分布式训练
分布式训练
- 为什么分布式训练流行
-
- 常见的并行策略
-
- 数据并行
- AllReduce
- 模型并行
- 流水并行
- 混合并行
- 集群的全局视角
-
- Placement
- SBP
- SBP Signature
- Boxing 机制
- Global Tensor
-
- 创建 Global Tensor
-
- 直接创建 global tensor
- 由 global tensor 得到 tocal tensor
- 由 local tensor 转换得到 global tensor
- 多机训练时的环境变量
- 2D SBP
-
- 2D 设备阵列
- 2D SBP
- 2D SBP Signature
- 用launch 模块启动分布式训练
-
- 常见选项说明
- launch 模块与并行策略的关系
- 数据并行训练
-
- DistributedSampler
- 流水并行训练
-
- 设置placement 和 sbp
为什么分布式训练流行
数度学习模型规模越来越大,因为内存墙的存在,单一设备的算力及容量受限于物理电路,持续提高芯片集成越来越困难,难以跟上模型扩大的需求。
以下内容整理自 OneFlow官网
常见的并行策略
简单的机器堆叠并不一定会带来算力的增长。它不仅需要多个设备进行计算,还涉及到设备之间的数据传输,只有协调好集群中的计算与通信,才能做高效的分布式训练。
数据并行
数据并行,将数据 x 进行切分,每个设备上模型 w 是完整的、一直的。如下图所示,x 被按照第 0 维度平均切分到 2 个设备上,两个设备上都有完整的 w。
这样,在两台设备上,分别得到的输出,都只是逻辑上输出的一半(形状为 ),将两个设备上的输出拼接到一起,才能得到逻辑上完整的输出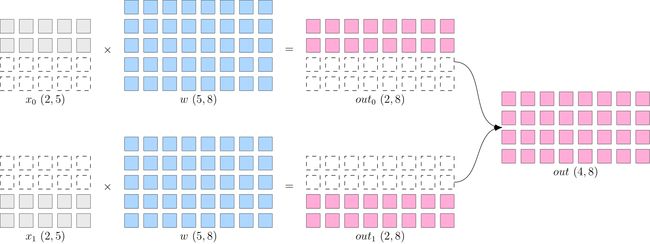
注意,因为数据被分发到了2个设备上,因此反向传播过程,各自设备上得到的 ∂ l o s s ∂ w \frac{\partial loss}{\partial w} ∂w∂loss会不一样,如果直接使用各个设备上的梯度更新各自的模型,会造成2个设备上的 模型不一致,训练就失去了意义(到底用哪个模型好呢?)
数据并行策略下,在反向传播过程中,需要对各个设备上的梯度进行 AllReduce,以确保各个设备上的模型始终保持一致.
当数据集较大,模型较小的时候,由于反向过程中为同步梯度产生的通信代价较小,此时选择数据并行一般比较有优势。
AllReduce
- AllReduce 操作对跨设备数据执行 reduction ,将结果写入每个rank的接收缓冲中。
- AllReduce操作是 rank 不可知的 (rank-agnostic)。对rank重新排序
模型并行
- 神经网络非常巨大,并行同步梯度代价很大,网络巨大到无法存放到单一计算设备中,采用模型并行策略解决问题
- 每个设备上数据完整的,模型w被切分到各个设备上,每个设备只有模型的一部分,所有计算设备上的模型拼在一起,才是完整的模型。
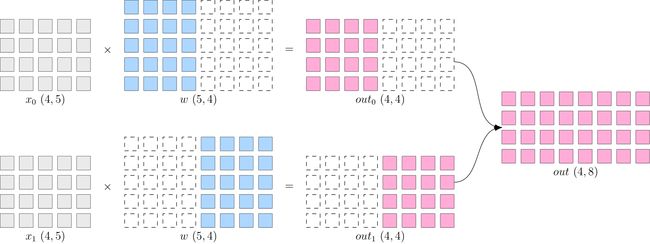
- 模型并行的好处是,省去了多个设备之间的梯度 AllReduce;
- 但是,由于每个设备都需要完整的数据输入,因此,数据会在多个设备之间进行广播,产生通信代价。
