监督学习 | SVM 之非线性支持向量机原理
文章目录
- 1. 非线性支持向量机
-
- 1.1 核技巧
- 1.2 核函数
-
- 1.2.1 核函数选择
- 1.2.2 RBF 函数
- 参考资料
相关文章:
机器学习 | 目录
机器学习 | 网络搜索及可视化
监督学习 | SVM 之线性支持向量机原理
监督学习 | SVM 之支持向量机Sklearn实现
1. 非线性支持向量机
对解线性分类问题,线性分类支持向量机是一种非常有效的方法。但是,有时分类问题是非线性的,这时可以使用非线性支持向量机(non-linear support vector machine)。
非线性分类问题是指通过利用非线性模型才能很好地进行分类的问题。如下图所示,这是一个分类问题,无法用直线(线性模型)将正负实例正确分开,但可以用一条椭圆(非线性模型)将它们正确分开。[1]

再看一个“异或”问题,同样也不是线性可分的:

对这样的问题,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。如图 2 所示,若将原始的二维空间映射到一个合适的三维空间,就可以找到一个合适的划分超平面。当原始空间是有限维(即属性数是有限的),那么一定存在一个高维特征空间使样本可分。
令 ϕ ( x ) \phi(x) ϕ(x) 表示将 x x x 映射后的特征向量,于是,在特征空间中划分超平面模型可表示为:
(1) f ( x ) = w T ϕ ( x ) + b f(x)=w^T\phi(x)+b \tag{1} f(x)=wTϕ(x)+b(1)
线性可分支持向量机的原始问题变为:
(2) min w , b 1 2 ∥ w ∥ 2 s.t. y i ( w T ϕ ( x i ) + b ) − 1 ⩾ 0 , i = 1 , 2 , ⋯ , N \begin{array}{ll}{\min \limits_{w, b}} & {\frac{1}{2}\|w\|^{2}} \tag{2}\\ {\text { s.t. }} & {y_{i}\left(w^T \phi(x_i)+b\right)-1 \geqslant 0, \quad i=1,2, \cdots, N}\end{array} w,bmin s.t. 21∥w∥2yi(wTϕ(xi)+b)−1⩾0,i=1,2,⋯,N(2)
其对偶问题为:
(3) max α ∑ i = 1 N α i − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ϕ ( x i ) T ϕ ( x j ) s.t. ∑ i = 1 N α i y i = 0 α i ⩾ 0 , i = 1 , 2 , ⋯ , N \begin{array}{ll}{\max \limits_{\alpha}} & { \sum_{i=1}^N\alpha_i-\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j\phi(x_i)^T\phi(x_j)} \tag{3}\\ {\text { s.t. }} & {\sum_{i=1}^N\alpha_iy_i=0}\\ & {\alpha_i\geqslant 0, \quad i=1,2,\cdots,N}\end{array} αmax s.t. ∑i=1Nαi−21∑i=1N∑j=1Nαiαjyiyjϕ(xi)Tϕ(xj)∑i=1Nαiyi=0αi⩾0,i=1,2,⋯,N(3)
1.1 核技巧
求解 (2) 涉及到计算 ϕ ( x i ) T ϕ ( x j ) \phi(x_i)^T\phi(x_j) ϕ(xi)Tϕ(xj),这是样本 x i x_i xi 与 x j x_j xj 映射到特征空间之后的内积。由于特征空间维数可能很高,设置可能是无穷维,因此直接计算 ϕ ( x i ) T ϕ ( x j ) \phi(x_i)^T\phi(x_j) ϕ(xi)Tϕ(xj) 通常是困难的。为了避开这个障碍,可以设想这样一个函数:
(4) k ( x i , x j ) = ϕ ( x i ) T ϕ ( x j ) k(x_i,x_j)= \phi(x_i)^T\phi(x_j)\tag{4} k(xi,xj)=ϕ(xi)Tϕ(xj)(4)
核技巧: x i x_i xi 与 x j x_j xj 在特征空间的内积等于它们在原始样本空间中通过函数 k ( ⋅ , ⋅ ) k(\cdot,\cdot) k(⋅,⋅) 计算的结果,于是 (3)可以重写为:
(5) max α ∑ i = 1 N α i − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j k ( ⋅ , ⋅ ) s.t. ∑ i = 1 N α i y i = 0 α i ⩾ 0 , i = 1 , 2 , ⋯ , N \begin{array}{ll}{\max \limits_{\alpha}} & { \sum_{i=1}^N\alpha_i-\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j k(\cdot,\cdot)}\\ {\text { s.t. }} & {\sum_{i=1}^N\alpha_iy_i=0}\\ & {\alpha_i\geqslant 0, \quad i=1,2,\cdots,N} \end{array}\tag{5} αmax s.t. ∑i=1Nαi−21∑i=1N∑j=1Nαiαjyiyjk(⋅,⋅)∑i=1Nαiyi=0αi⩾0,i=1,2,⋯,N(5)
