4.0 基于Hugging Face -Transformers的预训练模型微调.md
本文参考资料是Hugging Face主页Resources下的课程,节选部分内容并注释(加粗斜体),也加了Trainer和args的主要参数介绍。感兴趣的同学可以去查看原文。
本章节主要内容包含两部分内容:
- pipeline工具演示NLP任务处理
- 构建Trainer微调模型
目录
- 1. 简介
- Transformers的历史
- Architectures和checkpoints
- The Inference API
- 2. 用pipeline处理NLP问题
- 3. Behind the pipeline
- tokenizer预处理
- 选择模型
- Model heads
- Post-processing后处理
- 4. 构建Trainer API微调预训练模型
- 从Hub上下载dataset
- 数据集预处理
- 使用 Trainer API 在 PyTorch 中进行微调
- 训练
- 评估函数
- 5. 补充部分
- 为什么教程第四章都是用Trainer来微调模型?
- TrainingArguments主要参数
- 不同的模型加载方式
- Dynamic padding——动态填充技术
1. 简介
本章节将使用 Hugging Face 生态系统中的库—— Transformers来进行自然语言处理工作(NLP)。
Transformers的历史
以下是 Transformer 模型(简短)历史中的一些参考点:
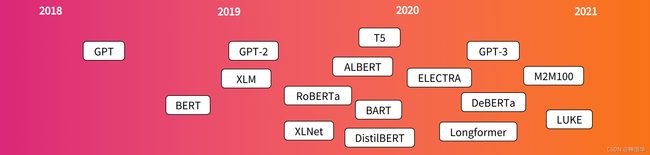
Transformer 架构于 2017 年 6 月推出。原始研究的重点是翻译任务。随后推出了几个有影响力的模型,包括:
- 2018 年 6 月:GPT,第一个预训练的 Transformer 模型,用于各种 NLP 任务的微调并获得最先进的结果
- 2018 年 10 月:BERT,另一个大型预训练模型,该模型旨在生成更好的句子摘要(下一章将详细介绍!)
- 2019 年 2 月:GPT-2,GPT 的改进(和更大)版本,由于道德问题未立即公开发布
- 2019 年 10 月:DistilBERT,BERT 的蒸馏版本,速度提高 60%,内存减轻 40%,但仍保留 BERT 97% 的性能
- 2019 年 10 月:BART 和 T5,两个使用与原始 Transformer 模型相同架构的大型预训练模型(第一个这样做)
- 2020 年 5 月,GPT-3,GPT-2 的更大版本,无需微调即可在各种任务上表现良好(称为零样本学习zero-shot learning)
这个列表并不全,只是为了突出一些不同类型的 Transformer 模型。大体上,它们可以分为三类:
- GPT类(只使用transformer-decoder部分,自回归 Transformer 模型)
- BERT类(只使用transformer-encoder部分,自编码 Transformer 模型)
- BART/T5 类(Transformer-encoder-decoder模型)
Architectures和checkpoints
对Transformer模型的研究中,会出现一些术语:架构Architecture和检查点checkpoint以及Model。 这些术语的含义略有不同:
Architecture:定义了模型的基本结构和基本运算
checkpoint:模型的某个训练状态,加载此checkpoint会加载此时的权重。(训练时可以选择自动保存checkpoint)
Model:这是一个总称,不像“架构”或“检查点”那样精确,它可以同时表示两者。 当需要减少歧义时,本课程将指定架构或检查点。
例如,BERT 是一种 Architectures,而 bert-base-cased(谷歌团队为 BERT 的第一个版本训练的一组权重)是一个checkpoints。 但是,可以说“the BERT model”和“the bert-base-cased model”。
checkpoint概念在大数据里面说的比较多。模型在训练时可以设置自动保存于某个时间点(比如模型训练了一轮epoch,更新了参数,将这个状态的模型保存下来,为一个checkpoint。)
所以每个checkpoint对应模型的一个状态,一组权重。大数据中检查点是一个数据库事件,存在的根本意义是减少崩溃时间。即减少因为意外情况数据库崩溃后重新恢复的时间。
The Inference API
Model Hub(模型中心)包含多语言模型的checkpoints。您可以通过单击语言标签来优化对模型的搜索,然后选择生成另一种语言文本的模型。
通过单击选择模型后,您会看到有一个小部件——Inference API(支持在线试用)。即您可以直接在此页面上使用各种模型,通过输入自定义文本就可以看到模型处理输入数据后的结果。 通过这种方式,您可以在下载模型之前快速测试模型的功能。
2. 用pipeline处理NLP问题
在本节中,我们将看看 Transformer 模型可以做什么,并使用 Transformers 库中的第一个工具:管道pipeline。
Transformers 库提供了创建和使用共享模型的功能.。Model Hub包含数千个所有人都可以下载和使用的预训练模型。 您也可以将自己的模型上传到 Hub!
