Android中的线程(二)线程安全 & 线程同步
文章目录
-
- 线程安全
-
- synchronized 同步锁
- ReentrantLock 重入锁
- volatile 线程可见
- Atomic 原子类家族
- ThreadLocal 本地副本
- Semaphore 信号量
- CountDownLatch 计数器
- BlockingQueue 阻塞队列
- Concurrent 线程安全的集合类
- ReadLock/WriteLock 读写锁
- 锁的优化
- 线程死锁
线程安全
线程安全又叫线程同步,在Java中多个线程同时访问一个可共享的资源变量时,有可能会导致数据不准确,导致使用该变量的逻辑出现问题,因此使用同步锁来保证一个线程对该资源的操作完成之前,其他线程不会对其进行操作,即保证线程同步安全。
因此线程同步的本质就是线程排队,这可能跟它的字面意思相反,它的目的就是保证线程按照先后顺序一个一个的访问共享资源,为了避免同时操作同一个共享资源。
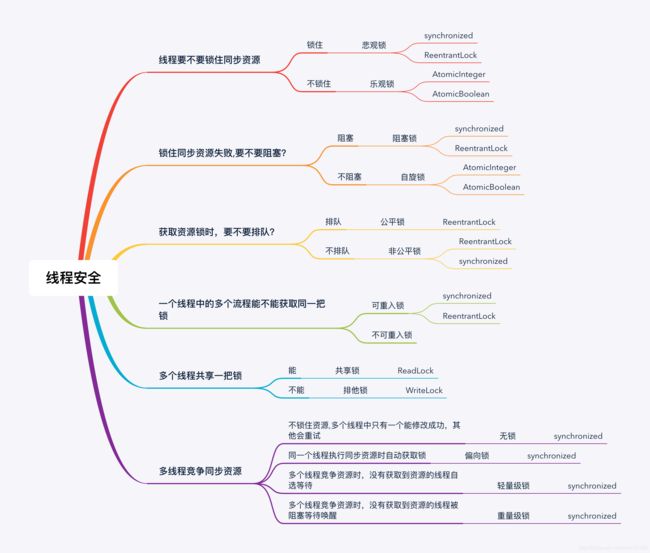
在Java中实现线程安全的主要手段有:
- synchronized 同步锁
- ReentrantLock 重入锁
- volatile 线程可见
- Atomic 原子类家族,如AtomicInteger、AtomicBoolean等
- ThreadLocal 本地副本
- Semaphore 信号量
- ReadLock/WriteLock 读写锁
- Concurrent 线程安全的集合类,如ConcurrentHashMap等
- BlockingQueue 阻塞队列
- CountDownLatch 计数器
synchronized 同步锁
synchronized关键字为同步锁,可重入锁,可以修饰普通方法、静态方法、代码块,但构造方法和成员变量除外。
同步方法:
public class Foo {
public synchronized void method() {
//...
}
}
这等价于:
public class Foo {
public void method() {
synchronized(this) {
//...
}
}
}
加在普通方法上的synchronized关键字修饰使用的同步锁的是当前对象,就是调用当前方法的那个对象,注意这里是指同一个对象,假如我有线程A、线程B,Foo的实例obj1, Foo的实例obj2,那么只有线程A和线程B同时调用obj1的method()方法(或同时调用obj2的),这时才会导致同步锁竞争,假如线程A访问的是obj1的method()方法,而线程B访问的是obj2的method()方法,那么它们互不影响,不会产生竞争,能同时访问执行。而访问同一个对象的不同的普通同步方法,也会产生竞争,因为它们是使用同一个this对象,竞争同一个锁。也就是说看是否会产生竞争本质是看使用的锁是否是同一个对象。
同步静态方法:
public class Foo {
public synchronized static void method() {
//...
}
}
这等价于:
public class Foo {
public static void method() {
synchronized (Foo.class) {
//...
}
}
}
加在静态方法上面的synchronized关键字使用的锁是当前的类对象(Class)作为同步锁,可以理解下面的代码:
public class Foo {
public static void method() {
Class<Foo> obj = Foo.class;
synchronized (obj) {
//...
}
}
}
假如有多个线程内同时调用Foo.method()时就会导致竞争,但是假如Foo类内部还有一个普通的非静态同步方法method2(), 那么当不同线程同时访问method() 和 method2() 方法时,它们并不会导致竞争,可以同时执行,因为它们所使用的加锁对象不同,一个是Foo类的实例对象Foo obj,一个是Class类的对象Class
同步代码块:
public class Foo {
public static final Object lock = new Object();
public void f1() {
synchronized (lock) { // lock 是公用同步锁
// 代码段 A
// 访问共享资源 resource1
// 需要同步
}
}
public void f2() {
synchronized (lock) { // lock 是公用同步锁
// 代码段 B
// 访问共享资源 resource1
// 需要同步
}
}
}
前面的普通同步方法和静态同步方法本质上都是同步代码块的实现,synchronize的括号里面的对象可以是任意一个Object对象,这里的 lock 对象并不一定是public static final的,但是必须保证的是,多个线程在访问同一共享资源时使用的是同一个锁对象,即唯一的锁对象,才有意义。
比如,像下面这样写是完全没有意义的:
public class Foo {
public void f1() {
Object lock = new Object();//局部变量作为锁
synchronized (lock) {
// 代码段 A
// 访问共享资源 resource1
// 需要同步
}
}
}
这段代码使用的锁对象是方法内部的局部变量,这样每调用一次该方法就会生成一个新的锁对象,导致最终在不同线程中调用该方法使用的是不同的锁对象,它们之间根本就不会产生竞争,完全达不到锁的目的。除非我们将该对象改成公用的唯一值。
注意,竞争同步锁失败的线程进入的是该同步锁的就绪(Ready)队列,而不是等待队列,就绪队列里面的线程总是时刻准备着竞争同步锁,时刻准备着运行。而等待队列里面的线程则只能一直等待,直到等到某个信号的通知之后,才能够转移到就绪队列中,准备运行。
成功获取同步锁的线程,执行完同步代码段之后,会释放同步锁。该同步锁的就绪队列中的其他线程就继续下一轮同步锁的竞争。成功者就可以继续运行,失败者继续待在就绪队列中。
线程的等待 & 唤醒机制 wait & notify
synchronized代码块中可以使用wait & notify方法实现线程的等待和唤醒机制,又称线程间的通信,但是我觉得描述为等待和唤醒更加准确,因为线程通信是可以发送携带消息的,而wait & notify只是发一个通知并不能携带额外的信息。
Object obj = new Object();
public void f1() {
synchronized(obj){
while(condition) {
...
obj.wait(); //进入等待状态,释放同步锁,直到有人唤醒它
...
}
}
}
public void f1() {
synchronized(obj){
...
obj.notify(); //唤醒等待obj的线程,当前线程继续执行
...
}
}
| 方法 | 说明 |
|---|---|
wait() |
释放当前线程的同步锁,使当前线程进入等待状态,直到有其他线程调用notify()或notifyAll()唤醒 |
notify() |
通知唤醒等待该对象的线程,使该线程从等待状态进入可运行状态,当前线程继续执行,被唤醒的线程不一定立马运行,这取决于当前调用notify的线程是否执行完了synchronized代码块释放了同步锁。如果有多个线程在等待该对象,那么由操作系统指定该执行哪一个。 |
notifyAll() |
唤醒所有等待该对象的线程,哪一个线程先执行取决于系统实现 |
wait和sleep的区别:wait和notify只能在synchronized代码块中调用,否则会抛异常,sleep可以在任何地方调用。wait进入等待的线程必须由notify来唤醒,而sleep等待的线程到指定时间会自动唤醒执行。wait和sleep都能被中断,响应中断异常。
synchronized实现原理:
每个Java对象可以作为同步锁是通过一个 内置锁 或者 监视器锁(Monitor Lock) 的指令来实现的。
java每个对象都有一个对象头,对象头中有个部分就是用来存储synchronized关键字锁的。
当线程访问一个同步代码块或者方法时必须得到这把锁,当退出或者抛出异常时会释放这把锁,进入锁释放锁是基于monitor对象来实现同步的,monitor对象主要有两个指令monitorenter(插入到同步代码开始位置)、monitorexit(插入到同步代码结束的时候),JVM会保证每个enter后有exit与之对应,但是可能会有多个exit和同一个enter对应,因为退出的时机不仅仅是方法退出也可能是方法抛出异常。每个对象都有一个monitor与之关联,一旦持有之后,就会处于锁定状态,当线程执行到monitorenter这个指令时,就会尝试获取该对象monitor所有权(尝试获取该对象锁)。
monitorenter和monitorexit指令
监视器锁的原理是通过计数器来实现,通过monitorenter和monitorexit指令会在执行的时候让锁计数减1或者加1,每个对象都与一个monitor对象关联,一个monitor的lock锁只能被一个线程在同一时间获得,一个线程在尝试获得与这个对象关联的monitor所有权时只会发生以下三种情况之一:
- 如果这个
monitor计数器为0,意味着目前还没有被获得,然后这个线程会立刻获得然后将计数器加1, 其它线程就会知道该monitor已经被持有了,这就是成功获得锁。 - 如果这个线程已经拿到了
monitor的所有权,又重入了,计数器就会再加1变成2、3…(可重入原理) - 如果
monitor已经被其它线程持有了,现在去获取就会得到无法获取信号,那么就会进入阻塞状态,直到monitor计数器变为0再去尝试获取锁。
monitorexit就是对锁进行释放,释放的过程就是将计数器减1,如果减完之后计数器变为0就意味着当前线程不再拥有对锁的所有权了。如果减完之后不为0就意味着是重入进来的,那么就继续持有该锁。
monitorenter和monitorexit指令可以在反编译的java class文件中对应的同步代码块位置查找到。
总结synchronized注意事项:
- 无论
synchronized关键字加在方法上还是对象上,它取得的锁都是对象,而不是把一段代码或函数当作锁。 - 每个对象只有一个锁(
lock)与之相关联。 Synchronized修饰的方法或代码块执行完毕后,同步锁是自动释放的,但是在执行同步代码块的过程中,遇到异常而导致线程终止,锁也会被释放。- 在执行同步代码块的过程中,执行了锁所属对象的
wait()方法,这个线程会释放对象锁,进入对象的等待池。 - 当一个线程开始执行同步代码块时,并不意味着必须以不间断的方式运行,进入同步代码块的线程可以执行
Thread.sleep()或执行Thread.yield()方法,此时它并不释放对象锁,只是把运行的机会让给其他的线程。 synchronized声明不会被继承,如果一个用synchronized修饰的方法被子类覆盖,那么子类中这个方法不再保持同步,除非用synchronized修饰。- 加锁对象不能为空,锁是保存在对象中的,为空自然不行。
synchronized缺陷:
- 不够灵活,不能手动释放锁,一旦加锁成功就必须一直等待同步代码块全部执行完毕,或者抛出异常。
- 不能中断正在加锁的线程, 相比于Lock
- 不能获取申请锁的结果是否成功,相比于Lock
- 不能做到读写锁分离
ReentrantLock 重入锁
ReentrantLock 是Lock接口的实现类,是同步锁,可重入锁,可重入锁是指支持一个线程内对资源的重复加锁,也就是可以多次调用lock()方法获取锁而不被阻塞,synchronized本身也是可重入锁,只不过ReentrantLock比synchronized控制更灵活更具可操作性,能更加有效的避免死锁。同时ReentrantLock还支持获取锁的公平性和非公平性。
可重入锁的示例:
void methodA(){
lock.lock(); // 获取锁
methodB();
lock.unlock() // 释放锁
}
void methodB(){
lock.lock(); // 获取锁
// 其他业务
lock.unlock();// 释放锁
}
public void doWork(){
lock.lock()
doWork();//递归调用,使得统一线程多次获得锁
lock.unLock()
}
ReentrantLock内部采用的是计数功能,当一个线程内调用lock方法时,计数器会设置为1,假如内部某个时刻再次申请时没有其他线程持有该锁,那么计数器加1,每当调用unlock方法时计数器减1。
| 方法 | 说明 |
|---|---|
void lock() |
获取锁 |
void lockInterruptibly() throws InterruptedException |
获取锁,并且在获取锁成功后可响应中断操作 |
boolean tryLock() |
尝试非阻塞式获取锁,调用该方法后立即返回能否获取到锁,如果能申请返回true, 否则返回false |
boolean tryLock(long time, TimeUnit unit) throws InterruptedException |
尝试在超时时间内获取锁,如果超时未获取到返回false,否则返回true, 并且在该时间内支持中断操作 |
void unlock() |
释放锁 |
Condition newCondition() |
生成绑定到加锁对象的子条件实例,在lock成功的前提下,该类可以通过Condition#await() 或Condition#signal() 来等待或唤醒线程,实现更精细的控制 |
ReentrantLock 的构造函数为 ReentrantLock(boolean fair), 这里的布尔参数fair是用来设置公平锁还是非公平锁,区别主要取决于申请时间上:
-
公平锁: 操作会排一个队按顺序执行,来保证执行顺序。所有进入阻塞的线程排队依次均有机会执行。
-
不公平锁: 是无序状态允许插队,
jvm会自动计算如何处理更快速来调度插队。避免每一个线程都进入阻塞,再唤醒,性能高。因为线程可以插队,导致队列中可能会存在线程饿死的情况,一直得不到锁,一直得不到执行。
ReentrantLock lock = new ReentrantLock(); //参数默认false,不公平锁
ReentrantLock lock = new ReentrantLock(true); //公平锁
lock.lock();
try {
//操作
} finally {
lock.unlock(); //释放锁
}
// 等价于synchronized关键字
// public synchronized void method {
//
// }
jdk推荐将 unlock() 方法写在 finally 当中,这样能确保即便操作中发生异常也能最终释放锁。很显然与synchronized相比,synchronized的优势是加锁和释放锁都是自动处理的,不需要开发者手动操作。
支持响应中断:
ReentrantLock lock = new ReentrantLock(true); //公平锁
try {
lock.lockInterruptibly();//获取锁, 中断
//操作
} catch (InterruptedException e) {
Thread.currentThread().interrupt();//出现异常就中断
} finally {
lock.unlock();//释放锁
}
防止重复执行(忽略重复触发):
ReentrantLock lock = new ReentrantLock();
if (lock.tryLock()) { //如果已经被lock,则立即返回false不会等待,达到忽略操作的效果
try {
//操作
} finally {
lock.unlock();
}
} else {
//申请失败操作
}
lock.tryLock() 是非阻塞的方法,即立马返回能否获取到锁的结果,这样提高了程序执行的性能。
支持超时等待&中断:
ReentrantLock lock = new ReentrantLock(true); //公平锁
try {
//尝试5s内获取锁,如果5s后仍然无法获得锁则返回false继续执行
