【深度学习】图片分类CNN模板
构建一个字母ABC的手写识别网络,
要求给出算法误差收敛曲线,所给程序要有图片导入接口。
 其中A,B,C都代表label,三个文件夹存在具体的图片。只要是这样类型的,直接套下面模板。
其中A,B,C都代表label,三个文件夹存在具体的图片。只要是这样类型的,直接套下面模板。

import os
import cv2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
import tqdm
from tensorflow import keras
from keras import Input, Model, Sequential
from tensorflow.keras.regularizers import l2
from keras.layers import Dense, Flatten, InputLayer, Reshape, BatchNormalization, Dropout, Conv2D, MaxPooling2D
from tensorflow.keras.utils import plot_model
%matplotlib inlinedata_dir = './data'# Dict of labels
categories = {
'A': 0,
'B': 1,
'C': 2
}def load_images(images_folder, img_size = (128,128), scale=False):
# Store paths to images
image_path = []
for dirname, _, filenames in os.walk(images_folder):
for filename in filenames:
image_path.append(os.path.join(dirname, filename))
print("There are {} images in {}".format(len(image_path), images_folder))
# Load images and associated labels
images = []
labels = []
for path in tqdm.tqdm(image_path):
img = cv2.imread(path)
img = cv2.resize(img, img_size) # Resize the images
img = np.array(img)
images.append(img)
labels.append(categories[path.split('/')[-2]]) # last folder before the image name is the category
images = np.array(images)
images = images.astype(np.int64)
if scale:
images = images/255 # scale
return image_path, images, np.asarray(labels)img_size = (128,128)
image_path, images, labels = load_images(data_dir, img_size=img_size)
# Resize
# images = np.array(images).reshape(-1,128,128,1)
images.shapeThere are 600 images in ./data
100%|██████████| 600/600 [00:03<00:00, 183.15it/s]
(600, 128, 128, 3)# 查看图片
plt.figure(figsize=(10,10))
random_inds = np.random.choice(len(image_path),36)
for i in range(36):
plt.subplot(6,6,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
image_ind = random_inds[i]
plt.imshow(np.squeeze(images[image_ind]), cmap=plt.cm.binary)
label = list(categories.keys())[list(categories.values()).index(labels[image_ind])]
plt.title(label)
labels_df = pd.DataFrame(labels)
labels_df.value_counts()2 201
0 201
1 198
dtype: int64dataset=[]
dataname=[]
count=0
for name in tqdm(os.listdir(data_dir)):
path=os.path.join(data_dir,name)
for im in os.listdir(path):
image=cv2.imread(os.path.join(path,im))
image2=np.resize(image,(50,50,3))
dataset+=[image2]
dataname+=[count]
count=count+1100%|██████████| 3/3 [00:03<00:00, 1.06s/it]data=np.array(dataset)
dataname=np.array(dataname)data[0].shape(50, 50, 3)print(pd.Series(dataname).value_counts())1 202
2 201
0 198
dtype: int64len(categories)3from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D, BatchNormalization
def build_cnn_model():
cnn_model=tf.keras.Sequential([
Conv2D(filters=32,kernel_size=(3,3),activation='relu',input_shape=images.shape[1:]),
MaxPooling2D(2,2),
BatchNormalization(),
Dropout(0.4),
Conv2D(filters=64,kernel_size=(3,3),activation='relu', padding='same'),
Conv2D(filters=64,kernel_size=(3,3),activation='relu', padding='same'),
MaxPooling2D((2,2)),
BatchNormalization(),
Dropout(0.4),
Conv2D(filters=128,kernel_size=(3,3),activation='relu', padding='same'),
Conv2D(filters=128,kernel_size=(3,3),activation='relu', padding='same'),
MaxPooling2D(2,2),
BatchNormalization(),
Dropout(0.4),
Conv2D(filters=256,kernel_size=(3,3),activation='relu', padding='same'),
Conv2D(filters=256,kernel_size=(3,3),activation='relu', padding='same'),
MaxPooling2D(2,2),
BatchNormalization(),
Dropout(0.4),
Conv2D(filters=128,kernel_size=(3,3),activation='relu', padding='same'),
Conv2D(filters=128,kernel_size=(3,3),activation='relu', padding='same'),
MaxPooling2D(2,2),
BatchNormalization(),
Dropout(0.4),
Conv2D(filters=64,kernel_size=(3,3),activation='relu', padding='same'),
Conv2D(filters=64,kernel_size=(3,3),activation='relu', padding='same'),
MaxPooling2D((2,2)),
BatchNormalization(),
Dropout(0.4),
Flatten(),
Dense(units=len(categories),activation='softmax')
])
return cnn_model
model = build_cnn_model()
# Initialize the model by passing some data through
model.predict(images[[0]])
