AAAI 2021 | 自动写歌:基于预训练和对齐约束的自动歌曲创作

©作者 | 盛中昊
学校 | 北京大学硕士
研究方向 | 自然语言处理
本工作由北京大学 KCL 实验室与南京理工大学、微软亚洲研究院、浙江大学共同提出。KCL(Knowledge Computing Lab,知识计算实验室)是北大软件工程国家工程研究中心一支 20 多人的研究团队,主要研究领域包括:信息抽取、信息检索、文本生成、程序语言理解等。

本文介绍我们发表于 AAAI 2021 的论文《SongMASS: Automatic Song Writing with Pre-training and Alignment Constraint》。该论文提出了 SongMASS,一种歌曲旋律生成和歌词文本生成的方法。我们使用扩展的 Masked Seq2Seq (MASS)预训练方法缓解平行语料稀缺的问题,设计句子级和字符级的注意力约束增强歌词和旋律对齐,并在推理阶段使用动态规划算法对齐歌词和旋律。

论文标题:
SongMASS: Automatic Song Writing with Pre-training and Alignment Constraint
论文作者:
Zhonghao Sheng, Kaitao Song, Xu Tan, Yi Ren, Wei Ye, Shikun Zhang, Tao Qin
论文链接:
https://arxiv.org/pdf/2012.05168.pdf

背景
自动歌曲写作在学术界和工业界一直是令人感兴趣的话题,由歌词生成旋律(Lyric-to-Melody,L2M)和由旋律生成歌词(Melody-to-Lyric,M2L)是其中两个重要的任务。歌词和旋律都可以被表示为离散序列,使用 Seq2Seq 的方式建模。
L2M 和 M2L 任务有两个难点:(1)歌词和旋律之间的相关性较弱,这使得任务需要大量的平行语料去学习这种跨模态的映射关系,但大量的平行语料是难以获得的;(2)歌词中的一个词或音节需要和旋律中的一个或多个音符严格对齐,这需要模型额外生成这种对齐关系。之前的工作通常都只使用少量的平行语料训练模型,使用简单的贪婪策略进行对齐,使得生成效果差强人意。
针对平行语料稀缺的问题,我们首次将预训练技术应用在 L2M 和 M2L 任务上。MASS 是 Seq2seq 学习任务中一项成功的预训练技术,我们将 MASS 方法从句子级扩展到歌曲(篇章)级,使用大规模非平行语料进行无监督预训练,并利用少量平行语料进行有监督约束。在歌词与旋律对齐方面,我们设计了句子级和字符级的注意力约束增强对齐。在推理阶段,我们基于注意力权重使用动态规划算法全局地生成歌词和旋律的严格对齐。
实验结果充分证明相比于 Baseline,我们提出的 SongMASS 大幅度提升了歌词到旋律、旋律到歌词的生成效果。

整体架构
下图是我们提出的 SongMASS 的整体架构,架构基于 Transformer 的编解码器结构。由于歌词和旋律之间的模态差异性巨大,我们对歌词和旋律分别使用独立的编解码器。
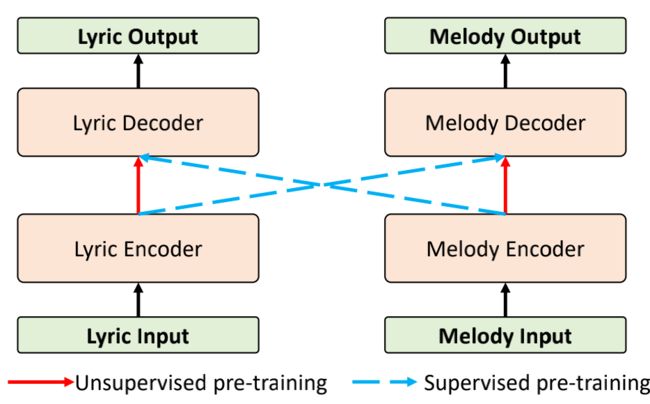
SongMASS 主要包含以下几个部分:
1)歌曲(篇章)级 MASS 预训练(上图红色箭头);
2)预训练过程中的有监督约束(上图蓝色箭头);
3)句子级和字符级的对齐约束;
4)基于动态规划的全局对齐。
下文将具体展开介绍。

