【论文翻译】Multi-modal Knowledge Graphs for Recommender Systems
ABSTRACT
推荐系统在解决信息爆炸问题和提高各种在线应用的用户体验方面显示出巨大潜力。为了解决推荐系统中的数据稀少和冷启动问题,研究人员通过利用有价值的外部知识作为辅助信息,提出了基于知识图(KGs)的推荐。
然而,这些工作大多忽略了多模式知识图(MMKGs)中的各种数据类型(如文本和图像)。
在本文中,我们提出了多模态知识图注意网络(MKGAT),通过利用多模态知识更好地增强推荐系统。
具体来说,我们提出了一种多模态图关注技术,在MMKGs上进行信息传播,然后使用所得到的聚合嵌入表示进行推荐。据我们所知,这是第一个将多模态知识图纳入推荐系统的工作。我们在两个不同领域的真实数据集上进行了广泛的实验,其结果表明我们的模型MKGAT可以成功地采用MMKGs来提高推荐系统的质量。
知识表示学习的前提是表示学习,那么何为表示学习?就是把图像、文本、语音等的语义信息表示为低维稠密的实体向量,即Embedding。Embedding是大家都熟知的,自从13年出现的word2vec,Embedding成为NLP任务的标配。
那么知识表示学习呢?改变了对象,即将知识库中的实体和关系表示为低维稠密的实体向量。
那么知识图谱中的知识都是什么?我们熟知知识图谱是由实体和关系组成,通常采用三元组的形式表示,【head(头实体),relation(实体的关系),tail(尾实体)】,简写为(h,r,t)。
1 Introduction
最近,知识图谱(KGs)因其全面的辅助数据而被广泛应用于推荐系统中(即基于KG的推荐)[24, 28]。具体来说,基于KG的推荐通过引入高质量的侧面信息(KGs),缓解了用户-项目互动的稀疏问题和冷启动问题。这些问题经常出现在基于协作过滤(CF)[11]的方法中。
然而,现有的基于KG的推荐方法在很大程度上忽略了多模态信息,如物品的图像和文字描述。这些视觉或文本特征可能在推荐系统中发挥重要作用。
例如,在观看一部电影之前,用户往往会观看预告片或阅读一些相关的电影评论。当去餐厅吃饭时,用户通常会先在一些网络平台上浏览菜肴的图片或餐厅的评论,如Yelp或大众点评。
因此,有必要将这些多模态信息引入知识图谱。这样做的好处是,多模态知识图谱(MKGs)将视觉或文本信息引入知识图谱,将图像或文本作为实体或实体的属性。这是一种更普遍的获取外部多模态知识的方式,不需要给视觉或文本信息专门定义。图1中显示了一个简单的MKGs的例子。
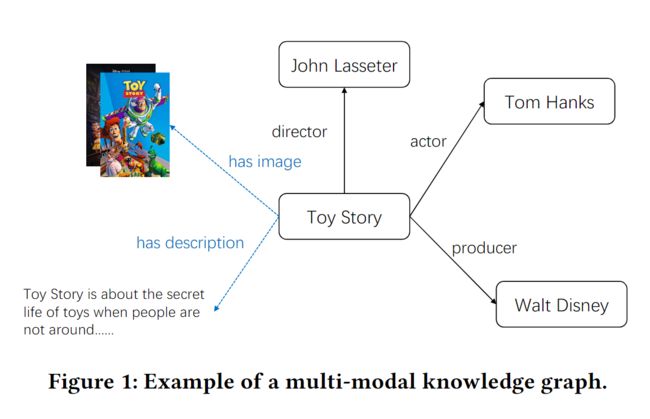
知识图谱的学习对基于KG的推荐起着关键作用。基于KG的推荐模型通常使用知识图谱表示模型来学习KG实体的embedding,然后将其输入下游的推荐任务。多模式的知识图表示学习有两种类型:基于特征的方法和基于实体的方法。
基于特征的方法[17, 30]将模态信息作为实体的一个辅助特征。它通过考虑视觉表征来扩展翻译模型(TransE)[2],视觉表征是从知识图谱实体对应的图像中提取的。
一个三联体的能量(例如TransE中三联体的评分函数)是根据KG的结构以及实体的视觉表示来定义的。
然而,基于特征的方法对知识图谱的数据源提出了相对的要求,因为它要求知识图谱中的每个实体都有多模态的信息。
为了解决对KGs数据源的严格要求,我们推荐采用基于实体的方法[19]。
基于实体的方法将不同类型的信息(如文本和图像)视为结构化知识的关系三要素,而不是辅助特征,即知识图谱的第一等公民。
它通过考虑新的关系,如ℎ(表示一个实体是否有图像信息)和ℎ(表示一个实体是否有文本信息来描述它),引入视觉和文本信息。然后, 基于实体的方法通过独立应用翻译模型[2]或基于卷积神经网络(CNN)的模型[18]来处理每个三元组(ℎ,,), 学习知识图谱嵌入, 其中ℎ和分别表示头和尾实体, 是ℎ和之间的关系(例如, ℎ和ℎ)。
基于实体的方法虽然解决了基于特征的方法中对MKGs数据源的高要求问题,但它只关注实体之间的推理关系,而忽略了多模态信息的融合。
事实上,多模态信息通常是作为一种辅助信息来充实其他实体的信息。因此,我们需要一种直接的互动方式,在对实体之间的推理关系进行建模之前,将多模态信息明确地融合到其相应的实体中。
考虑到现有解决方案的局限性,我们认为开发一个能够有效利用MKGs的MKGs表示模型是非常必要的。
具体来说,该模型应该满足两个条件:
1)对MKGs数据源的要求低。
2)在保留实体之间的推理关系的同时,考虑多模式的信息融合。
为此,我们遵循基于实体的方法来构建多模态知识图。然后,我们提出了多模态知识图关注网络(MKGAT),它从两个方面对多模态知识图进行建模。1)实体信息聚合,聚合实体的邻接节点信息以丰富实体本身;2)实体关系推理,通过三要素的评分函数(如TransE)构建推理关系。
我们首先提出了一种改进图注意神经网络(GATs)的新方法,在聚合相邻实体的同时考虑到知识图谱中的关系,完成实体信息的聚合。然后,我们使用翻译模型对实体之间的推理关系进行建模。
我们的MKGAT模型的一个明显优势在于,它不要求知识图谱中的每个实体都有多模态信息,这意味着它对知识图谱数据没有特别高的要求。此外,MKGAT模型并不独立处理每个知识图谱三要素,而是聚合实体的邻居信息。因此,它可以更好地学习融合其他模态信息的实体嵌入。
The primary contributions of this work can be summarized as follows:
- To the best of our knowledge, this is the first work to introduce a multi-modal knowledge graph into a recommendation system.