Transformers 库中最基本的对象是pipeline。 它将模型与其必要的预处理和后处理步骤连接起来,使我们能够直接输入任何文本并获得可理解的答案:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("I've been waiting for a HuggingFace course my whole life.")
[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
我们甚至可以传入几个句子!
classifier([
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!"
])
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
默认情况下,此管道选择一个特定的预训练模型,该模型已针对英语情感分析进行了微调。 创建分类器对象时,将下载并缓存模型。 如果您重新运行该命令,则将使用缓存的模型,无需再次下载模型。
将一些文本传递到管道时涉及三个主要步骤:
- 预处理:文本被预处理为模型可以理解的格式。
- 输入模型:构建模型,并将预处理的输入传递给模型。
- 后处理:模型的预测是经过后处理的,因此您可以理解它们。
目前可用的一些管道是:
- feature-extraction (获取文本的向量表示)
- fill-mask填充给定文本中的空白(完形填空)
- ner (named entity recognition)词性标注
- question-answering问答
- sentiment-analysis情感分析
- summarization摘要生成
- text-generation文本生成
- translation翻译
- zero-shot-classification零样本分类
您也可以从 Hub 中针对特定任务来选择特定模型的管道 例如,文本生成。转到 Model Hub并单击左侧的相应标签,页面将会仅显示文本生成任务支持的模型。
(除了模型要匹配任务,更进一步考虑的因素之一是:预训练模型训练时使用的数据集,要尽可能的接近你需要处理的任务所包含的数据集,两个数据集越接近越好。)
Transformers pipeline API 可以处理不同的 NLP 任务。您可以使用完整架构,也可以仅使用编码器或解码器,具体取决于您要解决的任务类型。 下表总结了这一点:
| 模型 | 例子 | 任务 |
|---|---|---|
| Encoder | ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa | 句子分类、命名实体识别、抽取式问答 |
| Decoder | CTRL, GPT, GPT-2, Transformer XL | 文本生成 |
| Encoder-decoder | BART, T5, Marian, mBART | 摘要生成、翻译、生成式问答 |
以上显示的pipeline主要用于演示目的。 它们是为特定任务编程的,不能执行它们的变体。 在下一节中,您将了解管道内部的内容以及如何自定义其行为。
上面这几种管道的简单示例可以查看——Hugging Face主页课程第一篇《Transformer models》。
或单击Open in Colab以打开包含其它管道应用代码示例的 Google Colab 笔记本。
如果您想在本地运行示例,我们建议您查看设置。
3. Behind the pipeline
本节代码:Open in Colab (PyTorch)
YouTube视频:what happend inside the pipeline function
让我们从一个完整的例子开始,看看当我们在第1节中执行以下代码时,幕后发生了什么:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier([
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
])
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
正如我们在第 1 章中看到的,这个管道将三个步骤组合在一起:预处理、通过模型传递输入和后处理:
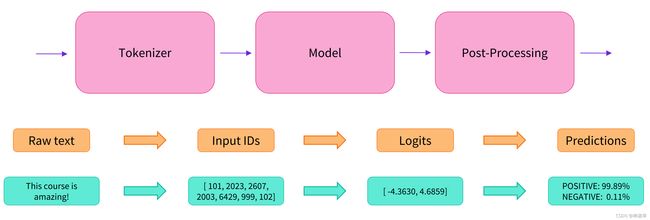
让我们快速浏览一下这些内容。
tokenizer预处理
与其他神经网络一样,Transformer 模型不能直接处理原始文本,因此我们管道的第一步是将文本输入转换为模型可以理解的数字。为此,我们使用了一个分词器tokenizer,它将负责:
- 将输入拆分为称为标记的单词、子词subword或符号symbols(如标点符号)
- 将每个标记映射到一个整数
- 添加可能对模型有用的其他输入
使用 AutoTokenizer 类及其 from_pretrained 方法,以保证所有这些预处理都以与模型预训练时完全相同的方式完成。设定模型的 checkpoint名称,它会自动获取与模型的Tokenizer关联的数据并缓存它(所以它只在你第一次运行下面的代码时下载)。
由于情感分析管道的默认检查点是 distilbert-base-uncased-finetuned-sst-2-english,我们可以运行以下命令得到我们需要的tokenizer:
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
#return_tensors="pt"表示返回Pytorch张量。文本转换为数字之后必须再转换成张量tensors才能输入模型。
#padding=True表示填充输入序列到最大长度,truncation=True表示过长序列被截断
print(inputs)
以下是 PyTorch 张量的结果:
{
'input_ids': tensor([
[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
