分布式数据同步工具之DataX Web的基本使用
分布式数据同步工具之DataX Web的基本使用
- DataX Web
-
- 架构
- 环境要求
- 安装方式
- 部署安装
-
- 1.解压安装包
- 2.执行一键安装脚本
- 3.数据库初始化
- 4.其他配置
- 5.启动服务
- 6.查看服务
- 7.运行项目
- 8.运行日志
- 9.集群部署
- 功能使用
-
- 1.创建项目
- 2.执行器配置
- 3.创建数据源
- 4.创建任务模版
- 5. 构建JSON脚本
- 6.批量创建任务
- 7.任务创建
- 8. 任务列表
- 9. 查看日志
- 10.任务资源监控
- 11. 用户管理
- 12.运行报表
DataX Web
GitHub地址: https://github.com/WeiYe-Jing/datax-web
DataX Web是在DataX之上开发的分布式数据同步工具,提供简单易用的 操作界面,降低用户使用DataX的学习成本,缩短任务配置时间,避免配置过程中出错。用户可通过页面选择数据源即可创建数据同步任务,支持RDBMS、Hive、HBase、ClickHouse、MongoDB等数据源,RDBMS数据源可批量创建数据同步任务,支持实时查看数据同步进度及日志并提供终止同步功能,集成并二次开发xxl-job可根据时间、自增主键增量同步数据。
任务"执行器"支持集群部署,支持执行器多节点路由策略选择,支持超时控制、失败重试、失败告警、任务依赖,执行器CPU.内存.负载的监控等等。后续还将提供更多的数据源支持、数据转换UDF、表结构同步、数据同步血缘等更为复杂的业务场景。
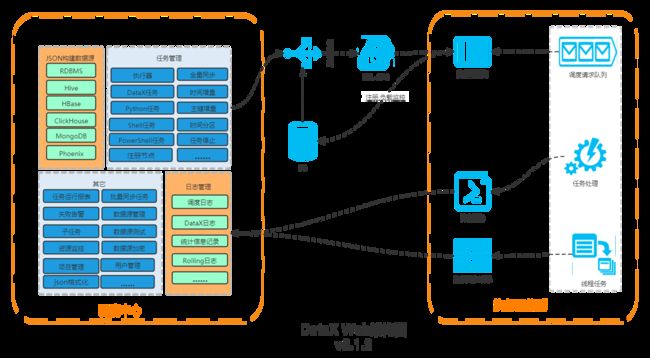
架构
环境要求
MySQL (5.5+) 必选,对应客户端可以选装, Linux服务上若安装mysql的客户端可以通过部署脚本快速初始化数据库
JDK (1.8.0_xxx) 必选
Maven (3.6.1+) 必选
DataX 必选
Python (2.x) (支持Python3需要修改替换datax/bin下面的三个python文件,替换文件在doc/datax-web/datax-python3下) 必选,主要用于调度执行底层DataX的启动脚本,默认的方式是以Java子进程方式执行DataX,用户可以选择以Python方式来做自定义的改造
安装方式
两种部署方式:
1.使用tar.gz包直接在linux上部署
官方提供的版本tar版本包: https://pan.baidu.com/s/13yoqhGpD00I82K4lOYtQhg 提取码:cpsk
2.编译打包
直接从Git上面获得源代码,在项目的根目录下执行如下命令
mvn clean install
执行成功后将会在工程的build目录下生成安装包
build/datax-web-{VERSION}.tar.gz
部署安装
1.解压安装包
