Yolov1-v4学习笔记
you only look one
学习视频:同济子豪兄的个人空间_哔哩哔哩_bilibili
组会PPT
总体而言这是本人整合的关于yolo的资料,里面大部分是借鉴网上优秀作者的文章。是给自己方便理解整理的。
YOLOv1
目标检测框架
计算机视觉的任务
Single object 单目标
- Classification 分类 识别图中是否存在某个物体
- Classification Localization 分类并定位物体
Multiple objects 多个对象
-
Object Detection 识别并定位多个物体
-
Segmentation
- 语义分割
- 实例分割
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N8tiaJuJ-1665490932206)(https://cdn.jsdelivr.net/gh/cxy-sky/jat-blog-img/image-20221001084437156.png)]
网络结构
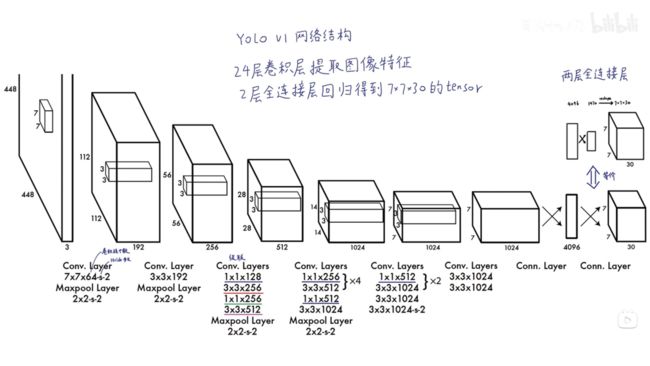
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GiHs6lGT-1665490932207)(https://cdn.jsdelivr.net/gh/cxy-sky/jat-blog-img/image-20221001090052379.png)]
预测限制
每个网格可以有多个bbox,只能预测一个类别。
一个bbox包括(p,x,y,h,w),在yolov1中最终结果为7*7*30,有两个bbox,可以分类20种物体。
损失函数

训练和测试过程
YOLO的训练过程的基本步骤:
YOLO在进行训练:
首先把输入图片resize成相同分辨率,然后对图片进行划网格。然后找出lable上每个检测物体所对应的边框中心点错在的网格(grid cell)。然后每个grid cell 负责检测一个物体。然后再根绝grid cell 按设定划B中bounding box,然后对bounding box记性可信度进行评分,可信度计算包括识别的得分和框所覆盖的IOU的乘积。这样产生的bounding box 和分类信息存在一个bxbxl的一个矩阵里。然后我们就要到loss进行计算了。loss主要包括三个部分,第一个是对框位置的误差进行计算。在计算框位置时我们我们只选择可信度分数最高的框进行计算。第二个就是IOU误差,IOU误差包括我们选择每个检测物体的最高得分框和剩下的框。由于剩下的框过多,我们考虑在剩下框的iou损失前加了一个参数来保持均衡。
YOlO的检测过程:
YOLO在检测的时候回遍历整一个图上的画出来的grid,每个grid会有B个bounding box,然后会对这些识别的物体打分,把地狱0.2 的bounding box 删除。然后对某类检测检测的结果做一个从小到大的排序,然后采用非极大致抑制,来对进行冗余的框进行删除。首先我们选取最大的框,然后查找与其融合超过规定的IOU的其它框,说明这些框与我这个选取最大得分框相似。我们就可以抛弃。把低于0.5的保存。因为可能存在覆盖的情况。然后我们在依次选取剩下第二高得分的框为对比框,知道进行了一轮筛选。然后我们按照同样的步骤对下一个类别坐同样的操作。当所有做完以后我们会发现每一类可能对应几个框,但是一个框一个物体只能有一个框,因此我们选取一个对每个物体都有最大得分的框作为最终的检测框。
YOLOv2
BN层
庖丁解牛yolo_v4之CmBN_Bruce_0712的博客-CSDN博客
BN是对每个神经元进行的,不是一层上的所有神经元
Anchor机制
使用 clusters 簇群
yolov1中bbox为(p,x,y,w,h),一个输出向量由box1+box2+…+20-Classes组成,
yolov2中bbox为一个Anchor由(p,x,y,w,h,20-classes)组成,输出向量为bbox1+bbox2+…+bboxN

