BP算法介绍
什么是神经网络?
神经网络是由很多神经元组成的,首先我们看一下,什么是神经元
上面这个图表示的就是一个神经元,我们不管其它书上说的那些什么树突,轴突的。我用个比较粗浅的解释,可能不太全面科学,但对初学者很容易理解:
1、我们把输入信号看成你在matlab中需要输入的数据,输进去神经网络后
2、这些数据的每一个都会被乘个数,即权值w,然后这些东东与阀值b相加后求和得到u,
3、上面只是线性变化,为了达到能处理非线性的目的,u做了个变换,变换的规则和传输函数有关
可能还有人问,那么那个阀值是什么呢?简单理解就是让这些数据做了个平移,这就是神经元工作的过程。处理后的结果又作为输入,可输给别的神经元,很多这样的神经元,就组成了网络。在matlab中具体用什么算法实现这些,我们先不管,我们需要注意的是怎么使用。比如使用BP的神经网络newff()构建一个网络,这些在后面的学习将提到。
BP网络的特点
①网络实质上实现了一个从输入到输出的映射功能,而数学理论已证明它具有实现任何复杂非线性映射的功能。这使得它特别适合于求解内部机制复杂的问题。我们无需建立模型,或了解其内部过程,只需输入,获得输出。只要BPNN结构优秀,一般20个输入函数 以下的问题都能在50000次的学习以内收敛到最低误差附近。而且理论上,一个三层的神经网络,能够以任意精度逼近给定的函数,这是非常诱人的期望;
②网络能通过学习带正确答案的实例集自动提取“合理的”求解规则,即具有自学习能力;
③网络具有一定的推广、概括能力。
bp主要应用
回归预测(可以进行拟合,数据处理分析,事物预测,控制等)、 分类识别(进行类型划分,模式识别等),在后面的学习中,我都将给出实例程序。
但无论那种网络,什么方法,解决问题的精确度都无法打到100%的,但并不影响其使用,因为现实中很多复杂的问题,精确的解释是毫无意义的,有意义的解析必定会损失精度。
BP注意问题
1、BP算法的学习速度很慢,其原因主要有:
a 由于BP算法本质上为梯度下降法,而它所要优化的目标函数又非常复杂,因此,必然会出现“锯齿形现象”,这使得BP算法低效;
b 存在麻痹现象,由于优化的目标函数很复杂,它必然会在神经元输出接近0或1的情况下,出现一些平坦区,在这些区域内,权值误差改变很小,使训练过程几乎停顿;
c 为了使网络执行BP算法,不能用传统的一维搜索法求每次迭代的步长,而必须把步长的更新规则预先赋予网络,这种方法将引起算法低效。
2、网络训练失败的可能性较大,其原因有:
a 从数学角度看,BP算法为一种局部搜索的优化方法,但它要解决的问题为求解复杂非线性函数的全局极值,因此,算法很有可能陷入局部极值,使训练失败;
b 网络的逼近、推广能力同学习样本的典型性密切相关,而从问题中选取典型样本实例组成训练集是一个很困难的问题。
3、网络结构的选择:
尚无一种统一而完整的理论指导,一般只能由经验选定。为此,有人称神经网络的结构选择为一种艺术。而网络的结构直接影响网络的逼近能力及推广性质。因此,应用中如何选择合适的网络结构是一个重要的问题。
4、新加入的样本要影响已学习成功的网络,而且刻画每个输入样本的特征的数目也必须相同。
5、采用s型激活函数,由于输出层各神经元的理想输出值只能接近于1或0,而不能达到1或0,因此设置各训练样本的期望输出分量Tkp时,不能设置为1或0,设置0.9或0.1较为适宜。
什么是网络的泛化能力?
一个神经网路是否优良,与传统最小二乘之类的拟合评价不同(主要依据残差,拟合优度等),不是体现在其对已有的数据拟合能力上,而是对后来的预测能力,既泛化能力。
网络的预测能力(也称泛化能力、推广能力)与训练能力(也称逼近能力、学习能力)的矛盾。一般情况下,训练能力差时,预测能力也差,并且一定程度上,随训练能力地提高,预测能力也提高。但这种趋势有一个极限,当达到此极限时,随训练能力的提高,预测能力反而下降,即出现所谓“过拟合”现象。此时,网络学习了过多的样本细节,而不能反映样本内含的规律。
过拟合是什么,怎么处理?
