《联邦学习》——个人笔记(五)
第五章纵向联邦学习
横向联邦学习可以方便用于建立由庞大数量的移动设备所支持的应用。在这些场景下,联邦的目标是应用的消费群体,可以将其视为企业对消费者(B2C)范式。然而在很多实际场景中,联邦学习的参与方是拥有同一用户群体的组织或机构。这些组织针对同一群体收集不同的数据特征以实现不同的业务目标。他们为了提高业务效率,通常由很强的合作意向,这可以被视为企业对企业(B2B)范式。
假设有一位用户在一家银行中有一些能够反映出该用户的经济收入、消费习惯和信用评级的数据记录。同时在一家电商平台中记录着这位用户所浏览和购买的商品的历史信息。尽管这两家公司拥有用户数据的特征空间完全不同,他们彼此间却有着紧密的联系。
我们把在数据集上具有相同的样本空间、不同的特征空间的参与方所组成的联邦学习归类为纵向联邦学习,也可以理解为按特征划分的联邦学习。
5.1纵向联邦学习的定义
出于不同的商业目的,不同组织拥有的数据集通常具有不同的特征空间,但这些组织可能共享一个巨大的用户群体。通过VFL,我们可以利用分布于这些组织的异构数据,搭建更好的机器学习模型,并且不需要交换和泄露隐私数据。
在VFL的设置中,存在一些一些关于实现安全和隐私保护的假设。首先,VFL假设参与方都是诚实但好奇的。这意味着参与方虽然遵守安全协议,但将会尝试通过从其他参与方处获得信息,尽可能多地推理出信息中包含的具体内容。由于各参与方也想要搭建一个更加精确的模型,所以他们相互之间不会共谋。第二,VFL假设信息的传输过程是安全且足够可靠的,能够抵御攻击。
5.2 纵向联邦学习的架构
我们举一个例子来描述VFL的架构。假设有两家公司A和B想要协同地训练一个机器学习模型。每一家公司都拥有各自的数据,此外B方还拥有进行模型预测任务所需要 的标注数据,由于用户隐私和数据安全的原因,A方和B方不能直接交换数据。为了保证训练过程中的数据保密性,加入了一个第三方的协调者C。在这里,我们假设C方式诚实的且不与A方或B方共谋,但A方和B方都是诚实但好奇的。被信任的第三方C是一个合理的假设,因为C方的角色可以由权威机关扮演或由安全计算节点代替。
VFL系统的训练过程一般由两个部分组成(如图a):首先对齐具有相同ID,但分布于不同参与方的实体;然后基于这些已经对齐的实体执行加密的模型训练。

1.第一部分:加密实体对齐
由于A方和B方公司的用户群体不同,系统使用一种基于用户加密的用户ID对齐技术,来确保AB方不需要暴露各自的原始数据便可以对齐共同用户。在实体对齐期间,系统不会将属于某一家公司的用户暴露出来。
2.第二部分:加密模型训练
在确定共有实体后,各方可以使用这些共有实体的数据来协同训练一个机器学习模型。训练过程可以分为以下四个步骤(如图b所示)
(1)协调者C创建密钥对,并将公共密钥发送给AB方
(2)AB方对中间结果进行加密和交换。中间结果用来帮助计算梯度和损失值。
(3)AB方计算加密梯度并分别加入附加掩码。B方还会计算加密损失。AB方将加密的结果发送给C
(4)C方对梯度和损失信息进行解密,并将结果发送回A方和B方。A方和B方解除梯度信息上的掩码,并根据这些梯度信息来更新模型参数。
5.3纵向联邦学习算法
-
5.3.1 安全联邦线性回归 第一种算法是安全联邦线性回归。这种算法利用同态加密方法,在联邦线性回归模型的训练中保护属于每一个参与方的本地数据。

为了使用梯度下降方法训练一个线性回归模型,我们需要一种安全的方法来计算模型损失和梯度。给定学习率、正则化参数,A方数据集,B方数据集和标记。与其特征空间相关的模型参数ΘA,ΘB。则训练目标可以表示为:
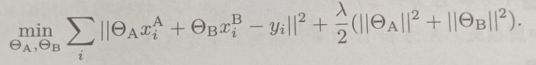
加密损失为:
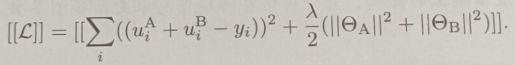