])
}
选择模型
我们可以像使用分词器一样下载我们的预训练模型。 Transformers 提供了一个 AutoModel 类,它也有一个 from_pretrained 方法:
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
AutoModel 类及其所有相关类实际上是库中各种可用模型的简单包装器。 它可以自动为您的checkpoint猜测合适的模型架构,然后使用该架构实例化模型。(即AutoModel 类可以从checkpoint实例化任何模型,而且这是一种更好的实例化模型方法。构建模型还有另一种方法,放在文末。)
在此代码片段中,我们下载了之前在管道中使用的相同checkpoint(它实际上应该已经被缓存)并用它实例化了一个模型。但是这个架构只包含基本的 Transformer 模块:给定一些输入,它输出我们称之为隐藏状态hidden states的东西。虽然这些隐藏状态本身就很有用,但它们通常是模型另一部分(model head)的输入。
Model heads
我们可以使用相同的模型体系结构执行不同的任务,但是每个任务都有与之关联的不同的Model heads。
Model heads:将隐藏状态的高维向量(也就是logits向量)作为输入,并将它们投影到不同的维度上。 它们通常由一个或几个线性层组成:
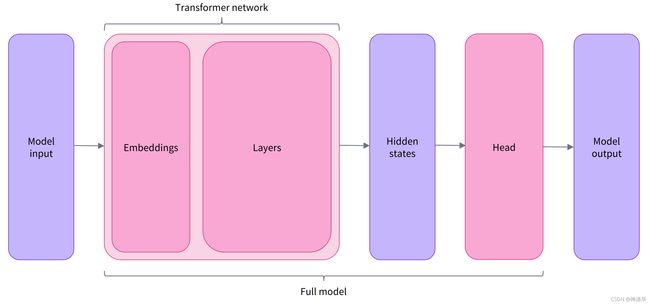
在此图中,模型由其embeddings layer和后续层表示。输入数据经过embeddings layer输出logits向量以产生句子的最终表示。
Transformers 中有许多不同的架构可用,每一种架构都围绕着处理特定任务而设计。 下面列举了部分Model heads:
- Model (retrieve the hidden states)
- ForCausalLM
- ForMaskedLM
- ForMultipleChoice
- ForQuestionAnswering
- ForSequenceClassification
- ForTokenClassification
- and others
以情感分类为例,我们需要一个带有序列分类的Model head(能够将句子分类为正面或负面)。 因此,我们实际上不会使用 AutoModel 类,而是使用 AutoModelForSequenceClassification:
(也就是说前面写的model = AutoModel.from_pretrained(checkpoint)并不能得到情感分类任务的结果,因为没有加载Model head)
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
model head将我们之前看到的高维向量作为输入,并输出包含两个值(每个标签一个)的向量:
print(outputs.logits.shape)
torch.Size([2, 2])
由于我们只有两个句子和两个标签,因此我们从模型中得到的结果是 2 x 2 的形状。
Post-processing后处理
我们从模型中获得的作为输出的值本身并不一定有意义。 让我们来看看:
print(outputs.logits)
tensor([[-1.5607, 1.6123],
[ 4.1692, -3.3464]], grad_fn=<AddmmBackward>)
我们的模型预测了第一个句子结果 [-1.5607, 1.6123] 和第二个句子的结果 [4.1692, -3.3464]。 这些不是概率,而是 logits,即模型最后一层输出的原始非标准化分数。 要转换为概率,它们需要经过一个 SoftMax 层。所有 Transformers 模型都输出 logits,这是因为训练的损失函数一般会将最后一个激活函数(比如SoftMax)和实际的交叉熵损失函数相融合。
(补充:在Pytorch里面,交叉熵损失CEloss不是数学上的交叉熵损失(NLLLoss)。Pytorch的CrossEntropyLoss就是把Softmax–Log–NLLLoss合并成一步。详细内容可以参考知乎文章《如何理解NLLLoss?》)
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
tensor([[4.0195e-02, 9.5980e-01],
[9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward>)
这次输出是可识别的概率分数。
要获得每个位置对应的标签,我们可以检查模型配置的 id2label 属性:
model.config.id2label
{0: 'NEGATIVE', 1: 'POSITIVE'}
现在我们可以得出结论,该模型预测了以下内容:
第一句:NEGATIVE:0.0402,POSITIVE:0.9598
第二句:NEGATIVE:0.9995,POSITIVE:0.0005
4. 构建Trainer API微调预训练模型
本节代码:Open in Colab(PyTorch),建议点此进行测试。colab上加载数据集非常快,设置GPU后训练也比较快。
打开后选择左上方“修改”选项卡,点击笔记本设置-硬件加速器None改成GPU就行。
在第3节中,我们探讨了如何使用分词器和预训练模型进行预测。 但是,如果您想为自己的数据集微调预训练模型怎么办? 这就是本章的主题! 你将学习:
- 如何从Model Hub 准备大型数据集
- 如何使用high-level Trainer API来微调模型
- 如何使用自定义训练循环a custom training loop
- 如何利用 Accelerate 库在任何分布式设置上轻松运行该custom training loop
从Hub上下载dataset
Youtube 视频:Hugging Face Datasets Overview(pytorch)