tar -zxvf datax-web-2.1.2.tar.gz
mv datax-web-2.1.2 datax-web
2.执行一键安装脚本
进入解压后的目录,找到bin目录下面的install.sh文件,如果选择交互式的安装,则直接执行
cd datax-web
./bin/install.sh
在交互模式下,对各个模块的package压缩包的解压以及configure配置脚本的调用,都会请求用户确认,可根据提示查看是否安装成功,如果没有安装成功,可以重复尝试; 如果不想使用交互模式,跳过确认过程,则执行以下命令安装
./bin/install.sh --force
3.数据库初始化
如果你的服务上安装有mysql命令,在执行安装脚本的过程中则会出现以下提醒:
Scan out mysql command, so begin to initalize the database
Do you want to initalize database with sql: [/usr/local/program/datax-web/bin/db/datax_web.sql]? (Y/N)y
Please input the db host(default: 127.0.0.1):
Please input the db port(default: 3306):
Please input the db username(default: root):
Please input the db password(default: ): 123456
Please input the db name(default: dataxweb)
按照提示输入数据库地址,端口号,用户名,密码以及数据库名称,大部分情况下即可快速完成初始化。 如果服务上并没有安装mysql命令,则可以取用目录下/bin/db/datax-web.sql脚本去手动执行,完成后修改相关配置文件
vi ./modules/datax-admin/conf/bootstrap.properties
#Database
#DB_HOST=
#DB_PORT=
#DB_USERNAME=
#DB_PASSWORD=
#DB_DATABASE=
4.其他配置
在项目目录: /modules/datax-admin/bin/env.properties 配置邮件服务(可跳过)
MAIL_USERNAME=""
MAIL_PASSWORD=""
指定PYTHON_PATH的路径
vim modules/datax-executor/bin/env.properties
# environment variables
#JAVA_HOME=""
SERVICE_LOG_PATH=${BIN}/../logs
SERVICE_CONF_PATH=${BIN}/../conf
DATA_PATH=${BIN}/../data