神经网络计算不能一味地追求训练误差最小,这样很容易出现“过拟合”现象,只要能够实时检测误差率的变化就可以确定最佳的训练次数,比如15000次左右的学习次数,如果你不观察,设成500000次学习,不仅需要很长时间来跑,而且最后结果肯定令人大失所望。
避免过拟合的一种方法是:在数据输入中,给训练的数据分类,分为正常训练用、变量数据、测试数据,在后面节将讲到如何进行这种分类。
其中变量数据,在网络训练中,起到的作用就是防止过拟合状态。
学习速率有什么作用?
学习速率这个参数可以控制能量函数的步幅,并且如果设为自动调整的话,可以在误差率经过快速下降后,将学习速率变慢,从而增加BPNN的稳定性。
此时训练方法采用
net.trainFcn = 'traingda'; % 变学习率梯度下降算法
net.trainFcn = 'traingdx'; % 变学习率动量梯度下降算法
可以定义一个变动的学习速率,如
p = [-1 -1 2 2; 0 5 0 5];
t = [-1 -1 1 1];
net = newff(p,t,3,{},'traingda');
net.trainParam.lr = 0.05;
net.trainParam.lr_inc = 1.05;
net = train(net,p,t);
y = sim(net,p)
在后面的拟合例题中,我们也将用到学习速率这个参数。
神经网络的权值和阈值分别是个什么概念?
第一节中,我们已经谈到了权值和阀值的概念。这里我们更深入的说明一下,因为他们很重要,关系到网络最后的结果。权值和阈值是神经元之间的连接,将数据输入计算出一个输出,然后与实际输出比较,误差反传,不断调整权值和阈值。
假如下面两个点属于不同的类,须设计分类器将他们分开
p1=[1 1 -1]';
p2=[1 -1 -1]';
这里用单层神经元感知器,假设初始权值
w=[0.2 0.2 0.3]
同时假设初始阀值
b=-0.3
输出 a1 a2
a1=hardlims(w*p1+b)
a2=hardlims(w*p2+b)
如果不能分开,还须不断调整w,b
用BP逼近非线性函数,如何提高训练精度
(1)调整网络结构
增加网络的层数可以进一步降低误差,提高精度但会使网络复杂化,从而增加网络的训练时间。精度的提高实际上也可以通过增加隐层神经元的数目来获得,其效果更容易观察和掌握,所以应优先考虑。
(2)初始值选取
为了使误差尽可能小 ,需要合理选择初始权重和偏置,如果太大就容易陷入饱和区,导致停顿 。一般应选为均匀分布的小数,介于 (-1,1) 。
(3)学习速率调整
学习速率的选取很重要 ,大了可能导致系统不稳定,小了会导致训练周期过长、收敛慢,达不到要求的误差。一般倾向于选取较小的学习速率以保持系统稳定,通过观察误差下降曲线来判断。下降较快说明学习率比较合适,若有较大振荡则说明学习率偏大。同时,由于网络规模大小的不同,学习率选择应当针对其进行调整。采用变学习速率的方案,令学习速率随学习进展而逐步减少,可收到良好的效果。
(4)期望误差
期望误差当然希望越小越好,但是也要有合适值。
为了充分利用数据,得到最优的网络训练结果,在网络建立前应该进行的基本数据处理问题,包括:
(1)BP神经网络matlab实现的基本步骤
(2)数据归一化问题和方法
(3)输入训练数据的乱序排法,以及分类方法
(4)如何查看和保存训练的结果
(5)每次结果不一样问题。
用matlab实现bp,其实很简单,按下面步骤基本可以了
BP神经网络matlab实现的基本步骤
1、数据归一化
2、数据分类,主要包括打乱数据顺序,抽取正常训练用数据、变量数据、测试数据
3、建立神经网络,包括设置多少层网络(一般3层以内既可以,每层的节点数(具体节点数,尚无科学的模型和公式方法确定,可采用试凑法,但输出层的节点数应和需要输出的量个数相等),设置隐含层的传输函数等。关于网络具体建立使用方法,在后几节的例子中将会说到。
4、指定训练参数进行训练,这步非常重要,在例子中,将详细进行说明
5、完成训练后,就可以调用训练结果,输入测试数据,进行测试
6、数据进行反归一化
7、误差分析、结果预测或分类,作图等
数据归一化问题
归一化的意义:
首先说一下,在工程应用领域中,应用BP网络的好坏最关键的仍然是输入特征选择和训练样本集的准备,若样本集代表性差、矛盾样本多、数据归一化存在问题,那么,使用多复杂的综合算法、多精致的网络结构,建立起来的模型预测效果不会多好。若想取得实际有价值的应用效果,从最基础的数据整理工作做起吧,会少走弯路的。
归一化是为了加快训练网络的收敛性,具体做法是:
1 把数变为(0,1)之间的小数
主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