Hub 不仅包含模型;还含有多个datasets,这些datasets有很多不同的语言。我们建议您在完成本节后尝试加载和处理新数据集(参考文档)。
MRPC 数据集是构成 GLUE 基准的 10 个数据集之一。而GLUE 基准是一种学术基准,用于衡量 ML 模型在 10 个不同文本分类任务中的性能。
Datasets库提供了一个非常简单的命令来下载和缓存Hub上的dataset。 我们可以像这样下载 MRPC 数据集:
from datasets import load_dataset
raw_datasets = load_dataset("glue", "mrpc")
raw_datasets
DatasetDict({
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
validation: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 408
})
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1725
})
})
这样就得到一个DatasetDict对象,包含训练集、验证集和测试集,训练集中有3,668 个句子对,验证集中有408对,测试集中有1,725 对。每个句子对包含四列数据:‘sentence1’, ‘sentence2’, 'label’和 ‘idx’。
load_dataset 方法, 可以从不同的地方构建数据集
- from the HuggingFace Hub,
- from local files, 如CSV/JSON/text/pandas files
- from in-memory data like python dict or a pandas dataframe.
例如: datasets = load_dataset(“text”, data_files={“train”: path_to_train.txt, “validation”: path_to_validation.txt} 具体可以参考文档
load_dataset命令下载并缓存数据集,默认在 ~/.cache/huggingface/dataset 中。您可以通过设置 HF_HOME 环境变量来自定义缓存文件夹。
和字典一样,raw_datasets 可以通过索引访问其中的句子对:
raw_train_dataset = raw_datasets["train"]
raw_train_dataset[0]
{'idx': 0,
'label': 1,
'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .'}
import pandas as pd
validation=pd.DataFrame(raw_datasets['validation'])
validation

可见标签已经是整数,不需要再做任何预处理。通过raw_train_dataset的features属性可以知道每一列的类型:
raw_train_dataset.features
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
'idx': Value(dtype='int32', id=None)}
label是 ClassLabel 类型,label=1表示这对句子互为paraphrases,label=0表示句子对意思不一致。
数据集预处理
YouTube视频《Preprocessing sentence pairs》
通过tokenizer可以将文本转换为模型能理解的数字。
from transformers import AutoTokenizer
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
让我们看一个示例:
inputs = tokenizer("This is the first sentence.", "This is the second one.")
inputs
{ 'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
所以将句子对列表传给tokenizer,就可以对整个数据集进行分词处理。因此,预处理训练数据集的一种方法是:
tokenized_dataset = tokenizer(
raw_datasets["train"]["sentence1"],
raw_datasets["train"]["sentence2"],
padding=True,
truncation=True,
)
这种处理方法是ok的,但缺点是处理之后tokenized_dataset不再是一个dataset格式,而是返回字典(带有我们的键:input_ids、attention_mask 和 token_type_ids,对应的键值对的值)。 而且一旦我们的dataset过大,无法放在内存中,那么这样子的做法会导致 Out of Memory 的异常。( Datasets 库中的数据集是存储在磁盘上的 Apache Arrow 文件,因此请求加载的样本都保存在内存中)。
为了使我们的数据保持dataset的格式,我们将使用更灵活的Dataset.map 方法。此方法可以完成更多的预处理而不仅仅是 tokenization。 map 方法是对数据集中的每个元素应用同一个函数,所以让我们定义一个函数来对输入进行tokenize预处理:
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
这个函数接受的是一个字典(就像我们dataset的items),返回的也是一个字典(有三个键:input_ids、attention_mask 和 token_type_ids )。
在tokenization函数中省略了padding 参数,这是因为padding到该批次中的最大长度时的效率,会高于所有序列都padding到整个数据集的最大序列长度。 当输入序列长度很不一致时,这可以节省大量时间和处理能力!