if (lock.tryLock(5, TimeUnit.SECONDS)) {
try {
//操作
} finally {
lock.unlock();
}
}
} catch (InterruptedException e) {
e.printStackTrace(); //当前线程5s内被中断(interrupt),会抛InterruptedException
}
newCondition子条件控制:
ReentrantLock lock = new ReentrantLock();
Condition worker1 = lock.newCondition();
Condition worker2 = lock.newCondition();
class Worker1 {
.....
worker1.await()//进入阻塞,等待唤醒
.....
}
class Worker2 {
.....
worker2.await()//进入阻塞,等待唤醒
.....
}
class Boss {
if(...) {
worker1.signal()//指定唤醒线程1
} else {
worker2.signal()//指定唤醒线程2
}
}
Condition的作用是对锁进行更精确的控制,可使用它的await-singnal 指定唤醒一个(组)线程。相比于Object的wait-notify要么全部唤醒,要么只能唤醒一个,更加灵活可控。
使用示例:
public class ProducerConsumerTest {
private Lock lock = new ReentrantLock();
/** 子条件控制 */
private Condition addCondition = lock.newCondition();
private Condition removeCondition = lock.newCondition();
private LinkedList<Integer> resources = new LinkedList<>();
private int maxSize;
public ProducerConsumerTest(int maxSize) {
this.maxSize = maxSize;
}
/** 生产者 */
public class Producer implements Runnable {
private int proSize;
private Producer(int proSize) {
this.proSize = proSize;
}
@Override
public void run() {
lock.lock();
try {
for (int i = 1; i < proSize; i++) {
while (resources.size() >= maxSize) {
System.out.println("当前仓库已满,等待消费...");
try {
// 生产者进入阻塞状态,等待消费者唤醒
addCondition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("已经生产产品数: " + i + "\t现仓储量总量:" + resources.size());
resources.add(i);
//唤醒消费者
removeCondition.signal();
}
} finally {
lock.unlock();
}
}
}
/** 消费者 */
public class Consumer implements Runnable {
@Override
public void run() {
String threadName = Thread.currentThread().getName();
while (true) {
lock.lock();
try {
while (resources.size() <= 0) {
System.out.println(threadName + " 当前仓库没有产品,请稍等...");
try {
// 消费者进入阻塞状态,等待生产者唤醒
removeCondition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 消费数据
int size = resources.size();
for (int i = 0; i < size; i++) {
Integer remove = resources.remove();
System.out.println(threadName + " 当前消费产品编号为:" + remove);
}
// 唤醒生产者
addCondition.signal();
} finally {
lock.unlock();
}
}
}
}
public void test() {
new Thread(new Producer(100), "producer").start();
TimeUnit.SECONDS.sleep(2);
new Thread(new Consumer(), "consumer").start();
}
public static void main(String[] args) throws InterruptedException {
new ProducerConsumerTest(10).test();
}
}
与 synchronized 相比 ReentrantLock 最大的优势就是能获取申请锁的结果是成功还是失败,并且申请锁的过程中支持中断,加锁以后可以主动退出(unlock)。
volatile 线程可见
volatile关键字修饰的成员变量可以保证在不同线程之间的可见性,即一个线程修改了某个变量的值,新的值对其他线程来说是立即可见的。
CPU高速缓存:
计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在CPU里面就有了高速缓存。
当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。
在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存,如果一个变量是被多个线程同时访问的共享变量,该变量就会同时存在于不同CPU缓存当中,就可能存在缓存不一致的问题。
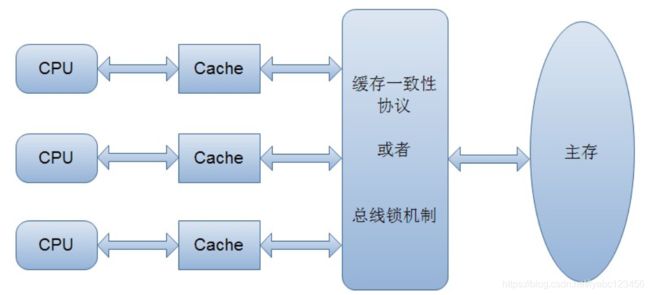
因此为了解决缓存一致性问题,有两种方案:一种是加同步锁, 另一种是通过缓存一致性协议(MESI)。由于加锁会导致锁住CPU的过程中其他CPU无法访问该内存,性能较差,因此出现了缓存一致性协议方案:
当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
Java内存模型(JMM)规定所有的变量都是存在主存当中(类似于前面说的物理内存),每个线程都有自己的工作内存(类似于前面的高速缓存)。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。因此Java内存当中也存在缓存一致性问题,而volatile关键字就是Java用来解决缓存一致性问题的方案。
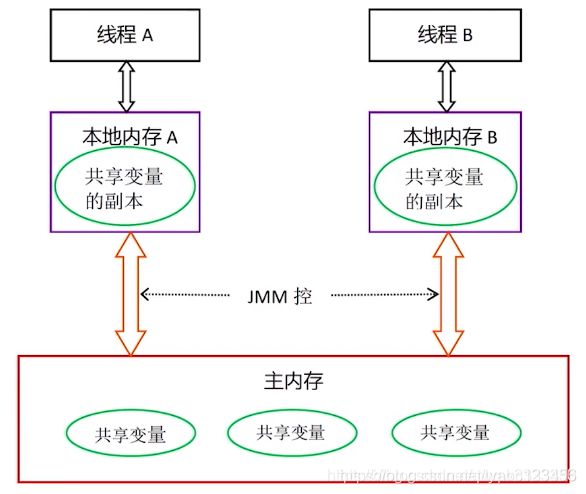
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
- 可见性:保证在不同线程间可见,当变量在每次被线程访问时,都强迫从共享内存重新读取该成员的值,当成员变量值每次发生变化时,又强迫将其变化的值重新写入共享内存。
- 有序性:禁止指令重排序。
注意volatile不能保证原子性,即不能解决非原子操作的线程安全。它的性能不及原子类高。
关于原子性、可见性、有序性
在多线程中这三点是保证线程并发安全的正确性的关键。
原子性:
原子性的含义:一个操作或多个操作要么全部执行完毕,要么都不执行,且执行过程不被任何因素打断。
在Java中,只有对基本数据类型的变量的读取和赋值操作是原子性操作,即这些操作是不可被中断的,要么执行,要么不执行。
x = 10; //语句1
y = x; //语句2
x++; //语句3
x = x + 1; //语句4
上面代码中,只有语句1是原子性操作,其他都是非原子性操作,语句2包含了两个操作:读取x的值和将x的值写入工作内存(赋值给y), 虽然读取x是原子性的,但是合起来就不是原子性了,语句3和语句4都会执行三个操作:读取x的值、对x的值进行加1操作、新的x值写入工作内存,也不是原子性操作。
注意,volatile不能保证原子性
volatile int count
public void increment() {
//其他线程可见
count =5
//非原子操作,其他线程不可见
count=count+1;
count++;
}
既然volatile不能保证原子性, 那如果保证安全性呢?可以通过前面提到的synchronized和ReentrantLock来进行同步加锁保证。由于加锁能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证安全性。可见单独使用volatile并不能完全的保证线程安全,要配合同步锁的使用才能完美的实现。
可见性:
可见性的含义:当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
在Java中,volatile保证了这一点,当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
对于同步锁synchronized和ReentrantLock等,在同步代码块释放锁之前会将对变量的修改刷新到主存当中,因此可以保证可见性。
有序性:
有序性的含义:程序执行的顺序按照代码的先后顺序执行。
通常来说这无可非议,但在JVM中真正的执行顺序可能不一定完全等价于代码中的顺序,发生这种执行顺序和代码顺序不一致的情况时,被称为指令重排序(Instruction Reorder)。
指令重排序:简单的理解就是,在Java内存模型中,为了提高程序运行效率,允许编译器和处理器对指令进行重排序优化,重排序的结果是不保证语句的执行顺序与代码中的顺序一致,但能保证程序最终执行结果和代码顺序执行的结果是一致的。
比如下面代码:
int i = 0;
boolean flag = false;
i = 1; //语句1
flag = true; //语句2
可能重排序之后,语句2优先于语句1执行,这对代码的最终执行结果没有影响。但是如果遇上多线程访问,就可能有问题了。
比如下面代码:
//线程1:
context = loadContext(); //语句1
inited = true; //语句2
//线程2:
while(!inited ){
sleep()
}
doSomethingWithContext(context);
上面代码中,由于语句1和语句2没有数据依赖性,因此可能会被重排序。假如发生了重排序,在线程1执行过程中先执行语句2,而此是线程2会以为初始化工作已经完成,那么就会跳出while循环,去执行doSomethingWithContext(context)方法,而此时context并没有被初始化,就会导致程序出错。
Java的volatile关键字禁止了重排序这一点,而同步锁synchronized和ReentrantLock等本身就是保证线程按顺序访问资源的,自然具备有序性。
补充: happens-before 原则
Java内存模型具备一些先天的“有序性”,即不需要通过任何手段就能够得到保证的有序性,这个通常也称为 happens-before 原则。如果两个操作的执行次序无法从happens-before原则推导出来,那么它们就不能保证它们的有序性,虚拟机可以随意地对它们进行重排序。
happens-before总共有8条原则(《深入理解Java虚拟机》):
- 程序次序规则: 一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
- 锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
可见volatile是其中的基本原则之一。
volatile使用场景,既然volatile不保证原子性,所以假如你要单独使用它,尽量用在只有原子性(纯粹的赋值读取操作)当中:
状态标记:
volatile boolean flag = false;
while(!flag){
doSomething();
}
public void setFlag() {
flag = true;
}
volatile boolean inited = false;
//线程1:
context = loadContext();
inited = true;
//线程2:
while(!inited ){
sleep()
}
doSomethingWithContext(context);
双重检测:
class Singleton{
private volatile static Singleton instance = null;
private Singleton() {
}
public static Singleton getInstance() {
if(instance==null) {
synchronized (Singleton.class) {
if(instance==null)
instance = new Singleton();
}
}
return instance;
}
}
Atomic 原子类家族
原子类家族,AtomicInteger 和 AtomicBoolean 等等,位于 java.util.concurrent.atomic 包下面的若干类AtomicXXX类。原子类内部包装了 CAS 操作,通过CAS来保证同步,无需加锁(号称无锁),提高了性能。
CAS概念:
CAS 是 Compare-and-swap(比较与替换) 的简写,是一种有名的 无锁算法,简单来说,就是指在set之前先比较该值有没有变化,只有在没变的情况下才对其赋值。
比较和替换是使用一个期望值和一个变量的当前值进行比较,如果当前变量的值与我们期望的值相等,就使用一个新值替换当前变量的值。CAS操作可以说是JAVA并发框架的基础,整个框架的设计都是基于CAS操作的。缺点是比较花费CPU资源,即使没有任何资源用也会做一些无用功。
在java中,主要是 Unsafe 类,因为所有的 CAS 操作都是它来实现的,它有几个方法compareAndSwapObject、compareAndSwapInt、compareAndSwapLong都是用来进行原子操作的,即线程安全的。
前面 volatile 无法保证的原子性,用原子类操作即可方便的实现,比如 i++之类的操作:
//# 1构建对象
AtomicInteger a = new AtomicInteger(1);
//#2 调用Api
int previous = a.getAndIncrement(); //a++, 等价getAndAdd(1), 返回操作之前的值
int previous = a.getAndDecrement(); //a--, 等价getAndAdd(-1), 返回操作之前的值
int after = a.incrementAndGet(); //++a, 等价addAndGet(1), 返回操作之后的值
int after = a.decrementAndGet(); //--a, 等价addAndGet(-1), 返回操作之后的值
int previous = a.getAndAdd(2); // a += 2, 返回操作之前的值
int after = a.addAndGet(2);// a += 2, 返回操作之后的值
int previous = a.getAndSet(2);// a = 2, 返回操作之前的值
a.set(2);// a = 2
boolean success = a.compareAndSet(2, 3); // 若 a == 2, 则执行 a = 3, 返回true, 若 a != 2, 返回false
原子类的CAS操作都是基于 Unsafe 类实现的:
private static final sun.misc.Unsafe U = sun.misc.Unsafe.getUnsafe();