2 把有量纲表达式变为无量纲表达式
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量
比如,复数阻抗可以归一化书写:Z = R + jωL = R(1 + jωL/R) ,复数部分变成了纯数量了,没有量纲。另外,微波之中也就是电路分析、信号系统、电磁波传输等,有很多运算都可以如此处理,既保证了运算的便捷,又能凸现出物理量的本质含义。
神经网络归一化方法:
由于采集的各数据单位不一致,因而须对数据进行[-1,1]归一化处理,归一化方法主要有如下几种,供大家参考:
1、线性函数转换,表达式如下:
y=(x-MinValue)/(MaxValue-MinValue)
说明:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。
2、对数函数转换,表达式如下:
y=log10(x)
说明:以10为底的对数函数转换。
3、反余切函数转换,表达式如下:
y=atan(x)*2/PI
matlab中归一化的实现:
matlab中的归一化处理有五种方法,只会其中一种就可以了,我喜欢用第4种,因为习惯和方便
注意:第一组和第二组归一化函数在Matlab7.0以上已遗弃,他们的用法相似,pre**是归一化,post**是反归一化,tram**是使用同样的设置归一化另外一组数据
1. 内部函数premnmx、postmnmx、tramnmx,将数据归一化到(-1,1)
premnmx的语法格式是
:[Pn,minp,maxp,Tn,mint,maxt]=premnmx(P,T)
其中P,T分别为原始输入和输出数据,minp和maxp分别为P中的最小值和最大值。mint和maxt分别为T的最小值和最大值。
我们在训练网络时,如果所用的是经过归一化的样本数据,那么以后使用网络时所用的新数据也应该和样本数据接受相同的预处理,这就要用到tramnmx,换句话说使用同一个归一化设置(setting)归一化另外一组数据。如下所示:
[Pn]=tramnmx(P,minp,maxp)
其中P和Pn分别为变换前、后的输入数据,maxp和minp分别为premnmx函返回的最大值maxp和最小值minp。
2、prestd、poststd、trastd归化数据到(0,1)
用法与1差不多。详细可以help prestd。
上述两种方法是可以相互转化的,比如,第一种归化后的数据为p,则(1+p)./2的结果就是第二种了
3、mapminmax()将数据归一化到(-1,1),是6.5中**mnmx系列的替换函数
该函数同时可以执行归一化、反归一化和归一化其他数据的功能,具体看帮助和后面的实例
% 归一化数据输入为p,输出为t
[normInput,ps] = mapminmax(p);
[normTarget,ts] = mapminmax(t);
% 反归一化
trainOutput = mapminmax('reverse',normTrainOutput,ts);
trainInsect = mapminmax('reverse',trainSamples.T,ts);
validateOutput = mapminmax('reverse',normValidateOutput,ts);
validateInsect = mapminmax('reverse',validateSamples.T,ts);
testOutput = mapminmax('reverse',normTestOutput,ts);
testInsect = mapminmax('reverse',testSamples.T,ts);
%例子:
x1 = [1 2 4; 1 1 1; 3 2 2; 0 0 0]
[y1,PS] = mapminmax(x1,0,1)% 归化到 [0,1],若不填,则默认为[-1,1]
%还原:
x1_again = mapminmax('reverse',y1,PS)
4、mapstd()将数据归一化到(0,1),是6.5中**std系列的替代函数
同理,3和4两种方法是可以相互转化的,比如,第一种归化后的数据为p,则(1+p)./2的结果就是第二种了。
5、自己写归一化函数,这个网上很多,大家可以百度下
输入训练数据的乱序排法,以及分类
注意:dividevec()函数在7.6版本还可以使用
把数据重新打乱顺序,进行输入,可以让数据更加具备典型性和更优良的泛化能力!
把数据进行打乱,并分类为:训练输入数据、变量数据、测试数据的方法
我用百度搜了一下,发现有些方法,但居然很少看到使用matlab内部函数直接进行的,其实matlab自带的内部函数dividevec,完全能胜任上述工作,推荐!