预测位置
C x , C y 为偏离整张图片的左上角坐标 Cx,Cy为偏离整张图片的左上角坐标 Cx,Cy为偏离整张图片的左上角坐标
例如:图片左上角为(Cx,Cy)=(0,0),则如果为九宫格型,中间grid cell的左上角坐标为(1,1)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TdsgtJJG-1665490932207)(https://cdn.jsdelivr.net/gh/cxy-sky/jat-blog-img/image-20221001200551203.png)]
损失函数
细粒度特征(Fine-Grained Features)
为了对小物体有更好的检测效果,文章想直接利用更为精细的特征来检测小物体,所以在进行最终的下采样之前,引入了passthrough的方法,该方法利用了下采样之前的特征是的对小物体的检测更为精确。

网络设计

多尺度训练
yolov1中对于检测任务采用的是[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-44EKOf0x-1665490932208)(https://math.jianshu.com/math?formula=448%20%5Ctimes%20488)]来训练网络。
yolov2为了适应多尺度的物体检测,网络的训练时采用多种图片尺寸,这些尺寸为32的倍数,有[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IeVdneyW-1665490932208)(https://math.jianshu.com/math?formula=%5C%7B320%2C%20352%2C%20…%2C%20608%5C%7D)]。训练过程中,每10个batches后随机选择这些尺度中的一个输入网络进行训练。
DarkNet主干网络
左边为分类模型,右边为检测模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dhmR8mqP-1665490932208)(https://cdn.jsdelivr.net/gh/cxy-sky/jat-blog-img/image-20221001151535057.png)]

对比YOLOv1

YOLOv3
骨干网络
Darknet53
网络结构
-
有不同的下采样比例32,16,8,不同尺度预测不同大小的物体,对应的anchor也不同
-
13*13下采样32倍,对应原图的感受野为32*32 -->预测大物体
-
26*26下采样16倍,对应原图的感受野为16*16 -->预测中等物体
-
52*52下采样8倍, 对应原图的感受野为8*8 -->预测小物体
-


部位图
不同尺度的图片
yolov2也可以
可以输入不同尺度的图片,因为没有全连接层,不用固定个数。
但因为下采样的比例分别为32,16,8,所以输入的图片大小要为32的倍数。

不再关注中心点
关注哪个anchor与真实标注的IOU最大,使用这个anchor所在的grid cell
正负样本
与真实标记图像的IOU最大的为正样本,IOU偏小但大于阈值的不参与,IOU小于阈值的为负样本。
损失函数
训练过程

测试过程

没有使用难例挖掘
- hard negative mining
小目标的改进
YOLOv4
【YOLOv3官网演示视频】
论文的目的
通过挑选一些方法将模型在准确率、速率以及成本上进行优化。yolov4设计的目的是能够在单GPU上就可以抛出的模型。
关于yolov4设计者的贡献
- 设计了一个高精度、高实时性的网络,并且该网络只需要一个GPU就可以快速训练;
- 验证了Bag-of-Freebies和Bag-of-Specials对目标检测的影响很大;
- 优化了一些方法(PAN,SAM),使其可以在单GPU上进行训练。
介绍目标检测的model结构
backbone、neck、head
-
backbone:主干网络,提取特征的网络,其作用就是提取图片中的信息,共后面的网络使用。
- Resnet、VGG、Darknet。
-
neck:在backbone和head之间,更好的利用backbone提取的特征,给head使用。
- FPN,PAN。
-
head:利用之前提取的特征,head利用这些特征,做出预测。
- one-stage中的YOLO
- two-stage中的R-CNN
Object detector的结构