在getAndAddInt方法中调用了compareAndSwapInt方法判断条件是否满足,不满足就一直do-while循环,不停的把当前内存的值和寄存器中的值做比较。自旋的设计能够有效避免线程因阻塞-唤醒带来的系统资源开销。
原子类-自旋:

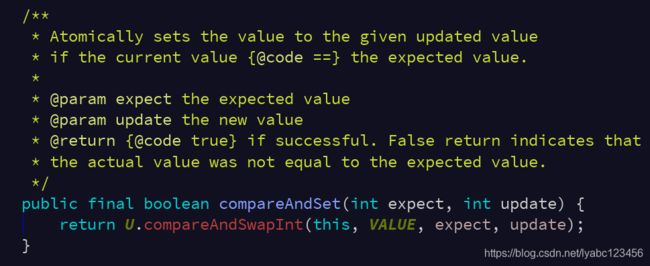
compareAndSwapInt是一个native方法:
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
关于compareAndSet的含义:判断变量的当前值如果与期望值expect相等,那么就把update的值赋值给当前变量,并返回true,否则如果当前值与期望值expect不相等,直接返回false。
下面是一个使用 AtomicBoolean 类实现 lock() 方法的例子:

这个类中有一个compareAndSet()方法,它使用一个期望值false和AtomicBoolean实例locked的值比较,若两者相等,则使用一个新值true替换原来locked的值。即如果locked的值为false,则修改为true。操作成功,compareAndSet()返回true,否则,返回false。
通过AtomicBoolean 我们可以实现开发中常见的保证某个逻辑(如初始化)只执行依次的安全性。
向用户账号增加余额的例子:
class Bank {
private AtomicInteger account = new AtomicInteger(100);
public AtomicInteger getAccount() {
return account;
}
public void save(int money) {
account.addAndGet(money);
}
}
锁适合写操作多的场景,先加锁可以保证写操作时数据正确。原子类适合读操作多的场景,不加锁的特点能够使其读操作的性能大幅提升。 因为原子类在写入数据的 是通过do-while循环实现。在并发量大的时候,相比原子类的自旋, 加锁的性能会更高。
ThreadLocal 本地副本
ThreadLocal 是从不共享变量的角度来保证线程安全的, 如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,副本之间相互独立,这样每一个线程都是对自己的变量副本进行修改,而不会影响其他线程。
其实ThreadLocal实现的是一种线程级别的全局变量,每个线程持有独立的变量副本,本质上是一种数据隔离。由于是数据隔离的,自己访问自己的变量,本身就是线程安全的,所以不存在什么同步问题,也并不是主要为了来解决共享资源的同步问题的,这与synchronized实现多线程访问共享资源的同步有本质的不同。
测试代码:
private static final ThreadLocal<String> STR_THREAD_LOCAL = new ThreadLocal<>();
private void testThreadLocal() throws InterruptedException {
Log.e(TAG, "main thread ThreadLocal.set() called ====================");
STR_THREAD_LOCAL.set("main thread value");
new Thread() {
@Override
public void run() {
Log.e(TAG, "thread 1 ThreadLocal.get(): " + STR_THREAD_LOCAL.get());
STR_THREAD_LOCAL.set("thread 1 value");
Log.e(TAG, "thread 1 ThreadLocal.set() called ====================");
Log.e(TAG, "thread 1 ThreadLocal.get(): " + STR_THREAD_LOCAL.get());
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}.start();
Thread.sleep(1000);
Log.e(TAG, "main thread ThreadLocal.get(): " + STR_THREAD_LOCAL.get());
new Thread() {
@Override
public void run() {
Log.e(TAG, "thread 2 ThreadLocal.get(): " + STR_THREAD_LOCAL.get());
STR_THREAD_LOCAL.set("thread 2 value");
Log.e(TAG, "thread 2 ThreadLocal.set() called ====================");
Log.e(TAG, "thread 2 ThreadLocal.get(): " + STR_THREAD_LOCAL.get());
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}.start();
Thread.sleep(1000);
Log.e(TAG, "main thread ThreadLocal.get(): " + STR_THREAD_LOCAL.get());
}
输出:
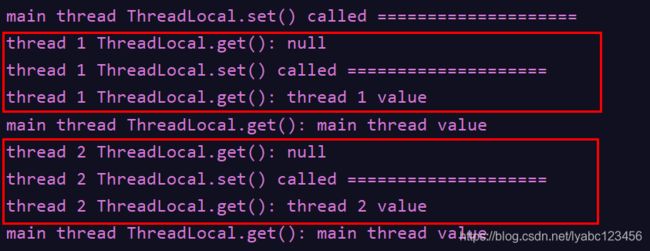
同一个ThreadLocal对象在不同线程中都可以访问,但是每个线程中只能获取到它在当前线程中设置的值,不能获取在其他线程中给它设置的值。
ThreadLocal实现原理
public class ThreadLocal<T> {
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
//此方法可以被子类覆写,返回初始化的值
protected T initialValue() {
return null;
}
}
ThreadLocal是一个可以接受泛型的类,泛型类型就是要保存的变量的类型。主要看它的set和get方法,在set方法中会先尝试获取一个ThreadLocalMap对象,这个对象是绑定到当前线程Thread.currentThread()中的,如果这个map有就设置值,没有创建一个并设置值。
public class Thread implements Runnable {
...
ThreadLocal.ThreadLocalMap threadLocals = null;
}
每个线程类中有一个threadLocals对象,它是一个ThreadLocalMap,如果第一次访问这个变量初始值为null, 所以在ThreadLocal的set方法中判断getMap == null时,调用createMap直接new了一个ThreadLocalMap对象,赋值给当前线程。然后将value值存储到这个Map当中。
ThreadLocalMap是一个类似HashMap的可以存储key-value的ThreadLocal内部类:
public class ThreadLocal<T> {
static class ThreadLocalMap {
//继承弱引用类
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
//初始化的容量
private static final int INITIAL_CAPACITY = 16;
//保存键值对的数组
private Entry[] table;
//容量
private int size = 0;
//下次扩容大小
private int threshold; // Default to 0
}
}
它的Entry类是继承的WeakReference弱引用类,它的key是一个ThreadLocal,value是用户设置的值,这个key采用弱引用,方便GC。
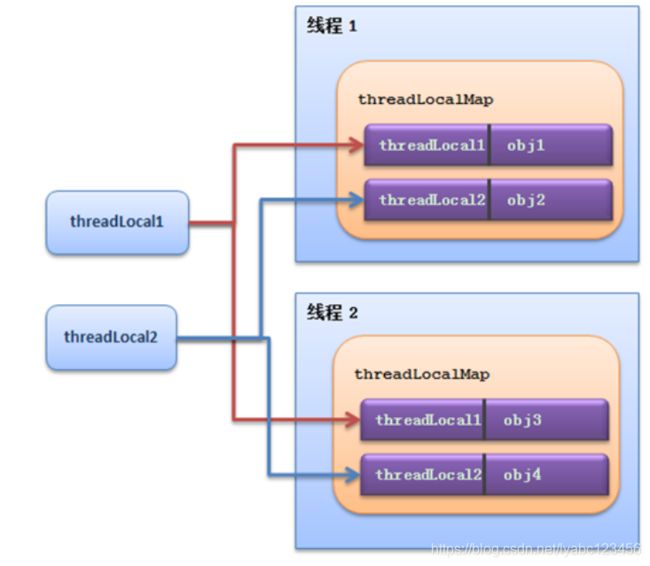
所以,Thread持有ThreadLocal的内部类ThreadLocalMap对象,而ThreadLocalMap是以ThreadLocal对象为key的Map结构,它们的关系如下:

ThreadLocal的get方法中主要是从map获取值,如果第一次访问get, map为空,就调用setInitialValue方法,setInitialValue方法中的逻辑与set中是一样的,先尝试获取map,没有就创建,用户可以用过覆写initialValue()这个方法来设置一个初始化的值。
ThreadLocal不支持继承: 同一个ThreadLocal变量在父线程中被设置值后,在子线程中是获取不到的。也就是说它是绝对隔离的。如果想要继承,jdk提供了一个 InheritableThreadLocal 类可以使用。
ThreadLocalMap中的内存泄漏
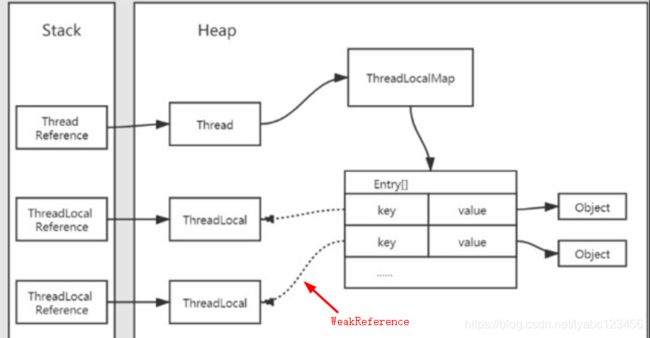
由于Thread 持有 ThreadLocalMap ,二者生命周期是绑定在一起的,所以只要线程一直运行,Map中持有的value变量就会一直占用内存。如果线程没有被正常终止,就可能造成内存泄漏。
为此,TheadLocalMap提供了一个remove方法来移除value:
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
需要在恰当的时机,调用remove方法移除value变量,如页面关闭或线程不再需要对副本变量进行处理等。
另外,由于TheadLocalMap的key ThreadLocal对象是WeakReference弱引用,容易被GC,但是它的value不是弱引用,当ThreadLocal对象被GC回收的 时候,就可能存在key为null且value不为null的情况,这时如果线程也没有终止,就没有办法移除掉这个value值的引用。因为上面的remove方法是需要通过ThreadLocal对象来调用的,而此时ThreadLocal对象已经被回收为null,因此无法用它来调用。
补充:强引用 软引用 弱引用 虚引用
引用强度依次减弱,GC回收依次增强
-
强引用:Java中默认的引用类型,只要该对象的引用还存在就不会被GC。
-
软引用:在JVM发生OOM之前(即内存充足够使用),是不会GC这个对象的;只有内存严重不足的时候才会GC掉。
-
弱引用:内存充足时,会优先回收它的内存。
-
虚引用:最弱的一种引用,在任何时候都可能被GC掉。虚引用必须和引用队列(ReferenceQueue)联合使用。
使用实例,多线程打印日志日期格式化:
public class ThreadLocalDemo {
public static final ThreadLocal<SimpleDateFormat> DATE_FORMAT_THREAD_LOCAL = new ThreadLocal<SimpleDateFormat>() {
@Override
protected SimpleDateFormat initialValue() {
return new SimpleDateFormat("mm:ss", Locale.getDefault());
}
};
public static ExecutorService threadPool = Executors.newFixedThreadPool(16);
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 1000; i++) {
final int finalI = i;
threadPool.submit(new Runnable() {
@Override
public void run() {
String data = new ThreadLocalDemo().date(finalI);
System.out.println(data);
}
});
}
threadPool.shutdown();
}
private String date(int seconds){
Date date = new Date(1000 * seconds);
SimpleDateFormat dateFormat = DATE_FORMAT_THREAD_LOCAL.get();
return dateFormat.format(date);
}
}
这里并没有在每个Runnable当中创建SimpleDateFormat对象,而是使用ThreadLocal在每个线程中保存一个SimpleDateFormat对象副本,由于线程池数设置为固定的,就避免了Runnable中创建大量无用对象。
Android当中ThreadLocal的应用
当我们调用 Looper.myLooper() 时获取当前所在线程的Looper对象,判断是否为主线程 Looper.myLooper() == Looper.getMainLooper(),这里myLooper内部的实现就是使用的 ThreadLocal
public final class Looper {
// sThreadLocal.get() will return null unless you've called prepare().
static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>();
...
public static @Nullable Looper myLooper() {
return sThreadLocal.get();
}
...
}
Looper内部有一个sThreadLocal 保存的是Looper对象,Looper.myLooper()就是调用的ThreadLocal#get()方法获取的,而当调用Looper.prepare()时:
public static void prepare() {
prepare(true);
}
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
内部就是调用ThreadLocal#set()方法保存创建的Looper对象,而且只能保存一次,这就是为啥在子线程中使用Handler前必须先调用Looper.prepare(),因为loop()方法中会检测当前线程的Looper对象是否为空。
通过ThreadLocal机制,每个线程都持有一个Looper变量副本,主线程也一样,在ActivityThread的main函数入口中,会执行Looper.prepareMainLooper(),最终也是调用了prepare方法通过sThreadLocal 设置主线程的Looper对象:
private static Looper sMainLooper; // guarded by Looper.class
public static void prepareMainLooper() {
prepare(false);
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
sMainLooper = myLooper();
}
}
public static Looper getMainLooper() {
synchronized (Looper.class) {
return sMainLooper;
}
}
这里同时将这个对象保存到了全局变量sMainLooper ,以便 Looper.getMainLooper()能方便的获取到主线程的Looper对象。
Semaphore 信号量
Semaphore 是一个计数信号量, 可以用来控制同时访问特定资源的线程数量,适用于那些资源有明确访问数量限制的场景,常用于限流器的实现 。
比如:比较常见的需求就是我们工作中遇到的各种池化资源,例如连接池、对象池、线程池等等。其中,你可能最熟悉数据库连接池,在同一时刻,一定是允许多个线程同时使用连接池的,当然,每个连接在被释放前,是不允许其他线程使用的,当连接达到了限制数量后,后面的线程只能排队等前面的释放了连接才能使用。
理解信号量
信号量最早是由大名鼎鼎的荷兰计算机科学家迪杰斯特拉(Dijkstra,最短路径算法发明者)于 1965 年提出,在这之后的 15 年,信号量一直都是并发编程领域的终结者,直到 1980 年管程被提出来。可以说是解决并发问题的鼻祖。