## datax json文件存放位置
JSON_PATH=${BIN}/../json
## executor_port
EXECUTOR_PORT=9999
## 保持和datax-admin端口一致
DATAX_ADMIN_PORT=
## PYTHON脚本执行位置
#PYTHON_PATH=/home/hadoop/install/datax/bin/datax.py
PYTHON_PATH=
## dataxweb 服务端口
SERVER_PORT=9504
#PID_FILE_PATH=${BIN}/service.pid
#debug 远程调试端口
#REMOTE_DEBUG_SWITCH=true
#REMOTE_DEBUG_PORT=7004
## 保持和datax-admin端口一致,默认是9527
DATAX_ADMIN_PORT=
## PYTHON脚本执行位置
#PYTHON_PATH=/home/hadoop/install/datax/bin/datax.py
PYTHON_PATH=/usr/local/program/datax/bin/datax.py
5.启动服务
一键启动所有服务
./bin/start-all.sh
中途可能发生部分模块启动失败或者卡住,可以退出重复执行,如果需要改变某一模块服务端口号,则:
vi ./modules/{module_name}/bin/env.properties
找到SERVER_PORT配置项,改变它的值即可。 当然也可以单一地启动某一模块服务:
./bin/start.sh -m {module_name}
一键取消所有服务
./bin/stop-all.sh
当然也可以单一地停止某一模块服务:
./bin/stop.sh -m {module_name}
6.查看服务
在Linux环境下使用JPS命令,查看是否出现DataXAdminApplication和DataXExecutorApplication进程,如果存在这表示项目运行成功
如果项目启动失败,请检查启动日志:modules/datax-admin/bin/console.out或者modules/datax-executor/bin/console.out
7.运行项目
访问: http://ip:9527/index.html,输入用户名 admin 密码 123456访问系统


8.运行日志
用户可以根据运行日志跟踪项目实际启动情况。运行日志在modules/对应的项目/data/applogs下。
自己指定日志,修改
modules/datax-executor/conf/application.yml中的logpath地址
如果执行器启动比admin快,执行器会连接失败,日志报"拒绝连接"的错误,一般是先启动admin,再启动executor,30秒之后会重连,如果成功请忽略这个异常。
9.集群部署
修改