但这个存在一个问题是,因为打乱了,最后分析结果的时候,数据重新排列困难,因为丢失了数据在数组中的位置参数。具体用法可以参见下面我的bp交通预测的例子。
因为我用的7.0版本,Neural Network Toolbox Version 5.0.2 (R2007a)
昨天,我去mathworks公司查看了一下nnet的新手册,上述问题得到了解决,里面视乎没有介绍dividverc这个函数了,但增加了新的函数来完成上述功能,并返回标号(手头没装新版本Neural Network Toolbox Version 6.0 (R2008a)),看guide大概是这个意思(有新版本的,可以试一下,这个函数是不是这个意思):
divideblock,divideind,divideint和dividerand
上述函数,用法和功能基本相同,只是打乱的方法不一样,分别是block方法抽取、按数组标号自定义抽取、交错索引抽取和随机抽。
下面以divideblock为例,讲解其基本用法:
[trainV,valV,testV,trainInd,valInd,testInd] =divideblock(allV,trainRatio,valRatio,testRatio)
[训练数据,变量数据,测试数据,训练数据矩阵的标号,变量数据标号,测试数据标号] =divideblock(所有数据,训练数据百分比,变量数据百分比,测试数据百分比)
其实dividevec和后面四个分类函数的区别在于,dividevec一般直接在Matlab代码中调用。
而后面四个函数是通过设置网络的divideFcn函数来实现,比如,net.divideFcn='divideblock',但不是说不可以在代码中像dividevec直接调用
如何查看和保存结果
训练好的权值、阈值的输出方法是:
输入到隐层权值:
w1=net.iw{1,1}
隐层阈值:
theta1=net.b{1}
隐层到输出层权值:
w2=net.lw{2,1};
输出层阈值:
theta2=net.b{2}
训练好的BP神经网络保存:
%保存
save file_name net_name%Matlab自动将网络保存为mat数据文件,下次使用时可以直接载入
%载入
load file_name
每次结果不一样问题
因为每次初始化网络时都是随机的,而且训练终止时的误差也不完全相同,结果训练后的权植和阀也不完全相同(大致是一样的),所以每次训练后的结果也略有不同。
找到比较好的结果后,用命令save filen_ame net_name保存网络,可使预测的结果不会变化,在需要的调用时用命令load filename载入。
关于如何找到比较好的结果,进行保存,可以设置误差,在循环中保存,具体使用可以参看bp交通预测优化后的例子
%bp神经网络进行交通预测的Matlab源代码
% BP 神经网络用于预测
% 使用平台 - Matlab7.0
% 数据为1986年到2000年的交通量 ,网络为3输入,1输出
% 15组数据,其中9组为正常训练数据,3组为变量数据,3组为测试数据
%by akjuan
%all rights preserved by www.4math.cn
%2008.11
clc
clear
%---------------------------------------------------
%原始数据
%---------------------------------------------------
year=1986:2000;%数据是从1986到2000年的
p=[493 372 445;372 445 176;445 176 235;176 235 378;235 378 429;...
378 429 561;429 561 651;561 651 467;651 467 527;467 527 668;...