BoF和BoS的介绍
BoF:使用一些方法,使目标检测在不增加推理成本的情况下获得更好的精度。
- 对数据图片进行光度畸变和几何畸变,增强训练出模型的鲁棒性
- 模拟对象遮挡问题上,random erase[和CutOut类似于dropblock,dropout等
- 拼接图像 MixUp,CutMix
- 对于one-stage使用focal loss来处理不同类别之间存在的数据不平衡问题。
- 使用软标签替代硬标签
- function of bbox regression ,边界回归函数
- IOU 交并比
- GIOU IOU覆盖区域外,还包括对象的形状和方向
- DIOU GLOU的基础是上,考虑了到物体中点的距离
- CLOU 同时考虑重叠区域、中心点之间的距离和纵横比。YES
BoS:对于那些只增加了少量推理成本但却能显著提高目标检测精度的插件模块和后处理方法。
-
感受野 SPP ASPP
-
注意力机制 SE,SAM
- SE,增加GPU功耗;SAM,YES
-
特征融合 FPN
-
激活函数 Relu Mish
Mish激活函数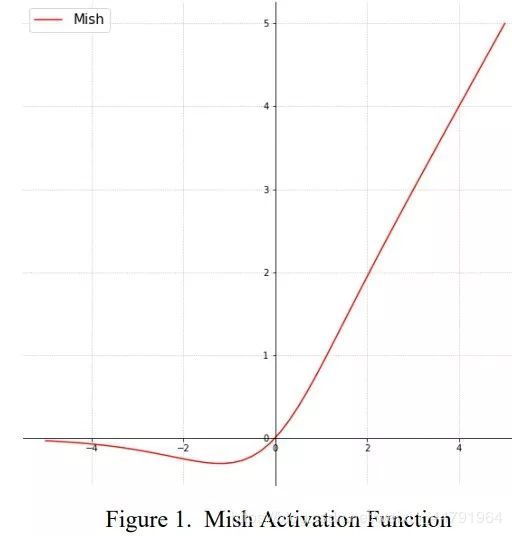
-
NMS(非极大值抑制)
网络的选择
目标是在输入网络分辨率、卷积层编号、参数编号(滤波器尺寸2滤波器信道/组)和层输出数量(滤波器)之间找到最佳平衡。
模型的要求
- Higher input network size (resolution) – for detecting
multiple small-sized objects- 更大的输入网络尺寸(分辨率)-用于检测多个小尺寸对象
- More layers – for a higher receptive field to cover the
increased size of input network- 更多层-用于更高的接收场,以覆盖输入网络的增加尺寸
- More parameters – for greater capacity of a model to
detect multiple objects of different sizes in a single im-
age- 更多参数-用于更大的模型容量,以检测单个图像中不同尺寸的多个对象
分类实验
CSPResNeXt50更适合于分类网络,CSPDarknet53更适合于检测网络,因此YOLOv4的backbone选择CSPDarknet53。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8ZamLJTQ-1665490932211)(https://cdn.jsdelivr.net/gh/cxy-sky/jat-blog-img/image-20221004171746590.png)]
确定结构
-
we choose CSPDarknet53 backbone, SPP addi-tional module, PANet path-aggregation neck, and YOLOv3(anchor based) head as the architecture of YOLOv4.
- 主干网络 CSPDarknet53
- 颈部 SPP,PANet(替代yolov3中的FPN)
- 头部YOLOv3(anchor based) head 沿用YOLOv3的头部(下图,YOLOv3的结构)
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0zZFweVr-1665490932211)(C:\SelfFile\笔记\论文\yolov4\yolov4.assets\image-20221001165803436.png)]
- 主干网络 CSPDarknet53
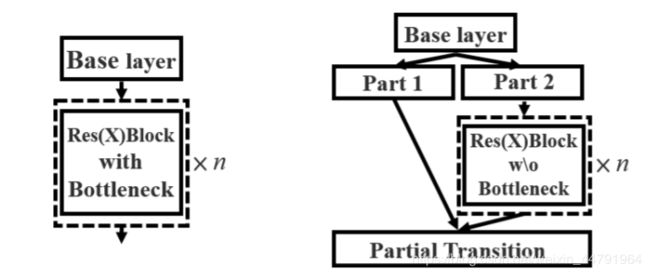
挑选BoF,BoS
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bnQogoYo-1665490932211)(C:\SelfFile\笔记\论文\yolov4\yolov4.assets\image-20221004172806295.png)]
-
使用范围:干掉PRelu,SELU,ReLU16,激活函数
-
正则化方法,毫不犹豫的选择dropblock
-
因为是单GPU,干掉sync BN,归一化方法
-
其他方面,选择更适合单GPU
-
YOLOv4还通过遗传算法对超参进行了优化
-
提出的Mosaic数据增强的方法,是将4张训练图片混合在一起然后输入网络,这样一来四张图片的信息会有融合(CutMix的plus)。
-
提出的SAT也是一种数据增强的方法,分成两阶段完成:
- 在第一阶段,神经网络会更改原始图像,而不是网络权重。以这种方式,神经网络对其自身执行对抗攻击,从而改变原始图像,以便造成一种图像上没有我们想要关注的目标的假象(就是在增加样本的训练难度)。
- 在第二阶段,训练神经网络以正常方式检测此修改图像上的物体。
-
本文分别对SAM、PAN和BN做了优化

