论文阅读图片和文本联合训练:IMAGEBERT: CROSS-MODAL PRE-TRAINING WITH LARGE-SCALE WEAK-SUPERVISED IMAGE-TEXT DATA
论文地址:https://arxiv.org/abs/2001.07966v1 https://arxiv.org/abs/2001.07966v1
https://arxiv.org/abs/2001.07966v1
摘要:
介绍了一种新的视觉语言预训练模型 ImageBERT 用于图像-文本联合表示。使用基于Transformer [1]的模型,该模型采用不同的模态(模态指代图片or文本)作为输入并对它们之间的关系进行建模。该模型同时针对四个任务进行了预训练:蒙版语言建模(MLM),蒙版对象分类(MOC),蒙版区域特征回归(MRFR)和图像文本匹配(ITM)。为了进一步提高预训练质量,从Web收集了大规模的weAk监督的图像文本(LAIT)数据集。首先在该数据集上对模型进行预训练,然后对概念字幕[2]和SBU字幕[3]进行第二阶段的预训练。实验表明,多阶段预训练策略优于单阶段预训练。还对图像检索和文本检索[4]任务进行了微调和评估了经过预训练的ImageBERT模型,并在MSCOCO [5]和Flickr30k [6]数据集上均获得了最新的最新结果。
最近,视觉语言任务在自然语言处理(NLP)和计算机视觉(CV)社区中都引起了很多关注。例如,Text-Image Retrieval [4]的目的是在给定文本的情况下检索最相关的图像,反之亦然。视觉问答(VQA)[7]的目的是预测给定图像和相关问题的正确答案。视觉常识推理(VCR)[8]要求模型不仅可以回答常识问题,还可以选择支持该回答的理由。图像标题[9]旨在为每个输入图像生成自然语言描述。基于分别由语言和视觉任务训练的预训练模型(例如,针对语言任务的BERT [10]和针对视觉任务的ResNet [11]),大多数以前的方法使用后期融合方式来融合下游的多模式输入任务。但是,这样的后期融合层在训练中通常需要任务特定的标记数据,但是对于许多多模式任务,获取足够的任务注释仍然非常具有挑战性且昂贵。
受NLP预训练模型(例如BERT [10],XLNet [12]和RoBERTa [13])成功的启发,交叉模式预训练已成为热门研究领域。这样的模型可以在早期基于大规模语料库学习语言和视觉内容的联合表示,然后通过任务特定的微调将其应用于下游任务。在本文中,首先回顾关于交叉模式预训练的最新工作,并比较它们的异同。然后,提出了ImageBERT作为交叉模式预训练的强大基线,它在MSCOCO [5]和Flicker30k上的文本到图像和图像到文本检索任务上获得了最新的最新结果。 [6]。还建立了一个新的语料库,其中包括从Web挖掘的1000万个文本图像对。希望这个语料库可以进一步推动跨模式预训练研究的发展。