求解后即可得到:
(6) f ( x ) = w T ϕ ( x ) + b = ∑ i = 1 N α i y i ϕ ( x i ) T ϕ ( x ) + b = ∑ i = 1 N α i y i k ( x , x i ) + b \begin{array}{ll} {f(x)} &= {w^T\phi(x)+b} \\ &= {\sum_{i=1}^N{\alpha_iy_i\phi(x_i)^T\phi(x)+b}} \\ &= {\sum_{i=1}^N\alpha_iy_ik(x,x_i)+b}\\ \end{array}\tag{6} f(x)=wTϕ(x)+b=∑i=1Nαiyiϕ(xi)Tϕ(x)+b=∑i=1Nαiyik(x,xi)+b(6)
这里的函数 k ( ⋅ , ⋅ ) k(\cdot,\cdot) k(⋅,⋅) 就是“核函数”(kernel function)。上式显示出模型最优解可以通过训练样本的核函数展开,这一展开式又称为支持向量展式(support vector expansion)。
1.2 核函数
定理(核函数):令 X X X 为输入空间, k ( ⋅ , ⋅ ) k(\cdot,\cdot) k(⋅,⋅) 是定义在 X × X X\times X X×X 上的对称函数,则 k k k 是核函数当且仅当对于任意数据 D = { x 1 , x 2 , ⋯ x m } D=\{x_1,x_2,\cdots x_m \} D={x1,x2,⋯xm},“核矩阵”(kernel matrix) K K K 总是半正定的:[2]
(7) K = [ κ ( x 1 , x 1 ) ⋯ κ ( x 1 , x j ) ⋯ κ ( x 1 , x m ) ⋮ ⋱ ⋮ ⋱ ⋮ κ ( x i , x 1 ) ⋯ κ ( x i , x j ) ⋯ κ ( x i , x m ) ⋮ ⋱ ⋮ ⋱ ⋮ κ ( x m , x 1 ) ⋯ κ ( x m , x j ) ⋯ κ ( x m , x m ) ] \mathbf{K}=\left[\begin{array}{ccccc}{\kappa\left(\boldsymbol{x}_{1}, \boldsymbol{x}_{1}\right)} & {\cdots} & {\kappa\left(\boldsymbol{x}_{1}, \boldsymbol{x}_{j}\right)} & {\cdots} & {\kappa\left(\boldsymbol{x}_{1}, \boldsymbol{x}_{m}\right)} \\ {\vdots} & {\ddots} & {\vdots} & {\ddots} & {\vdots} \\ {\kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{1}\right)} & {\cdots} & {\kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)} & {\cdots} & {\kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{m}\right)} \\ {\vdots} & {\ddots} & {\vdots} & {\ddots} & {\vdots} \\ {\kappa\left(\boldsymbol{x}_{m}, \boldsymbol{x}_{1}\right)} & {\cdots} & {\kappa\left(\boldsymbol{x}_{m}, \boldsymbol{x}_{j}\right)} & {\cdots} & {\kappa\left(\boldsymbol{x}_{m}, \boldsymbol{x}_{m}\right)}\end{array}\right] \tag{7} K=⎣⎢⎢⎢⎢⎢⎢⎡κ(x1,x1)⋮κ(xi,x1)⋮κ(xm,x1)⋯⋱⋯⋱⋯κ(x1,xj)⋮κ(xi,xj)⋮κ(xm,xj)⋯⋱⋯⋱⋯κ(x1,xm)⋮κ(xi,xm)⋮κ(xm,xm)⎦⎥⎥⎥⎥⎥⎥⎤(7)
这个定理表明,只要一个对称函数所对应的核矩阵半正定,它就能作为核函数使用。事实上,对于一个半正定核矩阵,总能找到一个与之对应的映射 ϕ \phi ϕ 。换言之,任何一个核函数都隐式地定义了一个称为“再生核希尔伯特空间”(RKHS, Reproducing Kernel Hilbert Space)的特征空间。
1.2.1 核函数选择
通过前面讨论我们知道,我们希望样本在特征空间内线性可分,因此特征空间的好坏对支持向量机的性能直观重要。需要注意的是,在不知道特征映射的形式时,我们并不知道什么样的核函数时合适的,而核函数也仅是隐式地定义了这个特征空间。于是,“核函数选择”称为支持向量机的最大变数。若核函数选择不合适,则意味着将样本映射到了一个不合适的特征空间,很可能导致性能不佳。

