深度强化学习主流算法介绍(一):DQN系列
本系列深度强化学习算法介绍文章,旨在将上次组会内容分享到公众号上(准备组会肝的挺累想成果转化下),内容不会特别深入(毕竟太深的我还不会)。
主要是按动作空间的类型进行分类,包括离散动作空间、连续动作空间和混合动作空间,并按照时间发展脉络进行梳理,方便了解整个深度强化学习领域大致的发展方向和趋势,以及各个算法之间的递进关系。

图片转自https://zhuanlan.zhihu.com/p/342919579
如果想学习或利用其中的某些算法,建议仔细看论文原文,以及网上找更多的资料进行学习。
系列中提到的算法的论文都已打包整理好,有需要的可以自取。
链接:https://pan.baidu.com/s/1ePMVVCF3jeGoXelpqAO9pw?pwd=nbzy
提取码:nbzy
本篇文章主要介绍深度强化学习的开山鼻祖DQN及其衍生品,应用场景为连续状态空间和离散动作空间。
首先简要介绍下深度强化学习Deep reinforcement learning (DRL)
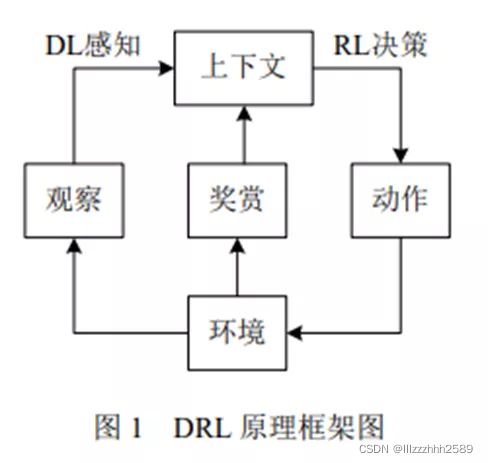
深度强化学习是人工智能领域的一个新的研究热点.它以一种通用的形式将深度学习的感知能力与强化学习的决策能力相结合,并能够通过端对端的学习方式实现从原始输入到输出的直接控制。
DL 的概念源于人工神经网络(Artificial Neural Network,ANN)这个不用过多介绍,这么火基本都知道点。
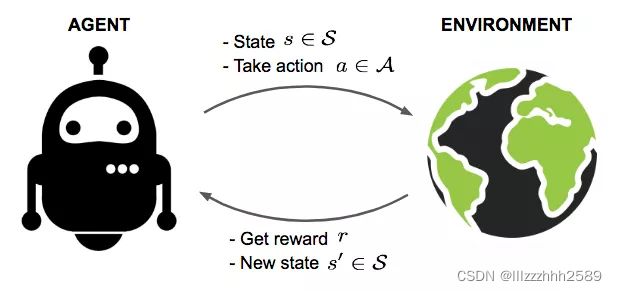
RL 是一种从环境状态映射到动作的学习,目标是使 agent 在与环境的交互过程中获得最大的累积奖赏。
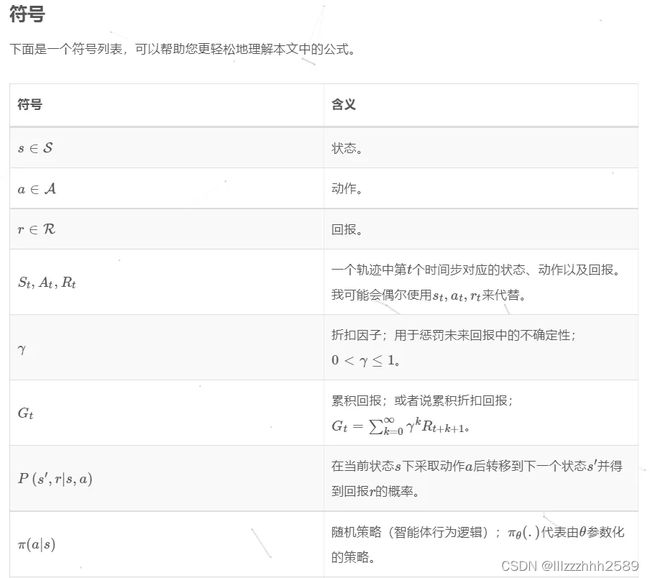