信号量本来是用来解决操作系统当中进程的互斥问题(mutex), 对临界区的访问实行PV原子操作。
信号量类型有两种实现方式:
- 二进制信号量:初始值只能是0和1
- 计数信号量:初始值可以是任意非负整数S,S > 0 时表示可用资源数,S < 0 时绝对值表示当前等待资源的进程数
信号量中的PV操作(又称PV原语)
信号量是由操作系统来维护的,用户进程只能通过 初始化和两个标准原语(P、V原语) 来访问。
信号量的初始值可指定一个非负整数S,表示空闲资源总数。
信号量S>=0时,S表示可用资源的数量。执行一次P操作意味着请求分配一个资源,因此S的值减1;当S<0时,表示已经没有可用资源,S的绝对值表示当前等待该资源的进程数。请求者必须等待其他进程释放该类资源,才能继续运行。而执行一个V操作意味着释放一个资源,因此S的值加1;若S<0,表示有某些进程正在等待该资源,因此要唤醒一个等待状态的进程,使之运行下去。
- P 操作: S 减 1,若 S >= 0,则进程继续执行;若 S < 0,则该进程被阻塞后进入与该信号相对应的队列中,然后转进程调度。
- V 操作:S 加 1; 若 S > 0,则进程继续执行;若 S <= 0,则从该信号的等待队列中唤醒一等待进程,然后再返回原进程继续执行或转进程调度。
PV操作对于每一个进程来说,都只能进行一次,而且必须成对使用。在PV原语执行期间不允许有中断的发生。
信号量在Java SDK中的实现就是Semaphore类。
Semaphore的常用方法:
| 方法 | 说明 |
|---|---|
acquire() |
获取一个令牌,在获取到令牌、或者被其他线程调用中断之前线程一直处于阻塞状态。 |
release() |
释放一个令牌,唤醒一个获取令牌不成功的阻塞线程。 |
acquire(int permits) |
获取一个令牌,在获取到令牌、或者被其他线程调用中断、或超时之前线程一直处于阻塞状态。 |
acquireUninterruptibly() |
获取一个令牌,在获取到令牌之前线程一直处于阻塞状态(忽略中断) |
tryAcquire() |
尝试获得令牌,返回获取令牌成功或失败,不阻塞线程。 |
tryAcquire(long timeout, TimeUnit unit) |
尝试获得令牌,在超时时间内循环尝试获取,直到尝试获取成功或超时返回,不阻塞线程。 |
hasQueuedThreads() |
等待队列里是否还存在等待线程。 |
getQueueLength() |
获取等待队列里阻塞的线程数。 |
availablePermits() |
返回可用的令牌数量。 |
最主要的是 acquire() 和 release() 方法,分别对应于PV操作中的P操作和V操作。
实例:使用Semaphore 实现停车场提示牌功能。
每个停车场入口都有一个提示牌,上面显示着停车场的剩余车位还有多少,当剩余车位为0时,不允许车辆进入停车场,直到停车场里面有车离开停车场,这时提示牌上会显示新的剩余车位数。
public class SemaphoreTest {
private final static String TAG = SemaphoreTest.class.getSimpleName();
private static ExecutorService executorService = Executors.newCachedThreadPool();
/** 停车场同时容纳10车辆 */
private static Semaphore semaphore = new Semaphore(10);
public static void main(String[] args) {
//模拟100辆车进入停车场
for (int i = 0; i < 100; i++) {
executorService.submit(new Runnable() {
@Override
public void run() {
try {
Log.e(TAG, Thread.currentThread().getName() + "====" + "来到停车场");
if (semaphore.availablePermits() == 0) {
Log.e(TAG, "==== 车位不足,请耐心等待");
}
semaphore.acquireUninterruptibly();//获取令牌尝试进入停车场
Log.e(TAG, Thread.currentThread().getName() + "======<<<<" + "成功进入停车场");
Thread.sleep(new Random().nextInt(10000));//模拟车辆在停车场停留的时间
Log.e(TAG, Thread.currentThread().getName() + "======>>>>" + "驶出停车场");
semaphore.release();//释放令牌,腾出停车场车位
} catch (InterruptedException e) {
e.printStackTrace();
Log.e(TAG, "run: InterruptedException");
}
}
});
}
}
}
实例:使用Semaphore实现一个对象池。
所谓对象池呢,指的是一次性创建出 N 个对象,之后所有的线程重复利用这 N 个对象,当然对象在被释放前,也是不允许其他线程使用的。
class ObjPool<T, R> {
final List<T> pool;
// 用信号量实现限流器
final Semaphore sem;
// 构造函数
ObjPool(int size, T t){
pool = new Vector<T>(){};
for(int i=0; i<size; i++){
pool.add(t);
}
sem = new Semaphore(size);
}
// 利用对象池的对象,调用func
R exec(Function<T,R> func) {
T t = null;
sem.acquire();
try {
t = pool.remove(0);
return func.apply(t);
} finally {
pool.add(t);
sem.release();
}
}
}
// 创建对象池
ObjPool<Long, String> pool = new ObjPool<Long, String>(10, 2);
// 通过对象池获取t,之后执行
pool.exec(t -> {
System.out.println(t);
return t.toString();
});
在ObjPool 的 exec() 方法里实现了限流的功能,首先调用 acquire() 方法,假设对象池的大小是 10,信号量的计数器初始化为 10,那么前 10 个线程调用 acquire() 方法,都能继续执行,而其他线程则会阻塞在 acquire() 方法上。对于通过的线程,分配一个对象 t(通过 pool.remove(0) 实现的),并通过一个回调函数 func执行对象t,执行完回调函数之后,释放并回收对象(通过 pool.add(t) 实现的),同时在finally里调用 release() 方法来更新信号量的计数器。如果此时信号量里计数器的值小于等于 0,那么说明有线程在等待,此时会自动唤醒等待的线程。
关于构造函数:
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
public Semaphore(int permits, boolean fair) {
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
当执行 new Semaphore(10) 实际是创建了一个非公平模式的信号量:
- 非公平模式:按照
acquire的顺序执行,FIFO - 公平模式:抢占式执行
fair参数为false时,默认会创建一个非公平的锁的同步阻塞队列,把初始令牌数量赋值给同步队列的state状态,state的值就代表当前所剩余的令牌数量。
理解非公平模式和公平模式:假设公司厕所有5个坑位,现在有10个人要上厕所,那么同时只能有5个人能够占用,当5个人中的任何一人让开后,剩余等待的另外5个人中又有一个人可以占用了。另外等待的5个人中可以是随机获得优先机会,也可以是按照先来后到的顺序获得机会,这取决于构造Semaphore对象时传入的参数选项。
semaphore.acquire():
1. 当前线程会尝试去同步队列获取一个令牌,获取令牌的过程也就是使用原子PV操作去修改同步队列的
state,获取一个令牌则修改为state = state - 1。
2. 如果state < 0,则代表令牌数量不足,此时会创建一个Node节点加入阻塞队列,挂起当前线程。
3. 如果state >= 0,则代表获取令牌成功。
semaphore.release():
1. 线程会尝试释放一个令牌,释放令牌的过程也就是把同步队列的
state修改为state = state + 1的过程
2. 释放令牌成功之后,同时会唤醒同步队列的所有阻塞节共享节点线程
3. 被唤醒的节点会重新尝试去修改state = state - 1的操作,如果state >= 0则获取令牌成功,否则重新进入阻塞队列,挂起线程。
CountDownLatch 计数器
CountDownLatch是一个减计数器,可以控制多个线程的并发执行。计数器的初始值为线程的数量,调用await()方法的线程会被阻塞,直到计数器 减到 0 的时候,才能继续往下执行。
CountDownLatch的主要方法:
await():调用该方法的线程会被阻塞,直到构造方法传入的 N 减到 0 的时候,才能继续往下执行;countDown():使计数值 减 1;如果计数到达零,则释放所有等待的线程
CountDownLatch的适用场景:
1.模拟并发:让多个线程一起同时开始执行,如模拟发令枪,让多个线程在同一起跑线上执行
public class CountDownLatchTest {
private final static String TAG = CountDownLatchTest.class.getSimpleName();
private final static ExecutorService THREAD_EXECUTOR = Executors.newFixedThreadPool(5);
public static void testCountDown() throws InterruptedException {
CountDownLatch startSignal = new CountDownLatch(1);
for (int i = 0; i < 5; i++) {
THREAD_EXECUTOR.submit(new WorkerRunnable(startSignal));
}
Thread.sleep(2000);
//唤醒等待的5个线程同时执行
startSignal.countDown();
}
public static class WorkerRunnable implements Runnable {
private final CountDownLatch startSignal;
public WorkerRunnable(CountDownLatch startSignal) {
this.startSignal = startSignal;
}
@Override
public void run() {
try {
//等待执行信号
this.startSignal.await();
doWork();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void doWork() {
Log.e(TAG, "doWork: " + Thread.currentThread().getName() + " 执行");
}
}
}
2.单个线程等待多个线程执行完毕,进行汇总合并,如详情页面我们可能会请求多个接口,最终合并到一起进行处理展示
public class CountDownLatchTest {
private final static String TAG = CountDownLatchTest.class.getSimpleName();
private final static ExecutorService THREAD_EXECUTOR = Executors.newFixedThreadPool(5);
public static void testCountDown() throws InterruptedException {
CountDownLatch doneSignal = new CountDownLatch(5);//计数值为5
for (int i = 0; i < 5; i++) {
THREAD_EXECUTOR.submit(new WorkerRunnable(doneSignal));
}
//等待所有线程执行完毕
doneSignal.await();
}
public static class WorkerRunnable implements Runnable {
private final CountDownLatch doneSignal;
public WorkerRunnable2(CountDownLatch doneSignal) {
this.doneSignal = doneSignal;
}
@Override
public void run() {
doWork();
this.doneSignal.countDown();
}
private void doWork() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Log.e(TAG, "doWork: " + Thread.currentThread().getName() + " 执行");
}
}
}
CountDownLatch的缺陷:
CountDownLatch是一次性的,计算器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当CountDownLatch使用完毕后,它不能再次被使用。
CountDownLatch与Thread.join
CountDownLatch的作用就是允许一个或多个线程等待其他线程完成操作,看起来有点类似join() 方法,但其提供了比 join() 更加灵活的API。
- CountDownLatch可以手动控制在n个线程里调用n次countDown()方法使计数器进行减一操作,也可以在一个线程里调用n次执行减一操作。
- join() 的实现原理是不停检查join线程是否存活,如果 join 线程存活则让当前线程永远等待。
BlockingQueue 阻塞队列
BlockingQueue 是 java.util.concurrent 包下的一个接口类,继承Queue接口,Queue又继承了Collection接口。
BlockingQueue 是一个阻塞队列,是线程安全的,主要用于生产者/消费者模型。
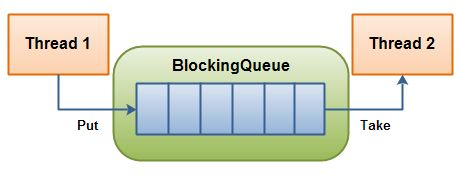
生产者线程不断生产新的对象放入队列,直到达到队列的最大值,消费者线程负责从队列中取不断消费对象。当队列已满时,生产者线程将被阻塞,直到消费者线程对队列进程出队操作,当队列为空时,消费者线程将被阻塞,直到生产者线程对队列进行入队操作。
| 操作 | 抛出异常 | 返回特殊值 | 阻塞 | 超时 |
|---|---|---|---|---|
| 入队/插入元素 | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| 出队/获取元素 | remove() | poll() | take() | poll(time, unit) |
| 检查 | element() | peek() |
BlockingQueue对于不能满足条件的操作,提供了四种处理方式:
- 直接抛异常,抛出异常。如果队列已满,添加元素会抛出IllegalStateException异常;如果队列为空,获取元素会抛出NoSuchElementException异常;
- -返回一个特殊值(null或false);
- 在满足条件之前,无限期的阻塞当前线程,当队列满足条件或响应中断退出;
- 在有限时间内阻塞当前线程,超时后返回失败。
注意,不能向BlockingQueue插入一个空对象,否则会抛出NullPointerException。
BlockingQueue的实现类:
| 实现类 | 说明 |
|---|---|
| ArrayBlockingQueue | 由 数组 实现的 有界阻塞队列,遵循 FIFO 原则。支持公平锁和非公平锁。 |
| LinkedBlockingQueue | 由 链表 实现的 有界阻塞队列,遵循 FIFO 原则。默认和最大长度为Integer.MAX_VALUE。在Executors.newFixedThreadPool()中使用了该队列。 |
| PriorityBlockingQueue | 支持 线程优先级排序 的 无界阻塞队列,默认自然序进行排序。也可以自定义实现compareTo()方法来指定元素排序规则,不能保证同优先级元素的顺序。 |
| DelayQueue | 使用 优先级队列 实现的 延时获取 的 无界阻塞队列。在创建元素时,可以指定多久才能从队列中获取当前元素。只有延时期满后才能从队列中获取元素。在Executors.newScheduledThreadPool()中使用了该队列。 |
| SynchronousQueue | 一个不存储元素的阻塞队列。每一个插入操作必须等待移除操作完成,否则调用插入操作的线程会一直阻塞。支持公平锁和非公平锁。在Executors.newCachedThreadPool()中使用了该队列。 |
| LinkedTransferQueue | 由 链表 实现的 无界阻塞队列。 |
| LinkedBlockingDeque | 由 链表 实现的 双向阻塞队列。队列头部和尾部都可以添加和移除元素,多线程并发时,可以将锁的竞争最多降到一半。 |
ArrayBlockingQueue
ArrayBlockingQueue是一个有边界的阻塞队列,它的内部实现是一个数组。有边界的意思是它的容量是有限的,我们必须在其初始化的时候指定它的容量大小,容量大小一旦指定就不可改变。
ArrayBlockingQueue是以先进先出的方式存储数据,在尾部插入最新的对象,在头部移出对象。
public class ArrayBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
/** The queued items */
final Object[] items;
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
}
通过构造函数可以看到ArrayBlockingQueue内部是通过一个ReentrantLock重入锁和一个对象数组实现的,并且使用了newCondition来实现线程同步控制,默认是非公平锁,且必须传入一个大于0的初始化的容量大小,否则会抛异常。
使用ArrayBlockingQueue实现生产者消费者的例子:
public class BlockingQueueExample {
public static void main(String[] args) throws Exception {
BlockingQueue queue = new ArrayBlockingQueue(1024);
Producer producer = new Producer(queue);
Consumer consumer = new Consumer(queue);
new Thread(producer).start();
new Thread(consumer).start();
Thread.sleep(4000);
}
}
public class Producer implements Runnable{
protected BlockingQueue queue = null;
public Producer(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
try {
queue.put("1");
Thread.sleep(1000);
queue.put("2");
Thread.sleep(1000);
queue.put("3");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public class Consumer implements Runnable{
protected BlockingQueue queue = null;
public Consumer(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
try {
System.out.println(queue.take());
System.out.println(queue.take());
System.out.println(queue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
LinkedBlockingQueue
LinkedBlockingQueue阻塞队列大小的配置是可选的,如果我们初始化时指定一个大小,它就是有边界的,如果不指定,也可以说它是“无边界”的,这是因为它的默认大小是Integer.MAX_VALUE的容量 ,对于实际开发就是无界的。
BlockingQueue<String> unbounded = new LinkedBlockingQueue<String>();
BlockingQueue<String> bounded = new LinkedBlockingQueue<String>(1024);
bounded.put("Value");
String value = bounded.take();
public class LinkedBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
static class Node<E> {
E item;
Node<E> next;
Node(E x) { item = x; }
}
transient Node<E> head;
private transient Node<E> last;
/** Lock held by take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** Wait queue for waiting takes */
private final Condition notEmpty = takeLock.newCondition();
/** Lock held by put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** Wait queue for waiting puts */
private final Condition notFull = putLock.newCondition();
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
}
由LinkedBlockingQueue的域可以看出,它使用链表存储元素。线程间的通信也是使用ReentrantLock和Condition实现的,与ArrayBlockingQueue不同的是,LinkedBlockingQueue在入队和出队操作时分别使用两个锁putLock和takeLock,提高入队和出队操作的效率,提高了并发的吞吐量。
LinkedBlockingQueue和ArrayBlockingQueue对比
- 存储容量上的区别:ArrayBlockingQueue由于其底层基于数组,并且在创建时指定存储的大小,在完成后就会立即在内存分配固定大小容量的数组元素,因此其存储通常有限,故其是一个“有界“的阻塞队列;而LinkedBlockingQueue可以由用户指定最大存储容量,也可以无需指定,如果不指定则最大存储容量将是Integer.MAX_VALUE,即可以看作是一个“无界”的阻塞队列,由于其节点的创建都是动态创建,并且在节点出队列后可以被GC所回收,因此其具有灵活的伸缩性。但是由于ArrayBlockingQueue的有界性,因此其能够更好的对于性能进行预测,而LinkedBlockingQueue由于没有限制大小,当任务非常多的时候,不停地向队列中存储,就有可能导致内存溢出的情况发生。
- 并行吞吐量上的区别:ArrayBlockingQueue中在入队列和出队列操作过程中,使用的是同一个lock,所以即使在多核CPU的情况下,其读取和操作的都无法做到并行,而LinkedBlockingQueue的读取和插入操作所使用的锁是两个不同的lock,它们之间的操作互相不受干扰,因此两种操作可以并行完成,故LinkedBlockingQueue的吞吐量要高于ArrayBlockingQueue。
PriorityBlockingQueue
PriorityBlockingQueue是带优先级的无界阻塞队列,每次出队都返回优先级最好或者最低的元素,内部是平衡二叉树最小根堆的实现。
补充:
平衡二叉树(Balanced Binary Tree)又被称为AVL树(有别于AVL算法),且具有以下性质:它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。 这个方案很好的解决了二叉查找树退化成链表的问题,把插入,查找,删除的时间复杂度最好情况和最坏情况都维持在O(logN)。但是频繁旋转会使插入和删除牺牲掉O(logN)左右的时间,不过相对二叉查找树来说,时间上稳定了很多。
堆结构是用数组实现的二叉树,数组下标可以表明元素节点的位置,所以省去指针的内存消耗
最小堆: 父节点的值小于或等于子节点的值
最大堆: 父节点的值大于或等于子节点的值
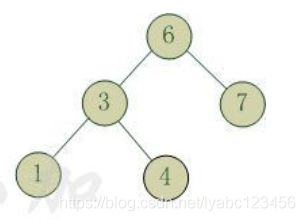
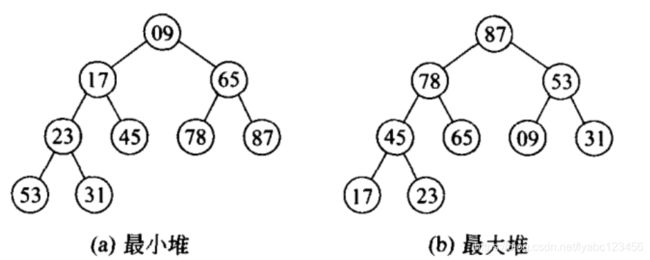
PriorityBlockingQueue构造函数:
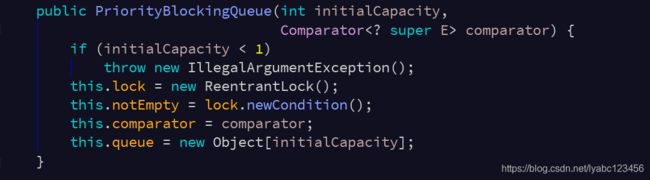
PriorityBlockingQueue内部也是通过ReentrantLock和Condition实现,使用数组存储元素,并且使用元素的compareTo方法进行比较来确定元素的优先级,队列元素必须实现Comparable接口。
PriorityBlockingQueue使用示例:
public class PriorityElement implements Comparable<PriorityElement> {
private int priority;//定义优先级
PriorityElement(int priority) {
//初始化优先级
this.priority = priority;
}
@Override
public int compareTo(PriorityElement o) {
//按照优先级大小进行排序
return priority >= o.getPriority() ? 1 : -1;
}
public int getPriority() {
return priority;
}
public void setPriority(int priority) {
this.priority = priority;
}
@Override
public String toString() {
return "PriorityElement [priority=" + priority + "]";
}
}
public class PriorityBlockingQueueExample {
public static void main(String[] args) throws InterruptedException {
PriorityBlockingQueue<PriorityElement> queue = new PriorityBlockingQueue<>();
for (int i = 0; i < 5; i++) {
Random random = new Random();
PriorityElement ele = new PriorityElement(random.nextInt(10));
queue.put(ele);
}
while (!queue.isEmpty()) {
System.out.println(queue.take());
}
}
}
输出:
PriorityElement [priority=3]
PriorityElement [priority=4]
PriorityElement [priority=5]
PriorityElement [priority=8]
PriorityElement [priority=9]
输出结果是按照有小到大排列的。
DelayQueue
DelayQueue的特点就是插入Queue中的数据可以按照自定义的delay时间进行排序,只有delay小于0的元素才能够被取出。即其中的对象只能在其到期时才能从队列中取走。
可以运用在以下应用场景:
- 缓存设计:可以用DelayQueue保存缓存元素,缓存元素设置有效期,使用一个线程循环查询DelayQueue,一旦缓存有效期到期,就能从DelayQueue中获取到元素并从缓存中移出。
- 定时任务:如请求或连接超时响应机制,使用DelayQueue保存将要执行的任务和执行时间,一旦从DelayQueue中能获取到任务就开始执行,表示到了超时时间了,从比如TimerQueue就是使用DelayQueue实现的。
- 订单业务:下订单后多长时间内未付款就自动取消订单
public class DelayQueue<E extends Delayed> extends AbstractQueue<E> implements BlockingQueue<E> {
private final transient ReentrantLock lock = new ReentrantLock();
private final PriorityQueue<E> q = new PriorityQueue<E>();
private Thread leader;
private final Condition available = lock.newCondition();
public DelayQueue() {}
}
DelayQueue内部使用ReentrantLock和PriorityQueue优先级队列来实现,其中的元素必须实现一个 Delayed 的接口:
public interface Delayed extends Comparable<Delayed> {
//返回对象的剩余延时时间,返回0或负数表示对象已经到期,可以take()方法来获取
long getDelay(TimeUnit unit);
}
这其实是一个Comparable接口。
DelayQueue使用示例:
public class DelayedItem implements Delayed {
private String name;
private long availableTime;
public DelayedItem(String name, long delayTime) {
this.name = name;
//availableTime = 当前时间 + delayTime
this.availableTime = delayTime + System.currentTimeMillis();
}
@Override
public long getDelay(TimeUnit unit) {
//判断availableTime是否大于当前系统时间
return availableTime - System.currentTimeMillis();
}
@Override
public int compareTo(Delayed other) {
//compareTo用在DelayedUser的排序
return (int) (this.availableTime - ((DelayedItem) other).getAvailableTime());
}
public long getAvailableTime() {
return availableTime;
}
public String getName() {
return name;
}
}
public class DelayedQueueTest {
private final static String TAG = DelayedQueueTest.class.getSimpleName();
public static void test() {
DelayQueue<DelayedItem> delayQueue = new DelayQueue<>();
delayQueue.add(new DelayedItem("ccc", 3000));
delayQueue.add(new DelayedItem("aaa", 1000));
delayQueue.add(new DelayedItem("bbb", 2000));
try {
while (!delayQueue.isEmpty()) {
DelayedItem item = delayQueue.take();
Log.e(TAG, "test: " + item.getName());
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
输出:

其中调用take方法会阻塞住调用线程,直到1s、2s、3s后才分别输出。
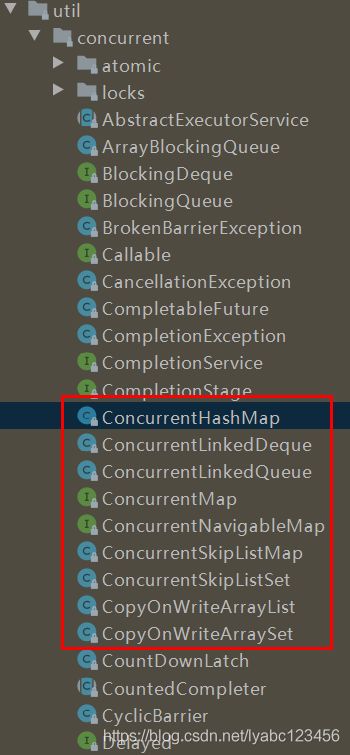
Concurrent 线程安全的集合类
在 java.util.concurrent包下面提供了很多Concurrent开头的集合类,都是线程安全的:
ConcurrentHashMap
ConcurrentHashMap是使用比较常见的,相比于HashMap它能保证线程安全。
与HashTable相比,HashTable也是线程安全的集合类,但是HashTable 是对整个对象加锁,HashTable源码当中的几乎每个操作方法像get()、put()、size() 等都加了 synchronized 关键字,也就是对几乎每个操作方法都加了锁,很显然,虽然简单粗暴的保证了线程安全,但效率低下。
HashTable的问题:
- 大锁:对整个对象加锁
- 长锁:直接对整个方法加锁
- 读写锁共用:只有一把锁,从头锁到尾
ConcurrentHashMap的做法:
- 小锁:分段锁(JDK7),桶点锁(JDK8)
- 短锁:先尝试获取,失败再加锁
- 读写锁分离:读失败再加锁,
volatile读CAS写
ConcurrentHashMap 将HashMap数据结构使用分段锁的思想进行细分化。在jdk1.7及以前,是这样实现的:
比如容器HashMap中存在1000个元素,各个元素都放置到HashMap数组的链表或者红黑树中,最后得到的数组大小可能只有128,ConcurrentHashMap会根据这128个数组,对其分段,比如以16个数组为一段,可以分为8段。在实际获取元素,添加元素时,会根据元素的索引找到该元素所处的段位,然后只将该段位锁住,并不影响其他段位的数据操作。这样如果按照HashTable的效率为基本单位来计算,ConcurrentHashMap在jdk1.7及以前的效率会提高8倍,当然数据量越大,提高的效率将越多。
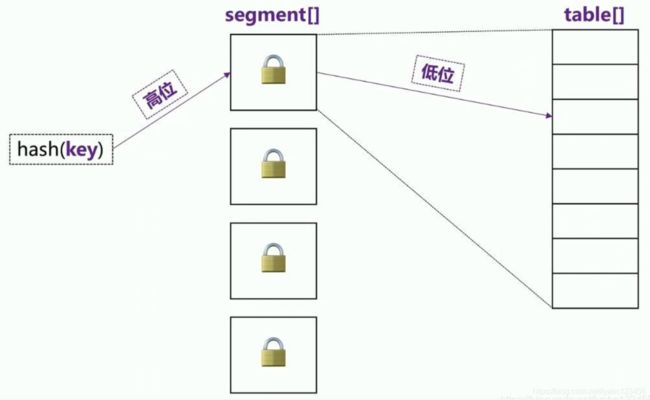
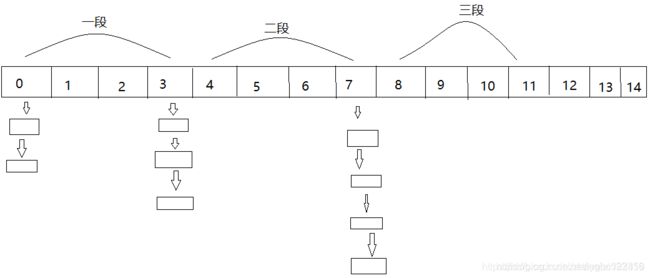
JDK1.7之前, 分段锁其实相当于一个 segment 里对应一个小 HashMap,其中segment 继承了 ReentrantLock 重入锁。
JDK1.8 之后,ConcurrentHashMap 抛弃了大的分段锁,将锁的粒度更加细分化,直接以每个数组索引为锁来进行实现。比如HashMap数组中长度有128,那么就会存在128个锁将每个索引锁住。这样相比于JDK1.7之前在效率上有了很大的改进。
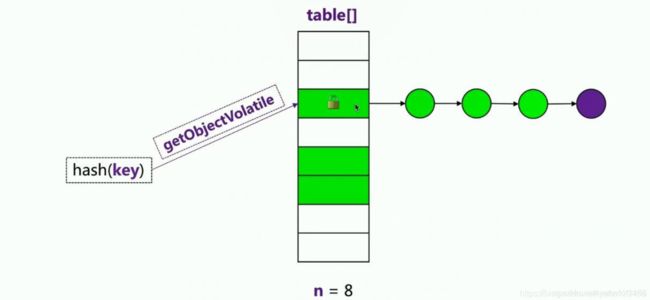
ConcurrentHashMap 在Node数组初始化时的线程安全保障技巧:
- volatile变量(sizeCtl): 它是一个标记位,用来告诉其他线程这个坑位有没有人在,其线程间的可见性由volatile保证。
- CAS操作: CAS操作保证了设置sizeCtl标记位的原子性,保证了只有一个线程能设置成功
存储K-V的Node[K, V] table数组初始值是空的,第一次使用时才初始化,而 这个 table 正是 volatile 的



