Python数据清洗-异常值处理
异常值的判别
如何定义异常值:
根据正态分布定律,95%的样本理论上应该落在均值的两倍标准差以内,因此我们将一组测定值中与平均值的偏差超过两倍标准差的测定值判别为异常值,与平均值的偏差超过三倍标准差的测定值,称为高度异常的异常值。在实际生活中最常讲到的二八法则也是根据这一定理。
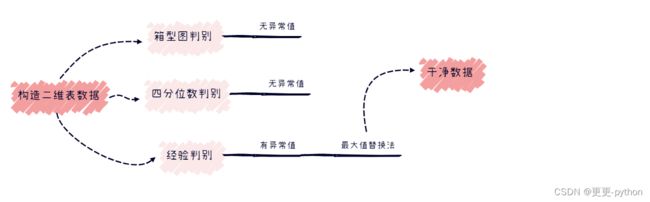
本文的分析结构
首先,自定义一个分析的数据集合,日常的话可以是从数据库提取的数据,EXCEL表格等
##自定义数据分析数据集合
import pandas as pd
name=["小宝","小红","小小","大大","一一","一二","小兰","柯南","大小","小黑","小宝"]
sex=["女","女","女","男","男","男","女","男","女","女","女"]
age=[17,18,19,11,17,18,19,10,15,10,17]
score=[86,86,98,98,91,92,104,94,93,92,86]
data=pd.DataFrame({"name":name,"sex":sex,"age":age,"score":score})
data.head()

1、箱形图法
绘制箱型图通过可视化的方法判断是否有异常值
###异常值的判别
##箱型图查看是否有异常值
import matplotlib.pyplot as plt
data['score'].plot(kind='box')
plt.show()

2、四分位数法
计算分位数量化的方式判断是否有异常值
##计算分位数
Q1=data['score'].quantile(q=0.25)
Q3=data['score'].quantile(q=0.75)
IQR=Q3-Q1
data['score']>Q3+1.5*IQR

通过箱型图和分位数判别都没有办法查看出是否有明显的异常值,但是因为分数理论上不大于100,我们查看分数有超过100,对其进行处理。
3、经验判别法
##因为四分位法无法筛选异常值,我们直接根据100法则判断分数的异常值
data['score']>100
##筛选是异常的一行
data[data['score']>100]

发现小兰的成绩是104,分析原因是附加题加上原始分数超过100分,按照统计原则,分数最大不可超过100(人为规定),因此用最大值替换小兰的分数
##最大值替换法
data['score'][6]=100
data

最终我们将分数维度的异常值处理干净。
异常值的出现往往会影响数据整体的趋势,但其出现可以帮助我们发现业务过程中的一些漏洞和特殊情况,含有特别的商业信息和价值。