歌曲(篇章)级MASS预训练
MASS 方法在句子级的 seq2seq 任务中取得了巨大成功。在自动歌曲写作的任务中,我们希望模型能捕捉整首歌的上下文信息,因此我们将 MASS 方法扩展到了歌曲(篇章)级的预训练。扩展的 mask 策略如下图所示,编码器输入含有多段屏蔽的歌曲序列,解码器解码出整个歌曲所有被屏蔽的部分。其中,我们在整首歌的句子与句子之间加入 [SEP] 作为边界标识。

我们让 X’ 和 Y’ 分别代表非平行的歌词和旋律语料,歌曲级的 MASS 公式如下:

S 表示的是 x 中句子的数目, 表示的是含有屏蔽的歌曲序列, 表示歌曲中第 i 个句子被屏蔽的部分, 分别表示歌词编码器、歌词解码器、旋律编码器、旋律解码器的参数。
那么歌词-歌词生成的损失为:
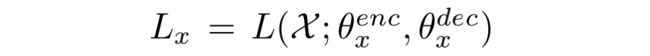
旋律-旋律的损失就为:


预训练过程中的有监督约束
分别对两组编解码器独立应用 MASS 预训练可以帮助模型理解并分别生成歌词或旋律,但在训练过程中,歌词和旋律的编解码器没有对齐到相同的隐空间,甚至可能互相远离,这将影响 L2M 和 M2L 的效果。因此,我们利用少量的平行语料,在预训练过程中有监督地进行 L2M 和 M2L 任务,以约束隐向量空间的距离。对于成对的平行语料(X,Y),有监督预训练的损失是:

所以对于歌词到旋律的生成,损失是:
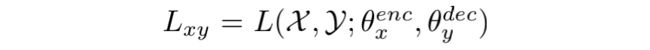
对于旋律到歌词的生成,损失是:

那么整个预训练过程的损失为:
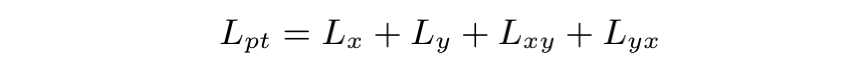
在 fine-tuning 过程中,对于 L2M 任务我们只用 ,对于 M2L 任务我们只用 。

句子级别的对齐约束
歌词和旋律通常可以被天然地划分为严格对齐的句子或乐句。我们约束目标序列中的每个句子在解码时只注意源序列中对应的句子。具体地,我们对解码器到编码器的注意力做了句子级的遮掩。我们用 代表目标序列的第 i 个字符, 代表源序列的第 j 个字符。假设 和 分别表示 和 在上一个 Transformer 层的表征, 那么 和 之间的注意力权重 可以计算为:
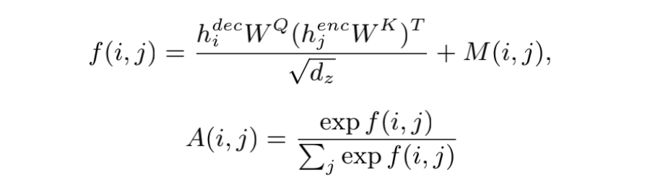
其中 WQ,WK 是模型的参数,dz 是隐向量维度。 用来控制 和 之间的注意力是否被屏蔽,以实现句子级的对齐,其值如下所示( 表示的字符 x 在其所在序列中属于第几个句子):
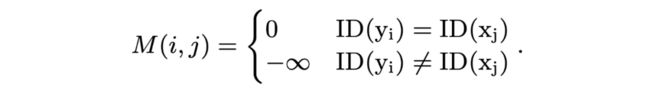
前面提到,我们引入了 [SEP] 符号增强句子间的边界信息。同时,我们在解码时根据生成的 [SEP] 符号动态切换句子级注意力约束,并保证生成的句子数量和输入序列一致。

字符级别的对齐约束
不同于句子级别的严格对齐,句子内的字符级对齐通常更加灵活。因此我们在训练时利用平行语料中标注的对齐关系,对编解码器间的注意力增加了一个正则项。我们希望 和 间的注意力权重满足:
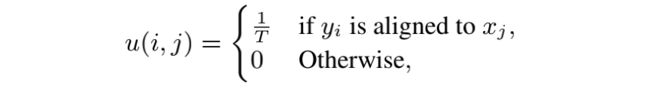
T 是 在源序列中对齐的字符数量。我们加入一个 L2 正则项来约束注意力权重(N 和 M 分别是源序列和目标序列的字符数目)

最终,损失的计算如下:
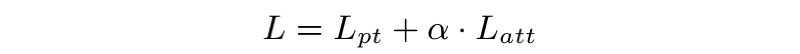
是 的权重, 是我们之前定义的预训练损失。

基于动态规划的全局对齐
在推理过程中,当句子中所有的字符都生成后,我们也得到了注意力权重矩阵 A。我们对 A 使用动态规划算法全局地获得最终的严格对齐,如下图所示。

