WebRTC系列之音频的那些事
年初因为工作需要,开始学习WebRTC,就被其复杂的编译环境和巨大的代码量所折服,注定是一块难啃的骨头。俗话说万事开头难,坚持一个恒心,终究能学习到WebRTC的设计精髓。今天和大家聊聊WebRTC中音频的那些事。WebRTC由语音引擎,视频引擎和网络传输三大模块组成,其中语音引擎是WebRTC中最具价值的技术之一,实现了音频数据的采集、前处理、编码、发送、接受、解码、混音、后处理、播放等一系列处理流程。

音频引擎主要包含:音频设备模块ADM、音频编码器工厂、音频解码器工厂、混音器Mixer、音频前处理APM。
音频工作机制
想要系统的了解音频引擎,首先需要了解核心的实现类和音频数据流向,接下来我们将简单的分析一下。
音频引擎核心类图:
音频引擎WebrtcVoiceEngine主要包含音频设备模块AudioDeviceModule、音频混音器AudioMixer、音频3A处理器AudioProcessing、音频管理类AudioState、音频编码器工厂AudioEncodeFactory、音频解码器工厂AudioDecodeFactory、语音媒体通道包含发送和接受等。
1.音频设备模块AudioDeviceModule主要负责硬件设备层,包括音频数据的采集和播放,以及硬件设备的相关操作。
2.音频混音器AudioMixer主要负责音频发送数据的混音(设备采集和伴音的混音)、音频播放数据的混音(多路接受音频和伴音的混音)。
3.音频3A处理器AudioProcessing主要负责音频采集数据的前处理,包含回声消除AEC、自动增益控制AGC、噪声抑制NS。APM分为两个流,一个近端流,一个远端流。近端(Near-end)流是指从麦克风进入的数据;远端(Far-end)流是指接收到的数据。
4.音频管理类AudioState包含音频设备模块ADM、音频前处理模块APM、音频混音器Mixer以及数据流转中心AudioTransportImpl。
5.音频编码器工厂AudioEncodeFactory包含了Opus、iSAC、G711、G722、iLBC、L16等codec。
6.音频解码器工厂AudioDecodeFactory包含了Opus、iSAC、G711、G722、iLBC、L16等codec。
音频的工作流程图:
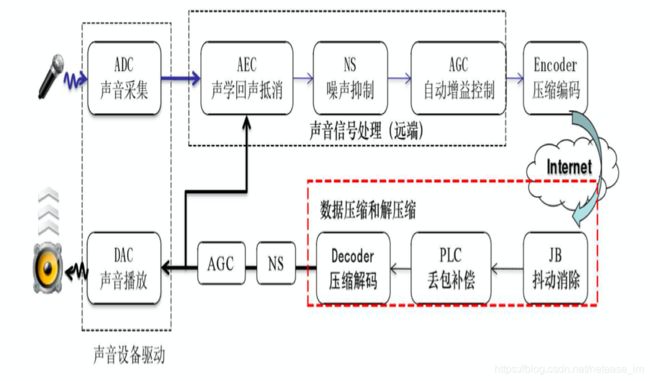
1.发起端通过麦克风进行声音采集
2.发起端将采集到的声音信号输送给APM模块,进行回声消除AEC,噪音抑制NS,自动增益控制处理AGC
3.发起端将处理之后的数据输送给编码器进行语音压缩编码
4.发起端将编码后的数据通过RtpRtcp传输模块发送,通过Internet网路传输到接收端
5.接收端接受网络传输过来的音频数据,先输送给NetEQ模块进行抖动消除,丢包隐藏解码等操作
6.接收端将处理过后的音频数据送入声卡设备进行播放
NetEQ模块是Webrtc语音引擎中的核心模块
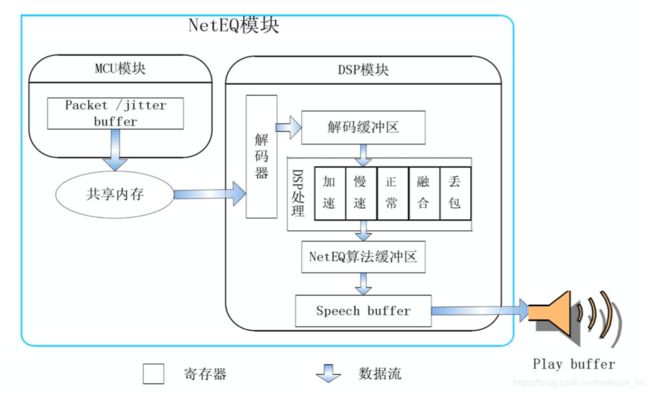
在 NetEQ 模块中,又被大致分为 MCU模块和 DSP 模块。MCU 主要负责做延时及抖动的计算统计,并生成对应的控制命令。而 DSP 模块负责接收并根据 MCU 的控制命令进行对应的数据包处理,并传输给下一个环节。
音频数据流向
根据上面介绍的音频工作流程图,我们将继续细化一下音频的数据流向。将会重点介绍一下数据流转中心AudioTransportImpl在整个环节中扮演的重要角色。

数据流转中心AudioTransportImpl实现了采集数据处理接口RecordDataIsAvailbale和播放数据处理接口NeedMorePlayData。RecordDataIsAvailbale负责采集音频数据的处理和将其分发到所有的发送Streams。NeedMorePlayData负责混音所有接收到的Streams,然后输送给APM作为一路参考信号处理,最后将其重采样到请求输出的采样率。
RecordDataIsAvailbale内部主要流程:
- 由硬件采集过来的音频数据,直接重采样到发送采样率
