【模式识别大作业】
模式识别大作业
- 1. 题目:基于改进LetNet5和VIT神经网络cifar10识别方法研究
- 2. 作业内容要求:
-
- 2.1. 简述模式识别系统
- 2.2. 介绍分类器卷积和VIT神经网络基本原理
- 3. 研究实验运行环境说明
- 4. LetNet5代码设计与说明
-
- 4.1. 准备
-
- 4.1.1 下载cifar10数据集
- 4.1.2 安装相关依赖库
- 4.2.调试网络
-
- 4.2.1 运行net.py
- 4.2.2 运行train.py
- 5. VIT+cifar10代码设计与说明
-
- 5.1.安装
- 5.2.数据集
- 5.3.预训练模型
- 5.4. 结果
- 6. 运行截图
-
- 6.1改进LetNet
- 6.2 VIT+cifar10
- 7. 实验结果比较与分析
- 8. 心得体会与总结
- 9. 实验数据
1. 题目:基于改进LetNet5和VIT神经网络cifar10识别方法研究
2. 作业内容要求:
2.1. 简述模式识别系统
一个完整的模式识别系统基本上是由三部分组成,即数据采集、数据处理和分类决策或模型匹配。在设计模式识别系统时,需要注意模式类的定义、应用场合、模式表示、特征提取和选择、聚类分析、分类器的设计和学习、训练和测试样本的选取、性能评价等。针对不同的应用目的, 模式识别系统三部分的内容可以有很大的差异, 特别是在数据处理和模式分类这两部分,为了提高识别结果的可靠性往往需要加入知识库(规则)以对可能产生的错误进行修正,或通过引入限制条件大大缩小识别模式在模型库中的搜索空间,以减少匹配计算量。
2.2. 介绍分类器卷积和VIT神经网络基本原理
-
卷积神经网络(Convolutional Neural Network,简称CNN),
是一种前馈神经网络,人工神经元可以响应周围单元,可以进行大型图像处理。典型的 CNN 由3个部分构成:卷积层、池化层、全连接层。如果简单来描述的话:卷积层负责提取图像中的局部特征;池化层用来大幅降低参数量级(降维);全连接层类似传统神经网络的部分,用来输出想要的结果。链接

-
Vision Transformer (ViT)
在计算机视觉领域中,多数算法都是保持CNN整体结构不变,在CNN中增加attention模块或者使用attention模块替换CNN中的某些部分。有研究者提出,为何总是依赖于CNN呢?因此,作者提出ViT算法,仅仅使用Transformer结构也能够在图像分类任务中表现很好。受到NLP领域中Transformer成功应用的启发,ViT算法尝试将标准的Transformer结构直接应用于图像,并对整个图像分类流程进行最少的修改。具体来讲,ViT算法中,会将整幅图像拆分成小图像块,然后把这些小图像块的线性嵌入序列作为Transformer的输入送入网络,然后使用监督学习的方式进行图像分类的训练。链接

3. 研究实验运行环境说明
实验环境
电脑采用华硕的飞行堡垒笔记本GTX 1650 4G,i5-9300H 2.4GHz
神经网络采用pytorch +改进LetNet5和VIT+cifar10
4. LetNet5代码设计与说明
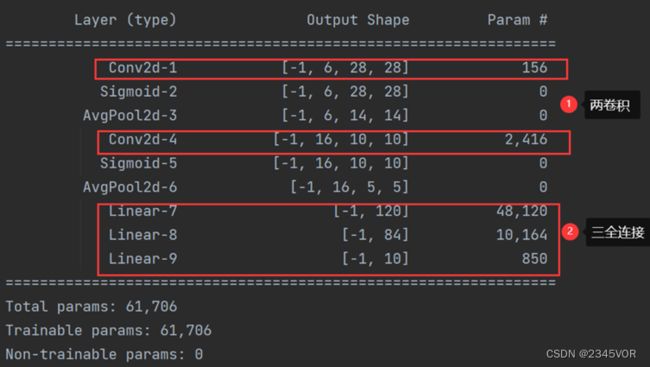
Letnet5网络结构如下:

具体参数:
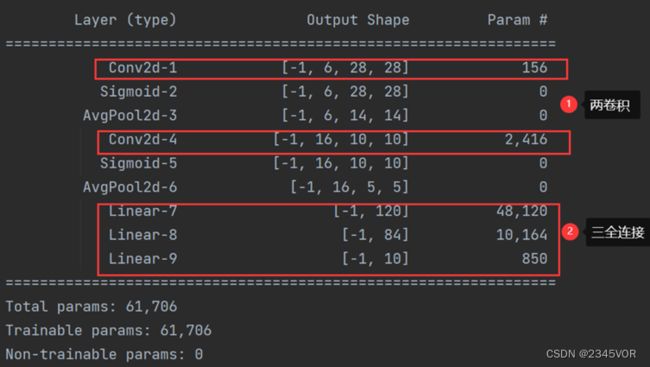
改进Letnet5参数如下:
改进LetNet+cifar10使用教程
4.1. 准备
LeNet5_cifar10源码地址:https://github.com/2345vor/LeNet5_cifar10
不妨点个star✨✨✨
4.1.1 下载cifar10数据集
https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
解压放在date文件夹解压

新建cifar_img,放入你需要预测的图片,大小为33232

4.1.2 安装相关依赖库
pip install 一下
torch PIL tensorboardX torchvision imageio pickle
4.2.调试网络
4.2.1 运行net.py
net.py
# 搭建神经网络
import torch
from torch import nn
from torchsummary import summary
class cifar_model(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 500),
nn.Linear(500, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
if __name__ == '__main__':
test_cifar = cifar_model()
input = torch.ones((64, 3, 32, 32))
output = test_cifar(input)
print(output.shape) # torch.Size([64, 10]) # 检查模型的正确性
device = torch.device('cuda:0')
test_cifar.to(device)
summary(test_cifar, (3, 32, 32))# 打印网络结构
返回网络结构
torch.Size([64, 10])
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 32, 32] 2,432
MaxPool2d-2 [-1, 32, 16, 16] 0
Conv2d-3 [-1, 32, 16, 16] 25,632
MaxPool2d-4 [-1, 32, 8, 8] 0
Conv2d-5 [-1, 64, 8, 8] 51,264
MaxPool2d-6 [-1, 64, 4, 4] 0
Flatten-7 [-1, 1024] 0