我们考虑以下两种情形:(1)一个目标字符对应一个或多个源字符;(2)一个源字符对应一个或多个目标字符。图中 7-12 行和 13-18 行分别对应这两种情形的得分,我们使用动态规划算法全局地寻找总得分最大的对齐关系。

实验分析
我们对本文提出的方法分别进行了客观评估和主观评估。
在客观评估中,我们根据生成旋律和正确旋律的音高分布相似度(PD)、时值分布相似度(DD)以及音符序列的距离(MD)评估 L2M 任务生成旋律的效果。此外,我们使用困惑度(PPL)衡量模型在 L2M 和 M2L 任务生成的表现。
我们对比的 Baseline 是使用和 SongMASS 一样配置的 Transformer 模型,但并没有任何预训练或者对齐约束。我们也引入了消融实验,验证预训练和对齐约束的作用。具体结果如下:

我们可以看到 SongMASS 对比 Baseline 有很大的性能提升。此外,不对歌词和旋律分别使用独立的编解码器,或是不进行预训练过程中的有监督约束都会使效果更差,这说明了这些设计都是有效的。
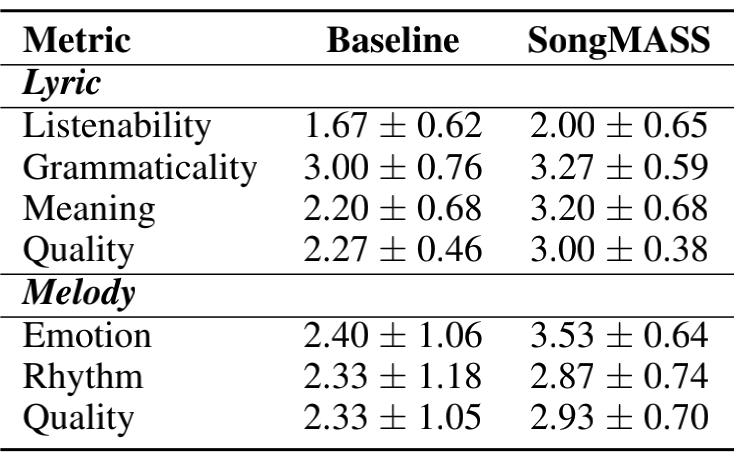
在主观评估中,我们找了 5 个专业音乐人士做人工打分,评估了测试集中随机 10 首歌曲的生成效果。在歌词生成上,评估人员将从可听性(Listenability)、语法正确性(Grammatically)、歌曲含义(Meaning)和整体质量(Quality)四个角度进行打分;在旋律生成上,专业人员将从情感(Emotion)、节奏(Rhythm)和整体质量(Quality)三个角度进行打分。
所有指标均采用 5 分制,1 为最差,5 为最好,并和 Baseline 的生成效果进行比较,下表展示了主观评估结果,可以看到 SongMASS 相比于 baseline 在所有指标上都取得了更好的效果:

对齐效果分析
我们根据对齐的准确率(Acc)评估歌曲和旋律对齐的正确性。我们研究了句子级约束(SC)、字符级约束(TC)和动态规划(DP)对对齐效果的影响,如下表所示:

我们可以看到句子级和字符级约束都能提升对齐效果,尤其是句子级约束。动态规划是非常有效的算法,如果不使用动态规划而使用简单的贪婪策略,对齐准确率将大幅降低。
此外我们可以看到预训练(PT)对于对齐也有一定的效果,我们认为这是因为预训练可以更好地捕捉歌词和旋律的特征。
为了更好展示我们对齐策略的优势,我们对部分 L2M 任务进行了可视化。

(a)图展示了是否使用句子级注意力对齐约束的注意力权重分布,我们可以看到左图在没有句子级别的约束时权重非常的分散,句子中对应的字符并不好关联起来;右图中句子级约束的使得源序列与目标序列的句子单调对齐,增强对齐效果。

(b)图展示了单句内是否使用字符级约束的注意力权重分布。从左图我们可以看到,没有使用字符级约束的注意力权重分布非常混乱,而右图使用了字符级约束使得注意力权重分布有很明显的对角趋势。红色框表示的使用动态规划策略得到的对齐路径,相比于黄色框使用的贪婪策略更优秀。详细的实验结果和分析在我们的论文中会有更完整的展示。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