- 由音频前处理针对重采样之后的音频数据进行3A处理
- VAD处理
- 数字增益调整采集音量
- 音频数据回调外部进行外部前处理
- 混音发送端所有需要发送的音频数据,包括采集的数据和伴音的数据
- 计算音频数据的能量值
- 将其分发到所有的发送Streams
NeedMorePlayData内部主要流程:
- 混音所有接收到的Streams的音频数据
1.1 计算输出采样率CalculateOutputFrequency()
1.2 从Source收集音频数据GetAudioFromSources(),选取没有mute,且能量最大的三路进行混音
1.3 执行混音操作FrameCombiner::Combine()
- 特定条件下,进行噪声注入,用于采集侧作为参考信号
- 对本地伴音进行混音操作
- 数字增益调整播放音量
- 音频数据回调外部进行外部前处理
- 计算音频数据的能量值
- 将音频重采样到请求输出的采样率
- 将音频数据输送给APM作为一路参考信号处理
由上图的数据流向发现,为什么需要FineAudioBuffer和AudioDeviceBuffer?因为WebRTC 的音频流水线只支持处理 10 ms 的数据,不同的操作系统平台提供了不同的采集和播放时长的音频数据,不同的采样率也会提供不同时长的数据。例如iOS上,16K采样率会提供8ms的音频数据128帧;8K采样率会提供16ms的音频数据128帧;48K采样率会提供10.67ms的音频数据512帧。
AudioDeviceModule 播放和采集的数据,总会通过 AudioDeviceBuffer 拿进来或者送出去 10 ms 的音频数据。对于不支持采集和播放 10 ms 音频数据的平台,在平台的 AudioDeviceModule 和 AudioDeviceBuffer 还会插入一个 FineAudioBuffer,用于将平台的音频数据格式转换为 10 ms 的 WebRTC 能处理的音频帧。在AudioDeviceBuffer 中,还会10s定时统计一下当前硬件设备过来的音频数据对应的采样点个数和采样率,可以用于检测当前硬件的一个工作状态。
音频相关改动
1.音频Profile的实现,支持Voip和Music 2种场景,实现了采样率、编码码率、编码模式、声道数的综合性技术策略。
iOS实现了采集和播放线程的分离,支持双声道的播放。
2. 音频3A参数的兼容性下发适配方案。
3.耳机场景的适配,蓝牙耳机和普通耳机的适配,动态3A切换适配。
4.Noise_Injection噪声注入算法,作为一路参考信号,在耳机场景的回声消除中的作用特别明显。
5.支持本地伴音文件file和网络伴音文件http&https。
6.Audio Nack的实现,提高音频的抗丢包能力,目前正在进行In-band FEC。
7.音频处理在单讲和双讲方面的优化。
8.iOS在Built-In AGC方面的研究:
- Built-In AGC对于Speech和Music有效,对于noise和环境底噪不会产生作用。
- 不同机型的麦克风硬件的增益不同,iPhone 7 Plus > iPhone 8 > iPhone X;因此会在软件AGC和硬件AGC都关闭的情况下,远端听到的声音大小表现不一样。
- iOS除了提供的可开关的AGC以外,还有一个AGC会一直工作,对信号的level进行微调;猜想这个一直工作的AGC是iOS自带的analog AGC,可能和硬件有关,且没有API可以开关,而可开关的AGC是一个digital AGC。
- 在大部分iOS机型上,外放模式“耳机再次插入后”,input的音量会变小。当前的解决方案是在耳机再次插入后,增加一个preGain来把输入的音量拉回正常值。
音频问题排查
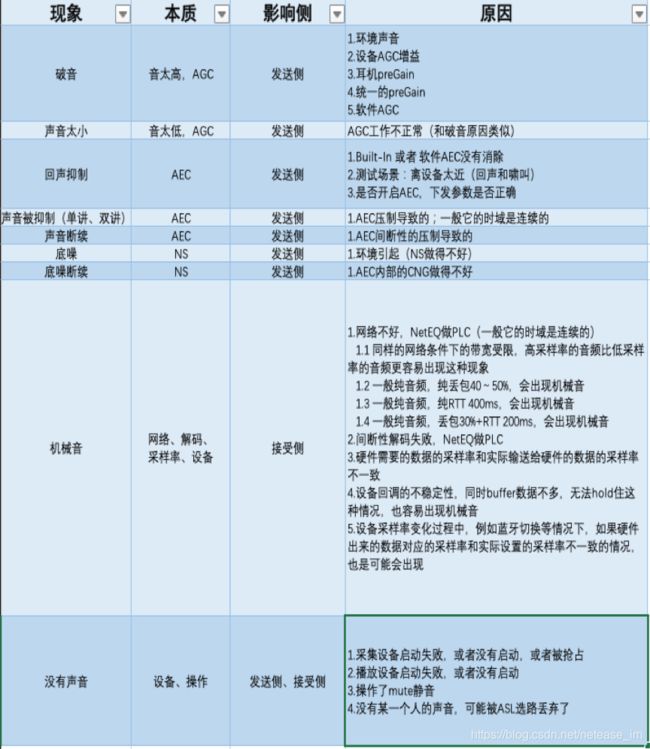
和大家分享一下音频最常见的一些现象以及原因:
更多技术干货,欢迎关注vx公众号“网易智慧企业技术+”。系列课程提前看,精品礼物免费得,还可直接对话CTO。
听网易CTO讲述前沿观察,看最有价值技术干货,学网易最新实践经验。网易智慧企业技术+,陪你从思考者成长为技术专家。