# Print the summary of the layers in the model.
print(model.summary())Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_6 (Conv2D) (None, 126, 126, 32) 896
max_pooling2d_6 (MaxPooling (None, 63, 63, 32) 0
2D)
batch_normalization (BatchN (None, 63, 63, 32) 128
ormalization)
dropout (Dropout) (None, 63, 63, 32) 0
conv2d_7 (Conv2D) (None, 63, 63, 64) 18496
conv2d_8 (Conv2D) (None, 63, 63, 64) 36928
max_pooling2d_7 (MaxPooling (None, 31, 31, 64) 0
2D)
batch_normalization_1 (Batc (None, 31, 31, 64) 256
hNormalization)
dropout_1 (Dropout) (None, 31, 31, 64) 0
conv2d_9 (Conv2D) (None, 31, 31, 128) 73856
conv2d_10 (Conv2D) (None, 31, 31, 128) 147584
max_pooling2d_8 (MaxPooling (None, 15, 15, 128) 0
2D)
batch_normalization_2 (Batc (None, 15, 15, 128) 512
hNormalization)
dropout_2 (Dropout) (None, 15, 15, 128) 0
conv2d_11 (Conv2D) (None, 15, 15, 256) 295168
conv2d_12 (Conv2D) (None, 15, 15, 256) 590080
max_pooling2d_9 (MaxPooling (None, 7, 7, 256) 0
2D)
batch_normalization_3 (Batc (None, 7, 7, 256) 1024
hNormalization)
dropout_3 (Dropout) (None, 7, 7, 256) 0
conv2d_13 (Conv2D) (None, 7, 7, 128) 295040
conv2d_14 (Conv2D) (None, 7, 7, 128) 147584
max_pooling2d_10 (MaxPoolin (None, 3, 3, 128) 0
g2D)
batch_normalization_4 (Batc (None, 3, 3, 128) 512
hNormalization)
dropout_4 (Dropout) (None, 3, 3, 128) 0
conv2d_15 (Conv2D) (None, 3, 3, 64) 73792
conv2d_16 (Conv2D) (None, 3, 3, 64) 36928
max_pooling2d_11 (MaxPoolin (None, 1, 1, 64) 0
g2D)
batch_normalization_5 (Batc (None, 1, 1, 64) 256
hNormalization)
dropout_5 (Dropout) (None, 1, 1, 64) 0
flatten_1 (Flatten) (None, 64) 0
dense_6 (Dense) (None, 3) 195
=================================================================
Total params: 1,719,235
Trainable params: 1,717,891
Non-trainable params: 1,344
_________________________________________________________________
Nonetf.keras.utils.plot_model(model, show_shapes=True)
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelEncoder
from sklearn.utils import shuffle
le = LabelEncoder()
labels = le.fit_transform(labels)
labels = to_categorical(labels)
labels[:10]array([[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.]], dtype=float32)model.compile(optimizer = "adam", loss = "binary_crossentropy", metrics = ["accuracy"])checkpoint_filepath = '/checkpoint.hdf5'
model_checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath,
save_weights_only=True,
monitor='val_accuracy',
mode='max',
save_best_only=True,
save_freq=500)from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
monitor='val_accuracy',
patience=10,
min_delta=0.001,
mode='max',
restore_best_weights=True
)datagen = ImageDataGenerator(horizontal_flip=True,vertical_flip=True,rotation_range=20,zoom_range=0.2,
width_shift_range=0.2,height_shift_range=0.2,shear_range=0.1,fill_mode="nearest")from tensorflow.keras.callbacks import ReduceLROnPlateau
reducelr = ReduceLROnPlateau(monitor = "val_accuracy",factor = 0.3, patience = 3,
min_delta = 0.001,mode = 'auto',verbose=1)from sklearn.model_selection import train_test_split
# Train, validation and test split
X_train, X_test, y_train, y_test = train_test_split(images, labels, test_size=0.10, random_state=7)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.20, random_state=1)print("*-*-*-*-*-*")