- We develop a new MKGAT model, which employs information propagation on the multi-modal knowledge graph, to obtain better entity embedding for recommendation.
- Extensive experiments conducted on two large-scale real-world datasets demonstrate the rationality and effectiveness of our model.
这项工作的主要贡献可以概括为以下几点:
- 据我们所知,这是第一项将多模态知识图引入推荐系统的工作。
- 我们开发了一个新的MKGAT模型,它在多模态知识图上采用了信息传播,以获得更好的实体嵌入来进行推荐。
- 在两个大规模的真实世界数据集上进行的广泛实验证明了我们模型的合理性和有效性。我们的模型的合理性和有效性。
本文的其余部分组织如下。第2节调查了相关工作。第3节介绍了初步的概念。然后,我们在第4节介绍了MKGAT模型,接着在第5节介绍了实验结果。第6节是本文的结论。
2 Related Work
在本节中,我们将介绍与我们的研究相关的现有工作,包括多模态知识图谱和基于知识图谱的推荐。
2.1 多模态知识图谱
多模态知识图谱(MKGs)通过在传统的KGs中引入其他模态的信息来丰富知识的类型。实体图像或实体描述可以为知识表示学习提供重要的视觉或文本信息。大多数传统方法仅仅从结构化的三要素中学习知识表示,而忽略了知识库中经常使用的各种数据类型(如文本和图像)。最近,人们在探索多模态知识图示学习方面做出了一些努力。这些工作证明,多模态知识图在知识图谱的完成和三重分类中发挥着重要作用[5, 17, 30]。
从知识图谱构建的角度来看,多模态知识图谱表示学习工作可以分为两种类型:基于特征的方法和基于实体的方法。
基于特征的方法。 [17, 30]将多模态信息作为实体的辅助特征。这些方法通过考虑视觉表征来扩展TransE[2]。视觉表征可以从与知识图谱实体相关的图像中提取。在这些方法中,三要素的能量(例如,TransE中三要素的评分函数)是根据知识图谱的结构以及实体的视觉表示来定义的,这意味着每个实体必须包含图像属性。然而,在真实场景中,一些实体并不包含多模态信息。所以这种方法不能被广泛使用。
基于实体的方法。 [19]将不同的模式信息(如文本和图像)作为结构化知识的关系三要素,而不是预先确定的特征。在这些工作中,多模态信息被认为是知识图谱的第一等公民。然后,基于实体的方法使用基于CNN的KGE方法来训练知识图谱的嵌入。然而,现有的基于实体的方法独立处理每个三元组,忽略了多模态信息的融合,这对多模态图元并不友好。
由于多模态知识图在近几年才被提出,因此在这个方向上的研究工作很有限。
2.2 基于知识图谱的推荐
最近,一些研究试图利用KGs结构进行推荐,可分为三种类型,基于嵌入的方法、基于路径的方法和统一的方法。
基于嵌入的方法。 基于嵌入的方法[23, 25, 27]首先使用知识图谱嵌入(KGE)[27]算法对知识图谱进行预处理,然后在推荐框架中使用学到的实体嵌入,将各种类型的辅助信息统一到CF(协同过滤)框架中。CKE算法[35]将协同过滤(CF)模块与item的知识嵌入、文本嵌入和图像嵌入结合在一个统一的贝叶斯框架中。基于知识的深度网络(DKN)[25]将实体嵌入和单词嵌入视为不同的渠道,然后使用卷积神经网络(CNN)框架将它们结合起来进行新闻推荐。
基于嵌入的方法在利用知识图谱辅助推荐系统方面表现出很高的灵活性,但这些方法所采用的KGE算法(翻译模型或基于CNN的模型)并不适合多模式图元(原因与MKGs中基于实体的方法相同)。换句话说,这些方法对多模态的知识图谱并不友好。
基于路径的方法。 基于路径的方法[33, 36]探索知识图谱中项目之间的各种连接模式,为推荐提供额外的指导。例如,关于知识图谱作为一个异质信息网络(HIN),个性化实体推荐(PER)[33]和基于元图的推荐[36]提取基于元路径/元图的潜在特征来表示用户和项目之间沿着不同类型的关系路径/图谱的连接。
基于路径的方法以一种更自然、更直观的方式利用知识图谱,但它们在很大程度上依赖于手工设计的元路径,这在实践中很难被优化。另一个问题是,在某些实体和关系不属于一个领域的情况下,不可能设计出手工制作的元路径。
联合方法。 基于嵌入的方法利用KG中实体的语义表示进行推荐,而基于路径的方法则利用KG中实体之间的连接模式。这两种方法都只利用了KGs中的一个方面的信息。
为了充分地利用KGs中的信息进行更好的推荐,人们提出了联合方法,这些方法整合了实体和关系的语义表征,以及连接模式的信息。
然而,联合方法也依赖于知识图谱的嵌入技术。翻译模型被广泛用于训练知识图谱嵌入。代表性的工作包括注意力增强的知识感知用户偏好模型(AKUPM)[12]和知识图谱注意力网络(KGAT)[28]。他们独立地处理每个三元组,不考虑多模式信息融合。与基于嵌入的方法类似,联合方法对多模态知识图不友好。
3 Problem Formulation
在这一节中,我们介绍了一组初步的概念,然后提出了基于多模式知识图的推荐任务。
定义1(知识图谱)。为了提高推荐性能,我们考虑了知识图谱中项目的侧面信息。通常情况下,这种辅助数据由现实世界的实体和它们之间的关系组成,以描述一个项目。
知识图谱(KG), =(,),是一个直接图,其中表示节点集,表示边集。节点是实体,边是主体-属性-客体三重事实。每条边属于一个关系类型∈R,其中R是一个关系类型的集合。每条边以(头实体,关系,尾实体)的形式(表示为(ℎ,,),其中ℎ,∈,∈R)表示从头实体ℎ到尾实体的一种关系。
图2展示了一个知识图谱的例子,其中一部电影(名为《玩具总动员》)由其导演、演员和制片人描述。我们可以用(Toy Story, DirectorOf, John Lasseter)来说明Toy Story是由John Lasseter导演的。
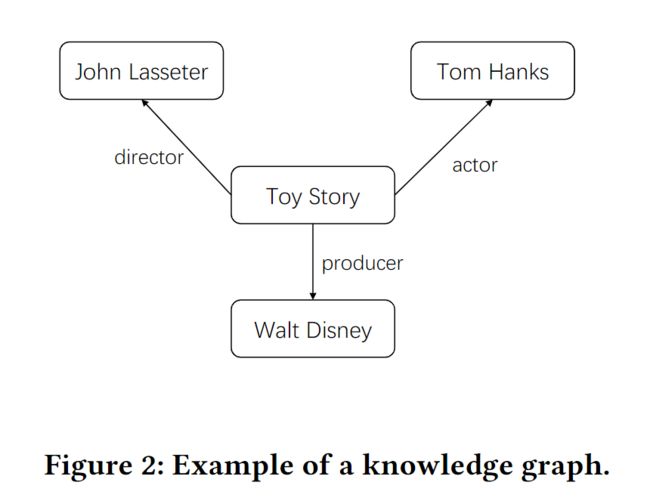
定义2(多模态知识图谱):
定义3(协同知识图谱):
Task description. We now formulate the multi-modal KGs based recommendation task to be addressed in this paper:
- Input Collaborative knowledge graph that includes the user-item bipartite graph and multi-modal knowledge graph.