527 668 841; 668 841 526;841 526 480;526 480 567;480 567 685]';%输入数据,共15组,每组3个输入
t=[176 235 378 429 561 651 467 527 668 841 526 480 567 685 507];%输出数据,共15组,每组1个输出
%---------------------------------------------------
%数据归一化处理
%mapminmax函数默认将数据归一化到[-1,1],调用形式如下
%[y,ps] =%mapminmax(x,ymin,ymax)
%x需归化的数据输入
%ymin,ymax为需归化到的范围,不填默认为归化到[-1,1]
%y归一化后的样本数据
%ps处理设置,ps主要在结果反归一化中需要调用,或者使用同样的settings归一化另外一组数据
%---------------------------------------------------
[normInput,ps] = mapminmax(p);
[normTarget,ts] = mapminmax(t);
%---------------------------------------------------
%数据乱序,及分类处理
%将输入的15组数据的20%,即3组,用来作为测试数据;
% 样本的20%,即3组,用来作为变化数据;
%另外9组用来正常输入,用来训练;
%dividevec()用来重新随机抽取上述三种分类的数据,原来的顺序被打乱
%函数调用的语法
%[trainV,valV,testV] = dividevec(p,t,valPercent,testPercent)
%输入p为输入数据,t为输出数据
%valPercent为训练用的变化数据在总输入中的百分比
%testPercent为训练用的测试数据在总输入中的百分比
%输出trainV,valV,testV分别为按乱序及相应百分比,抽取得到的数据
%另外,打乱后的数据,p和t都是对应的,请放心使用
%---------------------------------------------------
testPercent = 0.20; % Adjust as desired
validatePercent = 0.20; % Adust as desired
[trainSamples,validateSamples,testSamples] = dividevec(normInput,normTarget,validatePercent,testPercent);
%---------------------------------------------------
% 设置网络参数
%---------------------------------------------------
NodeNum1 = 20; % 隐层第一层节点数
NodeNum2 = 40; % 隐层第二层节点数
TypeNum = 1; % 输出维数
TF1 = 'tansig';TF2 = 'tansig'; TF3 = 'tansig';%各层传输函数,TF3为输出层传输函数
%如果训练结果不理想,可以尝试更改传输函数,以下这些是各类传输函数
%TF1 = 'tansig';TF2 = 'logsig';
%TF1 = 'logsig';TF2 = 'purelin';
%TF1 = 'tansig';TF2 = 'tansig';
%TF1 = 'logsig';TF2 = 'logsig';
%TF1 = 'purelin';TF2 = 'purelin';
%注意创建BP网络函数newff()的参数调用,在新版本(7.6)中已改变
net=newff(minmax(normInput),[NodeNum1,NodeNum2,TypeNum],{TF1 TF2 TF3},'traingdx');%创建四层BP网络
%---------------------------------------------------
% 设置训练参数
%---------------------------------------------------
net.trainParam.epochs=10000;%训练次数设置
net.trainParam.goal=1e-6;%训练目标设置
net.trainParam.lr=0.01;%学习率设置,应设置为较少值,太大虽然会在开始加快收敛速度,但临近最佳点时,会产生动荡,而致使无法收敛
%---------------------------------------------------
% 指定训练函数
%---------------------------------------------------
% net.trainFcn = 'traingd'; % 梯度下降算法
% net.trainFcn = 'traingdm'; % 动量梯度下降算法
%
% net.trainFcn = 'traingda'; % 变学习率梯度下降算法
% net.trainFcn = 'traingdx'; % 变学习率动量梯度下降算法
%
% (大型网络的首选算法)
% net.trainFcn = 'trainrp'; % RPROP(弹性BP)算法,内存需求最小
%
% (共轭梯度算法)
% net.trainFcn = 'traincgf'; % Fletcher-Reeves修正算法
% net.trainFcn = 'traincgp'; % Polak-Ribiere修正算法,内存需求比Fletcher-Reeves修正算法略大
% net.trainFcn = 'traincgb'; % Powell-Beal复位算法,内存需求比Polak-Ribiere修正算法略大
%
% (大型网络的首选算法)
%net.trainFcn = 'trainscg'; % Scaled Conjugate Gradient算法,内存需求与Fletcher-Reeves修正算法相同,计算量比上面三种算法都小很多
% net.trainFcn = 'trainbfg'; % Quasi-Newton Algorithms - BFGS Algorithm,计算量和内存需求均比共轭梯度算法大,但收敛比较快
% net.trainFcn = 'trainoss'; % One Step Secant Algorithm,计算量和内存需求均比BFGS算法小,比共轭梯度算法略大
%
% (中型网络的首选算法)