print("Train")
print(X_train.shape)
print(y_train.shape)
print("*-*-*-*-*-*")
print("Validation")
print(X_val.shape)
print(y_val.shape)
print("*-*-*-*-*-*")
print("Test")
print(X_test.shape)
print(y_test.shape)*-*-*-*-*-*
Train
(432, 128, 128, 3)
(432, 3)
*-*-*-*-*-*
Validation
(108, 128, 128, 3)
(108, 3)
*-*-*-*-*-*
Test
(60, 128, 128, 3)
(60, 3)history = model.fit(X_train, y_train,
batch_size = 32,
epochs = 100,
verbose = 1,
validation_data = (X_val, y_val),
callbacks=[model_checkpoint_callback, early_stopping, reducelr])Epoch 1/1000
14/14 [==============================] - 8s 238ms/step - loss: 0.8036 - accuracy: 0.3588 - val_loss: 6.2921 - val_accuracy: 0.2963 - lr: 0.0010
Epoch 2/1000
14/14 [==============================] - 1s 95ms/step - loss: 0.8162 - accuracy: 0.3796 - val_loss: 5.2361 - val_accuracy: 0.2963 - lr: 0.0010
Epoch 3/1000
14/14 [==============================] - 1s 97ms/step - loss: 0.7190 - accuracy: 0.4537 - val_loss: 1.3893 - val_accuracy: 0.3333 - lr: 0.0010
Epoch 4/1000
14/14 [==============================] - 1s 97ms/step - loss: 0.6875 - accuracy: 0.4792 - val_loss: 0.7386 - val_accuracy: 0.3519 - lr: 0.0010
Epoch 5/1000
14/14 [==============================] - 1s 100ms/step - loss: 0.6144 - accuracy: 0.5949 - val_loss: 0.7014 - val_accuracy: 0.4259 - lr: 0.0010
Epoch 6/1000
14/14 [==============================] - 1s 97ms/step - loss: 0.5156 - accuracy: 0.7060 - val_loss: 0.7592 - val_accuracy: 0.4537 - lr: 0.0010
Epoch 7/1000
14/14 [==============================] - 1s 96ms/step - loss: 0.4904 - accuracy: 0.7384 - val_loss: 0.7034 - val_accuracy: 0.5370 - lr: 0.0010
Epoch 8/1000
14/14 [==============================] - 1s 97ms/step - loss: 0.3854 - accuracy: 0.7940 - val_loss: 0.6092 - val_accuracy: 0.5556 - lr: 0.0010
Epoch 9/1000
14/14 [==============================] - 1s 97ms/step - loss: 0.3313 - accuracy: 0.8241 - val_loss: 0.5192 - val_accuracy: 0.6389 - lr: 0.0010
Epoch 10/1000
14/14 [==============================] - 1s 93ms/step - loss: 0.2873 - accuracy: 0.8519 - val_loss: 0.5089 - val_accuracy: 0.6111 - lr: 0.0010
Epoch 11/1000
14/14 [==============================] - 1s 96ms/step - loss: 0.2346 - accuracy: 0.8981 - val_loss: 0.4359 - val_accuracy: 0.6852 - lr: 0.0010
Epoch 12/1000
14/14 [==============================] - 1s 94ms/step - loss: 0.2238 - accuracy: 0.8819 - val_loss: 0.4404 - val_accuracy: 0.6481 - lr: 0.0010
Epoch 13/1000
14/14 [==============================] - 1s 97ms/step - loss: 0.1954 - accuracy: 0.8912 - val_loss: 0.4215 - val_accuracy: 0.7500 - lr: 0.0010
Epoch 14/1000
14/14 [==============================] - 1s 100ms/step - loss: 0.1792 - accuracy: 0.9051 - val_loss: 0.1971 - val_accuracy: 0.9074 - lr: 0.0010
Epoch 15/1000
14/14 [==============================] - 1s 96ms/step - loss: 0.1608 - accuracy: 0.9144 - val_loss: 0.2836 - val_accuracy: 0.8056 - lr: 0.0010
Epoch 16/1000
14/14 [==============================] - 1s 95ms/step - loss: 0.1447 - accuracy: 0.9398 - val_loss: 0.2867 - val_accuracy: 0.7500 - lr: 0.0010
Epoch 17/1000
14/14 [==============================] - ETA: 0s - loss: 0.1215 - accuracy: 0.9375
Epoch 00017: ReduceLROnPlateau reducing learning rate to 0.0003000000142492354.