YOLOv4模型

SPP

PAN

在Classifier training上的尝试


Detector training上


BoS的影响

mini-batch
在使用BOF,BOS后mini batch就是废物,没用了。成本更便宜了,可以用平常的GPU就可以跑动yolov4了。


Bag of Freebies
Bag of Freebies —— 提升目标检测模型性能的免费tricks - 知乎 (zhihu.com)
一文总结YOLOv4所列的Bag of freebies_xxZkj的博客-CSDN博客
特征增强
Bag of specials
一文总结YOLOv4所列的Bag of specials_xxZkj的博客-CSDN博客
一些通过增加推理成本,改变网络结构,来提高目标检测精度的方法。
IOU
深度学习中的IoU概念理解_鬼 | 刀的博客-CSDN博客_iou是什么意思
CIOU
目标检测—CIOU原理及代码实现_进我的收藏吃灰吧~~的博客-CSDN博客_ciou实现
NMS非极大值抑制(Non-Maximum Suppression,NMS) - 康行天下 - 博客园 (cnblogs.com)
NMS(non_max_suppression) - 知乎 (zhihu.com)
非极大值抑制
Squeeze-and-Excitation Networks
解读Squeeze-and-Excitation Networks(SENet) - 简书 (jianshu.com)
Grouped convolution
(1条消息) 分组卷积:Grouped convolution_你好再见z的博客-CSDN博客_分组卷积的好处
分组卷积
DropBlock
DropBlock - 知乎 (zhihu.com)
FPN
(1条消息) 深度学习中的FPN详解_tt丫的博客-CSDN博客_fpn
自下而上,自上而下,横向连接和卷积融合
PAN
(1条消息) 深度学习之PAN详解_tt丫的博客-CSDN博客_pan结构
backbone、head、neck术语解释
backbone、head、neck等深度学习中的术语解释 - 知乎 (zhihu.com)
SPP
【目标检测】SPP-net - 知乎 (zhihu.com)
空间金字塔
空间金字塔池化(Spatial Pyramid Pooling, SPP)原理和代码实现(Pytorch) - marsggbo - 博客园 (cnblogs.com)
Region proposals
Region proposals 是什么?如何提取?_轮子去哪儿了的博客-CSDN博客_proposals
候选区域
总结
学习了三四天关于yolo的知识,对目标检测有了大致的了解。
但里面还有很多概念没有完全搞定,例如一些优化方法tricks,还需要后面进一步的学习。
Yolov4也是本人第一次读论文,速度和效率方面都不行。
还需要加大文献的阅读速度和效率。
代码也没有进行分析,更不用说代码实现。
另附我找到的Yolov4代码复现给有需要的人:bubbliiiing/yolov4-pytorch: 这是一个YoloV4-pytorch的源码,可以用于训练自己的模型。 (github.com)