%net.trainFcn = 'trainlm'; % Levenberg-Marquardt算法,内存需求最大,收敛速度最快
% net.trainFcn = 'trainbr'; % 贝叶斯正则化算法
%
% 有代表性的五种算法为:'traingdx','trainrp','trainscg','trainoss', 'trainlm'
net.trainfcn='traingdm';
[net,tr] = train(net,trainSamples.P,trainSamples.T,[],[],validateSamples,testSamples);
%---------------------------------------------------
% 训练完成后,就可以调用sim()函数,进行仿真了
%---------------------------------------------------
[normTrainOutput,Pf,Af,E,trainPerf] = sim(net,trainSamples.P,[],[],trainSamples.T);%正常输入的9组p数据,BP得到的结果t
[normValidateOutput,Pf,Af,E,validatePerf] = sim(net,validateSamples.P,[],[],validateSamples.T);%用作变量3的数据p,BP得到的结果t
[normTestOutput,Pf,Af,E,testPerf] = sim(net,testSamples.P,[],[],testSamples.T);%用作测试的3组数据p,BP得到的结果t
%---------------------------------------------------
% 仿真后结果数据反归一化,如果需要预测,只需将预测的数据P填入
% 将获得预测结果t
%---------------------------------------------------
trainOutput = mapminmax('reverse',normTrainOutput,ts);%正常输入的9组p数据,BP得到的归一化后的结果t
trainInsect = mapminmax('reverse',trainSamples.T,ts);%正常输入的9组数据t
validateOutput = mapminmax('reverse',normValidateOutput,ts);%用作变量3的数据p,BP得到的归一化的结果t
validateInsect = mapminmax('reverse',validateSamples.T,ts);%用作变量3的数据t
testOutput = mapminmax('reverse',normTestOutput,ts);%用作变量3组数据p,BP得到的归一化的结果t
testInsect = mapminmax('reverse',testSamples.T,ts);%用作变量3组数据t
%---------------------------------------------------
% 数据分析和绘图
%---------------------------------------------------
figure
plot(1:12,[trainOutput validateOutput],'b-',1:12,[trainInsect validateInsect],'g--',13:15,testOutput,'m*',13:15,testInsect,'ro');
title('o为真实值,*为预测值')
xlabel('年份');
ylabel('交通量(辆次/昼夜)');
但通过程序运行后,可以看出,预测效果并不理想,如何得到理想的预测训练结果,下面是基本思路及matlab的实现:
1、设置一个误差项,为测试数据的网络仿真结果和实际结果偏差,并设置一个自己能接受的精度值
2、每次训练网络后,将这个误差和设置值比较,也可通过测试获得网络能给出的最高预测精度
3、得到满意训练网络后,保存BP结果,以便下次调用
下面这个程序是在第四节程序基础上优化而来,可以运行前面的程序和这个程序,比较两者的差别,可以通过修改eps来控制预测的误差!
%bp神经网络进行交通预测的Matlab源代码
% BP 神经网络用于预测
% 使用平台 - Matlab7.0
% 数据为1986年到2000年的交通量 ,网络为3输入,1输出
% 15组数据,其中9组为正常训练数据,3组为变量数据,3组为测试数据
%by akjuan
%all rights preserved by www.matlabsky.cn
%2008.11
clc
clear
All_error=[];%所有误差存储
%---------------------------------------------------
%原始数据
%---------------------------------------------------
year=1986:2000;%数据是从1986到2000年的
p=[493 372 445;372 445 176;445 176 235;176 235 378;235 378 429;...
378 429 561;429 561 651;561 651 467;651 467 527;467 527 668;...
527 668 841; 668 841 526;841 526 480;526 480 567;480 567 685]';%输入数据,共15组,每组3个输入
t=[176 235 378 429 561 651 467 527 668 841 526 480 567 685 507];%输出数据,共15组,每组1个输出
%---------------------------------------------------
%数据归一化处理
%mapminmax函数默认将数据归一化到[-1,1],调用形式如下
%[y,ps] =%mapminmax(x,ymin,ymax)
%x需归化的数据输入
%ymin,ymax为需归化到的范围,不填默认为归化到[-1,1]
%y归一化后的样本数据
%ps处理设置,ps主要在结果反归一化中需要调用,或者使用同样的settings归一化另外一组数据
%---------------------------------------------------
[normInput,ps] = mapminmax(p);
[normTarget,ts] = mapminmax(t);