以下是对整个数据集应用tokenization方法。 我们在 map 调用中使用了 batched=True,因此该函数一次应用于数据集的整个batch元素,而不是分别应用于每个元素。 这样预处理速度会更快(因为 Tokenizers 库中的Tokenizer用 Rust 编写,一次处理很多输入时这个分词器可以非常快)。
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets
Datasets库应用这种处理的方式是向数据集添加新字段,如下所示:
DatasetDict({
train: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 3668
})
validation: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 408
})
test: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 1725
})
})
如果您没有使用由该库支持的fast tokenizer,Dataset.map函数进行预处理时可以设定num_proc 参数来进行多线程处理,加快预处理速度。
最后,当我们将输入序列进行批处理时,要将所有输入序列填充到本批次最长序列的长度——我们称之为动态填充技术dynamic padding(动态填充:即将每个批次的输入序列填充到一样的长度。具体内容放在最后)。
使用 Trainer API 在 PyTorch 中进行微调
由于 PyTorch 不提供封装好的训练循环, Transformers 库写了了一个transformers.Trainer API,它是一个简单但功能完整的 PyTorch 训练和评估循环,针对 Transformers 进行了优化,有很多的训练选项和内置功能,同时也支持多GPU/TPU分布式训练和混合精度。即Trainer API是一个封装好的训练器(Transformers库内置的小框架,如果是Tensorflow,则是TFTrainer)。
但是Trainer一开始是不存在的(早期版本并没有),而由于启动训练需要特别多的参数,各个nlp任务又有很多通用的参数,这些就被抽象出来了Trainer。更具体的理解,可以看看多多写的最原始版本的Trainer代码 。Trainer就是把训练开始之前需要的参数合并了起来。
数据预处理完成后,只需要几个简单的步骤来定义Trainer的参数,就可以进行模型的基本训练循环了(否则的话,要自己从头加载和预处理数据,设置各种参数,一步步编写训练循环。自定义训练循环的内容在本节最后)。
Trainer最困难的部分可能是准备运行 Trainer.train 的环境,因为它在 CPU 上运行速度非常慢。( 如果您没有设置 GPU,则可以在 Google Colab 上访问免费的 GPU 或 TPU)
trainer主要参数包括:
- Model:用于训练、评估或用于预测的模型
- args (TrainingArguments):训练调整的参数。如果未提供,将默认为 TrainingArguments 的基本实例
- data_collator(DataCollator,可选)– 用于批处理train_dataset 或 eval_dataset 的的函数
- train_dataset:训练集
- eval_dataset:验证集
- compute_metrics:用于计算评估指标的函数。必须传入EvalPrediction 并将返回一个字典,键值对是metric和其value。
- callbacks (回调函数,可选):用于自定义训练循环的回调列表(List of TrainerCallback)
- optimizers:一个包含优化器和学习率调整器的元组,默认优化器是AdamW,默认的学习率是线性的学习率,从5e-5 到 0
除了以上主要参数还有一些参数和属性(得有几十个吧,可以慢慢看。完整的Trainer文档可以参考这里)
下面的代码示例假定您已经执行了上一节中的示例:
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")#MRPC判断两个句子是否互为paraphrases
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)#动态填充,即将每个批次的输入序列填充到一样的长度
训练
Trainer 第一个参数是TrainingArguments类,是一个与训练循环本身相关的参数的子集,包含 Trainer中用于训练和评估的所有超参数。 唯一一个必须提供的参数是:保存model或者说是checkpoint的目录,其它参数可以选取默认值(比如默认训练3个epoch等)(TrainingArguments也有几十个参数,,常见参数写在文末,完整文档包含在上面说的Trainer文档里)
from transformers import TrainingArguments
training_args = TrainingArguments("test-trainer")
第二步:定义模型
和上一节一样,我们将使用 AutoModelForSequenceClassification 类,带有两个标签:
(其实就是根据自己的任务选择任务头task head,以便进行微调)
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)#标签数为2也就是二分类
在实例化此预训练模型后会报一个warning。 这是因为 BERT 没有在句子对分类方面进行过预训练,所以预训练模型的head已经被丢弃,而是添加了一个适合序列分类的new head。 警告表明一些权重没有使用(对应于丢弃的预训练head部分),而其他一些权重被随机初始化(new head部分), 最后鼓励您训练模型。
有了模型之后,就可以定义一个训练器Trainer,将迄今为止构建的所有对象传递给它进行模型精调。这些对象包括:model、training_args、训练和验证数据集、data_collator 和tokenizer。(这都是Trainer的参数):
from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
像上面这样传递tokenizer时,参数data_collator 是之前定义的动态填充DataCollatorWithPadding,所以此调用中的 data_collator=data_collator行可以跳过。(但是像之前一样写出这一步很重要It was still important to show you this part of the processing in section 2!)