Linear-8 [-1, 500] 512,500
Linear-9 [-1, 64] 32,064
Linear-10 [-1, 10] 650
================================================================
Total params: 624,542
Trainable params: 624,542
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.44
Params size (MB): 2.38
Estimated Total Size (MB): 2.84
----------------------------------------------------------------
Process finished with exit code 0
4.2.2 运行train.py
rain.py
import time
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.utils.data import DataLoader
from net import cifar_model
import os
# 定义训练的设备
# device = torch.device("cuda")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 准备数据集
train_data = torchvision.datasets.CIFAR10("./data", train=True, transform=torchvision.transforms.ToTensor(), download=False)
test_data = torchvision.datasets.CIFAR10("./data", train=True, transform=torchvision.transforms.ToTensor(), download=False)
# length 长度
train_data_size = len(train_data) # 50000
test_data_size = len(test_data) # 10000
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用Dataloader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 加载模型并使用GPU
cifarr = cifar_model()
cifarr = cifarr.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(cifarr.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 30
# 添加tensorboard
folder = 'cifar_log'
if not os.path.exists(folder):
os.mkdir('cifar_log')
writer = SummaryWriter("./cifar_log")
start_time = time.time()
min_acc = 0
for i in range(epoch):
print("————————第{}轮训练开始————————".format(i+1))
# 训练步骤开始
cifarr.train()
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = cifarr(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() # 优化器梯度清零
loss.backward() # 反向传播,计算梯度
optimizer.step() # 根据梯度和优化器,更新权重
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time-start_time)
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 验证步骤
cifarr.eval()
total_test_loss = 0
total_accuracy = 0 # 总体的准确率
with torch.no_grad(): # 强制之后的内容不进行计算图构建
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = cifarr(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
a = total_accuracy/test_data_size
# 保存最好的模型权重文件
if a > min_acc:
folder = 'cifar_weight'
if not os.path.exists(folder):
os.mkdir('cifar_weight')
min_acc = a
print('save best model', )
torch.save(cifarr.state_dict(), "cifar_weight/best_model.pth")
# 保存最后的权重文件
if i == epoch - 1:
torch.save(cifarr.state_dict(), "cifar_weight/last_model.pth")
writer.close()
导入相关库—加载训练集和验证集—使用tensorboard记录日志—迭代训练—保存权重和日志
训练30轮,大约需要15分钟,精度达到76.01%,还行!第三十轮打印如下
————————第30轮训练开始————————
545.7393746376038
训练次数:22700, Loss:0.5816277861595154