%---------------------------------------------------
%数据乱序,及分类处理
%将输入的15组数据的20%,即3组,用来作为测试数据;
% 样本的20%,即3组,用来作为变化数据;
%另外9组用来正常输入,用来训练;
%dividevec()用来重新随机抽取上述三种分类的数据,原来的顺序被打乱
%函数调用的语法
%[trainV,valV,testV] = dividevec(p,t,valPercent,testPercent)
%输入p为输入数据,t为输出数据
%valPercent为训练用的变化数据在总输入中的百分比
%testPercent为训练用的测试数据在总输入中的百分比
%输出trainV,valV,testV分别为按乱序及相应百分比,抽取得到的数据
%另外,打乱后的数据,p和t都是对应的,请放心使用
%---------------------------------------------------
testPercent = 0.20; % Adjust as desired
validatePercent = 0.20; % Adust as desired
[trainSamples,validateSamples,testSamples] = dividevec(normInput,normTarget,validatePercent,testPercent);
for j=1:200
%---------------------------------------------------
% 设置网络参数
%---------------------------------------------------
NodeNum1 = 20; % 隐层第一层节点数
NodeNum2=40; % 隐层第二层节点数
TypeNum = 1; % 输出维数
TF1 = 'tansig';TF2 = 'tansig'; TF3 = 'tansig';%各层传输函数,TF3为输出层传输函数
%如果训练结果不理想,可以尝试更改传输函数,以下这些是各类传输函数
%TF1 = 'tansig';TF2 = 'logsig';
%TF1 = 'logsig';TF2 = 'purelin';
%TF1 = 'tansig';TF2 = 'tansig';
%TF1 = 'logsig';TF2 = 'logsig';
%TF1 = 'purelin';TF2 = 'purelin';
net=newff(minmax(normInput),[NodeNum1,NodeNum2,TypeNum],{TF1 TF2 TF3},'traingdx');%网络创建
%---------------------------------------------------
% 设置训练参数
%---------------------------------------------------
net.trainParam.epochs=10000;%训练次数设置
net.trainParam.goal=1e-6;%训练目标设置
net.trainParam.lr=0.01;%学习率设置,应设置为较少值,太大虽然会在开始加快收敛速度,但临近最佳点时,会产生动荡,而致使无法收敛
%---------------------------------------------------
% 指定训练参数
%---------------------------------------------------
% net.trainFcn = 'traingd'; % 梯度下降算法
% net.trainFcn = 'traingdm'; % 动量梯度下降算法
%
% net.trainFcn = 'traingda'; % 变学习率梯度下降算法
% net.trainFcn = 'traingdx'; % 变学习率动量梯度下降算法
%
% (大型网络的首选算法)
% net.trainFcn = 'trainrp'; % RPROP(弹性BP)算法,内存需求最小
%
% (共轭梯度算法)
% net.trainFcn = 'traincgf'; % Fletcher-Reeves修正算法
% net.trainFcn = 'traincgp'; % Polak-Ribiere修正算法,内存需求比Fletcher-Reeves修正算法略大
% net.trainFcn = 'traincgb'; % Powell-Beal复位算法,内存需求比Polak-Ribiere修正算法略大
%
% (大型网络的首选算法)
%net.trainFcn = 'trainscg'; % Scaled Conjugate Gradient算法,内存需求与Fletcher-Reeves修正算法相同,计算量比上面三种算法都小很多
% net.trainFcn = 'trainbfg'; % Quasi-Newton Algorithms - BFGS Algorithm,计算量和内存需求均比共轭梯度算法大,但收敛比较快
% net.trainFcn = 'trainoss'; % One Step Secant Algorithm,计算量和内存需求均比BFGS算法小,比共轭梯度算法略大
%
% (中型网络的首选算法)
%net.trainFcn = 'trainlm'; % Levenberg-Marquardt算法,内存需求最大,收敛速度最快
% net.trainFcn = 'trainbr'; % 贝叶斯正则化算法
%
% 有代表性的五种算法为:'traingdx','trainrp','trainscg','trainoss', 'trainlm'
net.trainfcn='traingdm';
[net,tr] = train(net,trainSamples.P,trainSamples.T,[],[],validateSamples,testSamples);
%---------------------------------------------------
% 训练完成后,就可以调用sim()函数,进行仿真了
%---------------------------------------------------
[normTrainOutput,Pf,Af,E,trainPerf] = sim(net,trainSamples.P,[],[],trainSamples.T);%正常输入的9组p数据,BP得到的结果t
[normValidateOutput,Pf,Af,E,validatePerf] = sim(net,validateSamples.P,[],[],validateSamples.T);%用作变量3的数据p,BP得到的结果t