- 例如上图结果 out(4x8), 如果它作为下一层网络的输入,那么它就需要被广播发送到两个设备上。
- 语言模型,如 BERT,常采用模型并行。
流水并行
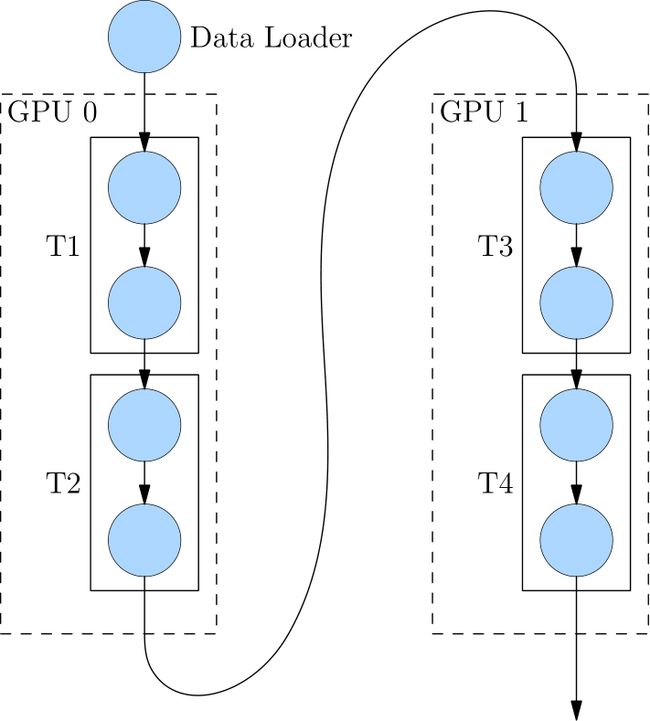
当神经网络过于巨大,无法在一个设备上存放时,除了上述的模型并行的策略外,还可以选择流水并行。 流水并行指将网络切为多个阶段,并分发到不同的计算设备上,各个计算设备之间以“接力”的方式完成训练。
-
4层网络被切分到2个计算设备上,其中 GPU0 上进行 T1 与 T2 的运算,GPU1 上进行 T3 与 T4 的计算。
-
GPU0 上完成前两层的计算后,它的输出被当作 GPU1 的输入,继续进行后两层的计算
混合并行
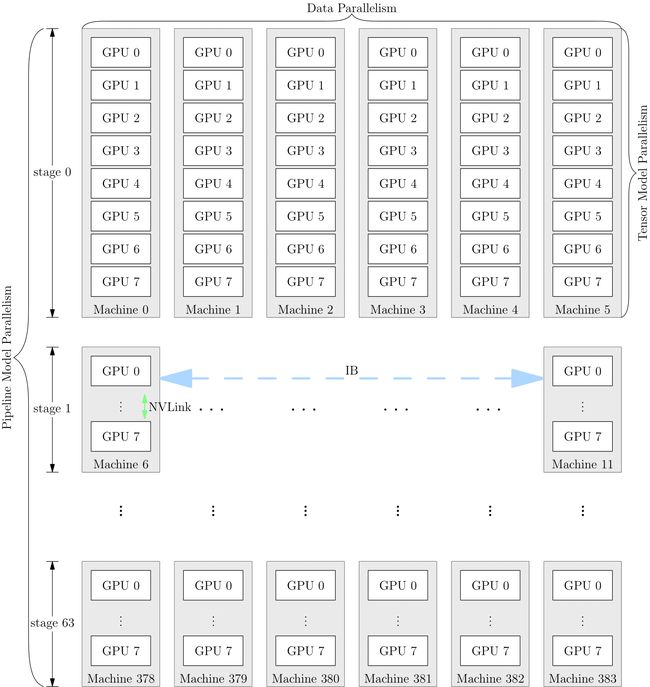
网络的训练中,也可以将多种并行策略混用,以 GPT-3 为例,以下是它训练时的设备并行方案:
它首先被分为 64 个阶段,进行流水并行。每个阶段都运行在 6 台 DGX-A100 主机上。在6台主机之间,进行的是数据并行训练;每台主机有 8 张 GPU 显卡,同一台机器上的8张 GPU 显卡之间是进行模型并行训练。
集群的全局视角
- 在全局视角下,集群被抽象成一台“超级计算机”
- 用户不用关心集群中计算、通信的细节,只需关心逻辑上的数据与计算,依然像单机单卡那样思考、编程,就能进行分布式训练。
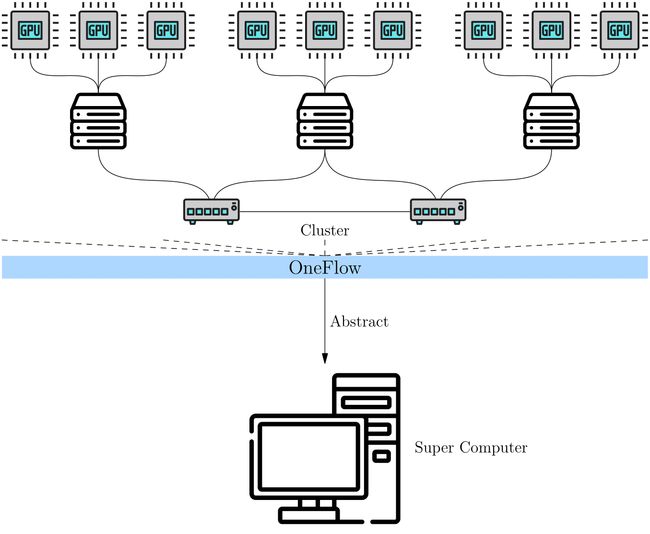
在OneFlow的全局视角下,几个重要概念: Placement、SBP与 SBP Signature
Placement
- Tensor 有 placement属性,通过placement属性可以指定该tensor 存放在那个物理设备上
SBP
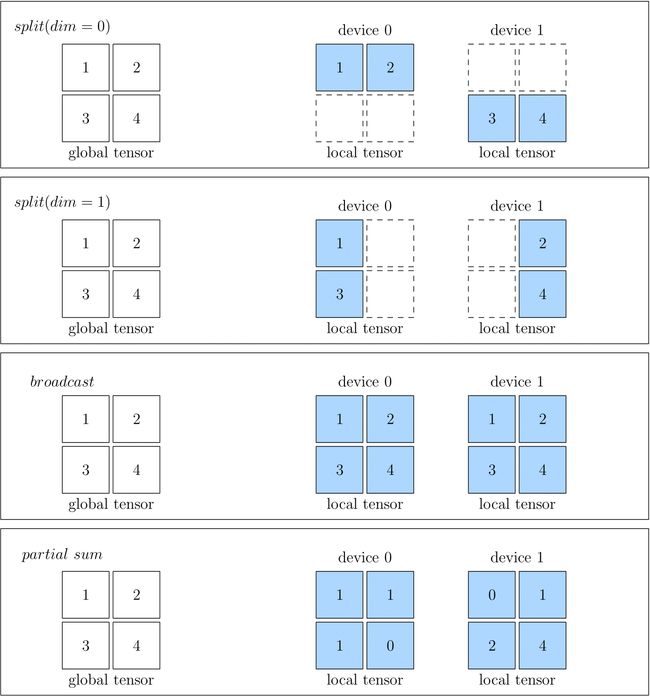
- 全局视角下,数据与集群中真实的物理设备上的数据的映射关系,split ,boradcast,partial
- split: 表示物理设备上的Tensor,将全局视角的Tensor切分得到的。 物理设备上的 Tensor ,经过拼接,可以还原得到全局视角的 Tensor 。
- broadcast 表示全局视角下的Tensor,恢复至并广播到所有物理设备上
- partial 表示全局视角下的 Tensor 与物理设备上的 Tensor 的 形状相同,但是物理设备上的值,只是全局视角下 Tensor 的 一部分。以 partial sum 为例,如果我们将集群中所有设备的张量按位置相加,那么就可以还原得到全局视角的 Tensor。除了 sum 外,min、max 等操作也适用于 partial
SBP Signature
SBP 描述了全局视角下的数据与物理设备上的数据的映射关系,当进行分布式训练时,OneFlow 根据数据的 SBP 属性,将数据分发到各个物理设备,进行计算,并输出结果。
- 对于某个算子,其输入输出的一个 特定的、合法的 SBP 组合,称为这个算子的一个 SBP Signature
- 因为有预设好的 SBP Signature,所以,某一层算子只要有输入的 SBP,OneFlow 就可以根据 SBP Signature 推导出该层算子输出的 SBP。