14/14 [==============================] - 1s 95ms/step - loss: 0.1215 - accuracy: 0.9375 - val_loss: 0.1474 - val_accuracy: 0.9074 - lr: 0.0010
Epoch 18/1000
14/14 [==============================] - 1s 97ms/step - loss: 0.1023 - accuracy: 0.9537 - val_loss: 0.1186 - val_accuracy: 0.9352 - lr: 3.0000e-04
Epoch 19/1000
14/14 [==============================] - 1s 101ms/step - loss: 0.0992 - accuracy: 0.9606 - val_loss: 0.1074 - val_accuracy: 0.9444 - lr: 3.0000e-04
Epoch 20/1000
14/14 [==============================] - 1s 94ms/step - loss: 0.0837 - accuracy: 0.9676 - val_loss: 0.0917 - val_accuracy: 0.9444 - lr: 3.0000e-04
Epoch 21/1000
14/14 [==============================] - 1s 98ms/step - loss: 0.0788 - accuracy: 0.9699 - val_loss: 0.0877 - val_accuracy: 0.9444 - lr: 3.0000e-04
Epoch 22/1000
14/14 [==============================] - ETA: 0s - loss: 0.0809 - accuracy: 0.9722
Epoch 00022: ReduceLROnPlateau reducing learning rate to 9.000000427477062e-05.
14/14 [==============================] - 1s 95ms/step - loss: 0.0809 - accuracy: 0.9722 - val_loss: 0.0897 - val_accuracy: 0.9444 - lr: 3.0000e-04
Epoch 23/1000
14/14 [==============================] - 1s 95ms/step - loss: 0.0677 - accuracy: 0.9792 - val_loss: 0.0834 - val_accuracy: 0.9537 - lr: 9.0000e-05
Epoch 24/1000
14/14 [==============================] - 1s 93ms/step - loss: 0.0741 - accuracy: 0.9722 - val_loss: 0.0771 - val_accuracy: 0.9537 - lr: 9.0000e-05
Epoch 25/1000
14/14 [==============================] - 1s 94ms/step - loss: 0.0672 - accuracy: 0.9815 - val_loss: 0.0733 - val_accuracy: 0.9537 - lr: 9.0000e-05
Epoch 26/1000
14/14 [==============================] - ETA: 0s - loss: 0.0595 - accuracy: 0.9838
Epoch 00026: ReduceLROnPlateau reducing learning rate to 2.700000040931627e-05.
14/14 [==============================] - 1s 95ms/step - loss: 0.0595 - accuracy: 0.9838 - val_loss: 0.0694 - val_accuracy: 0.9537 - lr: 9.0000e-05
Epoch 27/1000
14/14 [==============================] - 1s 94ms/step - loss: 0.0631 - accuracy: 0.9838 - val_loss: 0.0699 - val_accuracy: 0.9537 - lr: 2.7000e-05
Epoch 28/1000
14/14 [==============================] - 1s 97ms/step - loss: 0.0591 - accuracy: 0.9861 - val_loss: 0.0705 - val_accuracy: 0.9537 - lr: 2.7000e-05
Epoch 29/1000
14/14 [==============================] - ETA: 0s - loss: 0.0635 - accuracy: 0.9838
Epoch 00029: ReduceLROnPlateau reducing learning rate to 8.100000013655517e-06.
14/14 [==============================] - 1s 95ms/step - loss: 0.0635 - accuracy: 0.9838 - val_loss: 0.0697 - val_accuracy: 0.9444 - lr: 2.7000e-05
Epoch 30/1000
14/14 [==============================] - 1s 95ms/step - loss: 0.0643 - accuracy: 0.9792 - val_loss: 0.0687 - val_accuracy: 0.9444 - lr: 8.1000e-06
Epoch 31/1000
14/14 [==============================] - 1s 100ms/step - loss: 0.0768 - accuracy: 0.9745 - val_loss: 0.0665 - val_accuracy: 0.9537 - lr: 8.1000e-06
Epoch 32/1000
14/14 [==============================] - ETA: 0s - loss: 0.0645 - accuracy: 0.9861
Epoch 00032: ReduceLROnPlateau reducing learning rate to 2.429999949526973e-06.
