图像超分辨率之SRCNN(Learning a Deep Convolutional Network for Image Super-Resolution)
论文下载:Learning a Deep Convolutional Network for Image Super-Resolution
代码下载:https://github.com/tegg89/SRCNN-Tensorflow
ECCV2014
0.知识
图像超分辨率重建技术:用低质量、低分辨率图像(或运动序列)来产生单幅高质量、高分辨率图像
均方误差:

峰值信噪比:一般是在20~40之间,由于输入的图像、插值方法、恢复的方式不同都有差异。如果每个采样点用 8 位表示,那么就是 255,一般图片格式都是unit8

1.摘要
不是目标检测领域的一篇论文,但是是计算机图形学方向的,应用了深度学习技术,作者有何开明和汤晓欧等一系列大牛。基于深度学习的单图像超分辨率重建的开山论文,关于参数设置和对比实验很详细。
传统的基于稀疏编码的SR方法也可以视为深度卷积网络,作者把传统的插值方法,从深度学习的方向解释了一遍。
缺点也很明显了,由于是15年的论文,用的还是大卷积核,relu,没有bn等技术。

2.编码流程:
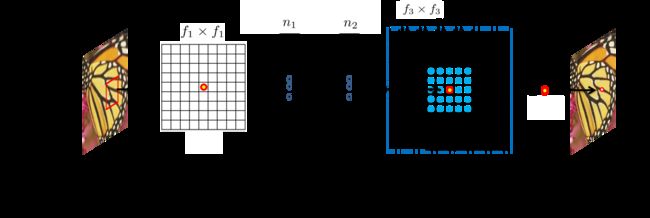
作者用了三个卷积来模拟传统操作:特征块提取和精炼、非线性映射、非线性映射
2.1特征块提取和精炼
图像恢复中的一种流行策略是密集提取补丁,然后用一组预先训练好的基(例如PCA,DCT,Haar等)来表示它们。这等同于用一组滤波器对图像进行卷积,每个滤波器对应一个基。用公式表示:

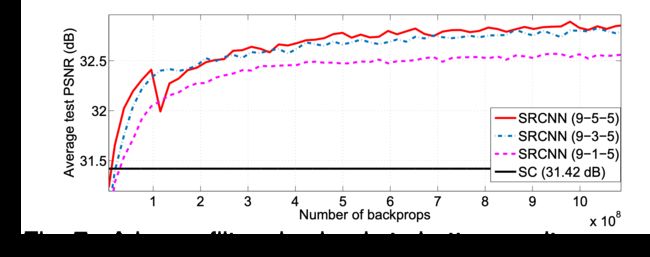
W1和B1分别代表滤波器(卷积核)和偏置,max即relu函数。这里用的是9964的卷积核。在SRCNN中使用不同的过滤器数量的结果:

2.2非线性映射
卷积操作是线性的,这里应该是指加了激活函数的卷积层,这里用的是1132的卷积核,用来压缩通道的。作者也尝试过用3*3的卷积核,较大的过滤器尺寸可获得更好的结果。
![]()
2.3 重建
去掉了relu层,目的还是要降低通道数,降低到输入时候的大小
![]()
3.实验结果:
作者还尝试了其他的结构:
加深网络:四层网络的收敛速度比三层网络慢。 但是,如果有足够的培训时间,则更深的网络将最终赶上并收敛到三层网络
更深的结构并不总能带来更好的结果

4.代码学习以及个人的理解
作者之前的三个操作都用了偏置,我在实验阶段没有使用偏执
self.biases = {
'b1': tf.Variable(tf.zeros([64]), name='b1'),
'b2': tf.Variable(tf.zeros([32]), name='b2'),
'b3': tf.Variable(tf.zeros([1]), name='b3')
}
在特征的提取和精炼阶段会迅速提高通道的数量,本来就用了大卷积核,再大通道会极大的增加计算量。所以在FPN中,降通道的那层去掉,然后再上采样后加入srcnn模块
self.weights = {
# 卷积核:f1*f1*c*n1. c为输入图像通道数,文中取YCrCb中Y通道,c=1;f1=9;n1为当前卷积核输出深度取64
'w1': tf.Variable(tf.random_normal([9, 9, 1, 64], stddev=1e-3), name='w1'),
'w2': tf.Variable(tf.random_normal([1, 1, 64, 32], stddev=1e-3), name='w2'),
'w3': tf.Variable(tf.random_normal([5, 5, 32, 1], stddev=1e-3), name='w3')
}
笔者的实验方法:
self.last_layer1_patch = conv2d(512, 512,9)
self.last_layer1_noline = conv2d(512, 256, 1)
self.last_layer1_recon = conv2d(256, 256, 5)
# 13,13,512 -> 26,26,512 -> 26,26,256
x1_in = self.last_layer1_upsample(out0_branch)#上采样,用的是临近点插值。scrnn中用的是双三插值
x1_in = self.last_layer1_patch(x1_in)#通道数不变
x1_in = self.last_layer1_noline(x1_in)
x1_in = self.last_layer1_recon(x1_in) #通道数不变
5.展望
alexnet中的提出:5*5卷积核几乎等效3*3卷积核*2,在感受野上相同,而且可以减少计算量,同理有:7*7卷积核=3*3卷积核*3、9*9卷积核=3*3卷积核*4;或者使用空洞卷积来提高感受野顺便也能减少几层卷积。
SRCNN的作者的时期,还没流行用小卷积核。所以可以尝试使用小卷积核来代替大卷积核。貌似加深这个模块的深度没什么用,但是用较大的卷积核比较有用,也可能是梯度弥散掉了,加个残差可以解决。