- 用户是不需要为每层网络都设置输入的 SBP。而只有最初输入层,或者需要强制指定某层的 SBP 时,才需要显式指定。上有算子的输出,又是下游算子的输入,这样就确定了下游算子输入的SBP
- SBP Signature 自动推导,指的是:在给定所有算子的所有合法的 SBP Signature 的前提下,OneFlow 有一套算法,会基于传输代价为每种合法的 SBP Signature 进行打分,并选择传输代价最小的那个 SBP Signature。这样使得系统的吞吐效率最高。
Boxing 机制
- 对用户透明
- 上一层算子的输出与下一层算子的输入的 SBP 属性不匹配时,OneFlow 会检测不一致,并在上游的输出和下游的输入之间插入一个算子没做相关的转换工作,称为Boxing算子
举个具体例子,比如以下代码中,上一层算子 matmul 的输出 SBP 本来是 split(0),但是下一层算子 matmul 的输入,被转成了 broadcast。此时,上一层的输出与下一层的输入,它们的 SBP 其实就不一致了。
import oneflow as flow
P0 = flow.placement("cuda", ranks=[0, 1])
P1 = flow.placement("cuda", ranks=[2, 3])
a0_sbp = flow.sbp.split(0)
b0_sbp = flow.sbp.broadcast
y0_sbp = flow.sbp.broadcast
b1_sbp = flow.sbp.split(1)
A0 = flow.randn(4, 5, placement=P0, sbp=a0_sbp)
B0 = flow.randn(5, 8, placement=P0, sbp=b0_sbp)
Y0 = flow.matmul(A0, B0)
Y0 = Y0.to_global(placement=P1, sbp=y0_sbp)
B1 = flow.randn(8, 6, placement=P1, sbp=b1_sbp)
Y2 = flow.matmul(Y0, B1)

Global Tensor
全局视角与物理视角的映射
创建 Global Tensor
直接创建 global tensor
import oneflow as flow
placement = flow.placement("cuda", [0,1])
sbp = flow.sbp.split(0)
x = flow.randn(4,5,placement=placement, sbp=sbp)
x.shape
oneflow.Size([4, 5])
由 global tensor 得到 tocal tensor
to_local()
Returns the local component of this global tensor in the current rank.
x.to_local()
tensor([[ 2.9186e-01, -3.9442e-01, 4.7072e-04, -3.2216e-01, 1.7788e-01],
[-4.5284e-01, 1.2361e-01, -3.5962e-01, 2.6651e-01, 1.2951e+00]],
device='cuda:0', dtype=oneflow.float32)
由 local tensor 转换得到 global tensor