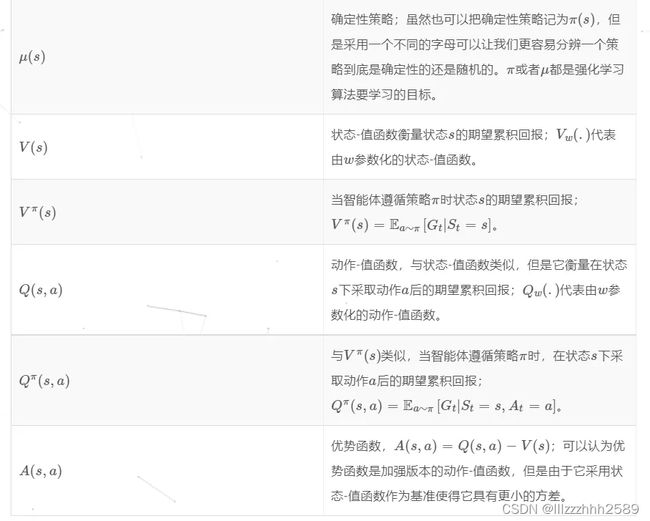
一、DQN
Mnih等人将卷积神经网络与传统RL中的 Q 学习算法相结合,提出了深度 Q 网络(Deep Q-Network, DQN)模型,是深度强化学习的开山鼻祖,解决了之前Q学习只能处理离散状态的问题,用神经网络来表达连续的状态。
使用一个Q Network来估计Q值,从而替换了之前 Q-table,完成从离散状态空间到连续状态空间的跨越。Q Network 会对每一个离散动作的Q值进行估计,执行的时候选择Q值最高的动作(greedy 策略)。
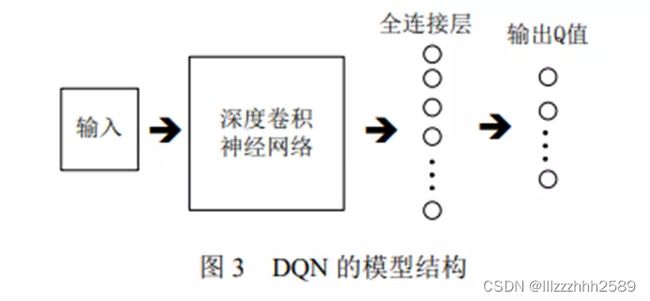
DQN 在训练过程中使用经验回放机制(experience replay);
DQN 除了使用深度卷积网络近似表示当 前的值函数之外,还单独使用了另一个网络来产生目标 Q 值 ;
DQN 将奖赏值和误差项缩小到有限的区间内,保证了 Q 值和梯度值都处于合理的范围内,提高了算法的稳定性.
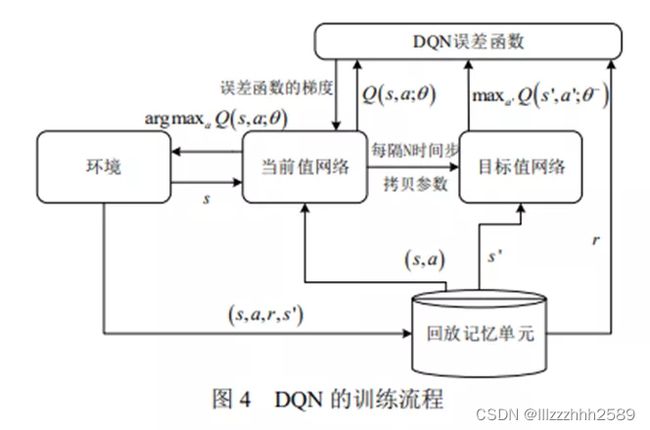


DQN的算法描述为
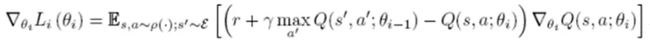
一句话说就是,在每一次策略的选择中,选择和已训练得到的Q值最近的哪个策略
二、Double DQN 双DQN
在原始的DQN中,会出现Q值估计偏高的情形,因为这是一种off-policy的策略,我们每次在学习时,不是使用下一次交互使用的真实动作,而是使用当前策略认为的价值最大的动作,所以会出现对Q值的过高估计。
为了将动作选择和价值估计进行解耦,我们有了Double-DQN方法。对于选择动作和对拟合目标使用的Q网络使用的参数并不是同一堆参数,而是不同时刻的参数.