1引言
2相关工作
•模型架构。 BERT [10]模型针对输入为一两个句子的NLP任务进行了预训练。要将BERT结构应用于交叉模式任务,可以有很多方法来处理不同的模式。ViLBERT [14]和LXMERT [15]分别将单模态转换器应用于图像和句子,然后将这两种模态与交叉模态转换器结合在一起。其他工作,例如VisualBERT [16],B2T2 [17],Unicoder-VL [18],VL-BERT [19],Unifineed VLP [20],UNITER [21]等,都将图像和句子串联在一起变压器的单一输入。很难争论哪种模型结构更好,因为它的性能实际上取决于特定的场景。
•图像视觉标记。几乎所有最近的论文都将对象检测模型应用于图像,并将检测到的感兴趣区域(RoI)视为图像描述符,就像语言标记一样。与使用预先训练的检测模型的其他工作不同,VL-BERT对检测网络及其图像-文本联合嵌入网络进行了训练,并且还在模型训练中添加了全局图像功能。我们可以看到基于区域的图像特征是很好的图像描述符,它们形成了一系列可视标记,可以直接输入到Transformer中。
•训练前数据。与可以利用大量自然语言数据的语言模型预训练不同,视觉语言任务需要高质量的图像描述,而这些图像描述很难免费获得。鉴于概念字幕[2]具有3M图像描述,并且相对于其他数据集而言相对较大,因此是用于图像文本预训练的最广泛使用的数据。UNITER [21]将四个数据集(概念字幕[2],SBU字幕[3],Visual Genome [22]和MSCOCO [5])组合在一起,形成了960万个训练语料库,并在许多图像文本跨模式任务。LXMERT [15]在预训练中添加了一些VQA训练数据,并获得了有关VQA任务的最新结果。我们可以看到,数据质量和数据量在模型训练中起着重要作用,在设计新模型时应更加注意。
3大规模弱监督的图文数据收集
与基于语言模型的预训练不同,它可以使用无限的自然语言文本,例如BooksCorpus [23]或Wikipedia,交叉模式的预训练需要大量和高质量的视觉语言对。例如,最新的跨模式预训练模型[16、17、18、19、20、21]在预训练中使用以下2个数据集:概念字幕(CC)数据集[2],其中包含3M图像从网页的Alt-text HTML属性和SBU Captions [3]收集的描述,其中SBU Captions由1M图像和用户关联的标题组成。但是,这些数据集的大小仍然不足以预训练具有数亿个参数的模型,甚至在将来甚至更大的模型。另外,由人类手动书写的图像描述可能是高质量的但昂贵的。但是Internet上有无数带有相关图像的网页。
因此,本文设计了一种弱监督方法(如图1所示),用于从Web收集大规模的图像文本数据,该数据的数量和质量对于视觉语言的预训练任务至关重要。所得数据集LAIT(大型weAk监督的图像文本)包含10M图像及其描述,平均长度为13个单词。我们将在实验中证明LAIT对于视觉语言预训练是有益的。图2给出了一些示例。我们将在下面解释数据收集方法.