ConcurrentHashMap 在 put操作的线程安全保障技巧:
- 减小锁粒度: 将Node链表的头节点作为锁,若在默认大小16情况下,将有16把锁,大大减小了锁竞争(上下文切换),在理想情况下线程的put操作都为并行操作。同时直接锁住头节点,保证了线程安全。
- Unsafe的getObjectVolatile方法: 此方法确保获取到的值为最新
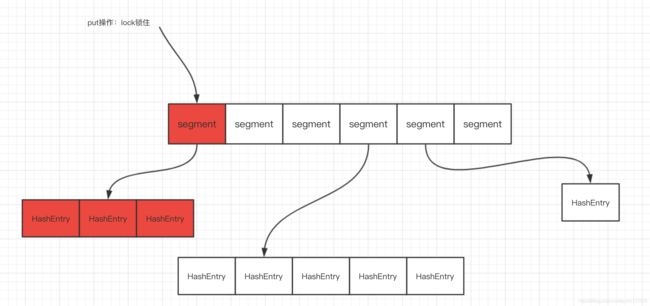

由于其减小了锁的粒度,若Hash完美不冲突的情况下,可同时支持n个线程同时put操作,n为Node数组大小,在默认大小16下,可以支持最大同时16个线程无竞争同时操作且线程安全。当hash冲突严重时,Node链表越来越长,将导致严重的锁竞争,此时会进行扩容,将Node进行再散列。
ConcurrentHashMap扩容操作的线程安全:
ConcurrentHashMap运用各类CAS操作,将扩容操作的并发性能实现最大化,在扩容过程中,就算有线程调用get查询方法,也可以安全的查询数据,若有线程进行put操作,还会协助扩容,利用sizeCtl标记位和各种volatile变量进行CAS操作达到多线程之间的通信、协助,在迁移过程中只锁一个Node节点,即保证了线程安全,又提高了并发性能。
ConcurrentHashMap统计容器大小的线程安全:
- CAS方式直接递增: 在线程竞争不大的时候,直接使用CAS操作递增baseCount值即可,这里说的竞争不大指的是CAS操作不会失败的情况
- 分而治之桶计数: 若出现了CAS操作失败的情况,则证明此时有线程竞争了,计数方式从- CAS方式转变为分而治之的桶计数方式

可以看到,先是一堆CAS操作,然后调用sumCount,
用到了 CounterCell 进行分段统计,CounterCell 本身也是 volatile 线程可见性的:

sumCount方法只不过是简单的把各段统计结果相加:
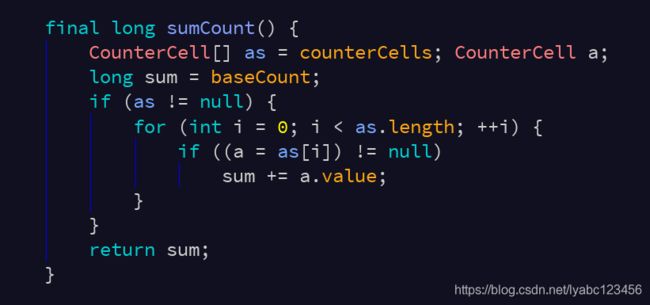
ConcurrentHashMap的get操作的线程安全:
对于get操作,其实没有线程安全的问题,只有可见性的问题,只需要确保get的数据是线程之间可见的即可:

与HashMap的get操作没有太大区别,只不过这里的 table 对象 Node
CopyOnWriteArrayList
CopyOnWriteArrayList是线程安全容器(相对于ArrayList),看名字就知道,它的原理是底层通过复制数组的方式来实现。CopyOnWriteArrayList在遍历的使用不会抛出ConcurrentModificationException异常,并且遍历的时候就不用额外加锁。
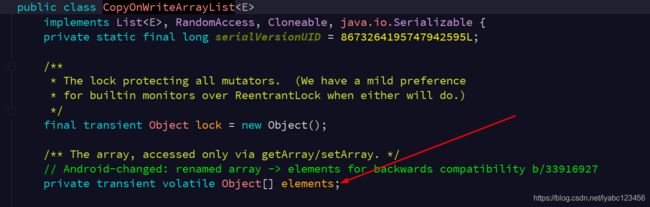
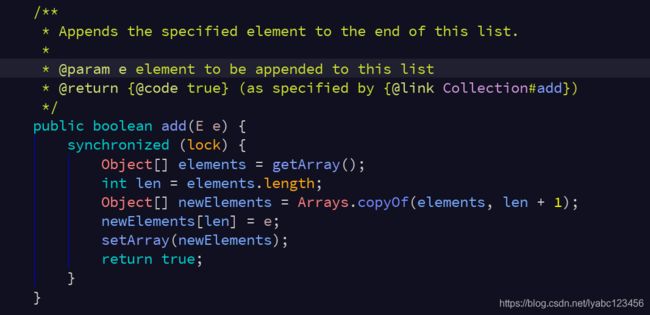
和ArrayList一样,其底层数据结构也是数组,transient保证不被序列化,volatile保证线程可见性和有序性。

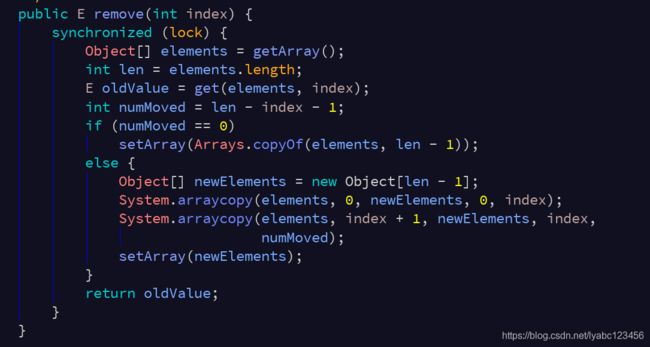
以上是参考Android sdk当中的源码,相比jdk的略有不同,但基本逻辑一致。
可见对于add()、set()、remove()、clear()等修改操作时,都是拷贝原来的数组,复制出一个新数组,修改的操作在新数组中完成,最后将新数组交由array变量指向。
只有写操作加锁,读不会加锁,因为读是直接定位volatile的数组对象中获取,是满足线程可见性的,不存在同步问题。


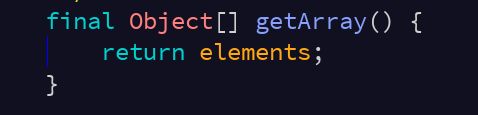
同样为什么CopyOnWriteArrayList在遍历时不用调用者额外加锁的原因,也是因为它在内部的迭代器当中是直接读取访问的这个线程可见的elements数组。
CopyOnWriteArrayList的缺点很明显:
- 内存占用高:如果
CopyOnWriteArrayList要频繁修改数据,每次执行add()、set()、remove()等方法时,内部都会copy一份数组,内存占用率很高。
因为我们知道每次add()、set()、remove()这些增删改操作都要复制一个数组出来。 - 数据一致性风险:CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。比如线程A在对CopyOnWriteArrayList容器的数据迭代过程当中(迭代的是原生数据),线程B对数据进行了修改了(修改的是副本),那么最终线程A迭代出来结果就有可能跟线程B修改后的结果不一致。
Collections.synchronizedxxx方法
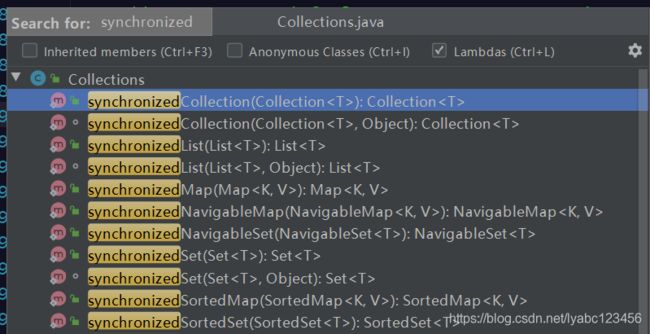
Collections类提供了一些以synchronized开头的方法,可以方便的将普通的非线程安全集合转化为线程安全的集合对象,如Collections.synchronizedMap、Collections.synchronizedList等等。
使用:
ArrayList<String> listNotSafe = new ArrayList<>();
HashMap<String, String> mapNotSafe = new HashMap<>();
List<String> listSafe = Collections.synchronizedList(listNotSafe);
Map<String, String> mapSafe = Collections.synchronizedMap(mapNotSafe);
为啥这样就能线程安全了,看一下内部的实现