可以先创建 local tensor,再利用 Tensor.to_global 方法,将 local tensor 转为 global tensor
多机训练时的环境变量
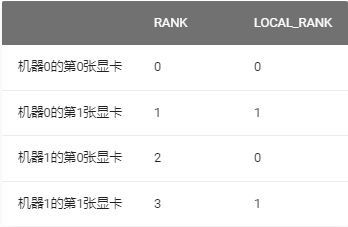
- rank 表示节点编号(n台节点即:0,1,2,…,n-1)
- MASTER _ADDR: 多级训练时的第 0 号机的IP
- MASTER——PORT: 多机训练的第 0 号机器监听端口,不与已经占用的端口号冲突。
- WORLD_SIZE: 整个集群中计算设备的数目, 目前还不支持机器上显卡数目不一致, 数目实际上是 机器数目 X 每台机器上的显卡数目
- RANK:全局视角的编号
- LOCAL_RANK: 某个特定机器上的“局部视角”的编号。当时单机训练时,两者是没有区别的。
2D SBP
2D 设备阵列
在 1D SBP 的场景下,通过 oneflow.placement 接口配置集群,比如使用集群中的第 0~3 号 GPU 显卡:
>>> placement1 = flow.placement("cuda", ranks=[0, 1, 2, 3])
ranks 可以是多维数组:
placement2 = flow.placement("cuda", ranks=[[0, 1], [2, 3]])
设备被划分成了 2X2设备阵列
2D SBP
当 placement 中的集群是 2 维的设备阵列时;SBP 也必须与之对应,是一个长度为 2 的 tuple,这个tuple中的第 0 个、第 1 个 元素,分别描述了 Global Tensor 张量在设备阵列第 0 维、第 1 维的分布。
>>> a = flow.Tensor([[1,2],[3,4]])
>>> placement = flow.placement("cuda", ranks=[[0, 1], [2, 3]])
>>> sbp = (flow.sbp.broadcast, flow.sbp.split(0))
>>> a_to_global = a.to_global(placement=placement, sbp=sbp)
- 在第0维上做 broadcast
- 在 第1维上做 split(0)
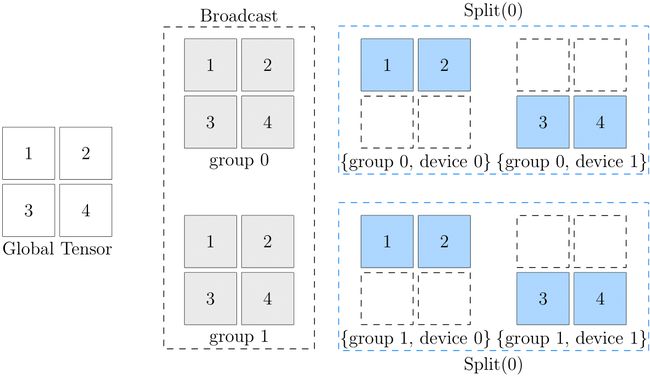
此图的最左边是全局视角的数据,最右边是设备阵列上各个设备的数据。可以看到,从第 0 维的角度看,它们都是 broadcast 的关系:
- (group0, device0) 与 (group1, device0) 中数据一致,互为 broadcast 关系
- (group0, device1) 与 (group1, device1) 中数据一致,互为 broadcast 关系
而从第 1 维的角度看,它们都是 split(0) 的关系
- (group0, device0) 与 (group0, device1) 互为 split(0) 关系
- (group1, device0) 与 (group1, device1) 互为 split(0) 关系
以 (broadcast, split(0)) 为例:
- 原始逻辑张量,先经过 broadcast,广播到 2 个 group 上,得到中间的状态