要在我们的数据集上微调模型,我们只需要调用 Trainer 的 train方法:
trainer.train()
开始微调(在colab上用 GPU 6分钟左右),训练完毕显示:
The following columns in the training set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence1, sentence2, idx.
***** Running training *****
Num examples = 3668
Num Epochs = 3
Instantaneous batch size per device = 8
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 1
Total optimization steps = 1377
Step Training Loss
500 0.544700
1000 0.326500
TrainOutput(global_step=1377, training_loss=0.3773723704795865, metrics={'train_runtime': 379.1704, 'train_samples_per_second': 29.021, 'train_steps_per_second': 3.632, 'total_flos': 405470580750720.0, 'train_loss': 0.3773723704795865, 'epoch': 3.0})
#运行中只显示500 steps和1000 steps的结果,最终是1377 steps,最终loss是0.377
我们可以先看看验证集预处理后的结构:
tokenized_datasets["validation"]
Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 408
})
我们可以使用 Trainer.predict 命令获得模型的预测结果:
predictions = trainer.predict(tokenized_datasets["validation"])
print(predictions.predictions.shape, predictions.label_ids.shape)
(408, 2) (408,)
predict 方法输出一个具有三个字段的元组。
- predictions: 预测值,形状为:[batch_size, num_labels], 是logits 而不是经过softmax之后的结果
- label_ids:真实的的label id
- metrics:评价指标,默认是training loss,以及一些time metrics (预测所需的总时间和平均时间)。但是一旦我们传入了 compute_metrics 函数给 Trainer,那么该函数的返回值也会一并输出

metrics={'test_loss': 0.6269022822380066, 'test_runtime': 4.0653, 'test_samples_per_second': 100.362, 'test_steps_per_second': 12.545})
predictions是一个二维数组,形状为 408 x 2(验证集408组数据,两个标签)。 要预测结果与标签进行比较,我们需要在predictions第二个轴上取最大值的索引:
import numpy as np
preds = np.argmax(predictions.predictions, axis=-1)
同时,从上面训练过程可以看到:模型每 500 steps报告一次训练损失。 但是,它不会告诉您模型的表现如何。 这是因为:
- 没有设置evaluation_strategy 参数,告诉模型多少个“steps”(eval_steps)或“epoch”来评估一次损失。
- Trainer的compute_metrics 可以计算训练时具体的评估指标的值(比如acc、F1分数等等)。不设置compute_metrics 就只显示training loss,这不是一个直观的数字。
而如果我们将compute_metrics 函数写好并将其传递给Trainer后,metrics字段也将包含compute_metrics 返回的metrics值。
评估函数
现在看看如何构造compute_metrics 函数。这个函数:
- 必须传入 EvalPrediction 参数。 EvalPrediction是一个具有 predictions字段和 label_ids 字段的元组。
- 返回一个字典,键值对是key:metric 名字(string类型),value:metric 值(float类型)。
也就是教程4.1说的:直接调用metric的compute方法,传入labels和predictions即可得到metric的值。也只有这样做才能在训练时得到acc、F1等结果(具体指标根据不同任务来定)
为了构建我们的 compute_metric 函数,我们将依赖 Datasets 库中的metric。 通过 load_metric 函数,我们可以像加载数据集一样轻松加载与 MRPC 数据集关联的metric。The object returned has a compute method we can use to do the metric calculation:
from datasets import load_metric
metric = load_metric("glue", "mrpc")
metric.compute(predictions=preds, references=predictions.label_ids)
{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}#模型在验证集上的准确率为 85.78%,F1 分数为 89.97
每次训练时model head的随机初始化可能会改变最终的metric值,所以这里的最终结果可能和你跑出的不一样。 acc和F1 是用于评估 GLUE 基准的 MRPC 数据集结果的两个指标。 BERT 论文中的表格报告了基本模型的 F1 分数为 88.9。 那是un-cased模型,而我们目前使用的是cased模型,这说明了更好的结果。(cased就是指区分英文的大小写)
将以上内容整合到一起,得到 compute_metrics 函数:
def compute_metrics(eval_preds):
metric = load_metric("glue", "mrpc")
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
再设定每个epoch查看一次验证评估。所以下面就是我们设定compute_metrics参数之后的Trainer:
training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
请注意,我们创建了一个新的 TrainingArguments,其evaluation_strategy 设置为“epoch”和一个新模型——否则,我们只会继续训练我们已经训练过的模型。 要启动新的训练运行,我们执行:
trainer.train()
最终训练了6分33秒,比上一次稍微长了一点点。最后运行结果为:
The following columns in the training set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence1, sentence2, idx.
***** Running training *****
Num examples = 3668
Num Epochs = 3
Instantaneous batch size per device = 8
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 1
Total optimization steps = 1377
Epoch Training Loss Validation Loss Accuracy F1
1 No log 0.557327 0.806373 0.872375
2 0.552700 0.458040 0.862745 0.903448
3 0.333900 0.560826 0.867647 0.907850
TrainOutput(global_step=1377, training_loss=0.37862846690325436, metrics={'train_runtime': 393.5652, 'train_samples_per_second': 27.96, 'train_steps_per_second': 3.499, 'total_flos': 405470580750720.0, 'train_loss': 0.37862846690325436, 'epoch': 3.0})
这次,模型训练时会在training loss之外,还报告每个 epoch 结束时的 validation loss和metrics。 同样,由于模型的随机头部(task head)初始化,您达到的准确准确率/F1 分数可能与我们发现的略有不同,但它应该在同一范围内。
Trainer 默认支持 多GPU/TPU,也支持混合精度训练,可以在训练的配置 TrainingArguments 中,设置 fp16 = True。
使用Trainer 很方便,但是高级的封装API也会有其弊端,就是无法进行很多自定义的操作。所以我们可以采用常规的 pytorch 的训练方法,自定义训练循环。还可以选择使用Accelerate库进行分布式训练(之前的例子都是使用单个GPU/CPU)。这部分内容不做要求,感兴趣的可以查看原文《A full training》,或者翻译《微调预训练模型》。
5. 补充部分
为什么教程第四章都是用Trainer来微调模型?
预训练模型有两种用法:
- 特征提取(预训练模型不做后续训练,不调整权重)
- 微调(根据下游任务简单训练几个epoch,调整预训练模型权重)
BERT论文第五部分(实验)写的,虽然BERT做NLP任务有两种方法,但是不建议不训练模型,就直接输出结果来预测。而且Hugging Face的作者也推荐大家使用Trainer来训练模型。
实际中,微调的效果也会明显好于特征提取(除非头铁,特征提取后面接一个很复杂的模型)。
至于为什么用Trainer来微调,之前也已经说了:Trainer是专门为Transformers写的一个PyTorch训练和评估循环API,使用相对简单一点。否则就要自定义训练循环。
这一小段是我的理解,不在HF主页课程中。
TrainingArguments主要参数
TrainingArguments参数有几十个,后面章节用到的主要有:
- output_dir (str) :model predictions和检查点的保存目录。保存后的模型可以使用管道加载,在下次预测时使用,详见《使用huggingface transformers全家桶实现一条龙BERT训练和预测》
- evaluation_strategy :有三个选项
- “no”:训练时不做任何评估
- “step”:每个 eval_steps 完成(并记录)评估
- “epoch”:在每个 epoch 结束时进行评估。
- learning_rate (float, 可选) – AdamW 优化器学习率,defaults to 5e-5
- weight_decay (float, 可选,默认 0) :如果不是0,就是应用于所有层的权重衰减,除了 AdamW 优化器中的所有偏差和 LayerNorm 权重。关于weight decay可参考知乎文章都9102年了,别再用Adam + L2 regularization了。
- save_strategy (str 或 IntervalStrategy, 可选, 默认为 “steps”) :在训练期间采用的检查点保存策略。可能的值为:
- “no”:训练期间不保存
- “epoch”:在每个epoch结束时进行保存
- “steps”:每个step保存一次。
- fp16 (bool, 可选, 默认False) –是否使用 16 位(混合)精度训练而不是 32 位训练。
- metric_for_best_model (str, 可选) :与 load_best_model_at_end 结合使用以指定用于比较两个不同模型的metric 。必须是评估返回的metric 的名称,带或不带前缀“eval_”。
- num_train_epochs (float, 可选,默认是3) – 要训练的epoch数
- load_best_model_at_end (bool, 可选, 默认为 False) :是否在训练结束时加载训练过程中找到的最佳模型。
不同的模型加载方式
AutoModel 类及其所有相关类实际上是库中各种可用模型的简单包装器。 它可以自动为您的checkpoint猜测合适的模型架构,然后使用该架构实例化模型。
但是,如果您知道要使用的模型类型,则可以直接使用定义其架构的类。 让我们来看看它如何与 BERT 模型配合使用。
初始化 BERT 模型需要做的第一件事是加载配置对象:
from transformers import BertConfig, BertModel
# Building the config
config = BertConfig()
# Building the model from the config
model = BertModel(config)
config配置包含了许多用于构建模型的属性:
print(config)
BertConfig {
[...]