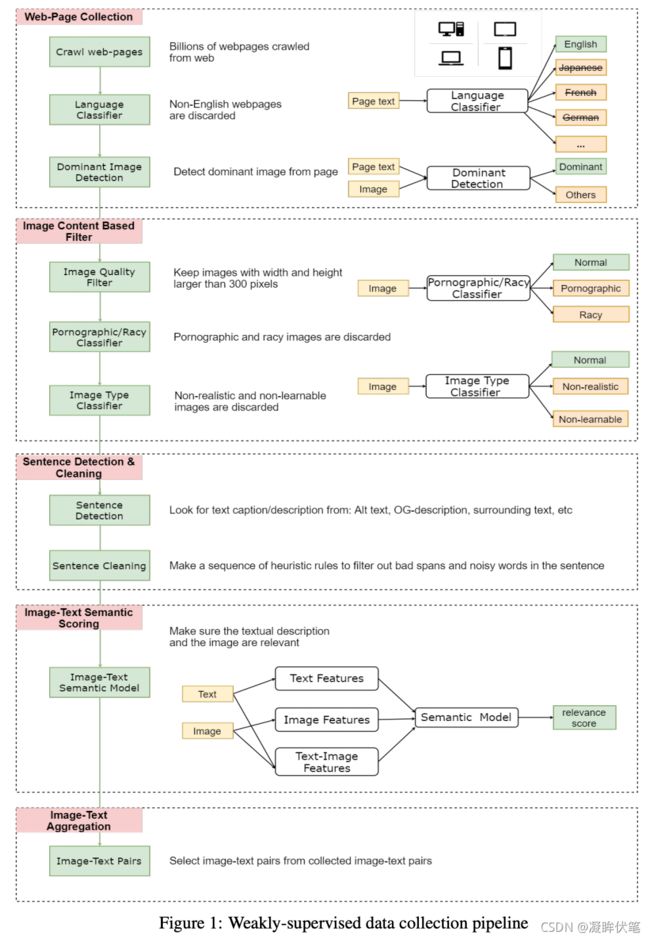
网页集合。鉴于所有下游任务都是英文的,从Web上检索了数十亿个网页并丢弃了所有非英文网页。然后,解析每个网页以收集图像URL,并通过HTML标签和DOM树功能检测主要图像。丢弃非主要图像,因为它们很可能与网页内容无关。
基于图像内容的过滤。根据图像内容进一步过滤数据。仅保留宽度和高度均大于300像素的图像。同样,包含色情或淫秽内容的图像也将被丢弃。此外,由于下游任务中的图像都是从现实世界中拍摄的自然,逼真的图片,因此我们应用了二元分类器来丢弃不自然/非现实且不可学习的图像。图3显示了在此过程中已丢弃的不合格图像的一些示例。
句子检测和清洁。使用以下数据源作为图像的文本描述:HTML中用户定义的元数据,例如Alt或Title属性,图像的周围文本等;制定了一系列启发式规则,以过滤出句子中的不良跨度和嘈杂的单词(垃圾邮件/色情内容),并仅使句子保持正常长度。最后们丢弃词汇率较高的句子。
图像文字语义评分。过滤不良图像并清除嘈杂的文本后,要确保文本和图像在语义上相关。利用少量监督的图像文本数据,训练了一个弱的图像文本语义模型来预测
图像-文本聚合。在某些情况下,一个图像是从多个网页下载的,因此具有不同的文本描述。在这种情况下,仅选择得分最高的
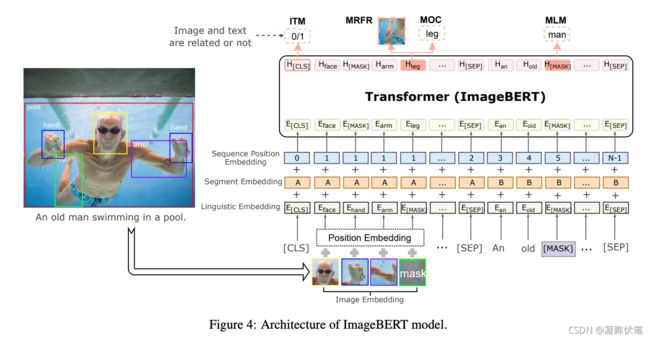
图4展示了ImageBERT模型的整体架构。与BERT [10]类似,使用Transformer作为基本结构,但同时使用图像视觉标记和文本标记作为输入。图像和文本输入被编码为通过嵌入层进行不同的嵌入,其中图像视觉标记是从Faster-RCNN [24,25]模型中提取的RoI特征。然后,将这些嵌入内容馈送到多层双向自注意变压器中,以学习交叉模态变压器,以对视觉区域和语言标记之间的关系进行建模。
我们首先介绍如何处理输入.
文本embedding。我们采用与BERT类似的单词预处理方法。使用WordPiece [26]方法将输入句子标记为n个子词标记。特殊标记(例如[CLS]和[SEP])也添加到标记化文本序列中。每个子词标记的最终嵌入是通过将其原始词嵌入,片段嵌入和序列位置嵌入相结合而生成的(稍后将对此进行详细说明)。所有这些嵌入都是从公共预训练的BERT模型初始化的
图像嵌入。与语言嵌入类似,也可以通过类似的过程从视觉输入生成图像嵌入。Faster-RCNN模型用于从图像的ROI中提取特征,以{r_0, r_1..... r_n-1}表示,以表示其视觉内容。检测到的对象不仅可以为语言部分提供整个图像的视觉环境,而且还可以通过详细的区域信息与特定术语相关。我们还通过将相对于全局图像的对象位置编码为5-D向量c .