546.7848184108734
训练次数:22800, Loss:0.6448397040367126
547.836345911026
训练次数:22900, Loss:0.7739525437355042
548.8866136074066
训练次数:23000, Loss:0.48977798223495483
549.9396405220032
训练次数:23100, Loss:0.5046865940093994
550.9778225421906
训练次数:23200, Loss:0.7065502405166626
552.0327830314636
训练次数:23300, Loss:0.6883654594421387
553.0864734649658
训练次数:23400, Loss:0.54579758644104
整体测试集上的loss:541.3202195465565
整体测试集上的正确率:0.7601000070571899
save best model
Process finished with exit code 0
打开终端,在tensorboard中查看训练效果
tensorboard --logdir “cifar_log”
可视化训练损失、测试精度、测试损失

5. VIT+cifar10代码设计与说明
Vision-Transformer-ViT源码地址:https://github.com/2345vor/Vision-Transformer-ViT
不妨点个star✨✨✨
本项目使用 ViT 对 DATA 集 CIFAR10 执行图像分类任务。Vit 和预训练权重的实现来自https://github.com/asyml/vision-transformer-pytorch。
5.1.安装
pip install 一下
torch tqdm scheduler matplotlib argparse
5.2.数据集
从http://www.cs.toronto.edu/~kriz/cifar.html下载 CIFAR10或从https://pan.baidu.com/s/1ogAFopdVzswge2Aaru_lvw获取(代码:k5v8),创建数据文件并解压 ‘./data’ 下的 cifar-10-python.tar.gz。跟前面一致
5.3.预训练模型
您可以从https://pan.baidu.com/s/1CuUj-XIXwecxWMEcLoJzPg(代码:ox9n)下载预训练文件,在./Vit_weights下创建Vit_weights floder和预训练文件,基于迁移学习的方法
运行main.py ,bach_size设置为4,只训练一次,大概需要1h15min。

main.py
# -*- coding: utf-8 -*-
# @File : main.py
# @Author : Kaicheng Yang
# @Time : 2022/01/26 11:03:50
import argparse
from torchvision import datasets, transforms
import torch
from torchvision.transforms import Resize, ToTensor, Normalize
from PIL import Image
from train import train_model
def main():
parser = argparse.ArgumentParser()
# Optimizer parameters
parser.add_argument("--learning_rate", default = 2e-5, type = float,
help = "The initial learning rate for Adam.5e-5")
parser.add_argument('--opt-eps', default = None, type = float, metavar = 'EPSILON',
help = 'Optimizer Epsilon (default: None, use opt default)')
parser.add_argument("--beta1", type = float, default = 0.99, help = "Adam beta 1.")
parser.add_argument("--beta2", type = float, default = 0.99, help = "Adam beta 2.")
parser.add_argument("--eps", type = float, default = 1e-6, help = "Adam epsilon.")
parser.add_argument('--momentum', type = float, default = 0.9, metavar = 'M',
help = 'Optimizer momentum (default: 0.9)')
parser.add_argument('--weight_decay', type = float, default = 2e-5,
help = 'weight decay (default: 2e-5)')
parser.add_argument(
"--warmup", type = int, default = 500, help = "Number of steps to warmup for."
)
parser.add_argument("--batch_size", type = int, default = 4, help = "Number of steps to warmup for.")
parser.add_argument("--epoches", type = int, default = 1, help = "Number of steps to warmup for.")
