对“科大讯飞2021丨广告点击率预估挑战赛 Top1方案(附完整代码)_Jack_Yang的博客-CSDN博客”的补充。
这篇文章的初衷是针对科大讯飞2021丨广告点击率预估挑战赛 Top1方案(附完整代码)_Jack_Yang的博客-CSDN博客进行补充。
博客的信息量很少,对任务背景的介绍也不太对,说实话令人费解。我想的是能不能写份博客视为补充,更加严谨,也是这份博客的缘由。
比赛是讯飞的比赛 2021 iFLYTEK A.I.开发者大赛-讯飞开放平台。大赛已经结束,博主也没能拿到数据,很遗憾只能介绍结合大赛数据格式、代码说明算法设计的思维。
1. 任务背景
广告点击率预估是在线广告交易的核心环节之一,如果说一家公司想知道 CTR(点击率),以确定将他们的钱花在数字广告上是否值得。点击率高表示对该特定广告系列更感兴趣,点击率低可能表明广告可能不那么相关。高点击率表明更多人点击了网站,这有利于在谷歌、必应等在线平台上以更少的钱获得更好的广告位置。
平台展示给用户特定的广告,用户存在点击与不点击两种行为。给定某平台实际广告业务中的用户行为数据,共包含13个用户相关的字段,其中isClick字段表明用户是否会点击广告。
任务目标是通过训练集训练模型,来预测测试集中isClick字段的概率结果,即用户点击平台所推荐广告的概率,以此为依据,表示用户对特定广告感兴趣的程度。
2.数据说明
2.1 数据格式
赛题数据由训练集和测试集组成,包含13个特征字段,6天的数据。其中39万多条作为训练集(7月2-6日),7万多条作为测试集(7月7日),同时会对部分字段信息进行脱敏。

训练集:完整字段的数据(gender中有空NULL,date是排序好的行为时间(一般时序数据都要根据时间排序为timestep,便于diff))
测试集:预测是否点击isClick。
2.2 数据探索
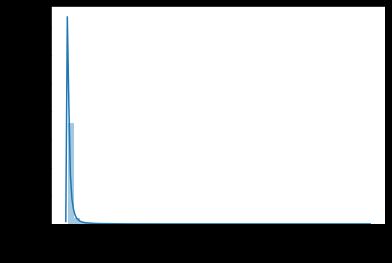
userid的分布是有偏的
import seaborn as sns from tqdm import tqdm from sklearn.model_selection import KFold import lightgbm as lgbm sns.distplot(df_tr_te['user_id'].value_counts())
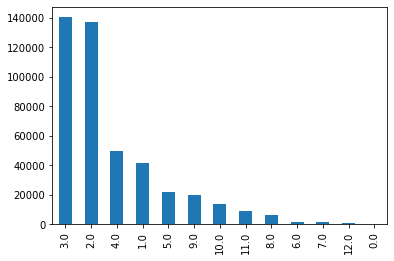
user_group_i的分布主要集中在1,2,3,4,5。
df_tr_te['user_group_id'].value_counts().plot(kind='bar')
day每天的数据是类似的(day是2~7,这里只给出了6天的数据)df_tr_te['day'].value_counts().plot(kind = 'bar')

isClick标签分布有些不平衡;
df_tr['isClick'].value_counts().plot(kind = 'bar')
每一天用户的点击率会有些许差异,但大致都在0.06-0.075之间。
df_tr_te.loc[df_tr_te['isClick']!=-1].groupby('day')['isClick'].mean().plot()
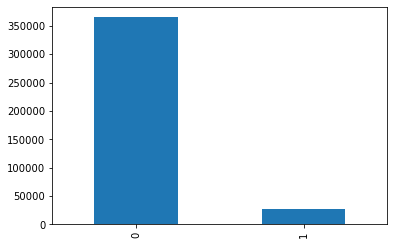

下手这种题目,一般先从活动特征、商品历史特征、时间序列特征下手。活动特征是外部导致(外部特征导致,一般来源于业务本身)、商品历史特征(统计比例、权重设置,这个主要靠想象了)、时间序列特征(可以做的处理比较多)可以参考这份博客学学。开源-BDCI2018供应链需求预测模型第一名解决方案和代码_fengdu78的博客-CSDN博客
具体特征可以有这些
a. 常用的count和nunique特征, 至于按几个分类变量分组, 需要多尝试;
b. 时间特征: 因为数据涉及时间, 所有构造了很多时间差, 平均用时, 总用时特征, 不同分类组合的平均用时, 总用时特征;
c. 权重特征: 次赛题业务涉及广告, 广告出现的次数和它此次被点击的概率应该成反比, 所有构造了很多权重特征;
d. 历史点击率特征
e. 其他特征: 星期归类, 频次较少的样本归为一类等
下面结合代码介绍各个特征吧。
3.代码介绍
1、准备数据
# ============================================================================= # # 导入工具包 # ============================================================================= import numpy as np import pandas as pd import matplotlib.pyplot as plt import os import seaborn as sns from sklearn.model_selection import KFold import lightgbm as lgb from sklearn.metrics import f1_score, roc_auc_score import warnings warnings.filterwarnings('ignore') os.chdir('C:/Users/yyz/Desktop/比赛/广告点击率/data/广告点击率预估挑战赛_数据集/') # ============================================================================= # # 读取数据并合并 # ============================================================================= df_tr = pd.read_csv('train.csv') df_te = pd.read_csv( 'test.csv') df_tr_te = pd.concat([df_tr,df_te],axis=0,ignore_index = True) # 区分训练集和测试 df_tr_te['isClick'] = df_tr_te['isClick'].fillna(-1) # 读取待提交的数据 df_sub = pd.read_csv('sample_submit.csv')
2、特征工程
- 考虑到user_id为有偏分布,可对出现user_id的次数小于等于3的归一类。变成活跃/非活跃的特征。
# 对日期进行分列 df_tr_te['hour'] = df_tr_te['date'].apply(lambda x: int(x.split(' ')[-1].split(':')[0])) df_tr_te['day']= df_tr_te['date'].apply(lambda x: int(x.split(' ')[0].split('-')[1])) # 对user_id计数小于等于3的归为1类 te = df_tr_te['user_id'].value_counts().reset_index() lis_thr = te[te['user_id']<=3]['index'].unique().tolist() df_tr_te['thr'] = np.where(df_tr_te['user_id'].isin(lis_thr),0,1)
- 统计历史点击率特征。分析各用户在历史window_size天内的产品点击率。历史点击率大的人说明点击的可能性越大,这里的day是2~7,所以才有range(3,8)。最终得到每个user_id在某一date(day)的前window_size的历史综合点击率,并增补到原数据的列中。
# 历史点击率 def _his_click_rate(df, f1, window_size = 2): fea_name = '{}_his_{}_clickrate'.format(f1,window_size ) df[fea_name] = 0 for i in tqdm(range(3,8)): df_t = df.loc[((df['day'] >= i-window_size) & (df['day'] < i))] inds = df['day'] == i # 当前df['day']==i下的前window_size天 df.loc[inds,fea_name] = df.loc[inds,f1].map(df_t.groupby(f1)['isClick'].mean()) return df df_tr_te = _his_click_rate(df = df_tr_te, f1 = 'user_id', window_size = 5)
- 接上只是对于用户一个维度区分点击率,能不能把网页这个维度加进去。还是历史特征,只不多是某个用户在某个网页的过去window_size天内的综合点击率。
# 在baseline的基础上又增加了一个 df_tr_te['user_id_webpage_id'] = [str(i)+ str(j) for i,j in zip(df_tr_te['user_id'],df_tr_te['webpage_id'])] df_tr_te = _his_click_rate(df = df_tr_te, f1 = 'user_id_webpage_id', window_size = 5)
- 现在要加上和产品一起分析,目的就是分析对产品是否点击。分析某一用户在同一天对同个产品的平均点击次数。 rolling(3).mean()表示3个一组滑动求平均,shift表示往后偏置1位(没明白具体作用)。
# 窗口特征 df_tr_te['user_product_day_5mean'] = df_tr_te.groupby(['user_id','product','day']) ['isClick'].transform(lambda x: x.rolling(3).mean().shift(1))历史点击率特征分析结束。当然可以根据产品类型category进一步分析点击率,不断扩充新的特征。
- 其他特征。填补空缺,时间离散替换。
# 缺失值数据填充并替换 df_tr_te['gender'] = df_tr_te['gender'].fillna('NAN').map({'Female':1,'Male':0,'NAN':-1}) # 星期数据替换, 主要将周五 周六 周天归为一类 df_tr_te['xingqi'] = df_tr_te['day'].replace([2,3,4,5,6,7],[2,2,1,0,0,0])其他特征分析结束。可以进一步分析,某一产品的男女比例,产品类型的男女比例,作为其他标注特征。
- 统计单变量历史分布比例特征。分析各变量特征的分布,以特征作为相同值,.groupby(特征)['行为id'],得到各特征出现的count次数——单变量特征
- 统计组合变量历史分布比例特征。两两itertool permutations组合特征变量list(c),作为相同特征值,.groupby(list(c))['id'].transform('count'),得到组合特征出现的count次数——双变量特征
# 单变量count特征 for c in ['user_id','product','hour','campaign_id','webpage_id','user_group_id','age_level', 'gender','day','product_category_id','user_depth']: df_tr_te[c + '_cnt'] = df_tr_te.groupby(c)['id'].transform('count') # 双变量的count特征 import itertools lis_i = ['user_id','product','hour','campaign_id','webpage_id','user_group_id','age_level', 'gender','day','product_category_id','user_depth'] lis_i_re = list(itertools.permutations(lis_i, 2)) for c in lis_i_re: df_tr_te[c[0] + c[1] + '_cnt'] = df_tr_te.groupby(list(c))['id'].transform('count')特征变量的历史分布分析结束。
- 时间序列特征。如何处理?因为不需要精细度较高的时间,所以常用的还是统计、差分、极值、平均值等等,这些都是常见的。如果对于连续信号、精细度好的特征,预测输出也要求准确率高,则不采用统计。
- 计算时间差。1. 同一个用户同一天同一小时,行为时间的极值; 2. 同一个用户同一天,行为时间的极值; 3. 同一用户的行为差分时间(注意.groupby(xx)[xx].transform的用法,参考dataframe groupby_Pandas笔记深入Groupby详解_weixin_39748445的博客-CSDN博客)
# 处理时间(根据数据条数猜测是2021年数据) df_tr_te['date'] = ['2021-' + i for i in df_tr_te['date']] df_tr_te['date'] = pd.to_datetime(df_tr_te['date']) # 计算按用户, 天, 小时的时间差 df_tr_te['user_time_hour'] = df_tr_te.groupby(['user_id','day','hour'])['date'].transform(lambda x: (x.max()-x.min()).total_seconds()) # 计算按用户, 天的时间差 df_tr_te['user_time_day'] = df_tr_te.groupby(['user_id','day'])['date'].transform(lambda x: (x.max()-x.min()).total_seconds()) # 一阶差分 df_tr_te['user_time_del'] = df_tr_te.groupby(['user_id'])['date'].transform(lambda x: (x.diff(periods=-1))) df_tr_te['user_time_del'] = df_tr_te['user_time_del'].apply(lambda x: x.total_seconds())
- 广告业务权重特征(活动特征)。这个需要仔细想想。广告出现的次数和它此次被点击的概率应该成反比, 所以构造权重特征。
- .groupby(['user_id'])['product'].transform(lambda x: len(x)/np.array(range(1,len(x)+1)))开始没太看懂,其实就是按照同一用户分组,得到其所有产品,对应统计产品数目len(x)。对应的值逐步递减 len(x) / np.array(range(1,len(x)+1)),第一次是len(x),后面就是len(x)-1.....模拟出点击权重的反比变化。(时间早晚排序)
- # 网页按用户, 产品权重
df_tr_te['user_id_product_webpage_range'] = df_tr_te.groupby(['user_id','product'])['webpage_id'].transform(lambda x : len(x) / np.array(range(1,len(x)+1))) 根据同一用户同一产品,分组得到所有网页数目为len(x),对应值递减。# count计数 df_tr_te['user_id_webpage_id_product'] = df_tr_te.groupby(['user_id','product','webpage_id'])['id'].transform('count') # 产品按用户, 天权重 df_tr_te['user_id_day_range'] = df_tr_te.groupby(['user_id','day'])['product'].transform(lambda x : len(x) / np.array(range(1,len(x)+1))) # 产品按用户权重 df_tr_te['user_id_range'] = df_tr_te.groupby(['user_id'])['product'].transform(lambda x : len(x) / np.array(range(1,len(x)+1))) # 网页按用户, 产品权重 df_tr_te['user_id_product_webpage_range'] = df_tr_te.groupby(['user_id','product'])['webpage_id'].transform(lambda x : len(x) / np.array(range(1,len(x)+1))) # 网页按用户, 活动权重 df_tr_te['user_id_campaign_id_webpage_range'] = df_tr_te.groupby(['user_id','campaign_id'])['webpage_id'].transform(lambda x : len(x) / np.array(range(1,len(x)+1)))
- 扩展时序特征,增补时序特征的统计信息。df_tr_te.groupby(c)['user_time_hour'].transform('mean'),计算按用户, 天, 小时的时间差的均值、综合。
# 不同组合的时间均值 lis_i_1 = ['user_id','product','campaign_id','webpage_id','product_category_id', 'user_group_id','age_level','gender','user_depth','var_1'] for c in lis_i_1: df_tr_te[str(c) + '_user_time_hour_mean'] = df_tr_te.groupby(c)['user_time_hour'].transform('mean') df_tr_te[str(c) + '_user_time_day_mean'] = df_tr_te.groupby(c)['user_time_hour'].transform('mean') df_tr_te[str(c) + '_user_time_hour_sum'] = df_tr_te.groupby(c)['user_time_hour'].transform('sum') df_tr_te[str(c) + '_user_time_day_sum'] = df_tr_te.groupby(c)['user_time_hour'].transform('sum')
- 组合时序特征统计值。df_tr_te.groupby(['gender','age_level','product_category_id'])['user_time_hour'].transform('mean'),取同一性别、同一年龄段、同一类型产品的用户时间差均值。
- df_tr_te[c[0] + c[1] + '_user_time_hour_mean'] = df_tr_te.groupby(list(c))['user_time_hour'].transform('mean') ,两两特征组合,计算时间差均值。
# 性别, 年龄, 产品的平均用时 df_tr_te['yong_time_gender_age_level_product_category_id_ave'] = df_tr_te.groupby(['gender','age_level','product_category_id'])['user_time_hour'].transform('mean')# 暴力增加2个特征的组合平均用时 lis_i_1 = ['user_id','product','campaign_id','webpage_id','product_category_id','user_group_id','age_level','gender','user_depth','var_1'] lis_i_re_1 = list(itertools.permutations(lis_i_1, 2)) for c in lis_i_re_1: df_tr_te[c[0] + c[1] + '_user_time_hour_mean'] = df_tr_te.groupby(list(c))['user_time_hour'].transform('mean')
- nunique特征。采用transform处理。
# nunique特征 for i in ['product','campaign_id','webpage_id','product_category_id']: df_tr_te['day_'+str(i)+'_nunique'] = df_tr_te.groupby(['user_id','day'])[i].transform('nunique') df_tr_te['day_'+str(i)+'_nunique_p%'] = df_tr_te['user_idday_cnt'] / df_tr_te['day_'+str(i)+'_nunique'] df_tr_te['day_web_nunique'] = df_tr_te.groupby(['user_id','day','hour'])['webpage_id'].transform('nunique')
3、建模
# ============================================================================= # 建模 # ============================================================================= # cate_features = ['user_id','product','hour','campaign_id','webpage_id','user_group_id','age_level'] features = [i for i in df_tr_te.columns if i not in ['id','isClick','date','user_id_webpage_id']] test= df_tr_te[df_tr_te['isClick']==-1] train= df_tr_te[df_tr_te['isClick']!=-1] x_train = train[features] x_test = test[features] y_train = train['isClick']明确哪些特征是需要的。['user_id','product','hour','campaign_id','webpage_id','user_group_id','age_level'] 不需要作为特征,开始5折lgb训练。
def cv_model(clf, train_x, train_y, test_x, clf_name='lgb'): folds = 5 seed = 2021 kf = KFold(n_splits=folds, shuffle=True, random_state=seed) train = np.zeros(train_x.shape[0]) test = np.zeros(test_x.shape[0]) cv_scores = [] for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)): print('************ {} *************'.format(str(i+1))) trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index] train_matrix = clf.Dataset(trn_x, label=trn_y) valid_matrix = clf.Dataset(val_x, label=val_y) params = { 'boosting_type': 'gbdt', 'objective': 'binary', 'metric': 'auc', 'min_child_weight': 5, 'num_leaves': 2**6, 'lambda_l2': 10, 'feature_fraction': 0.9, 'bagging_fraction': 0.9, 'bagging_freq': 4, 'learning_rate': 0.01, 'seed': 2021, 'nthread': 28, 'n_jobs':-1, 'silent': True, 'verbose': -1, } model = clf.train(params, train_matrix, 50000, valid_sets=[train_matrix, valid_matrix], #categorical_feature = categorical_feature, verbose_eval=500,early_stopping_rounds=200) val_pred = model.predict(val_x, num_iteration=model.best_iteration) test_pred = model.predict(test_x, num_iteration=model.best_iteration) train[valid_index] = val_pred test += test_pred / kf.n_splits cv_scores.append(roc_auc_score(val_y, val_pred)) print(cv_scores) print("%s_scotrainre_list:" % clf_name, cv_scores) print("%s_score_mean:" % clf_name, np.mean(cv_scores)) print("%s_score_std:" % clf_name, np.std(cv_scores)) return train, test lgb_train, lgb_test = cv_model(lgb, x_train, y_train, x_test)## 预测结果 df_sub['isClick'] = lgb_test df_sub.to_csv('C:/Users/yyz/Desktop/比赛/广告点击率/baseline55_5zhe_re.csv', index=False)
4. 收获心得
精细度要求不高的预测,可以采用时序特征 + 历史特征 + 活动业务特征 来挖掘隐藏信息;而精细度要求较高的,则需要时序连续信号的预测了,这里牵扯到ARIMA模型、离散信号处理(EMD、小波),后续再来分享这方面的研究想法。
你的点赞和关注是我的不断动力哦!