modules/datax-executor/conf/application.yml文件下admin.addresses地址。 为了方便单机版部署,项目目前没有将ip部分配置到env.properties,部署多节点时可以将整个地址作为变量配置到env文件。
将官方提供的tar包或者编译打包的tar包上传到服务节点,按照介绍的方式单一地启动某一模块服务即可。例如执行器需要部署多个节点,仅需启动执行器项目,执行 ./bin/start.sh -m datax-executor
调度中心、执行器支持集群部署,提升调度系统容灾和可用性。
1.调度中心集群:
DB配置保持一致;<br>
集群机器时钟保持一致(单机集群忽视);<br>
2.执行器集群:
执行器回调地址(admin.addresses)需要保持一致;执行器根据该配置进行执行器自动注册等操作。
同一个执行器集群内AppName(executor.appname)需要保持一致;调度中心根据该配置动态发现不同集群的在线执行器列表。
功能使用
1.创建项目

2.执行器配置
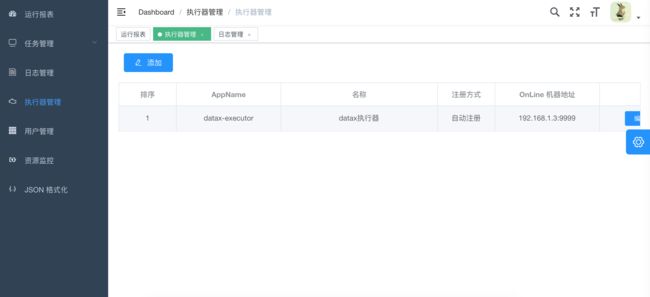
1、"调度中心OnLine:"右侧显示在线的"调度中心"列表, 任务执行结束后, 将会以failover的模式进行回调调度中心通知执行结果, 避免回调的单点风险;
2、“执行器列表” 中显示在线的执行器列表, 可通过"OnLine 机器"查看对应执行器的集群机器;
执行器属性说明
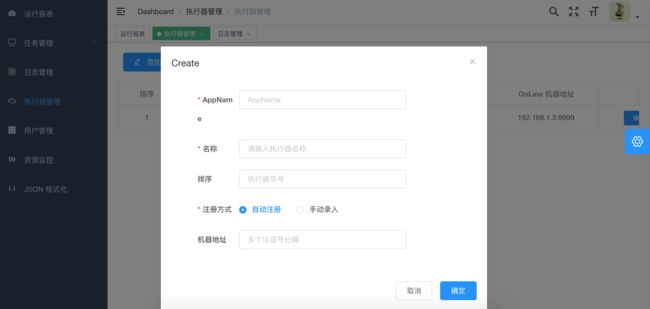
1、AppName: (与datax-executor中application.yml的datax.job.executor.appname保持一致)
每个执行器集群的唯一标示AppName, 执行器会周期性以AppName为对象进行自动注册。可通过该配置自动发现注册成功的执行器, 供任务调度时使用;
2、名称: 执行器的名称, 因为AppName限制字母数字等组成,可读性不强, 名称为了提高执行器的可读性;
3、排序: 执行器的排序, 系统中需要执行器的地方,如任务新增, 将会按照该排序读取可用的执行器列表;
4、注册方式:调度中心获取执行器地址的方式;
自动注册:执行器自动进行执行器注册,调度中心通过底层注册表可以动态发现执行器机器地址;
手动录入:人工手动录入执行器的地址信息,多地址逗号分隔,供调度中心使用;
5、机器地址:"注册方式"为"手动录入"时有效,支持人工维护执行器的地址信息;
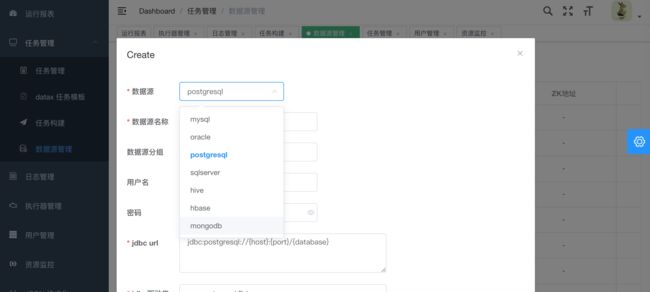
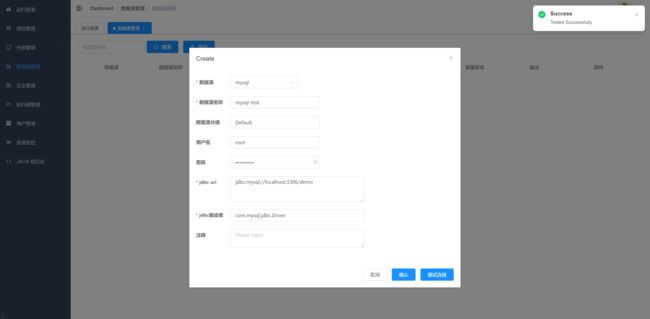
3.创建数据源
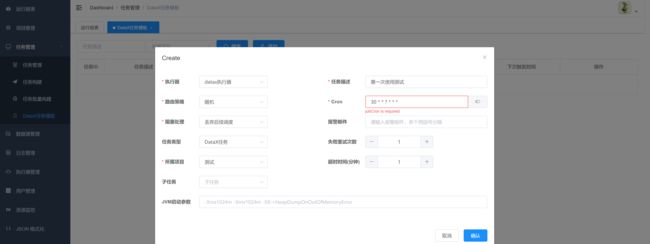
4.创建任务模版

5. 构建JSON脚本
1.选择读与写的数据源