14/14 [==============================] - 1s 95ms/step - loss: 0.0645 - accuracy: 0.9861 - val_loss: 0.0656 - val_accuracy: 0.9537 - lr: 8.1000e-06
Epoch 33/1000
14/14 [==============================] - 1s 97ms/step - loss: 0.0635 - accuracy: 0.9792 - val_loss: 0.0645 - val_accuracy: 0.9630 - lr: 2.4300e-06
Epoch 34/1000
14/14 [==============================] - 1s 95ms/step - loss: 0.0606 - accuracy: 0.9838 - val_loss: 0.0636 - val_accuracy: 0.9630 - lr: 2.4300e-06
Epoch 35/1000
14/14 [==============================] - 1s 95ms/step - loss: 0.0620 - accuracy: 0.9907 - val_loss: 0.0628 - val_accuracy: 0.9630 - lr: 2.4300e-06
Epoch 36/1000
9/14 [==================>...........] - ETA: 0s - loss: 0.0729 - accuracy: 0.9826WARNING:tensorflow:Can save best model only with val_accuracy available, skipping.
14/14 [==============================] - ETA: 0s - loss: 0.0682 - accuracy: 0.9861
Epoch 00036: ReduceLROnPlateau reducing learning rate to 7.289999985005124e-07.
14/14 [==============================] - 1s 95ms/step - loss: 0.0682 - accuracy: 0.9861 - val_loss: 0.0622 - val_accuracy: 0.9630 - lr: 2.4300e-06
Epoch 37/1000
14/14 [==============================] - 1s 96ms/step - loss: 0.0573 - accuracy: 0.9907 - val_loss: 0.0613 - val_accuracy: 0.9630 - lr: 7.2900e-07
Epoch 38/1000
14/14 [==============================] - 1s 97ms/step - loss: 0.0575 - accuracy: 0.9931 - val_loss: 0.0607 - val_accuracy: 0.9722 - lr: 7.2900e-07
Epoch 39/1000
14/14 [==============================] - 1s 94ms/step - loss: 0.0622 - accuracy: 0.9769 - val_loss: 0.0600 - val_accuracy: 0.9722 - lr: 7.2900e-07
Epoch 40/1000
14/14 [==============================] - 1s 96ms/step - loss: 0.0660 - accuracy: 0.9838 - val_loss: 0.0594 - val_accuracy: 0.9722 - lr: 7.2900e-07
Epoch 41/1000
14/14 [==============================] - ETA: 0s - loss: 0.0614 - accuracy: 0.9884
Epoch 00041: ReduceLROnPlateau reducing learning rate to 2.1870000637136398e-07.
14/14 [==============================] - 1s 95ms/step - loss: 0.0614 - accuracy: 0.9884 - val_loss: 0.0591 - val_accuracy: 0.9722 - lr: 7.2900e-07
Epoch 42/1000
14/14 [==============================] - 1s 94ms/step - loss: 0.0605 - accuracy: 0.9792 - val_loss: 0.0583 - val_accuracy: 0.9722 - lr: 2.1870e-07
Epoch 43/1000
14/14 [==============================] - 1s 99ms/step - loss: 0.0529 - accuracy: 0.9954 - val_loss: 0.0582 - val_accuracy: 0.9722 - lr: 2.1870e-07
Epoch 44/1000
14/14 [==============================] - ETA: 0s - loss: 0.0500 - accuracy: 0.9884
Epoch 00044: ReduceLROnPlateau reducing learning rate to 6.561000276406048e-08.