"hidden_size": 768, #hidden_states 向量的大小
"intermediate_size": 3072, #FFN第一层神经元个数,即attention层传入第一层全连接会扩维4倍
"max_position_embeddings": 512,#最大序列长度512
"num_attention_heads": 12,
"num_hidden_layers": 12,
[...]
}
hidden_size : hidden_states 向量的大小
num_hidden_layers :Transformer 模型的层数
从默认配置创建模型会使用随机值对其进行初始化:
from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)
# 模型已经随机初始化了
模型可以在这种状态下使用,但是会输出乱码; 它需要先训练。 我们可以根据手头的任务从头开始训练模型,这将需要很长时间和大量数据。
使用 from_pretrained 方法来加载一个已经训练过的 Transformer 模型:
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")
正如您之前看到的,我们可以用 AutoModel 类替换 BertModel,效果是一样的。后面我们会使用AutoModel类,这样做的好处是设定模型结构的部分可以不影响checkpoint。如果您的代码适用于一个checkpoint,那么也可以用于另一个checkpoint。甚至即使模型结构不同,只要checkpoint是针对类似任务训练的,也适用。
使用AutoModel类,传入不同的ckeckpoint,就可以实现不同的模型,来处理任务(只要这个模型的输出可以处理此任务)。如果选择BertModel这样的,模型结构就定死了。
在上面的代码示例中,我们没有使用 BertConfig(BertConfig是初始化的模型,没有经过任何训练),而是通过标识符"bert-base-cased"加载了一个预训练模型的checkpoint,这个checkpoint由 BERT 的作者自己训练。您可以在其model card中找到有关它的更多详细信息。
该模型现在已使用checkpoint的所有权重进行初始化。它可以直接用于对训练过的任务进行推理,也可以在新任务上进行微调。
权重已下载并缓存在缓存文件夹中(因此以后对 from_pretrained 方法的调用不会重新下载它们),该文件夹默认为 ~/.cache/huggingface/transformers。您可以通过设置 HF_HOME 环境变量来自定义缓存文件夹。
用于加载模型的标识符可以是 Model Hub 上任何模型的标识符,只要它与 BERT 架构兼容即可。 可以在此处找到 BERT 检查点的完整列表。
Dynamic padding——动态填充技术
youtube视频:《what is Dynamic padding》
在 PyTorch 中,DataLoader有一个参数——collate 函数。它负责将一批样本放在一起,默认是一个函数,所以叫整理函数。它将您的样本转换为 PyTorch 张量进行连接(如果您的元素是列表、元组或字典,则递归)。
由于我们所拥有的输入序列长度不同,所以需要对输入序列进行填充(作为模型的输入,同批次的各张量必须是同一长度)。前面说过,padding到该批次中的最大长度时的效率,会高于所有序列都padding到整个数据集的最大序列长度。
注意:如果使用TPU,则还是需要padding 到模型的 max length,因为TPU这样子效率更高。
为了在实践中做到这一点,我们必须定义一个 collate 函数,它将对批处理数据应用正确的填充数量。(对于不同的batch 数据,进行不同长度的padding。) Transformers 库通过 DataCollatorWithPadding 为我们提供了这样的功能。当您实例化它时,它需要一个tokenizer(以了解要使用哪个填充token,以及模型希望填充在输入的左侧还是右侧),并且会执行您需要的所有操作:
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
为了测试,我们从训练集中选取我们想要一起批处理的样本。这里需要删除 idx、sentence1 和 sentence2 列,因为不需要这些列并且它们包含字符串(不能创建张量)。查看批处理中每个输入的长度:
samples = tokenized_datasets["train"][:8]
samples = {
k: v for k, v in samples.items() if k not in ["idx", "sentence1", "sentence2"]
}
[len(x) for x in samples["input_ids"]]
[50, 59, 47, 67, 59, 50, 62, 32]
我们得到了不同长度的序列。动态填充意味着该批次中的序列都应该填充到 67 的长度。 如果没有动态填充,所有样本都必须填充到整个数据集中的最大长度,或者模型可以接受的最大长度。 让我们仔细检查我们的 data_collator 是否正确地动态填充批处理:
batch = data_collator(samples)
{k: v.shape for k, v in batch.items()}
{'attention_mask': torch.Size([8, 67]),
'input_ids': torch.Size([8, 67]),
'token_type_ids': torch.Size([8, 67]),
'labels': torch.Size([8])}
Tips:以上加粗的斜体字都是笔者的注释,是对原文部分内容的解读。本教程中如果发现问题请及时反馈,谢谢。