- Output A prediction function that predicts the probability of a user adopting an item.
4 Method
在本节中,我们将介绍本文提出的MKGAT模型。MKGAT模型的框架概况如图5所示,它由两个主要的子模块组成:多模式知识图谱嵌入模块和推荐模块。
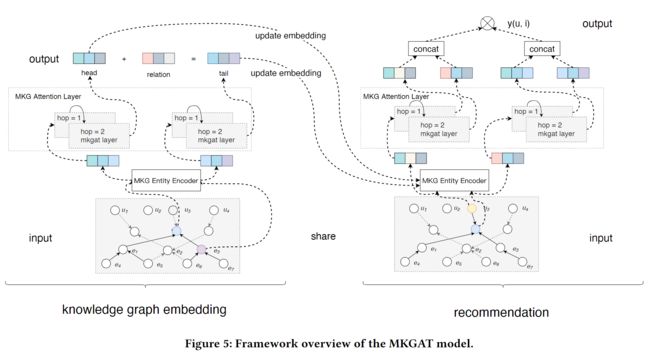
在讨论子模块之前,我们首先介绍两个关键组件,多模态知识图谱实体编码器和多模态知识图谱关注层,它们是KG嵌入模块和推荐模块的基本构件。
- 多模态知识图实体编码器,使用不同的编码器来嵌入每个特定的数据类型。
- 多模式知识图注意层,它将每个实体的相邻实体信息汇总到每个实体本身,以学习新的实体嵌入。
现在我们介绍MKGAT中的两个子模块。
- 多模块知识图谱嵌入模块
以协同知识图谱为输入,知识图谱嵌入模块利用多模态知识图谱(MKGs)实体编码器和MKGs注意层为每个实体学习新的实体表示。新的实体表征聚合了其邻居实体的信息,同时保留了关于自身的信息。然后,新的实体表示可以用来学习知识图谱嵌入,以表示知识推理关系。 - 推荐模块
以实体的知识图谱嵌入(由知识图谱嵌入模块获得)和协作知识图谱为输入,推荐模块还采用MKGs实体编码器和MKGs关注层,利用相应的邻居实体来丰富用户和物品的表示。最后,用户和物品之间的匹配分数可以按照传统的推荐模型生成。
在下文中,我们将详细阐述知识图形嵌入模块和推荐模块。
4.1 多模态知识图谱embedding
在本节中,我们首先介绍MKGs实体编码器和MKGs注意层,然后介绍了知识图谱嵌入的训练过程。
4.1.1 多模态知识图谱实体编码器
为了将多模态实体纳入模型,我们建议也学习不同模态数据的嵌入。我们利用深度学习的最新进展,为这些实体构建编码器来表示它们,本质上是为所有实体提供一个嵌入。这里我们描述一下我们用于多模态数据的编码器。如图4所示,我们使用不同的编码器来嵌入每个特定的数据类型。
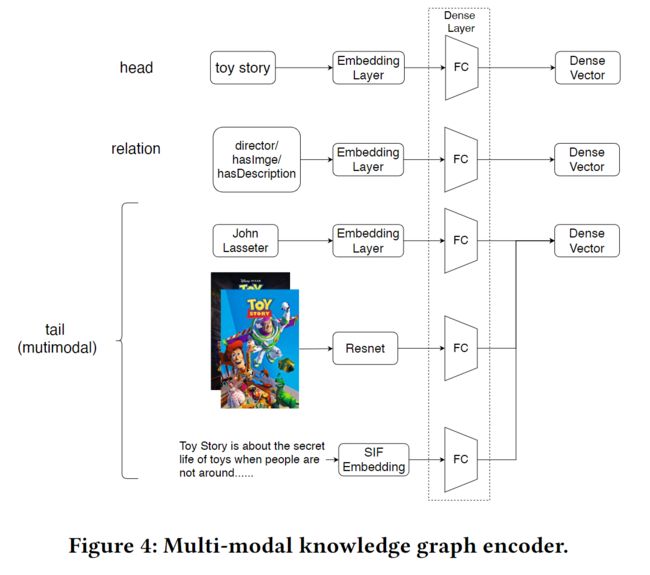
结构化知识。考虑一个三元组的信息,其形式为(ℎ,,)。为了将头部实体ℎ、尾部实体和关系表示为独立的嵌入向量,我们将其实体或关系通过嵌入层生成密集向量。
图像。为了紧凑地表示图像中的语义信息,已经开发了多种模型,并成功地应用于图像分类[8]和问题回答[32]等任务。为了嵌入图像以使编码代表这种语义信息,我们使用ResNet50[6]的最后一个隐藏层,它是由Imagenet[3]预训练的。
文本。这些文本信息与内容高度相关,并能捕捉到用户的偏好。对于文本实体,我们使用Word2Vec[16]来训练词向量,然后应用平滑反频率(SIF)模型[1]来获得一个句子的词向量的加权平均值,作为句子向量来表示文本特征。为了提高模型的效率,我们使用句子向量技术,而不是使用LSTM对句子进行编码。而SIF会比单纯使用词向量的平均值有更好的表现。
最后,如图4所示,我们使用密集层将实体的所有模态统一到同一维度,这样我们就可以在我们的模型上进行训练。
4.1.2 多模态知识图谱注意层
图6中说明的MKGs注意层,它沿着高阶连接性递归传播嵌入[10]。此外,通过利用图注意网络(GATs)的思想[22],我们产生了级联传播的注意权重,以揭示这种连接的重要性。尽管GATs很成功,但它们并不适合于KGs,因为它们忽略了KGs的关系。因此,我们修改了GATs以考虑到KGs的嵌入关系。