14/14 [==============================] - 1s 95ms/step - loss: 0.0500 - accuracy: 0.9884 - val_loss: 0.0580 - val_accuracy: 0.9722 - lr: 2.1870e-07
Epoch 45/1000
14/14 [==============================] - 1s 94ms/step - loss: 0.0613 - accuracy: 0.9861 - val_loss: 0.0581 - val_accuracy: 0.9722 - lr: 6.5610e-08
Epoch 46/1000
14/14 [==============================] - 1s 94ms/step - loss: 0.0672 - accuracy: 0.9861 - val_loss: 0.0572 - val_accuracy: 0.9722 - lr: 6.5610e-08
Epoch 47/1000
14/14 [==============================] - ETA: 0s - loss: 0.0511 - accuracy: 0.9931
Epoch 00047: ReduceLROnPlateau reducing learning rate to 1.9683000829218145e-08.
14/14 [==============================] - 1s 96ms/step - loss: 0.0511 - accuracy: 0.9931 - val_loss: 0.0574 - val_accuracy: 0.9722 - lr: 6.5610e-08
Epoch 48/1000
14/14 [==============================] - 1s 99ms/step - loss: 0.0622 - accuracy: 0.9861 - val_loss: 0.0570 - val_accuracy: 0.9722 - lr: 1.9683e-08plt.plot(history.history["accuracy"])
plt.plot(history.history["val_accuracy"])
plt.title("Model accuracy")
plt.ylabel("Accuracy")
plt.xlabel("Epoch")
plt.legend(["Train", "Test"], loc = "upper left")
plt.show()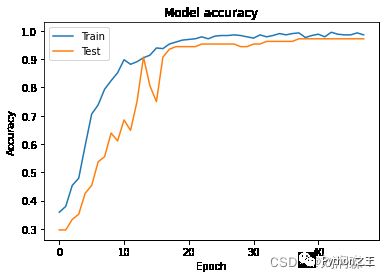
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("Model loss")
plt.ylabel("Loss")
plt.xlabel("Epoch")
plt.legend(["Train", "Test"], loc = "upper left")
plt.show()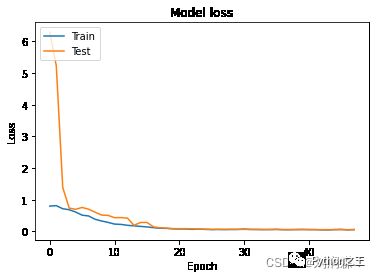
def predict_class(img):
# Resize
img = img.reshape(1,128,128,3)
# Predict
predictions = model.predict(img)
true_prediction = [tf.argmax(pred) for pred in predictions]
true_prediction = np.array(true_prediction)
# Return label corresponding to predicted index
return list(categories.keys())[list(categories.values()).index(true_prediction)]# Predict on test set
y_pred = model.predict(X_test)# From categorical outputs to discrete values
y_pred_ = [np.argmax(y) for y in y_pred]
y_test_ = [np.argmax(y) for y in y_test]from sklearn.metrics import classification_report
print(classification_report(y_test_, y_pred_))precision recall f1-score support
0 1.00 0.96 0.98 25
1 0.85 1.00 0.92 11
2 1.00 0.96 0.98 24
accuracy 0.97 60
macro avg 0.95 0.97 0.96 60
weighted avg 0.97 0.97 0.97 60plt.figure(figsize=(10,10))
random_inds = np.random.choice(X_test.shape[0],36)
for i in range(36):
plt.subplot(6,6,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
image_ind = random_inds[i]
plt.imshow(np.squeeze(X_test[image_ind]), cmap=plt.cm.binary)
# Predict and get label
label = predict_class(X_test[image_ind])
plt.xlabel(label)
model.save("model.h5")# 识别接口
def predict(path,model_str,img_size = (128,128)):
new_model = tf.keras.models.load_model(model_str)
img = cv2.imread(path)
img = cv2.resize(img, img_size) # Resize the images
img = np.array(img)
# Resize
img = img.reshape(1,128,128,3)
# Predict
predictions = new_model.predict(img)
true_prediction = [tf.argmax(pred) for pred in predictions]
true_prediction = np.array(true_prediction)
# Return label corresponding to predicted index
return list(categories.keys())[list(categories.values()).index(true_prediction)]
predict("./data/A/051.jpg","model.h5")'A'predict("./data/B/048.jpg","model.h5")'B'predict("./data/C/050.jpg","model.h5")'C'
![]()
往期精彩回顾
适合初学者入门人工智能的路线及资料下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载本站qq群955171419,加入微信群请扫码: