存雪崩指的是缓存层支撑不住,甚至宕机导致大量流量冲击到数据库
而导致缓存雪崩的原因:超大并发过来,缓存层支撑不住(redis官方生命支撑的并发大概100000qps);大量请求访问bigkey,导致缓存并发能力急剧下降,都会使大量请求打到数据库,最后导致数据库级联宕机。
预防缓存雪崩:
保证redis服务高可用,使用哨兵集群或者cluster集群保证缓存层高可用
使用隔离组件为后端限流并降级。提前演练。
热点缓存key重建优化
热点缓存key重建指的是热点数据失效后进行重建的过程,如果在热点数据缓存失效的一瞬间有大量的用户访问热点key,会导致大量线程进行热点key重建缓存,从而导致数据库压力巨大甚至导致宕机。但是一般来讲,缓存+过期时间的策略已经满足大多数的需求。热点缓存key典型常见某大明星热恋离婚等上热搜。
解决热点缓存重建的方案不难,就是分布式锁+double check,在大量线程进行缓存重建之前上分布式锁,最终只有一个线程可以进行热点缓存重建,其他线程进行阻塞等待,当热点缓存key重建完成,其他线程从缓存命中数据。代码就不上了,毕竟方案已经给了。
缓存和数据库双写不一致
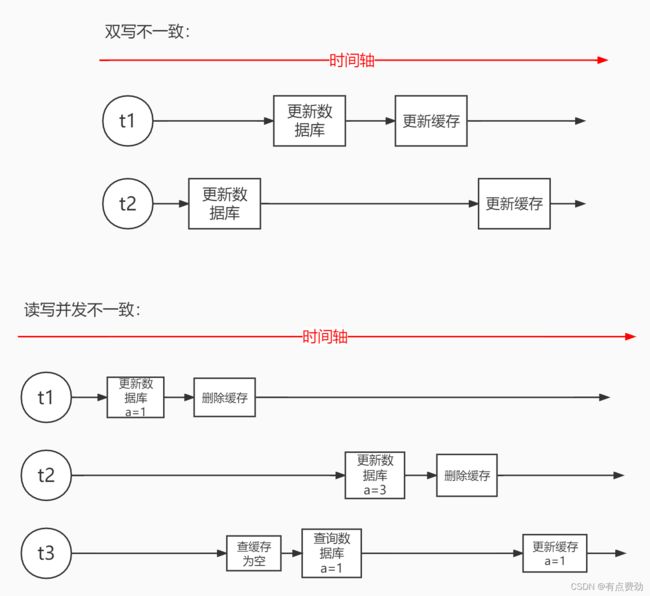
根据业务的场景不同可以做出不同的方案,假如业务不需要强一致性,能够容忍数据库和缓存不一致的情况只需要“缓存+过期时间”策略即可。如果业务要求必须满足一致性,则可以加分布式读写锁,对于大多数业务场景,都是读多写少,读读保证并发执行,读写和写写军为互斥锁,不能并发执行,从而保证数据库和缓存的数据一致。
bigkey
首先说明bigkey描述的是key-value的数据对的总和,不是指单个key。
产生bigkey的集中场景:微博某明星粉丝列表set集合;统计某个常用网页的访问用户量;从数据库load某固定不变的业务数据到redis中,可能是bigkey
对于bigkey的优化。可以进行拆分,比如某明星的粉丝有10000个,可以拆分为5个key-value,key重新设计为userId:fans:1类似这种;对于不可避免的bigkey,可以思考获取的方式,比如只获取其中的某个字段或者某些字段,而不是获取所有的value数据。设计合理的数据类型,控制key的过期时间。
过期key清除策略
1、被动清除:当读/写一个过期的key时,直接删除掉这个过期key
2、主动清除:被动清除无法保证删除冷数据,redis设计主动定期删淘汰一批过期key,可以有效淘汰掉冷数据缓存。
3、当redis中内存打到maxmemory限定时,触发主动清除策略
主动清除策略有8种:
对于设置了过期时间的key的清除策略
(1)volatile-ttl:会根据key的过期时间长度先后删除
(2)volatile-random:对设置了过期时间的key,进行随机删除
(3)volatile-lru:对设置了过期时间的key采用lru算法进行删除淘汰(lru算法:淘汰最近最少使用,以最近一次访问时间为基准)
(4)volatile-lfu:对设置了过期时间的key采用lfu算法进行删除淘汰(lfu算法:淘汰最不经常使用,以最近一段时间访问次数为基准)
针对所有key:
(5)allkeys-random:从所有数据随机选择进行删除
(6)allkeys-lru:对于所有数据使用lru算法进行淘汰
(7)allkeys-lfu:对于所有数据使用lfu算法进行淘汰
不处理:
(8)不会做任何处理,对于客户端新写入的数据直接报错拒绝,只响应读操作
对于存在热点数据时,推荐使用volatile-lru算法。