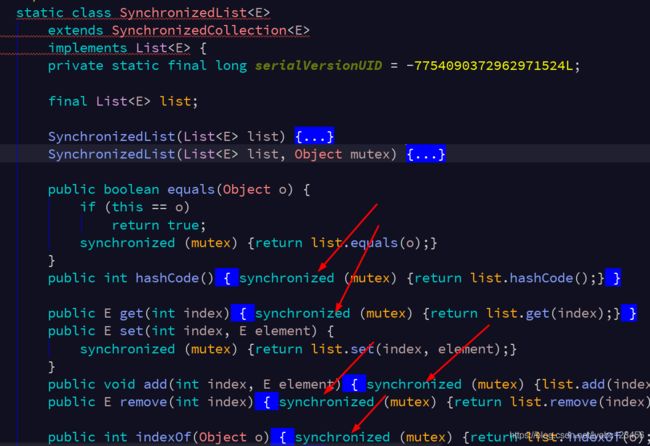

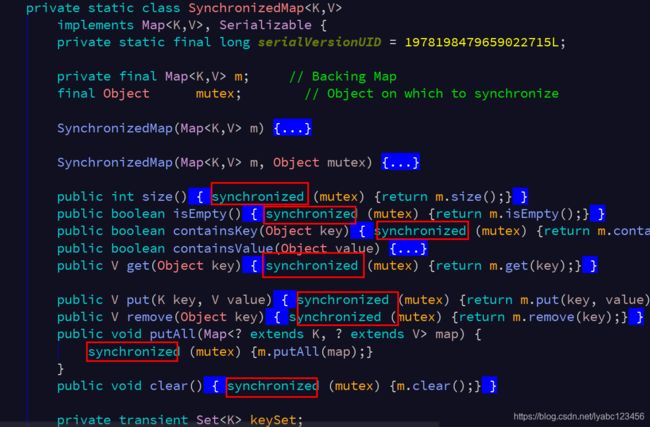
其实内部就是利用装饰者模式又包装了一层,在这一层当中的每个方法调用前都加了synchronized同步关键字,没错,就是这么简单粗暴。缺点也很明显了,性能效率太低,在追求不太高的场景下倒是很方便。比如如果一个第三方SDK返回的一个普通List,想把它变成同步安全的,这应该是最快的。
ReadLock/WriteLock 读写锁
java中读写锁的实现是ReentrantReadWriteLock类,它位于java.util.concurrent.locks包下面,是Lock的另一种实现方式。
我们已经知道了ReentrantLock是一个排他锁,同一时间只允许一个线程访问,而ReentrantReadWriteLock允许多个读线程同时访问,但不允许写线程和读线程、写线程和写线程同时访问。
相对于排他锁,提高了并发性。在实际应用中,大部分情况下对共享数据(如缓存)的访问都是读操作远多于写操作,这时ReentrantReadWriteLock能够提供比排他锁更好的并发性和吞吐量。
public class ReentrantReadWriteLock implements ReadWriteLock {
private final ReentrantReadWriteLock.ReadLock readerLock;
private final ReentrantReadWriteLock.WriteLock writerLock;
final Sync sync;
public ReentrantReadWriteLock() {
this(false);
}
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
public ReentrantReadWriteLock.WriteLock writeLock() { return writerLock; }
public ReentrantReadWriteLock.ReadLock readLock() { return readerLock; }
abstract static class Sync extends AbstractQueuedSynchronizer {
...
}
}
实现了ReadWriteLock接口:
public interface ReadWriteLock {
Lock readLock();
Lock writeLock();
}
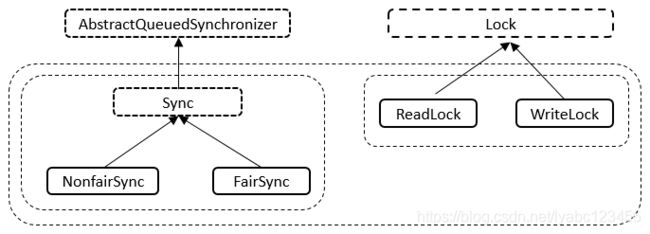
Sync继承自AQS、NonfairSync和FairSync继承自Sync类(通过构造函数传入的布尔值决定要构造哪一种Sync实例);ReadLock和WriteLock实现了Lock接口。读写锁的加锁解锁操作最终都是调用内部类Sync提供的方法。
ReentrantReadWriteLock内部维护了两个锁:
- 读操作锁,称为共享锁(所有线程均可同时获得,并发量高,比如在线文档查看)
- 写操作锁,称为排他锁(同一时刻只有一个线程有权修改资源,比如在线文档编辑)
线程进入读锁的前提条件:没有其他线程的写锁,没有写请求或者有写请求,但调用线程和持有锁的线程是同一个。
线程进入写锁的前提条件:没有其他线程的读锁,没有其他线程的写锁。
所有 ReadWriteLock实现都必须保证 writeLock操作的内存同步效果也要保持与相关 readLock的联系。也就是说,成功获取读锁的线程会看到写入锁之前版本所做的所有更新。
ReentrantReadWriteLock支持以下重要特性:
- 公平选择性:支持公平锁和非公平锁(默认)的获取锁的方式;
- 可重入性:读写锁都支持线程重入
- 锁降级:写锁能够降级成为读锁。其实现方式是:先获取写入锁,然后获取读取锁,最后释放写入锁。但是,从读取锁升级到写入锁是不允许的。
- 可中断:读锁和写锁都支持锁获取期间的中断;
- Condition支持:写入锁提供了一个 Conditon 实现;读取锁不支持 Conditon。
示例一:利用重入来执行升级缓存后的锁降级
class CachedData {
Object data;
volatile boolean cacheValid; //缓存是否有效
ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
void processCachedData() {
rwl.readLock().lock(); //获取读锁
//如果缓存无效,更新cache;否则直接使用data
if (!cacheValid) {
// Must release read lock before acquiring write lock
//获取写锁前须释放读锁
rwl.readLock().unlock();
rwl.writeLock().lock();
// Recheck state because another thread might have acquired
// write lock and changed state before we did.
if (!cacheValid) {
data = ...
cacheValid = true;
}
// Downgrade by acquiring read lock before releasing write lock
//锁降级,在释放写锁前获取读锁
rwl.readLock().lock();
rwl.writeLock().unlock(); // Unlock write, still hold read
}
use(data);
rwl.readLock().unlock(); //释放读锁
}
}
示例二:使用 ReentrantReadWriteLock 来提高 Collection 的并发性
通常在 collection 数据很多,读线程访问多于写线程并且 entail 操作的开销高于同步开销时尝试这么做。
class RWDictionary {
private final Map<String, Data> m = new TreeMap<String, Data>();
private final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
private final Lock r = rwl.readLock(); //读锁
private final Lock w = rwl.writeLock(); //写锁
public Data get(String key) {
r.lock();
try { return m.get(key); }
finally { r.unlock(); }
}
public String[] allKeys() {
r.lock();
try { return m.keySet().toArray(); }
finally { r.unlock(); }
}
public Data put(String key, Data value) {
w.lock();
try { return m.put(key, value); }
finally { w.unlock(); }
}
public void clear() {
w.lock();
try { m.clear(); }
finally { w.unlock(); }
}
}
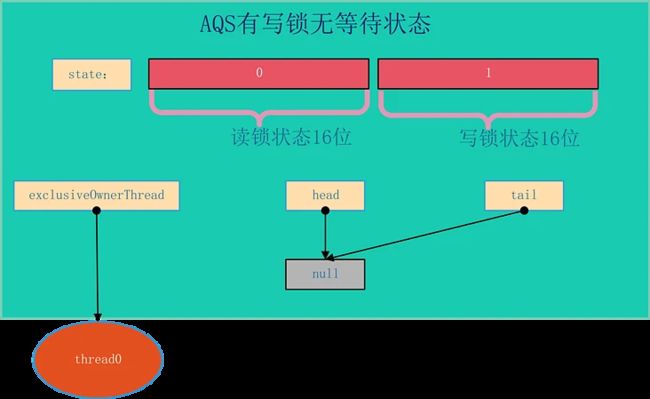
ReentrantReadWriteLock 是基于AQS实现的,它的自定义同步器(继承AQS)需要在同步状态(一个整型变量state)上维护多个读线程和一个写线程的状态,使得该状态的设计成为读写锁实现的关键。
如果在一个整型变量上维护多种状态,就一定需要“按位切割使用”这个变量,读写锁将变量切分成了两个部分,高16位表示读,低16位表示写。
锁的优化
由于线程同步加锁是非常耗费系统开销的操作,还有可能导致死锁,因此为了提高性能,我们必须严格控制使用锁的情况。
总结一些优化锁的方法:
-
长锁不如短锁,尽可能只锁必要部分,不要对线程安全类的所有方法都进行同步,只对那些会改变共享资源方法的进行同步。
-
如果可变类有两种运行环境,单线程环境和多线程环境,则应该为该可变类提供两种版本:线程安全版本和线程不安全版本(没有同步方法和同步块)。在单线程中环境中,使用线程不安全版本以保证性能,在多线程中使用线程安全的版本。
-
只有共享资源的读写访问才需要同步。如果不是共享资源,那么就根本没有同步的必要。(如
ThreadLocal) -
避免共享变量,或共享不可变的资源。只有“变量”才需要同步访问。如果共享的资源是固定不变的,那么就相当于“常量”,线程同时读取常量也不需要同步。如使用final实现不可变量,无需
volatile就能保证线程可见性。 -
减小锁的颗粒度,同步的代码段范围越小越好,可将同步方法改成同步代码块,以便更加精细的控制锁的范围。
-
减少加锁的次数,合并访问相同共享资源的锁,将访问相同的资源的的多次加锁进行合并成只加一次锁,或者将访问相同资源的不同锁对象合并成一个锁对象。
-
读写锁分离,只要有写锁进入才需要做同步处理,但是对于大多数应用来说,读的场景要远远大于写的场景,因此一旦使用读写锁,在读多写少的场景中,就可以很好的提高系统的性能。
-
减少持锁时间, 尽管锁在同一时间只能允许一个线程持有,其它想要占用锁的线程都得在临界区外等待锁的释放,这个等待的时间我们希望尽可能的短。
public void syncMethod(){ noneLockedCode1();//2s synchronized(this){ needLockedMethed();2s } noneLockedCode2();2s } -
锁粗化 ,尽可能的合并处理频繁过短的锁
public void doSomethingMethod() { synchronized (lock) { //do some thing } // ..... // 这是还有一些代码,做其它不需要同步的工作,但能很快执行完毕 // ..... synchronized (lock) { //do other thing } }public void doSomethingMethod() { //进行锁粗化:整合成一次锁请求、释放 synchronized (lock) { //do some thing // 做其它不需要同步但能很快执行完的工作 // do other thing } } -
尽量避免嵌套锁,使用扁平锁替代,避免死锁
-
消除无用锁,能不加锁尽量不加,或使用
volatile代替。
线程死锁
死锁发生的条件
Java发生死锁的根本原因是:在申请锁时发生了交叉闭环申请。即线程在获得了锁A并且没有释放的情况下去申请锁B,这时,另一个线程已经获得了锁B,在释放锁B之前又要先获得锁A,因此闭环发生,陷入死锁循环。
死锁示例代码:
public class DeadLockA extends Thread {
@Override
public void run() {
try{
System.out.println("LockA running");
while(true){
synchronized(Client.obj1){
System.out.println("LockA locked obj1");
//获取obj1后先等一会儿,让LockB有足够的时间锁住obj2
Thread.sleep(100);
System.out.println("LockA trying to lock obj2...");
synchronized(Client.obj2){
System.out.println("LockA locked obj2");
}
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}
public class DeadLockB extends Thread {
@Override
public void run() {
try{
System.out.println("LockB running");
while(true){
synchronized(Client.obj2){
System.out.println("LockB locked obj2");
System.out.println("LockB trying to lock obj1...");
synchronized(Client.obj1){
System.out.println("LockB locked obj1");
}
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}
public class Client {
public static final String obj1 = "obj1";
public static final String obj2 = "obj2";
public static void main(String[] ars) {
new DeadLockA().start();
new DeadLockB().start();
}
}
输出:

如何避免死锁
- 调整申请锁的顺序:当几个线程都要访问共享资源A、B、C 时,保证每个线程都按照同样的顺序去访问他们。
- 调整申请锁的范围:尝试减小锁的申请范围,避免锁的申请发生闭环。
- 避免一个线程同时获取多个锁。避免在一个资源内占用多个 资源,尽量保证每个锁只占用一个资源。
- 尝试使用定时锁,使用
tryLock(timeout)来代替使用内部锁机制。 - 避免同步嵌套的发生,尽量避免在一个对象的同步块内调用另一个对象的同步方法。