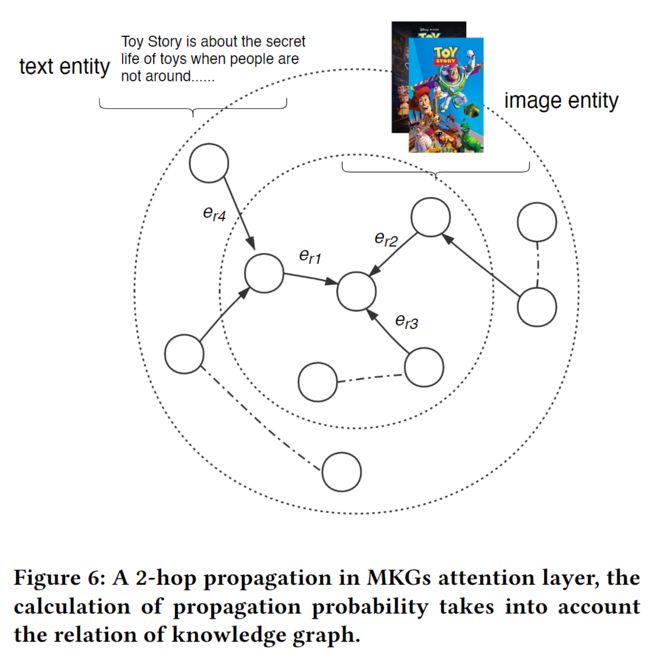
而注意力机制的引入[21]可以减少噪声的影响,使模型专注于有用的信息。
这里我们先描述一个单层,由传播层和聚合层两部分组成,然后讨论如何将其推广到多层。多模态知识图谱关注层不仅用于知识图谱的嵌入,而且还用于推荐。
传播层。 给定一个候选实体ℎ,我们在学习其知识图谱嵌入时必须考虑两个方面。首先,我们通过transE模型学习知识图谱的结构化表示,即h + r ≈ t。其次,对于实体ℎ的多模态邻居实体,我们要将这些信息汇总到实体ℎ,以丰富实体ℎ的表示。 按照文献[28]的方式,我们用Nℎ表示与ℎ直接相连的三联体集合。e是聚合了邻居实体信息的表示向量,它是每个三联体表示的线性组合,可以用公式1计算。
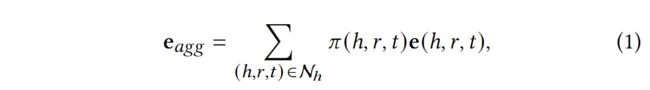
其中,e(ℎ,,)是每个三联体(ℎ,,)的嵌入,(ℎ,,)是对每个三联体e(ℎ,,)的关注分数。(ℎ,,)控制从三联体e(ℎ,,)传播的信息量。
由于关系在知识图谱中的重要性,我们在e(ℎ,,)和(ℎ,,)中保留关系的嵌入,其中的参数是可学习的。对于三联体e(ℎ,,), 我们通过对头部实体、尾部实体和关系的嵌入进行线性变换来学习这个嵌入, 其表述如下:
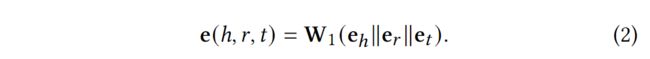
其中,ℎ和是实体的嵌入,而是关系的嵌入。我们通过关系的关注机制来实现(ℎ,,), 其计算方法如下:
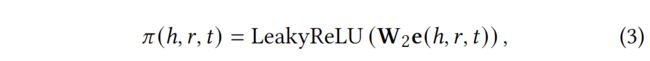
其中,我们按照文献[22]的方法,选择LeakyReLU[15]作为非线性激活函数。此后,我们通过采用softmax函数将所有与ℎ连接的三联体的系数归一化。
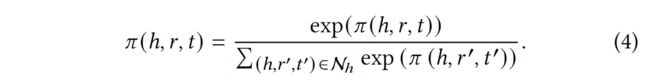
聚合层。 这个阶段是将实体表示eℎ和相应的e聚合为实体ℎ的新表示,以便不丢失初始eℎ信息。在这项工作中,我们通过以下两种方法实现聚合函数(eℎ,e)。
直接加 or 拼接
1)添加聚合法考虑eℎ和e之间的元素-明智(element-wise)的添加特征互动,可由公式5得到。
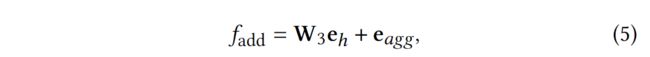
其中,我们对初始eℎ进行线性变换,并将其加入到e中。W3是一个权重矩阵,将当前的表征转移到公共空间,表示可训练的模型参数。这个操作类似于残差网络中的操作[6]。
2)串联聚合法将eℎ和e串联起来,使用线性变换。
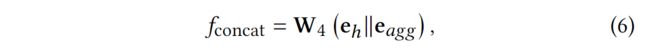
其中∥是串联操作,W4是可训练的模型参数。
高阶传播。通过堆叠更多的传播和聚合层,我们探索协作知识图谱中固有的高阶连接性。一般来说,对于层模型来说,传入的信息会在跳的邻域内积累。
4.1.3 知识图谱嵌入
在通过MKGs实体编码器和MKGs注意力层后,我们为每个实体学习一个新的实体表征。然后,我们将这些新的实体表征输入到知识图谱嵌入中,这是一种将实体和关系参数化为矢量表征的有效方法,同时保留了知识图谱结构中的关系推理。
更具体地说,我们采用了知识图谱嵌入中广泛使用的翻译评分函数[2],来训练知识图谱嵌入。它通过优化翻译原则eℎ+e≈e来学习嵌入每个实体和关系, 当一个三联体(ℎ,,)有效时, 其中eℎ和e是来自MKGs注意层的新实体嵌入,e是关系的嵌入。公式7描述了三联体的得分(ℎ,,).