每次嵌入都投影到一个向量,该向量的嵌入大小与Transformer子层中的隐藏大小相同,然后进行层归一化(LN)。我在标签预测任务中使用检测模型中每个区域的分类标签(将在第4.3节中进行说明)。在我们的消融研究中,我们还尝试在区域特征之外添加全局图像特征。
序列位置和片段嵌入。每个令牌的序列位置嵌入用于指示输入令牌的顺序。对所有视觉标记使用固定的虚拟位置,因为没有检测到的RoI的顺序,并且对象的坐标已经添加到图像嵌入中。对于语言部分,使用升序表示文本描述中的单词顺序。此外,将段嵌入添加到每个输入令牌以区分不同的模式.
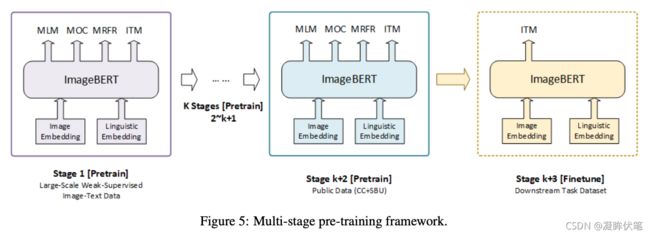
由于从不同来源收集了不同的数据集,因此它们可能具有不同的质量水平和噪声分布。为了更好地利用不同种类的预训练数据,我们提出了一个多阶段的预训练框架,如图所示。
5.根据下游任务,应该首先使用大规模的域外数据再使用小规模的域内数据对预训练模型进行训练,以使模型可以更好地收敛于最终任务。在多阶段预训练中,可以将几个预训练阶段(例如,图5中的k + 2阶段)应用于同一网络结构,以依次利用不同种类的数据集。与[27]中提到的训练策略只有一个阶段的语言模型预训练,语言模型的微调和分类器微调分别不同,我们的多阶段框架主要适用于预训练阶段,以便更好地利用异构域外数据集。另一个也提到多阶段概念的工作[28]使用它来解决特征学习中的优化问题,这与我们的多阶段策略有很大的不同。
更具体地说,在我们的ImageBERT模型中,我们使用了两阶段的预训练策略。预训练的第一阶段使用第3节中提到的LAIT数据集,第二阶段使用其他公共数据集,例如概念字幕和SBU字幕。两个预训练阶段都使用相同的训练策略,其中包括我们所有的四个预训练任务。我们还对单阶段预训练进行了实验,该训练同时在所有数据集上进行训练。4.2多阶段预训练,但发现它不如多阶段预训练有效。最终的微调阶段在前两个阶段使用相同的模型和参数,但丢弃所有带有掩盖术语或虚构对象的任务。
在消融研究中,我们还针对图像文本检索任务对不同的微调目标进行了实验。我们将在下面介绍训练前的任务以及微调任务。
在模型预训练期间,我们设计了四个任务来对语言信息和视觉内容及其交互进行建模。
任务4:图像文字匹配(ITM)。除了语言建模任务和视觉内容建模任务之外,我们还添加了ITM任务来学习图像-文本对齐。对于每个训练样本,我们为每个图像随机抽取否定句子,为每个句子随机抽取否定图片,以生成否定训练数据。因此,我们将每个图像-文本对(v,w)的地面真理标签表示为y属于{0, 1},指示输入样本对是否相关。与BERT相似,我们将[CLS]作为输入序列的第一个标记添加到ImageBERT模型,并在其顶部应用完全连接的层以获得图像-文本相似性评分(v,w)。二进制分类损失用于优化
![]()
经过预训练后,我们得到了关于视觉语言联合表示的训练有素的预训练模型。我们对图像文本检索任务进行进一步的微调和评估。该任务包含两个子任务:图像检索和文本检索。给定描述图像内容的输入字幕语句,图像检索的目标是检索正确的图像。文本检索在相反的方向上执行类似的任务。经过两阶段的预训练后,我们对MSCOCO和Flickr30k数据集进行微调。在微调期间,输入序列的格式与预训练中的相同,但在对象或单词上没有任何遮罩。我们提出了与不同的否定采样方法相对应的两个细调目标:图像到文本(每个图像采样否定句子)和文本到图像(每个文本采样负采样)。此外,我们对三种不同的损失进行了实验以获得最佳模型质量:
•二进制分类损失。这是为了确保阴性样本的预测是正确的:阴性样本的输出分数不仅应与阳性样本不同,而且还应使用正确的标签进行预测。对于具有地面真实性标签y属于{0,1},然后应用二进制分类损失进行优化:
![]()
•多类分类损失。这是扩大正负样本之间的余量的最广泛使用的损失。对于每个正对(v,w ),我们从不同的字幕或图像中采样.