JSON构建目前支持的数据源有hive,mysql,oracle,postgresql,sqlserver,hbase,mongodb,clickhouse 其它数据源的JSON构建正在开发中,暂时需要手动编写。
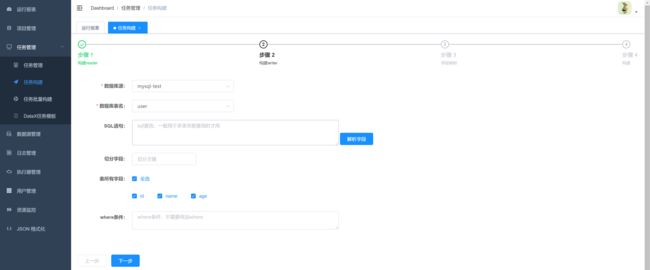
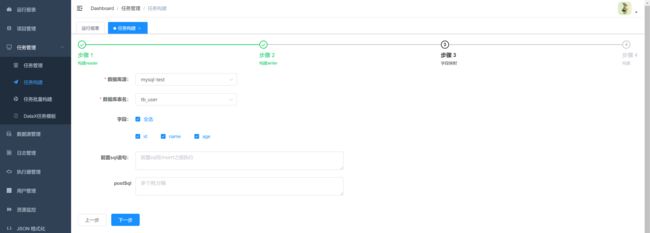
2.字段映射
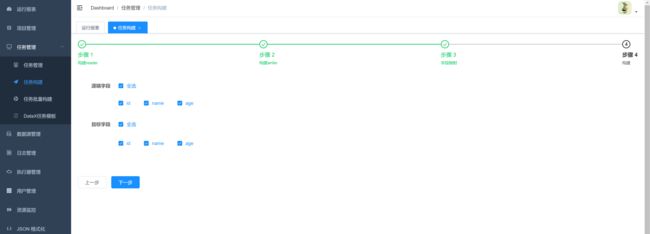
3.点击构建,生成json。
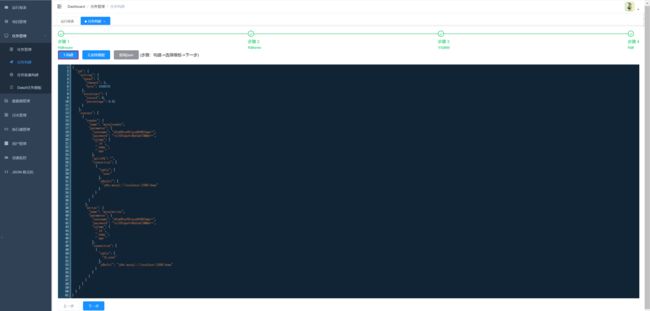
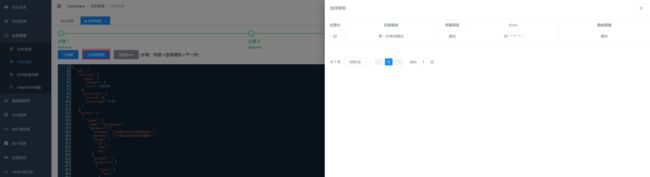
此时:可以选择复制json然后创建任务,选择datax任务,将json粘贴到文本框。

也可以点击选择模版,直接生成任务。
6.批量创建任务

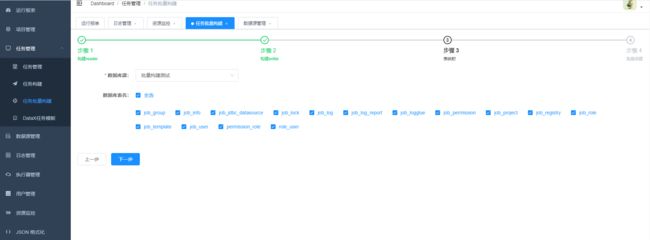
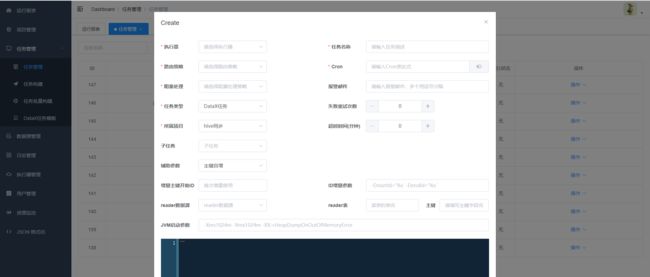
7.任务创建
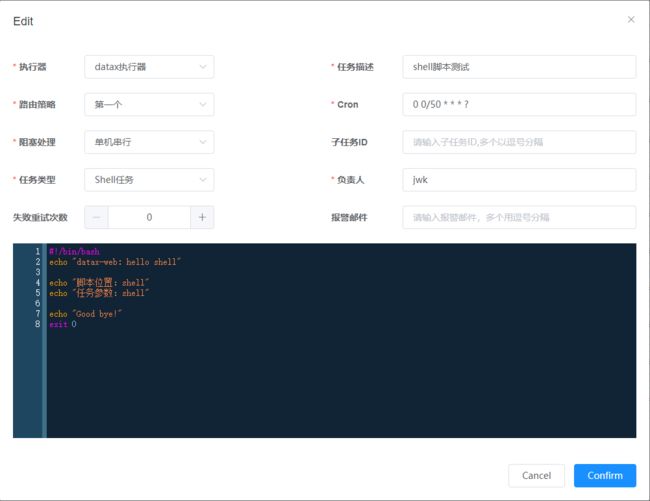
支持DataX任务,Shell任务,Python任务,PowerShell任务
-
阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
- 单机串行:调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
- 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
- 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
-
增量增新建议将阻塞策略设置为丢弃后续调度或者单机串行
- 设置单机串行时应该注意合理设置重试次数(失败重试的次数*每次执行时间<任务的调度周期),重试的次数如果设置的过多会导致数据重复,例如任务30秒执行一次,每次执行时间需要20秒,设置重试三次,如果任务失败了,第一个重试的时间段为1577755680-1577756680,重试任务没结束,新任务又开启,那新任务的时间段会是1577755680-1577758680
-
增量参数设置
-
分区参数设置
8. 任务列表


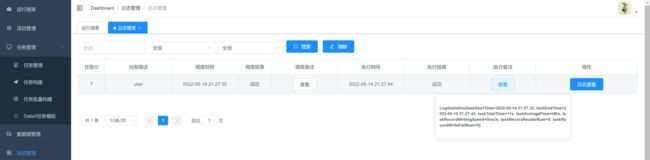
9. 查看日志
可以点击查看日志,实时获取日志信息,终止正在执行的datax进程
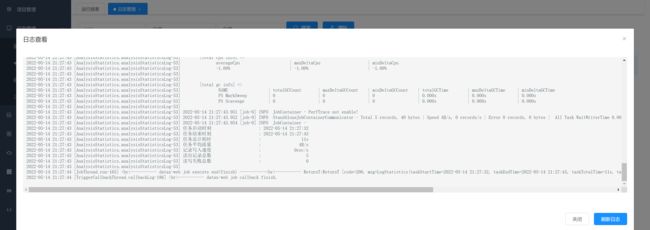
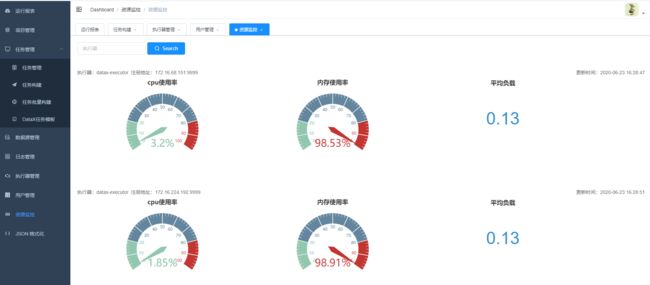
10.任务资源监控
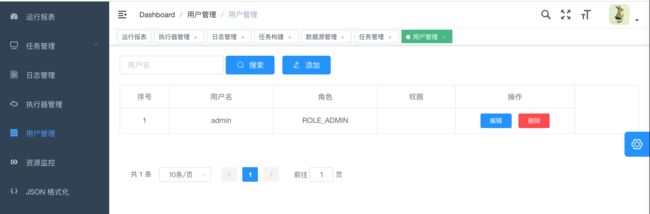
11. 用户管理
admin可以创建用户,编辑用户信息
12.运行报表