![]()
知识图谱嵌入的训练考虑了有效三联体和破损三联体之间的相对顺序,并通过成对的排名损失来鼓励它们的区分。
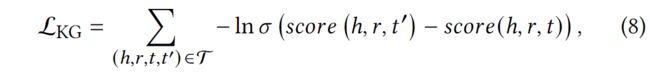
其中,T={(ℎ,,,′)|(ℎ,,)∈G, (ℎ,,′) ∉G},而(ℎ,,′) 是通过随机替换有效三元组中一个实体构造的破碎三元组。(-)是sigmoid函数。
该层在三联体的粒度上对实体和关系进行建模,作为正则器工作,将直接连接注入到表示中,可以提高模型的知识表示能力。
4.2 Recommendation
在每个实体通过知识图谱嵌入模块获得相应的嵌入后,将被输入到推荐模块。与知识图谱嵌入模块类似,推荐模块也使用MKGs注意层来聚合邻居实体信息。
为了保留1-的跳数信息,我们沿用了[28]的设置,保留了第层的候选用户和项目的输出。不同层的输出代表不同跳数的信息。因此,我们采用层聚合机制[31],将每一步的表征串联成一个单一的向量,可以发现如下:
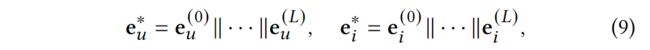
其中∥是连接操作,是MKGs注意层的数量。
通过这样做,我们不仅可以通过执行嵌入传播操作来丰富初始嵌入,而且还可以通过调整来控制传播的强度。
最后,我们通过公式10对user和item的表示进行内积,从而预测它们的匹配分数。
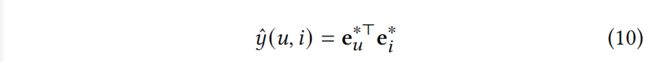
然后,我们通过使用贝叶斯个性化排名(BPR)损失来优化我们的推荐预测损失[20]。具体来说,我们假设观察到的记录,表明更多的用户偏好,应该比未观察到的记录分配更高的预测分数。BPR损失可以用公式11来构建。
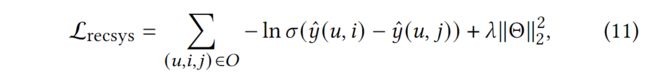
其中={(,, )|(,) ∈R+, (, ) ∈R-}表示训练集。R+表示用户和物品之间观察到的交互,R-是抽样的未观察到的交互集,(-)是sigmoid函数。而Θ是参数集,是L2正则化的参数。我们交替更新MKGs嵌入模块和推荐模块的参数。具体来说, 对于一批随机抽样的(ℎ,,,′), 我们更新所有实体的知识图嵌入. 然后,我们随机抽取一批(,, ),从知识图谱嵌入中检索它们的表示。两个模块的损失函数被交替优化。
5 Experiments
在这一节中,我们使用两个来自不同领域的真实世界数据集来评估MKGAT模型。我们首先在第5.1节介绍了我们的实验设置,然后在第5.2节讨论了主要的实验结果。此外,我们还在第5.3节进行了详细的案例研究。
5.1 实验设置
5.1.1 数据集
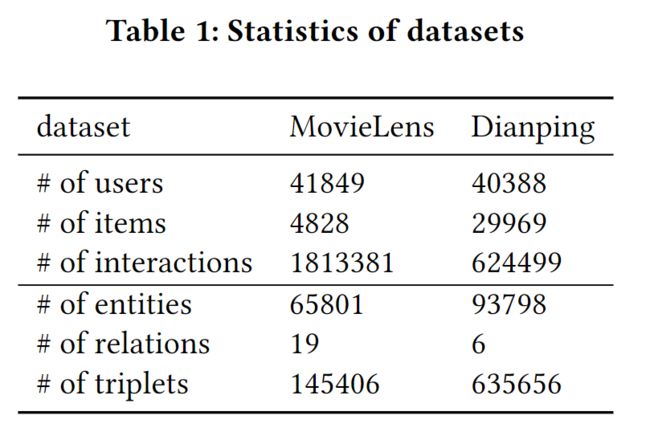
我们使用电影和餐馆领域的两个推荐数据集进行实验。具体情况如下。
- MovieLens 这个数据集已被广泛用于评估推荐系统。它由MovieLens网站上的明确评级(范围从1到5)组成。在我们的实验中,我们使用MovieLens-10M数据集。我们将评分转换为隐性反馈数据,其中每个条目都被标记为1,表示用户对该项目进行了评分,如果没有评分则为0。MovieLens数据集的知识图谱来自于[26],它使用微软的Satori来构建这个数据集的知识图谱。特别是,[26]首先从整个知识图谱中选择一个置信度大于0.9的三要素子集。考虑到子知识图,[26]通过将其名称与三联体的尾部相匹配,收集所有有效电影的Satori ID。在获得项目ID集后,[26]将这些项目ID与Satori子KG中所有三联体的头部进行匹配,并选择所有匹配良好的三联体作为每个数据集的最终KG。为了构建MovieLens知识图谱的图像实体,我们从Youtube上抓取相应的预告片而不是完整的视频。我们使用FFmpeg 5来提取每个预告片的关键帧,并使用预先训练好的ResNet50[6]模型来提取关键帧的视觉特征。为了构建MovieLens知识图谱的文本实体,我们从TMDB抓取相应的电影描述。
- 大众点评网是一个中国生活信息服务网站,用户可以在这里搜索和获得餐馆的信息。大众点评网是由美团点评集团提供的,其中正面互动的类型包括购买,和添加到收藏夹。我们对每个用户的负面互动进行采样。大众点评网的知识图谱来自美团大脑,这是一个由美团点评集团为餐饮和娱乐业建立的内部知识图谱。实体的类型包括 实体类型包括POI(即餐厅)、一级和二级分类、商业区和标签。为了构建大众点评数据集的知识图谱的图像实体,我们选择了POI的顶级推荐菜肴的图像。与MovieLens数据集类似,我们使用预先训练好的ResNet50[6]模型来提取推荐菜品图片的视觉特征。为了构建大众点评知识图谱的文本实体,我们使用了每个POI的用户评论。
两个数据集的统计信息如表1所示。
5.1.2 评价指标
对于测试集中的每个用户,我们将用户没有互动过的项目视为负面项目。然后,每种方法都输出用户对所有项目的偏好分数,除了训练集中的正面项目。我们随机选择20%的互动作为测试的基础事实,其余的互动用于训练。为了评估顶级推荐和偏好排名的有效性,我们采用了两个广泛使用的评估指标。@和@。的默认值为20。我们报告的是测试集中所有用户的平均结果。
recall(召回率):在正样本中有多少被预测为真。
ndcg(Normalized Discounted cumulative gain 归一化折损累计增益):用户对推荐列表中的item是否喜欢,是1否0,进行归一化(标准化,为了便于考虑与其他用户的对比)求和。
5.1.3 对照组