5.1评估预训练模型
5.2对微调模型的评估我们还对Flickr3k上的训练前数据集的不同组合,全局视觉特征的存在,不同的训练任务等进行了消融实验,从而深入研究了我们的模型结构和训练策略。
训练前数据集。我们使用不同数据集的组合进行训练前实验。结果如表3所示。CC代表仅在概念字幕数据集上进行预训练,SBU代表仅对SBU字幕上进行预训练,LAIT + CC + SBU代表使用LAIT,Conceptual Caption数据集和SBU组合数据集进行预训练,LAIT→CC + SBU代表使用LAIT作为阶段1的预训练,然后继续使用概念字幕和SBU字幕作为阶段2的预训练。我们可以看到,与其他所有设置相比,以多阶段方式使用三个不同的域外数据集可获得明显更好的结果。
全局图像功能。值得注意的是,检测到的RoI可能不会包括整个图像的所有信息。因此,我们还尝试将全局图像功能添加到可视部分。我们使用三种不同的卷积神经网络(CNN)模型(DenseNet [32],Resnet [11]和GoogleNet [33])从输入图像中提取全局视觉特征,但发现并非所有度量标准都有改进。结果可以在表4的第1部分中看到。
训练前损失。我们还在预训练中增加了受UNITER [21]启发的MRFR损失,并实现了零射结果的巨大改进,如表4第2部分所示。这意味着添加一项艰巨的任务来更好地对视觉内容进行建模可以促进视觉文本联合学习。
图像中的对象数(RoIs)。为了了解模型中视觉部分的重要性,我们对不同数量的对象进行了实验。在上面的所有实验中,我们都使用100个对象的设置来为预训练任务提供足够的输入图像上下文。在我们的模型中,使用Faster R-CNN模型提取100个RoI,以从检测网络中获得由置信度得分排序的前100名对象。由于对象的某些边界框可能彼此重叠或包含重复信息,因此我们也进行实验以查看不同数量对象的影响。正如我们在表4的第3部分中看到的那样,对象较少(ViLBERT [14]中的对象数量相同),我们的模型在检索任务上没有更好的结果。我们可以得出5.3消融研究的结论,更多的对象确实可以帮助模型获得更好的结果,因为更多的RoI有助于理解图像内容。
微调损耗。对于我们在4.4节中提到的三种损耗,我们在微调过程中尝试将它们进行不同的组合。如表4的第4部分所示,使用二进制交叉熵损失本身可以对图像-文本检索任务提供最佳的优化结果。
在本文中,我们提出了一个新的视觉语言预训练模型ImageBERT,该模型基于Transformer架构并为视觉语言联合嵌入建模。我们还使用弱监督方法从Web上收集了一个大型图像文本训练语料库LAIT,该语料库在当前现有视觉语言数据集中是最大的,并已在多阶段预训练流水线的第一阶段证明了其有效性。 。我们可以看到,尽管缺乏精确的人为标签,但大规模的域外数据可以为预训练模型的质量增加价值,并因此受益于相应的下游任务。我们的ImageBERT模型在MSCOCO和Flickr30k的图像检索和句子检索任务上均取得了最新的最新结果。将来,我们将尝试将我们的预训练模型扩展到其他交叉模式任务,例如VQA,VCR和图像字幕。