[normTestOutput,Pf,Af,E,testPerf] = sim(net,testSamples.P,[],[],testSamples.T);%用作测试的3组数据p,BP得到的结果t
%---------------------------------------------------
% 仿真后结果数据反归一化,如果需要预测,只需将预测的数据P填入
% 将获得预测结果t
%---------------------------------------------------
trainOutput = mapminmax('reverse',normTrainOutput,ts);%正常输入的9组p数据,BP得到的归一化后的结果t
trainInsect = mapminmax('reverse',trainSamples.T,ts);%正常输入的9组数据t
validateOutput = mapminmax('reverse',normValidateOutput,ts);%用作变量3的数据p,BP得到的归一化的结果t
validateInsect = mapminmax('reverse',validateSamples.T,ts);%用作变量3的数据t
testOutput = mapminmax('reverse',normTestOutput,ts);%用作变量3组数据p,BP得到的归一化的结果t
testInsect = mapminmax('reverse',testSamples.T,ts);%用作变量3组数据t
%绝对误差计算
absTrainError = trainOutput-trainInsect;
absTestError = testOutput-testInsect;
error_sum=sqrt(absTestError(1).^2+absTestError(2).^2+absTestError(3).^2);
All_error=[All_error error_sum];
eps=90;%其为3组测试数据的标准差,或者每个数据偏差在一定范围内而判别
if ((abs(absTestError(1))<=30 )&(abs(absTestError(2))<=30)&(abs(absTestError(3))<=30)|(error_sum<=eps))
save mynetdata net
break
end
j
end
j
Min_error_sqrt=min(All_error)
testOutput
testInsect
%---------------------------------------------------
% 数据分析和绘图
%---------------------------------------------------
figure
plot(1:12,[trainOutput validateOutput],'b-',1:12,[trainInsect validateInsect],'g--',13:15,testOutput,'m*',13:15,testInsect,'ro');
title('o为真实值,*为预测值')
xlabel('年份');
ylabel('交通量(辆次/昼夜)');
figure
xx=1:length(All_error);
plot(xx,All_error)
title('误差变化图')
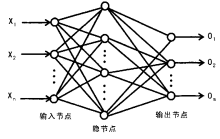
误差反向传播(Error Back Propagation, BP)算法
1、BP算法的基本思想是,学习过程由信号的正向传播与误差的反向传播两个过程组成。 1)正向传播:输入样本->输入层->各隐层(处理)->输出层 注1:若输出层实际输出与期望输出(教师信号)不符,则转入2)(误差反向传播过程) 2)误差反向传播:输出误差(某种形式)->隐层(逐层)->输入层 其主要目的是通过将输出误差反传,将误差分摊给各层所有单元,从而获得各层单元的误差信号,进而修正各单元的权值(其过程,是一个权值调整的过程)。 注2:权值调整的过程,也就是网络的学习训练过程(学习也就是这么的由来,权值调整)。 2、BP算法实现步骤( 软件 ): 1)初始化 2)输入训练样本对,计算各层输出 3)计算网络输出误差 4)计算各层误差信号 5)调整各层权值 6)检查网络总误差是否达到精度要求 满足,则训练结束;不满足,则返回步骤2) 3、多层感知器(基于BP算法)的主要能力: 1)非线性映射:足够多样本->学习训练 能学习和存储大量输入-输出模式映射关系。只要能提供足够多的样本模式对供BP网络进行学习训练,它便能完成由n维输入空间到m维输出空间的非线性映射。 2)泛化:输入新样本(训练时未有)->完成正确的输入、输出映射 3)容错:个别样本误差不能左右对权矩阵的调整 4、标准BP算法的缺陷: 1)易形成局部极小(属贪婪算法,局部最优)而得不到全局最优; 2)训练次数多使得学习效率低下,收敛速度慢(需做大量运算); 3)隐节点的选取缺乏理论支持; 4)训练时学习新样本有遗忘旧样本趋势。 注3:改进算法—增加动量项、自适应调整学习速率(这个似乎不错)及引入陡度因子 BP算法基本介绍 含有隐层的多层前馈网络能大大提高神经网络的分类能力,但长期以来没有提出解决权值调整问题的游戏算法。1986年,Rumelhart和McCelland领导的科学家小组在《Parallel Distributed Processing》一书中,对具有非线性连续转移函数的多层前馈网络的误差反向传播(Error Back Proragation,简称BP)算法进行了详尽的分析,实现了Minsky关于多层网络的设想。由于多层前馈网络的训练经常采用误差 反向传播算法 ,人们也常把将多层前馈网络直接称为BP网络。 BP算法的基本思想是,学习过程由信号的正向传播与误差的反向传播两个过程组成。正向传播时,输入样本从输入层传人,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出(教师信号)不符,则转入误差的反向传播阶段。误差反传是将输出误差以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。这种信号正向传播与误差反向传播的各层权值调整过程,是周而复始地进行的。权值不断调整的过程,也就是网络的学习训练过程。此过程一直进行到网络输出的误差减少到可接受的程度,或进行到预先设定的学习次数为止。 5,BP算法的网络结构示意图