我们将我们提出的MKGAT模型与一些最先进的模型进行比较,其中包括基于FM的方法(NFM),基于KG的方法(CKE,KGAT),多模态方法(MMGCN)。
- NFM:神经因式分解机(NFM)[7]是一种最先进的因式分解机(FM),它将FM归入神经网络。特别是,我们按照[7]的建议在输入特征上采用了一个隐藏层。
- CKE:协作知识库嵌入(CKE)[35]将协作过滤(CF)与结构知识、文本知识和视觉知识结合在一个统一的推荐框架中。我们在本文中把CKE作为CF加结构知识的模块来实现。
- KGAT:知识图谱关注网络(KGAT)[28]首先应用TransR模型[13]来获得实体的初始表示。然后,它从实体本身向外运行实体传播。通过这种方式,用户表征和物品表征都可以用相应的邻居信息来充实。
- MMGCN:多模态图卷积网络(MMGCN)[29]是一个最先进的多模态模型,它考虑了每个模态的单个用户-物品交互。具体来说,MMGCN为每个模态建立了用户-物品的二部图,然后使用GCN来训练每个二部图,最后合并不同模态的节点信息。
5.1.4 参数设置
我们使用Xavier初始化器[4]来初始化模型参数,并使用Adam优化器[9]对模型进行优化。小批量大小和学习率分别在[1024;5120;10240]和[0:0001;0:0005;0:001]中搜索。推荐部分和知识图谱嵌入部分的MKGAT层数在[1;2;3]中搜索。对于视觉实体,我们使用Resnet的最后一个隐藏层的2048维特征。对于文本实体,我们通过word2vec[16]训练300维的单词嵌入,并使用SIF[1]算法生成相应的句子向量。最后,我们将所有实体的维度设定为64。
5.2 实验结果
我们首先报告所有方法的性能,然后研究不同因素(即模式、模型深度和组合层)对模型的影响。
5.2.1 所有方法的性能
所有模型的结果都显示在表2中。
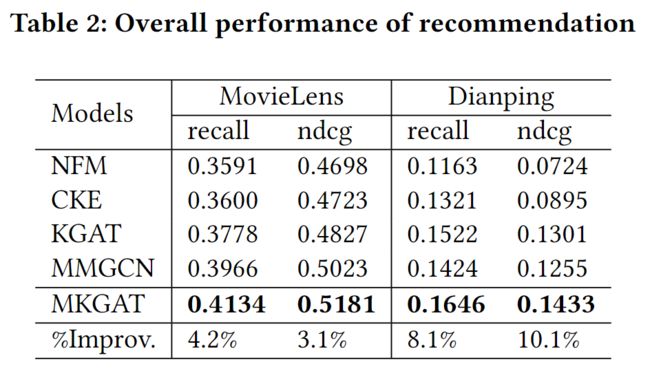
我们可以看到,我们提出的MKGAT模型(其中模式包括结构化知识、文本和视觉;知识图谱部分和推荐部分的模型深度设置为2;组合层设置为添加聚合层)在两个数据集上的和方面都优于所有基线。此外,我们还有以下观察。
- 在这两个数据集上,MKGAT始终产生了最好的性能。具体来说,在MovieLens和大众点评上,MKGAT比最强的基于KG的对照组KGAT在ndcg@20上分别提高了7.33%和10.14%,在recall@20上提高了9.42%和8.15%。这验证了多模态知识图谱的有效性。而综合分析表2和表3,在引入多模态实体的情况下,我们的方法与其他基于KG的方法相比,可以取得更大的进步。这验证了我们的方法比其他方法对多模态信息更加友好。
- 在所有的比较方法中,基于KG的方法(即CKE和KGAT)在两个数据集上的两个评价指标上都优于基于CF的普通方法(即NFM),这表明KG的使用确实大大改善了推荐性能。
- 比较两个基于KG的方法,CKE和KGAT的性能,我们发现KGAT在两个指标上都比CKE有更好的表现,这证明了图卷积网络在推荐系统中的力量。
- 值得一提的是,MKGAT可以在MovieLens数据上击败MMGCN模型,这是一种最先进的多模态推荐方法。这表明我们的方法可以合理利用多模态信息。
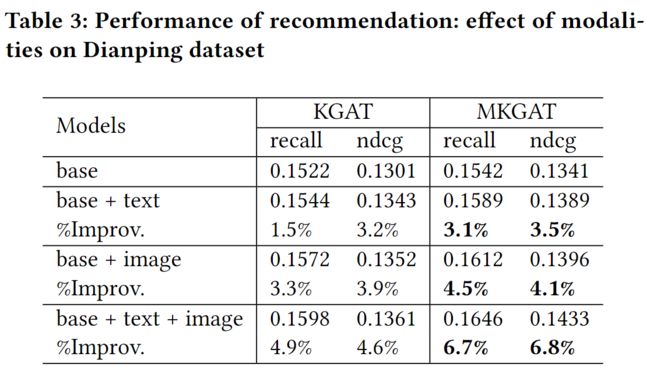
5.2.2 模态的影响
为了探索不同模式的影响,我们比较了KGAT和我们的MKGAT模型在大众点评数据集上不同模式的结果。性能比较结果见表3。我们有以下的观察:
- 如表3所示,在KGAT和MKGAT中,具有多模态特征的方法都优于具有单模态特征的方法。
- 在推荐效果方面,视觉模态比文字模态更重要,这是因为当用户在网络平台上浏览餐厅信息时,视觉信息(如图片)往往会吸引他/她的注意力。
- 我们的MKGAT模型,也是一种基于KG的方法,与KGAT相比,可以利用图片信息来更好地提高推荐效果。换句话说,与其他基于KG的方法相比,我们的方法在引入多模态信息后会有更大的改善。其背后的原因是,当我们训练知识图谱嵌入时,MKGAT可以更好地将图像实体的信息聚合到项目实体中,如表3所示。
5.2.3 模型深度的影响
为了评估层栈的有效性,我们对不同的层数进行了实验。层数被认为是模型的深度。在我们的模型中,知识图谱嵌入和推荐部分都使用MKGAT层,所以我们分别讨论知识图谱嵌入部分和推荐部分。在讨论知识图谱嵌入部分时,我们将推荐部分的MKGAT层数固定为2;在讨论推荐部分时,我们将知识图谱嵌入部分的MKGAT层数固定为2。 实验结果见表4。
不同的模型深度(即不同的MKGAT层数)对知识图谱嵌入(标记为KGE)和推荐(标记为REC)的影响可以总结为以下几点。
- 对于知识图谱嵌入,在MovieLens数据集中,随着MKGAT层数的增加,评价指标(即召回率和ndcg)也在增加。这证明了邻域信息融合在知识图谱嵌入中的有效性。在大众点评的数据集中,随着MKGAT层数的增加,评价指标先增长后下降。这可能是由于大众点评数据的多跳信息比较稀疏造成的。结合表3的结果,我们可以看出,与那些独立考虑知识图谱实体三联体的方法(如KGAT)相比,我们的方法(在做知识图谱嵌入时考虑了邻居实体的信息)可以为推荐提供更高质量的实体嵌入。
- 当提到推荐部分时,随着MKGAT层数的增加,两个数据集的评价指标首先增长,这验证了不同跳数的知识图谱嵌入对推荐系统有帮助。然而,当两个数据集的层数大于2时,评价指标将下降。换句话说,当层数增加到一定程度时,评价指标会下降。这可能是由于数据的稀缺性造成的过度拟合。