注意到A方和B方使用各自的本地数据来计算ui。然而,di中包含了uiA和uiB-yi,因此他不能由任何一方来单独计算。因此,A方和B方应该协同地计算di,同时需要针对其他参与方保护uiA和uiB-yi的隐私安全。在同态加密设定里,为了防止AB方对uiA和uiB-yi进行窥视,uiA和uiB-yi将会通过由一个第三方C拥有的公共密钥来加密。
1.安全联邦线性回归模型的训练过程
在实体对齐和模型训练期间,AB方所拥有的的数据存储在本地,并且模型训练中的交互不会导致数据隐私泄露。需要注意的是,由于C方是受信任的,所以C方的潜在信息泄露可能会或可能不会被认为是隐私侵犯。为了进一步防止C方从A方或者B方学习到相关的信息,A方和B方可以将他们的梯度信息加上加密随机掩码。
2.安全联邦线性回归模型的预测过程
在预测期间,两方需要协作地计算预测结果。 步骤一:C方将用户ID i 发送给A方和B方 步骤二:AB方分别计算uiA和uiB发送给C方,C方计算uiA+uiB的结果 -
5.3.2 安全联邦提升树(SecureBoost)
主动方:不仅是数据提供方,同时拥有样本特征和样本标签,此外,还扮演着协调者的角色,计算每个树节点的最佳分割。被动方:只是数据提供者,只提供样本特征,没有样本标签。 因此,被动方需要主动方共同地建构模型来预测标签
1.安全的样本对齐
安全联邦提升树包含主要两个步骤。首先,在隐私保护下对参与方之间具有不同特征的重叠用户进行样本对齐。然后所有参与方通过隐私保护协议共同地学习一个共享的梯度提升树模型。
SecureBoost框架的第一步是实体对齐,即在所有参与方中寻找数据样本的公共集合(如共同用户),共同用户可以同工用户ID被识别出来。特别地,我们可以通过基于加密的数据库交集算法对样本进行对齐。2.SecureBoost的训练过程
因为gi和hi的计算需要类标签,所以gi和hi必须由主动方计算得到,因为只有主动方拥有样本的标签信息,我们将在后面的算法描述中介绍到,所有的被动方都需要对它们当前节点的样本所对应的gi和hi进行聚合。因此,所有被动房需要知道gi和hi。为了保证gi和hi的隐私性,主动方将在gi和hi发送给被动方之前,对梯度进行了加法同态加密操作。需要注意的是,由于算法采用加法同态加密,被动方将不能再gi和hi加密的情况下计算分割分数。因此,分割的评估将由主动方执行。
算法:聚合梯度统计值
输入:I,当前节点的样本空间;
输入:d,特征维度
输入:{[[gi]],[[hi]]}i∈I
输出:G∈Rd*l,H∈Rd*l
For k=0 →d do
通过特征k的百分数,得到Sk = {sk1,sk2,sk3......skl}
End for
For k = 0 →d do
Gk,v = ∑i∈{i|sk,v>=xi,k>sk,v-1}[[gi]]
Hk,v = ∑i∈{i|sk,v>=xi,k>sk,v-1}[[hi]]
End for
由算法得知,每一个被动方首先要对其所有的特征进行分桶,然后将每个特征的特征值映射至每个桶中。基于分桶后的特征值,被动方将聚合相应的加密梯度统计信息。通过这种方法,主动方只需要从所有被动方处收集聚合的加密梯度信息。从而主动方可以更高效地确定全局最优分割。
算法:寻找最优分割

SecureBoost算法中一棵树的训练过程:
步骤一:从主动方开始,首先计算gi和hi,i∈{1,…,N},并使用加法同态加密对其进行加密。其中N为样本个数。主动方将加密的gi和hi,i∈{1,…,N}发送给所有的被动方。
步骤二:对于每一个被动方,根据聚合梯度统计值算法,将当前节点样本空间中样本的特征映射至桶中,并以此为基础将加密梯度统计信息聚合起来,将结果发送至主动方。
步骤三:主动方对各被动方聚合的梯度信息进行解密,并根据寻找最优分割算法确定全局最优分割,并将kopt和vopt返回给相应的被动方。
步骤四:被动方根据从主动方发送的kopt和vopt确定特征值的阈值,并对当前样本空间进行划分。然后,被动方在查找表中记录选中特征的阈值,形成记录[记录id,特征,阈值],并将记录id和IL返回给主动方
步骤五:主动方将会根据收到的[记录id,IL]对当前节点进行划分,并将当前节点与[参与方id,记录id]关联。主动方将当前节点的划分信息与所有被动方同步,并进入对下一节点的分割。
步骤六:迭代步骤2~5,直到达到训练停止条件。
当我们完成当前树的构建时,我们可以计算每个叶结点的最佳权值。然后,我们根据需求继续构建其他的决策树。
3.SecureBoost的预测过程
新样本的特征也分散于各个参与方中,并且不能对外公开。每个参与方知道自己的特征,但是对其他参与方的特征一无所知。因此,分类过程需要在隐私保护的协议下,由各参与方协调进行。分类过程从主动方的root节点开始。
步骤一:主动方查询与当前节点相关联的[参与方id,记录id]记录。基于该记录,主动方向相应参与方发送待标注样本的id和记录id,并且询问下一步的树搜索方向(即向左子节点或右子节点)。
步骤二:被动方接收到待标注样本的id和记录id后,将待标注样本中相应特征的值与本地查找表中的记录[记录id,特征,阈值]中的阈值进行比较,得出下一步的树搜索方向,然后,该被动方将搜索决定发往主动方。
步骤三:主动方接收到被动方传来的搜索决定,前往相应的子节点。
步骤四:迭代步骤1~3,直至到达一个叶结点得到分类标签以及该标签的权值。
5.4 挑战和展望
纵向联邦学习能够利用样本分散于多个参与方的多样化特征来建立一个健壮的共享模型。但与横向联邦学习中所有参与方共享一个共有的模型不同,但纵向联邦学习体系中,每个参与方都拥有与其他特征相关联的共享模型中的一部分。因此,纵向联邦学习中各参与方彼此间有更紧密的共生关系。对于分散在参与方的模型各部分的训练,也通常需要按照纵向联邦学习算法所给出的特定计算来执行。换言之,参与方之间的计算具有依赖关系,从而需要频繁的互动以交换模型训练中间结果。
因此,纵向联邦学习的训练很容易受到通信故障的影响,从而需要可靠并且高效的通信机制。在物理距离比较长的参与方之间传输模型训练中间结果是比较耗时的。
目前,大部分防止信息泄露或者对抗恶意攻击的研究都是针对横向联邦学习的场景。由于纵向联邦学习通常需要参与方之间进行更紧密和直接的交互,因此需要灵活高效的安全协议,以满足每一方的安全需求。