对文本数据通常采用线性核;情况不明时可先尝试高斯核(RBF 核)
此外,还可以通过函数组合得到,例如:
- 若 k 1 k_1 k1 和 k 1 k_1 k1 为核函数,则对于任意正数 γ 1 , γ 2 \gamma_1, \gamma_2 γ1,γ2,其线性组合:
(8) γ 1 k 1 + γ 2 k 2 \gamma_1 k_1 + \gamma_2 k_2 \tag{8} γ1k1+γ2k2(8)
也是核函数;
- 若 k 1 k_1 k1 和 k 1 k_1 k1 为核函数,则核函数的直积:
(9) k 1 ⊗ k 2 ( x , z ) = k 1 ( x , z ) k 2 ( x , z ) k_1 \otimes k_2(x,z)=k_1(x,z)k_2(x,z) \tag{9} k1⊗k2(x,z)=k1(x,z)k2(x,z)(9)
也是核函数;
- 若 k 1 k_1 k1 为核函数,则对于任意函数 g ( x ) g(x) g(x):
(10) k ( x , z ) = g ( x ) k 1 ( x , z ) g ( z ) k(x,z)=g(x)k_1(x,z)g(z) \tag{10} k(x,z)=g(x)k1(x,z)g(z)(10)
也是核函数。
1.2.2 RBF 函数
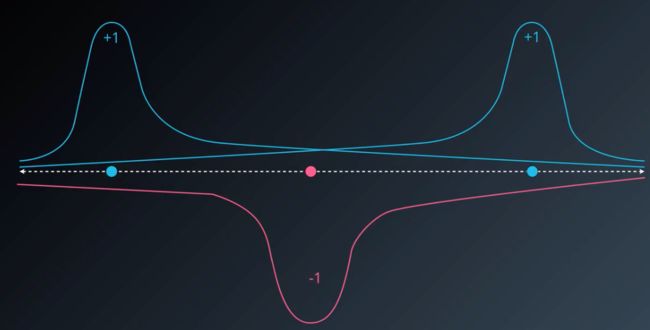
首先来看一个例子,假设我们要将一组直线上的数据进行分类,但由于它们是非线性的,因此需要利用核函数将数据变换为线性可分的数据。

我们通过一条曲线将直线上的数据投射到一个平面上,可以看见,所有的正实例都被投射到了曲线的顶端,而所有的负实例都被投射到了曲线的低端,因此这时我们就可以利用线性可分支持向量机找出分类超平面。

那么这条曲线是怎么构造出来的呢,这里就要介绍一个函数:径向基函数(RBF Radial Basis Function)。
所谓径向基函数,就是某种沿径向对称的标量函数。通常定义为空间中任一点 x x x 到某中心 x c x_c xc 之间欧式距离的单调函数,可以记为 k ( x , x c ) k(x,x_c) k(x,xc),其作用往往是局部的,即当 x x x 原理 x c x_c xc 时函数取值很小。
最常用的径向基函数是高斯径向基函数:
(11) k ( x , x c ) = e x p ( − ∥ x − x c ∥ 2 2 σ 2 ) k(x,x_c) = exp(-\frac{\|x-x_c\|^2}{2\sigma^2}) \tag{11} k(x,xc)=exp(−2σ2∥x−xc∥2)(11)
当我们使用高斯径向基函数作为核函数时,就称之为高斯核函数。
它的图像与高斯分布 y = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 y=\frac{1}{\sigma \sqrt{2\pi}}e^{-\frac{(x-\mu)^2}{2\sigma^2}} y=σ2π1e−2σ2(x−μ)2 相似,在高斯分布中,其分布被参数 σ \sigma σ 和 μ \mu μ 唯一确定,当 σ \sigma σ 越大时,图像越矮胖;当 σ \sigma σ 越小时,图像越高瘦。

类似地,我们在高斯径向基函数中使用 gamma 参数来决定图像的高瘦或矮胖:
(12) γ = 1 2 σ 2 \gamma = \frac{1}{2\sigma^2} \tag{12} γ=2σ21(12)
当 γ \gamma γ 越大时,图像越高瘦;当 γ \gamma γ 越小时,图像越矮瘦:

在高维数据中也相似:

此时超平面的截面即为分类数据的边界:

当我们使用高斯核函数时,此时的非线性支持向量机则由参数 γ \gamma γ 和惩罚参数 C C C 所确定:
当 γ \gamma γ 越大时,越有可能过拟合;当 γ \gamma γ 越小时,越有可能欠拟合;
当 C C C 越大时,对误分类的惩罚越大;当 C C C 越小时,对误分类的惩罚越小。
由于 SVM 模型没有先验信息,所以可以使用网络搜索来确定参数大小。
现在我们可以回答开头的例子中曲线时怎么拟合出来的了,我们通过在每一个数据点上使用一个高斯核函数,可以将数据分为两类,接着用一个连续平滑的曲线将这些图形连接起来,就得到了曲线:

参考资料
[1] 李航. 统计学习方法[M]. 北京: 清华大学出版社, 2012: 115-116.
[2] 周志华. 机器学习[M]. 北京: 清华大学出版社, 2016: 127-129.