5.2.4 组合层的影响
在这组实验中,我们研究了我们模型中组合层的效果。具体来说,我们使用两种类型的聚合层,即添加层和连接层,来学习知识图的嵌入。表5总结了实验结果,表明采用连接层的方法(用CONCAT标记)要优于采用添加层的方法(用ADD标记)。
一个可能的原因是,每个实体的相邻实体包含文本和视觉信息,这些信息与知识图谱中的一般实体是不一致的。它们不在同一个语义空间中。事实上,ADD是一种逐个元素的特征交互方法,它适用于同一语义空间的特征。因为在同一语义空间中,每个特征的每个维度的含义都是相同的,所以将每个特征的每个维度都加起来是合理的。然而,CONCAT是对特征之间维度的扩展,它更适合于不同语义空间中特征的交互。
5.3 案例分析
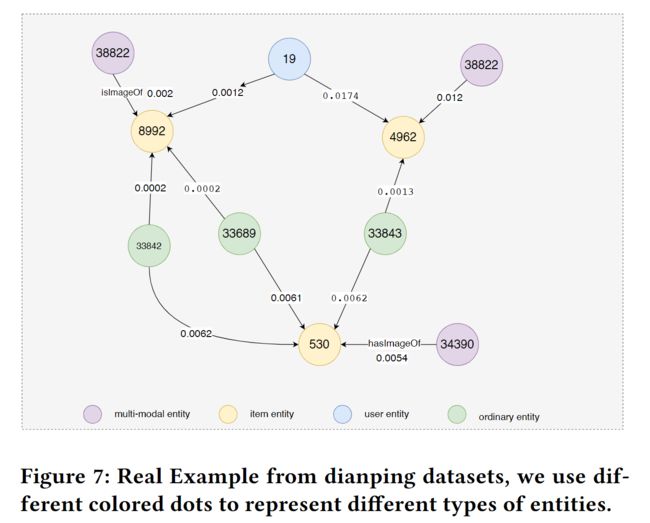
为了直观地证明多模式实体在MKGAT模型中的作用,我们通过从大众点评数据集中随机选择一个用户和一个相关项目来进行案例研究。受益于注意力机制,我们可以计算出候选项目和实体(或项目和用户)之间的相关性分数(未标准化)。我们还可以观察每个实体和其他实体之间的相关性分数。相关性分数越高,模型认为当前实体对模型的影响越大。我们在图7中直观地展示了相关性分数。在图7中,对于项目实体(即项目实体8992、4962和530),它们的相邻实体包括多模态实体和非多模态实体(交互或普通KG实体)。我们将每个项目实体和其相邻实体的边缘权重可视化,如图7所示。在协作知识图中,多模态关系通常具有相对较高的相关性得分,表明多模态实体的重要性。
6 Conclusion and Future Work
在本文中,我们提出了一个新颖的基于KG的推荐模型,即多模态知识图谱关注网络(MKGAT),它创新性地将多模态知识图谱引入了推荐系统。通过学习实体之间的推理关系,并将每个实体的相邻实体信息聚合到自己身上,MKGAT模型可以使
更好地利用多模态实体信息。在两个真实世界的数据集上进行的大量实验证明了我们提出的MKGAT模型的合理性和有效性。这项工作代表了探索多模式知识图在推荐系统中使用的初步尝试,在此基础上可以进行进一步有趣的研究。例如,在多模态知识图的框架下,自然可以探索更多的多模态融合方式,如张量融合网络(TFN)[34]或低秩多模态融合(LMF)[14]。
参考文献
[1] Sanjeev Arora, Yingyu Liang, and Tengyu Ma. 2016. A simple but tough-to-beat baseline for sentence embeddings. (2016).
[2] Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. In Advances in neural information processing systems. 2787–2795.
[3] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255.
[4] Xavier Glorot and Yoshua Bengio. 2010. Understanding the difficulty of training
deep feedforward neural networks. In Proceedings of the thirteenth international
conference on artificial intelligence and statistics. 249–256.
[5] Maoxiang Hao, Zhixu Li, Yan Zhao, and Kai Zheng. 2018. Mining High-Quality
Fine-Grained Type Information from Chinese Online Encyclopedias. In Interna-
tional Conference on Web Information Systems Engineering. 345–360.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual
learning for image recognition. In Proceedings of the IEEE conference on computer
vision and pattern recognition. 770–778.
[7] Xiangnan He and Tat-Seng Chua. 2017. Neural factorization machines for sparse
predictive analytics. In Proceedings of the 40th International ACM SIGIR conference
on Research and Development in Information Retrieval. 355–364.
[8] Andrej Karpathy and Li Fei-Fei. 2015. Deep visual-semantic alignments for
generating image descriptions. In Proceedings of the IEEE conference on computer
vision and pattern recognition. 3128–3137.