#Vit params
parser.add_argument("--output", default = './output', type = str)
parser.add_argument("--vit_model", default = './Vit_weights/imagenet21k+imagenet2012_ViT-B_16-224.pth', type = str)
parser.add_argument("--image_size", type = int, default = 224, help = "input image size", choices = [224, 384])
parser.add_argument("--num-classes", type = int, default = 10, help = "number of classes in dataset")
parser.add_argument("--patch_size", type = int, default = 16)
parser.add_argument("--emb_dim", type = int, default = 768)
parser.add_argument("--mlp_dim", type = int, default = 3072)
parser.add_argument("--num_heads", type = int, default = 12)
parser.add_argument("--num_layers", type = int, default = 12)
parser.add_argument("--attn_dropout_rate", type = float, default = 0.0)
parser.add_argument("--dropout_rate", type = float, default = 0.1)
args = parser.parse_args()
normalize = Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
transform = transforms.Compose([
Resize((224, 224)),
ToTensor(),
normalize,
])
trainset = datasets.CIFAR10(root = './data', train = True,
download = True, transform = transform)
testset = datasets.CIFAR10(root = './data', train = True,
download = True, transform = transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size = args.batch_size,
shuffle = True, num_workers = 2)
testloader = torch.utils.data.DataLoader(testset, batch_size = args.batch_size,
shuffle = False, num_workers = 2)
train_model(args, trainloader, testloader)
if __name__ == '__main__':
main()
model.py
# -*- coding: utf-8 -*-
# @File : model.py
# @Author : Kaicheng Yang
# @Time : 2022/01/26 11:03:24
import torch
import torch.nn as nn
import torch.nn.functional as F
class PositionEmbs(nn.Module):
def __init__(self, num_patches, emb_dim, dropout_rate = 0.1):
super(PositionEmbs, self).__init__()
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, emb_dim))
if dropout_rate > 0:
self.dropout = nn.Dropout(dropout_rate)
else:
self.dropout = None
def forward(self, x):
out = x + self.pos_embedding
if self.dropout:
out = self.dropout(out)
return out
class MlpBlock(nn.Module):
""" Transformer Feed-Forward Block """
def __init__(self, in_dim, mlp_dim, out_dim, dropout_rate = 0.1):
super(MlpBlock, self).__init__()
# init layers
self.fc1 = nn.Linear(in_dim, mlp_dim)
self.fc2 = nn.Linear(mlp_dim, out_dim)
self.act = nn.GELU()
if dropout_rate > 0.0:
self.dropout1 = nn.Dropout(dropout_rate)
self.dropout2 = nn.Dropout(dropout_rate)
else:
self.dropout1 = None
self.dropout2 = None
def forward(self, x):
out = self.fc1(x)
out = self.act(out)
if self.dropout1:
out = self.dropout1(out)
out = self.fc2(out)
out = self.dropout2(out)
return out
class LinearGeneral(nn.Module):
def __init__(self, in_dim = (768,), feat_dim = (12, 64)):
super(LinearGeneral, self).__init__()
self.weight = nn.Parameter(torch.randn(*in_dim, *feat_dim))
self.bias = nn.Parameter(torch.zeros(*feat_dim))
def forward(self, x, dims):
a = torch.tensordot(x, self.weight, dims = dims) + self.bias
return a
class SelfAttention(nn.Module):
def __init__(self, in_dim, heads = 8, dropout_rate = 0.1):
super(SelfAttention, self).__init__()
self.heads = heads
self.head_dim = in_dim // heads
self.scale = self.head_dim ** 0.5
self.query = LinearGeneral((in_dim,), (self.heads, self.head_dim))
self.key = LinearGeneral((in_dim,), (self.heads, self.head_dim))
self.value = LinearGeneral((in_dim,), (self.heads, self.head_dim))
self.out = LinearGeneral((self.heads, self.head_dim), (in_dim,))
if dropout_rate > 0:
self.dropout = nn.Dropout(dropout_rate)
else:
self.dropout = None