同时训练两个Q network并选择较小的Q值用于计算TD-error,降低高估误差 在Double-DQN中,在计算Q实际值时,动作选择由eval-net得到,而价值估计由target-net得到。此时,损失函数变为:

一句话说就是:训练两个Q网络每次选择最小值使用,避免Q值高估
三、Dueling DQN 决斗DQN
传统DQN 将 CNN 提取的抽象特征经过全连接层后,直接在输出层输出对应动作的 Q 值,而引入竞争网络结构的模型则将 CNN 提取的抽象特征分流到两个支路中,其中一路代表状态值函数,另一路 代 表 依 赖 状 态 的 动 作 优 势 函 数 ( advantage function).
通过该种竞争网络结构,agent 可以在 策略评估过程中更快地识别出正确的行为。
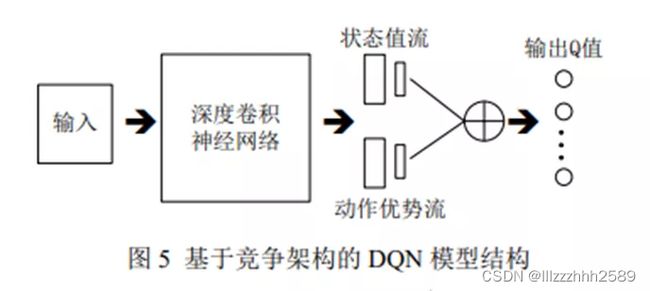
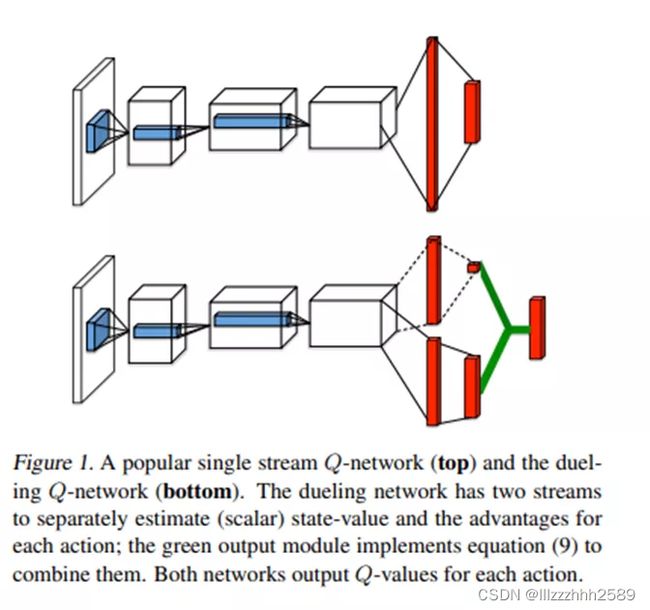
Dueling DQN 使用了优势函数 advantage function:它只估计state的Q值,不考虑动作,好的策略能将state 导向一个更有优势的局面。
原本DQN对一个state的Q值进行估计时,它需要等到为每个离散动作收集到数据后,才能进行准确估值。然而,在某些state下,采取不同的action并不会对Q值造成多大的影响,因此Dueling DQN 结合了 优势函数估计的Q值 与 原本DQN对不同动作估计的Q值。使得在某些state下,Dueling DQN 能在只收集到一个离散动作的数据后,直接得到准确的估值。当某些环境中,存在大量不受action影响的state,此时Dueling DQN能学得比DQN更快。