- 在中间状态的基础上,继续在各自的 group 上,做 split(0),得到最终设备阵列中各个物理张量的状态
2D SBP Signature
假定我们给 x 设置了 2D SBP 为:(broadcast, split(0)), 给 设置 2D SBP 为 (split(1), broadcast),那么,在 2D SBP 的背景下, x X w = y 运算,得到 y 的 SBP 属性为 (split(1), split(0)) 。
( b r o a d c a s t , s p l i t ( 0 ) ) X ( s p l i t ( 1 ) , b r o a d c a s t ) = ( s p l i t ( 1 ) , s p l i t ( 0 ) ) (broadcast, split(0)) X (split(1), broadcast) = (split(1), split(0)) (broadcast,split(0))X(split(1),broadcast)=(split(1),split(0))
用launch 模块启动分布式训练
python3 -m oneflow.distributed.launch [启动选项] 训练脚本.py
常见选项说明
- nnodes: 机器数目
- node_rank : 机器编号,从0开始
- nproc_per_node: 每台机器上要启动的进程数目,推荐与GPU一致
- logdir: 子进程日志的相对存储路径
launch 模块与并行策略的关系
注意 oneflow.distributed.launch 的主要作用,是待用户完成分布式程序后,让用户可以更方便地启动分布式训练。它省去了配置集群中环境变量 的繁琐。
oneflow.distributed.launch 并不决定 并行策略,并行策略是由设置数据、模型的分发方式、在物理设备上的放置位置决定的。
数据并行训练
OneFlow中 提供了两种数据并行方式。
- 一种是使用OneFlow原生得到SBP的概念,通过设置global 行两,进行数据并行训练,推荐方式。
- 为了方便从pyTorch 迁移到 OneFlow的用户,OneFlow 提供了与 torch.nn.parallel.DistributedDataParallel 对齐一致的接口 oneflow.nn.parallel.DistributedDataParallel,它也能让用户方便地从单机训练脚本,扩展为数据并行训练
DistributedSampler
DistributedSampler 会在每个进程中实例化 Dataloader,每个 Dataloader 实例会加载完整数据的一部分,自动完成数据的分发。
流水并行训练
设置placement 和 sbp
将需要使用的 placement 与 sbp 设置提前准备好:
BROADCAST = [flow.sbp.broadcast]
P0 = flow.placement("cuda", ranks=[0])
P1 = flow.placement("cuda", ranks=[1])
P0 、P1 分别代表集群的第 0 个 GPU 和第 1 个 GPU。
通过调用 nn.Module.to_global 或 Tensor.to_global 就可以将模型或张量分配到指定的计算设备上运行,将一个网络拆分为多个流水阶段(stage)