def forward(self, x):
b, n, _ = x.shape
q = self.query(x, dims = ([2], [0]))
k = self.key(x, dims = ([2], [0]))
v = self.value(x, dims = ([2], [0]))
q = q.permute(0, 2, 1, 3)
k = k.permute(0, 2, 1, 3)
v = v.permute(0, 2, 1, 3)
attn_weights = torch.matmul(q, k.transpose(-2, -1)) / self.scale
attn_weights = F.softmax(attn_weights, dim = -1)
out = torch.matmul(attn_weights, v)
out = out.permute(0, 2, 1, 3)
out = self.out(out, dims = ([2, 3], [0, 1]))
return out
class EncoderBlock(nn.Module):
def __init__(self, in_dim, mlp_dim, num_heads, dropout_rate = 0.1, attn_dropout_rate = 0.1):
super(EncoderBlock, self).__init__()
self.norm1 = nn.LayerNorm(in_dim)
self.attn = SelfAttention(in_dim, heads = num_heads, dropout_rate = attn_dropout_rate)
if dropout_rate > 0:
self.dropout = nn.Dropout(dropout_rate)
else:
self.dropout = None
self.norm2 = nn.LayerNorm(in_dim)
self.mlp = MlpBlock(in_dim, mlp_dim, in_dim, dropout_rate)
def forward(self, x):
residual = x
out = self.norm1(x)
out = self.attn(out)
if self.dropout:
out = self.dropout(out)
out += residual
residual = out
out = self.norm2(out)
out = self.mlp(out)
out += residual
return out
class Encoder(nn.Module):
def __init__(self, num_patches, emb_dim, mlp_dim, num_layers = 12, num_heads = 12, dropout_rate = 0.1, attn_dropout_rate = 0.0):
super(Encoder, self).__init__()
# positional embedding
self.pos_embedding = PositionEmbs(num_patches, emb_dim, dropout_rate)
# encoder blocks
in_dim = emb_dim
self.encoder_layers = nn.ModuleList()
for _ in range(num_layers):
layer = EncoderBlock(in_dim, mlp_dim, num_heads, dropout_rate, attn_dropout_rate)
self.encoder_layers.append(layer)
self.norm = nn.LayerNorm(in_dim)
def forward(self, x):
out = self.pos_embedding(x)
for layer in self.encoder_layers:
out = layer(out)
out = self.norm(out)
return out
class VisionTransformer(nn.Module):
""" Vision Transformer """
def __init__(self,
image_size = (256, 256),
patch_size = (16, 16),
emb_dim = 768,
mlp_dim = 3072,
num_heads = 12,
num_layers = 12,
attn_dropout_rate = 0.0,
dropout_rate = 0.1):
super(VisionTransformer, self).__init__()
h, w = image_size
# embedding layer
fh, fw = patch_size
gh, gw = h // fh, w // fw
num_patches = gh * gw
self.embedding = nn.Conv2d(3, emb_dim, kernel_size = (fh, fw), stride = (fh, fw))
# class token
self.cls_token = nn.Parameter(torch.zeros(1, 1, emb_dim))
# transformer
self.transformer = Encoder(
num_patches = num_patches,
emb_dim = emb_dim,
mlp_dim = mlp_dim,
num_layers = num_layers,
num_heads = num_heads,
dropout_rate = dropout_rate,
attn_dropout_rate = attn_dropout_rate)
def forward(self, x):
emb = self.embedding(x) # (n, c, gh, gw)
emb = emb.permute(0, 2, 3, 1) # (n, gh, hw, c)
b, h, w, c = emb.shape
emb = emb.reshape(b, h * w, c)
# prepend class token
cls_token = self.cls_token.repeat(b, 1, 1)
emb = torch.cat([cls_token, emb], dim = 1)
# transformer
feat = self.transformer(emb)
return feat
class CAFIA_Transformer(nn.Module):
def __init__(self, args):
super(CAFIA_Transformer, self).__init__()
self.vit = VisionTransformer(
image_size = (args.image_size, args.image_size),
patch_size = (args.patch_size, args.patch_size),
emb_dim = args.emb_dim,
mlp_dim = args.mlp_dim,
num_heads = args.num_heads,
num_layers = args.num_layers,
attn_dropout_rate = args.attn_dropout_rate,
dropout_rate = args.dropout_rate)
self.init_weight(args)
self.classifier = nn.Linear(args.emb_dim, args.num_classes)
def init_weight(self, args):
state_dict = torch.load(args.vit_model)['state_dict']
del state_dict['classifier.weight']
del state_dict['classifier.bias']
self.vit.load_state_dict(state_dict)