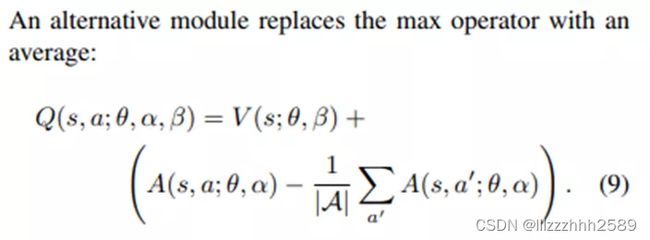

一句话说就是:将状态和动作分开,学习得更精准
四、D3QN Dueling Double DQN 决斗双DQN
没找到基础论文,都是直接用的。
一句话说就是:Dueling DQN 与Double DQN 的结合体,一起用效果很好
五、Rainbow DQN 彩虹DQN
在2013年DQN首次被提出后,学者们对其进行了多方面的改进,其中最主要的有六个,分别是:
Double-DQN:将动作选择和价值估计分开,避免价值过高估计
Dueling-DQN:将Q值分解为状态价值和优势函数,得到更多有用信息
Prioritized Replay Buffer:将经验池中的经验按照优先级进行采样
Multi-Step Learning:使得目标价值估计更为准确
Distributional DQN(Categorical DQN):得到价值分布
NoisyNet:增强模型的探索能力
DeepMind在论文《Rainbow: Combining Improvements in Deep Reinforcement Learning》中,将这六种方法进行了一个整合,提出了Rainbow模型
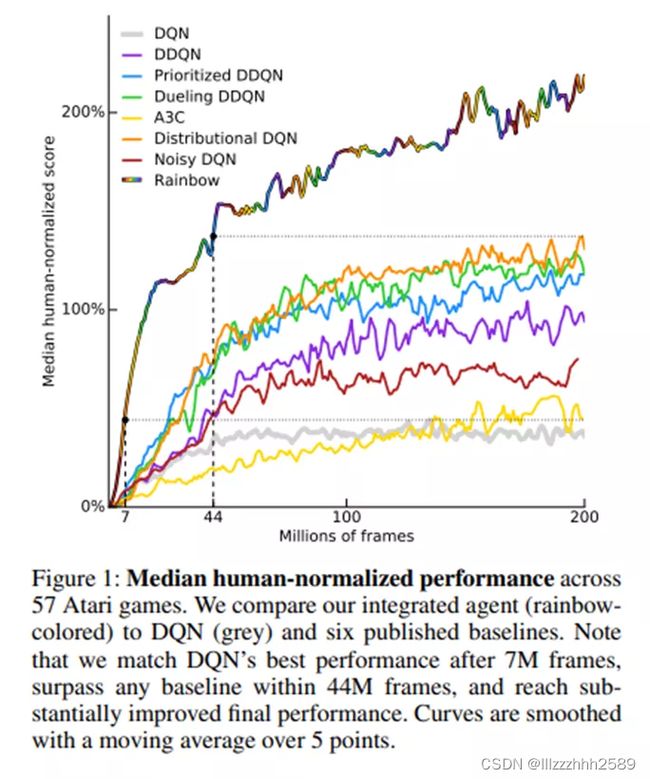

一句话说就是:DQN的很多变种都是可兼容的,彩虹DQN就是个缝合怪,而且缝的很好
至此DQN系列主要算法算是介绍完了,对于算法选择上,DQN系列适用于单智能体、连续状态、离散动作的情形,使用上推荐D3QN,好用且没彩虹那么复杂,理解上也稍微容易些。
其他的DRL算法请期待后面的文章!