[9] Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti-
mization. arXiv preprint arXiv:1412.6980 (2014).
[10] Thomas N Kipf and Max Welling. 2016. Semi-supervised classification with graph
convolutional networks. arXiv preprint arXiv:1609.02907 (2016).
[11] Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization tech-
niques for recommender systems. Computer 42, 8 (2009), 30–37.
[12] Qianyu Li, Xiaoli Tang, Tengyun Wang, Haizhi Yang, and Hengjie Song. 2019.
Unifying task-oriented knowledge graph learning and recommendation. IEEE
Access 7 (2019), 115816–115828.
[13] Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, and Xuan Zhu. 2015. Learning
entity and relation embeddings for knowledge graph completion. In Twenty-ninth
AAAI conference on artificial intelligence.
[14] Zhun Liu, Ying Shen, Varun Bharadhwaj Lakshminarasimhan, Paul Pu Liang,
Amir Zadeh, and Louis-Philippe Morency. 2018. Efficient low-rank multimodal
fusion with modality-specific factors. arXiv preprint arXiv:1806.00064 (2018).
[15] Andrew L Maas, Awni Y Hannun, and Andrew Y Ng. [n.d.]. Rectifier nonlinearities
improve neural network acoustic models.
[16] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013.
Distributed representations of words and phrases and their compositionality. In
Advances in neural information processing systems. 3111–3119.
[17] Hatem Mousselly-Sergieh, Teresa Botschen, Iryna Gurevych, and Stefan Roth.
2018. A multimodal translation-based approach for knowledge graph represen-
tation learning. In Proceedings of the Seventh Joint Conference on Lexical and
Computational Semantics. 225–234.
[18] Tu Dinh Nguyen, Dat Quoc Nguyen, Dinh Phung, et al. 2018. A Novel Embed-
ding Model for Knowledge Base Completion Based on Convolutional Neural
Network. In Proceedings of the 2018 Conference of the North American Chapter
of the Association for Computational Linguistics: Human Language Technologies,
Volume 2 (Short Papers). 327–333.
[19] Pouya Pezeshkpour, Liyan Chen, and Sameer Singh. 2018. Embedding Multimodal
Relational Data for Knowledge Base Completion. In Proceedings of the 2018
Conference on Empirical Methods in Natural Language Processing. 3208–3218.
[20] Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme.
2012. BPR: Bayesian personalized ranking from implicit feedback. arXiv preprint
arXiv:1205.2618 (2012).
[21] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones,
Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all
you need. In Advances in neural information processing systems. 5998–6008.
[22] Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro
Lio, and Yoshua Bengio. 2017. Graph attention networks. arXiv preprint
arXiv:1710.10903 (2017).
[23] Hongwei Wang, Fuzheng Zhang, Min Hou, Xing Xie, Minyi Guo, and Qi Liu. 2018.
Shine: Signed heterogeneous information network embedding for sentiment link
prediction. In Proceedings of the Eleventh ACM International Conference on Web
Search and Data Mining. 592–600.
[24] Hongwei Wang, Fuzheng Zhang, Jialin Wang, Miao Zhao, Wenjie Li, Xing Xie,
and Minyi Guo. 2018. Ripplenet: Propagating user preferences on the knowledge
graph for recommender systems. In Proceedings of the 27th ACM International
Conference on Information and Knowledge Management. 417–426.
[25] Hongwei Wang, Fuzheng Zhang, Xing Xie, and Minyi Guo. 2018. DKN: Deep
knowledge-aware network for news recommendation. In Proceedings of the 2018
world wide web conference. 1835–1844.
[26] Hongwei Wang, Fuzheng Zhang, Mengdi Zhang, Jure Leskovec, Miao Zhao,
Wenjie Li, and Zhongyuan Wang. 2019. Knowledge-aware graph neural networks
with label smoothness regularization for recommender systems. In Proceedings of
the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data
Mining. 968–977.
[27] Quan Wang, Zhendong Mao, Bin Wang, and Li Guo. 2017. Knowledge graph
embedding: A survey of approaches and applications. IEEE Transactions on
Knowledge and Data Engineering 29, 12 (2017), 2724–2743.
[28] Xiang Wang, Xiangnan He, Yixin Cao, Meng Liu, and Tat-Seng Chua. 2019. Kgat:
Knowledge graph attention network for recommendation. In Proceedings of the
25th ACM SIGKDD International Conference on Knowledge Discovery & Data
Mining. 950–958.
[29] Yinwei Wei, Xiang Wang, Liqiang Nie, Xiangnan He, Richang Hong, and Tat-Seng
Chua. 2019. MMGCN: Multi-modal Graph Convolution Network for Personalized
Recommendation of Micro-video. In Proceedings of the 27th ACM International
Conference on Multimedia. 1437–1445.
[30] Ruobing Xie, Zhiyuan Liu, Huanbo Luan, and Maosong Sun. 2016. Image-
embodied knowledge representation learning. arXiv preprint arXiv:1609.07028
(2016).
[31] Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi
Kawarabayashi, and Stefanie Jegelka. 2018. Representation learning on graphs
with jumping knowledge networks. arXiv preprint arXiv:1806.03536 (2018).
[32] Zichao Yang, Xiaodong He, Jianfeng Gao, Li Deng, and Alex Smola. 2016. Stacked
attention networks for image question answering. In Proceedings of the IEEE
conference on computer vision and pattern recognition. 21–29.
[33] Xiao Yu, Xiang Ren, Yizhou Sun, Quanquan Gu, Bradley Sturt, Urvashi Khandel-
wal, Brandon Norick, and Jiawei Han. 2014. Personalized entity recommendation:
A heterogeneous information network approach. In Proceedings of the 7th ACM
international conference on Web search and data mining. 283–292.
[34] Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe
Morency. 2017. Tensor fusion network for multimodal sentiment analysis. arXiv
preprint arXiv:1707.07250 (2017).
[35] Fuzheng Zhang, Nicholas Jing Yuan, Defu Lian, Xing Xie, and Wei-Ying Ma.
2016. Collaborative knowledge base embedding for recommender systems. In
Proceedings of the 22nd ACM SIGKDD international conference on knowledge
discovery and data mining. 353–362.
[36] Huan Zhao, Quanming Yao, Jianda Li, Yangqiu Song, and Dik Lun Lee. 2017. Meta-
graph based recommendation fusion over heterogeneous information networks.
In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge
Discovery and Data Mining. 635–644.