def forward(self, batch_X):
feat = self.vit(batch_X)
output = self.classifier(feat[:, 0])
return output
predict1.py
import os
import json
import argparse
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import CAFIA_Transformer
# 获取预测结果
# classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
def predict():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
# load image
img_path = "./image/bird.png"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path).convert('RGB')
#img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
parser = argparse.ArgumentParser()
parser.add_argument("--output", default='./output', type=str)
parser.add_argument("--vit_model", default='./Vit_weights/imagenet21k+imagenet2012_ViT-B_16-224.pth', type=str)
parser.add_argument("--image_size", type=int, default=224, help="input image size", choices=[224, 384])
parser.add_argument("--num-classes", type=int, default=10, help="number of classes in dataset")
parser.add_argument("--patch_size", type=int, default=16)
parser.add_argument("--emb_dim", type=int, default=768)
parser.add_argument("--mlp_dim", type=int, default=3072)
parser.add_argument("--num_heads", type=int, default=12)
parser.add_argument("--num_layers", type=int, default=12)
parser.add_argument("--attn_dropout_rate", type=float, default=0.0)
parser.add_argument("--dropout_rate", type=float, default=0.1)
args = parser.parse_args()
model = CAFIA_Transformer(args)
model.to(device) #has_logits=False要和训练时(train.py)设置的一样
# load model weights
model_weight_path = "./output/0.9912199974060059.pt"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
if predict[predict_cla].numpy() <0.5:
print_res = "class: {} prob: {:.3}".format('no match',
predict[predict_cla].numpy())
else:
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
print(print_res)
plt.show()
if __name__ == '__main__':
predict()
5.4. 结果
基于预训练的权重,经过一个 epoch,我们得到 99.1 %Accuracy

6. 运行截图
6.1改进LetNet
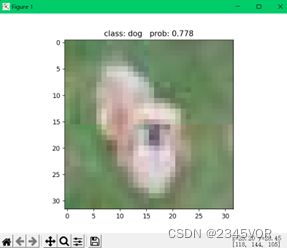
改进LetNet运行主程序main.py,返回如下,预测狗dog,预测率为77.8%
torch.Size([3, 32, 32])
class: plane prob: 0.000458
class: car prob: 1.94e-08
class: bird prob: 0.124
class: cat prob: 0.0532
class: deer prob: 0.0414
class: dog prob: 0.778
class: frog prob: 5.11e-05
class: horse prob: 0.0019
class: ship prob: 0.000887
class: truck prob: 1.69e-07
Process finished with exit code 0
效果
6.2 VIT+cifar10
首先添加几张image png图片
运行predict1.py,此时默认预测图片为502.png,返回不匹配
class: no match prob: 0.222

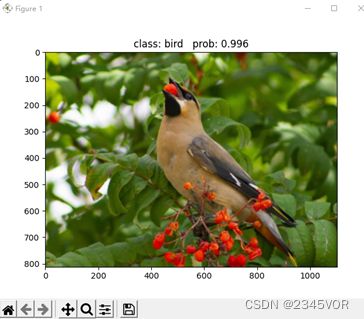
更改预测图片为bird.png,返回预测概率为99.6%,已经非常高啦!
class: bird prob: 0.996
7. 实验结果比较与分析
(两种方法识别结果比较,精度、迭代次数等)
| 神经网络 | 精度 | 迭代时间 | Bach_size | 迭代次数 |
|---|---|---|---|---|
| 改进LetNet5 | 76.01% | 15min | 64 | 30 |
| VIT | 99.12% | 1h15min | 4 | 1 |
8. 心得体会与总结
首先非常感谢程老师给我们上的模式识别课程,让我们对模式识别有一定的系统性认识,从一开始的均值和方差导入寻寻善诱,让我们对模式和识别这一块有了更加深入的认识,同时一路上走来非常感动有许多组分享了非常精彩的网络结构以及心得体会,期待神经网络会让模式识别发扬光大!
本次实验两种神经网络都是来自于网络,因为要适配自己的电脑,需要调整里面的相关参数,难免会遇到许多bug,但是就这样一点一点的调,也会收获许多,例如tensorboard的显示,根据训练的权重进行预测输出显示等等。
从以上实验可知,虽然Transformer体系结构已经成为自然语言处理任务的事实标准,但其在计算机视觉中的应用仍然有限。在视觉中,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构。我们表明,这种对CNN的依赖是不必要的,直接应用于图像块序列的纯变换器可以很好地执行图像分类任务。当对大量数据进行预训练并将其传输到多个中小型图像识别基准(ImageNet、CIFAR-10、VTAB等)时,与最先进的卷积网络相比,视觉转换器(ViT)可以获得优异的结果,同时需要的计算资源大大减少。
9. 实验数据
CIFAR-10,包含了6万张分辨率为32x32的图片,一共分为了10类,飞机、汽车、鸟类、猫、鹿、狗、蛙类、马、船和卡车。数据集中一共有50000 张训练图片和10000 张测试图片。

参考文献:
Vision-Transformer-ViT
【利用pytorch搭建改进LeNet-5网络模型(win11)续】
代码:
- LeNet5_cifar10源码地址:https://github.com/2345vor/LeNet5_cifar10
- Vision-Transformer-ViT源码地址:https://github.com/2345vor/Vision-Transformer-ViT
不妨点个star✨✨✨